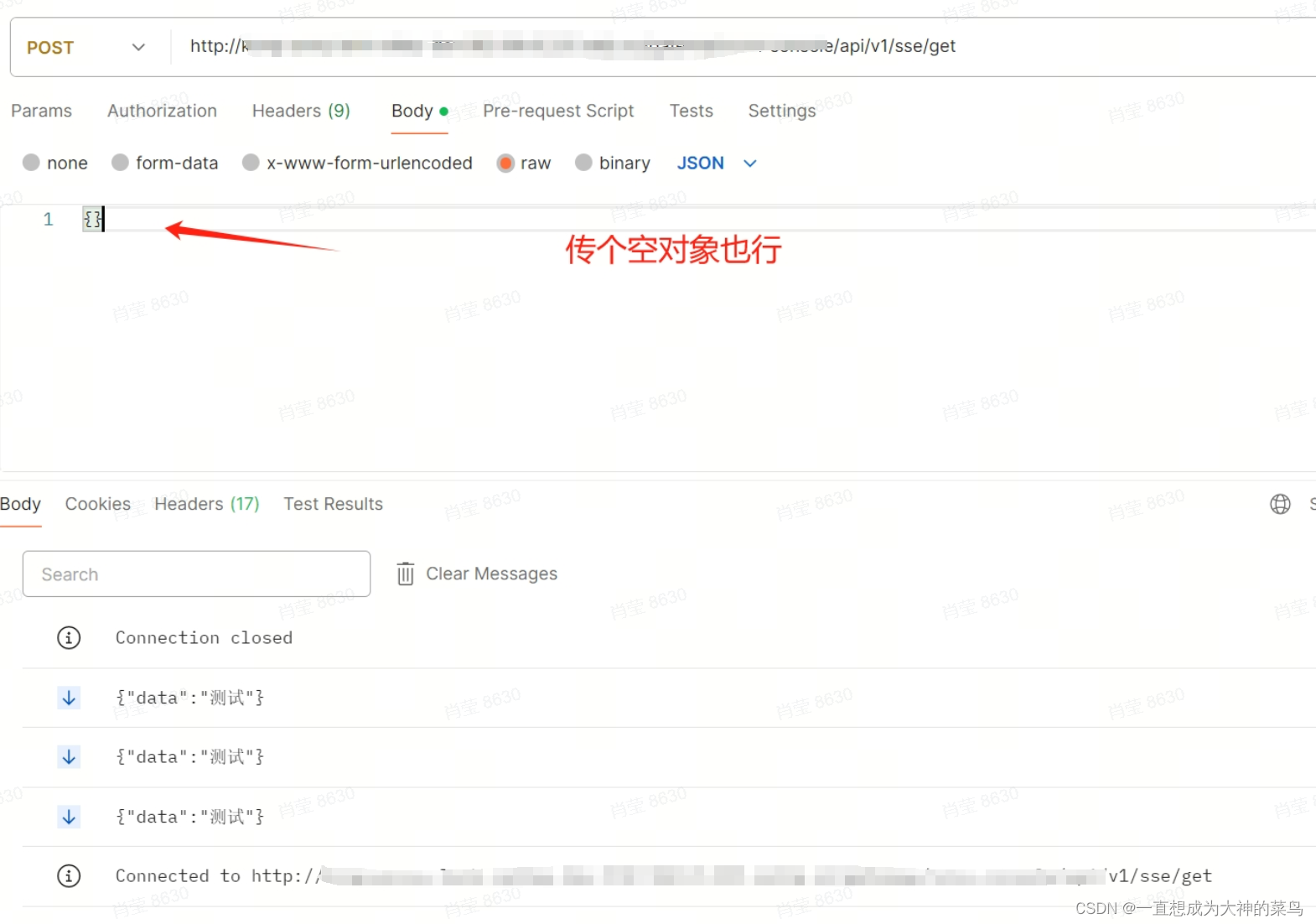
Storm 是一个免费并开源的分布式实时计算系统,具有高容错性和可扩展性。它能够处理无边界的数据流,并提供了实时计算的功能。与传统的批处理系统相比,Apache Storm 更适合处理实时数据。
Storm 是一个免费并开源的分布式实时计算系统,具有高容错性和可扩展性。它能够处理无边界的数据流,并提供了实时计算的功能。与传统的批处理系统相比,Apache Storm 更适合处理实时数据。
让我们深入了解一下 Storm:
1.Storm 简介:
- Storm 是一个分布式实时大数据处理系统,设计用于在容错和水平可扩展方法中处理大量数据。
- 它是一个流数据框架,具有最高的摄取率。
- 虽然 Storm 是无状态的,但它通过 Apache ZooKeeper 管理分布式环境和集群状态。
2.Storm 的特点:
- 编程简单:开发人员只需关注应用逻辑,类似于 Hadoop,Storm 提供的编程原语也很简单。
- 高性能,低延迟:适用于广告搜索引擎等需要实时响应的场景。
- 分布式:轻松应对数据量大、单机无法处理的场景。
- 可扩展:随着业务发展,系统可水平扩展。
- 容错:单个节点故障不影响应用。
- 消息不丢失:保证消息处理
3.Storm 与 Hadoop 的比较:
- Storm 用于实时计算,Hadoop 用于离线计算。
- Storm 处理的数据保存在内存中,源源不断;Hadoop 处理的数据保存在文件系统中,一批一批。
- Storm 的数据通过网络传输进来;Hadoop 的数据保存在磁盘中。
- Storm 与 Hadoop 的编程模型相似。
4.Storm 集群架构:
- Nimbus:Storm 集群的 Master 节点,负责分发用户代码,指派给具体的 Supervisor 节点上的 Worker 节点运行 Topology 对应的组件(Spout/Bolt)的 Task。
- Supervisor:Storm 集群的从节点,负责管理运行在 Supervisor 节点上的每一个 Worker 进程的启动和终止。
- ZooKeeper:协调 Nimbus 和 Supervisor,确保 Topology 在故障情况下重新分配到可用的 Supervisor 上运行。
5.Storm 编程模型:
- Spout:获取源数据流的组件,通常从外部数据源中读取数据并转换为 Topology 内部的源数据。
- Bolt:接受数据并执行处理的组件,用户可以在其中执行自己想要的操作。
- Tuple:一次消息传递的基本单元,理解为一组消息就是一个 Tuple。
- Stream:Tuple 的集合,表示数据的流向。
6.Topology 运行:
- 在 Storm 中,一个实时应用的计算任务被打包作为 Topology 发布,类似于 Hadoop 的 MapReduce 任务。
- 不同之处在于,Storm 中的 Topology 任务一旦提交后永远不会结束,除非显式停止任务。
- Topology 由不同的 Spouts 和 Bolts 通过数据流连接起来,形成图形结构。
- Storm 使用 Worker、Executor 和 Task 来完成 Topology 的执行工作,保证实时数据处理。
7.应用场景:
Storm 是一个强大的分布式实时计算系统,适用于多种场景。以下是一些 Storm 的应用场景:
实时分析:Storm 可以处理无限的数据流,用于实时分析,例如实时监控、实时报警、实时指标计算等。
在线机器学习:Storm 适用于在线机器学习任务,如实时模型训练、特征提取和预测。
持续计算:Storm 可以处理连续的数据流,例如流式处理日志、事件流、传感器数据等。
分布式 RPC:Storm 可以用于构建分布式远程过程调用(RPC)系统,实现分布式服务之间的通信。
ETL(Extract, Transform, Load):Storm 可以用于数据抽取、转换和加载,将数据从不同源转移到目标系统。
 总之,Storm 是一款强大的分布式实时计算系统,为企业提供稳定可靠的实时计算服务,帮助处理和分析大规模数据,促进业务增长和发展。Storm 的灵活性、高性能和可靠性使其成为处理实时数据的理想选择,适用于各种业务需求。
总之,Storm 是一款强大的分布式实时计算系统,为企业提供稳定可靠的实时计算服务,帮助处理和分析大规模数据,促进业务增长和发展。Storm 的灵活性、高性能和可靠性使其成为处理实时数据的理想选择,适用于各种业务需求。