书生·浦语大模型实战营之Llama 3 高效部署实践(LMDeploy 版)


- 环境,模型准备
- LMDeploy chat
- Turmind和Transformer的速度对比
- LMDeploy模型量化(lite)
- LMDeploy服务(serve)
环境,模型准备
InternStudio 可以直接使用
studio-conda -t Llama3_lmdeploy -o pytorch-2.1.2
Llama3 的下载
软链接 InternStudio 中的模型
mkdir -p ~/model
ln -s /root/share/new_models/meta-llama/Meta-Llama-3-8B-Instruct ~/model/Meta-Llama-3-8B-Instruct
LMDeploy chat
Huggingface与TurboMind
- HuggingFace
HuggingFace是一个高速发展的社区,包括Meta、Google、Microsoft、Amazon在内的超过5000家组织机构在为HuggingFace开源社区贡献代码、数据集和模型。可以认为是一个针对深度学习模型和数据集的在线托管社区,如果你有数据集或者模型想对外分享,网盘又不太方便,就不妨托管在HuggingFace。
托管在HuggingFace社区的模型通常采用HuggingFace格式存储,简写为HF格式。
但是HuggingFace社区的服务器在国外,国内访问不太方便。国内可以使用阿里巴巴的MindScope社区,或者上海AI Lab搭建的OpenXLab社区,上面托管的模型也通常采用HF格式。 - TurboMind
TurboMind是LMDeploy团队开发的一款关于LLM推理的高效推理引擎,它的主要功能包括:LLaMa 结构模型的支持,continuous batch 推理模式和可扩展的 KV 缓存管理器。
TurboMind推理引擎仅支持推理TurboMind格式的模型。因此,TurboMind在推理HF格式的模型时,会首先自动将HF格式模型转换为TurboMind格式的模型。该过程在新版本的LMDeploy中是自动进行的,无需用户操作。
几个容易迷惑的点:
- TurboMind与LMDeploy的关系:LMDeploy是涵盖了LLM 任务全套轻量化、部署和服务解决方案的集成功能包,TurboMind是LMDeploy的一个推理引擎,是一个子模块。LMDeploy也可以使用pytorch作为推理引擎。
- TurboMind与TurboMind模型的关系:TurboMind是推理引擎的名字,TurboMind模型是一种模型存储格式,TurboMind引擎只能推理TurboMind格式的模型。
使用Transformer库运行模型
使用Transformer库之前需要确定安装的是最新版本
pip install transformers==4.40.0
运行touch /root/pipeline_transformer.py 将下面代码复制进去,然后保存
import torch
from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("/root/model/Meta-Llama-3-8B-Instruct", trust_remote_code=True)# Set `torch_dtype=torch.float16` to load model in float16, otherwise it will be loaded as float32 and cause OOM Error.
model = AutoModelForCausalLM.from_pretrained("/root/model/Meta-Llama-3-8B-Instruct", torch_dtype=torch.float16, trust_remote_code=True).cuda()
model = model.eval()messages = [{"role": "system", "content": "你现在是一个友好的机器人,回答的时候只能使用中文"},{"role": "user", "content": "你好"},
]input_ids = tokenizer.apply_chat_template(messages,add_generation_prompt=True,return_tensors="pt"
).to(model.device)terminators = [tokenizer.eos_token_id,tokenizer.convert_tokens_to_ids("<|eot_id|>")
]outputs = model.generate(input_ids,max_new_tokens=256,eos_token_id=terminators,do_sample=True,temperature=0.6,top_p=0.9,
)
response = outputs[0][input_ids.shape[-1]:]
print(tokenizer.decode(response, skip_special_tokens=True))
执行代码:
python /root/pipeline_transformer.py
运行结果为:模型能够正常输出结果,那就表明下载的模型没有问题。
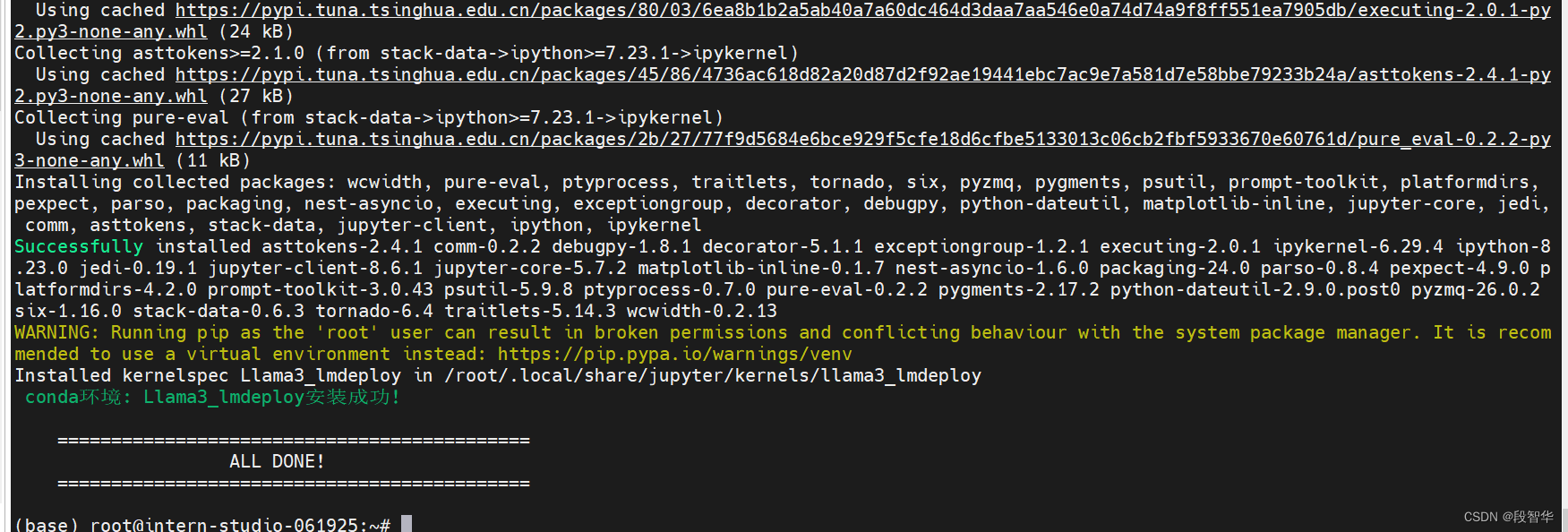
(Llama3_lmdeploy) root@intern-studio-061925:~# python /root/pipeline_transformer.py
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████| 4/4 [00:41<00:00, 10.42s/it]
The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Setting `pad_token_id` to `eos_token_id`:128001 for open-end generation.
你好!很高兴见到你!如何可以帮助你?
(Llama3_lmdeploy) root@intern-studio-061925:~#接下来,可以使用lmdeploy进行对话交互。
使用LMDeploy与模型对话
直接在终端运行
lmdeploy chat /root/model/Meta-Llama-3-8B-Instruct
Llama3模型在回答问题时倾向于使用英文,特别是对于稍微复杂的问题。简单的中文问题它会用中文回答,但是一旦问题变得复杂一些,就会全部使用英文。
(Llama3_lmdeploy) root@intern-studio-061925:~#
(Llama3_lmdeploy) root@intern-studio-061925:~# lmdeploy chat /root/model/Meta-Llama-3-8B-Instruct
2024-04-24 09:38:44,886 - lmdeploy - WARNING - Fallback to pytorch engine because turbomind engine is not installed correctly. If you insist to use turbomind engine, you may need to reinstall lmdeploy from pypi or build from source and try again.
2024-04-24 09:38:57,493 - lmdeploy - INFO - Checking environment for PyTorch Engine.
2024-04-24 09:39:00,136 - lmdeploy - INFO - Checking model.
2024-04-24 09:39:00,137 - lmdeploy - WARNING - LMDeploy requires transformers version: [4.33.0 ~ 4.38.2], but found version: 4.40.0
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████| 4/4 [00:37<00:00, 9.42s/it]
2024-04-24 09:39:48,210 - lmdeploy - INFO - build CacheEngine with config:CacheConfig(block_size=64, num_cpu_blocks=512, num_gpu_blocks=512, window_size=-1, cache_max_entry_count=0.8, max_prefill_token_num=4096)
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
match template: <llama3>double enter to end input >>> 你好<|begin_of_text|><|start_header_id|>user<|end_header_id|>你好<|eot_id|><|start_header_id|>assistant<|end_header_id|>😊 !你好!double enter to end input >>> 北京有哪些著名景点<|start_header_id|>user<|end_header_id|>北京有哪些著名景点<|eot_id|><|start_header_id|>assistant<|end_header_id|>Beijing has many famous landmarks and attractions. Here are some of the most popular ones:1. **The Great Wall of China** (长城): A series of fortifications built across the northern borders of China, stretching over 4,000 miles.
2. **The Forbidden City** (Forbidden City): A palace complex that was the imperial palace of the Ming and Qing dynasties for over 500 years.
3. **Tiananmen Square** (天安门广场): One of the largest city squares in the world, surrounded by famous landmarks like the Forbidden City, Mao's Mausoleum, and the National Museum of China.
4. **Temple of Heaven** (天坛): A Taoist temple complex built in the 15th century, where emperors would worship and make sacrifices to heaven.
5. **Summer Palace** (颐和园): A beautiful palace complex with gardens, temples, and pavilions, built in the 18th century as a summer retreat for emperors.
6. **Ming Tombs** (明十三陵): The mausoleum of 13 Ming dynasty emperors, located about 45 miles northwest of Beijing.
7. **Hutongs** (胡同): Narrow alleys and traditional courtyard homes that are a reminder of old Beijing.
8. **Beihai Park** (北海公园): A large park with a lake, temples, and gardens, located in the heart of Beijing.
9. **National Grand Theater** (国家大剧院): A modern theater complex with a unique "egg" design, hosting various performances and events.
10. **Olympic Park** (奥林匹克公园): A large park built for the 2008 Beijing Olympics, featuring the iconic "Bird's Nest" and "Water Cube" stadiums.These are just a few of the many amazing attractions Beijing has to offer.double enter to end input >>>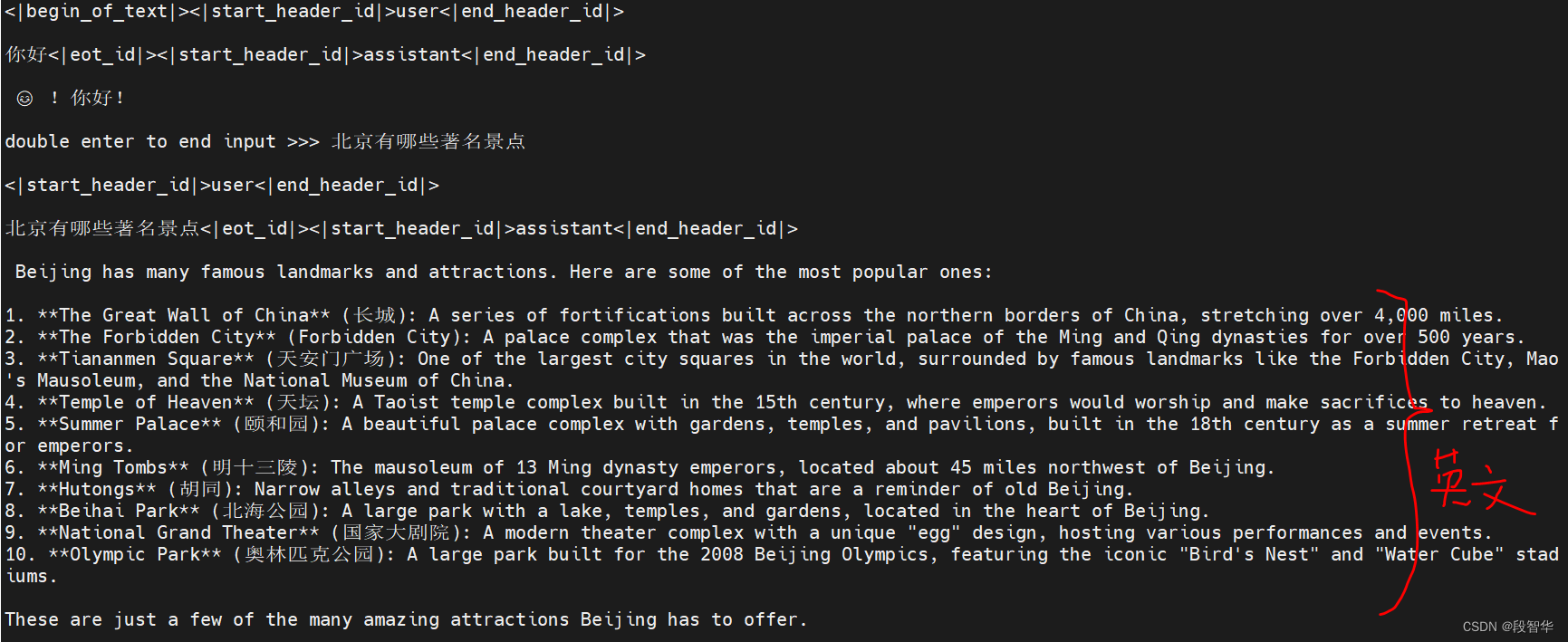
因此需要修改prompt,打开/root/lmdeploy/lmdeploy/model.py
(Llama3_lmdeploy) root@intern-studio-061925:~# cat /root/lmdeploy/lmdeploy/model.py
# Copyright (c) OpenMMLab. All rights reserved.
import dataclasses
import json
import uuid
from abc import abstractmethod
from typing import List, Literal, Optionalfrom mmengine import Registryfrom lmdeploy.utils import get_loggerlogger = get_logger('lmdeploy')
MODELS = Registry('model', locations=['lmdeploy.model'])def random_uuid() -> str:"""Return a random uuid."""return str(uuid.uuid4().hex)@dataclasses.dataclass
class ChatTemplateConfig:"""Parameters for chat template.Args:model_name (str): the name of the deployed model. Determine which chat template will be applied.All the chat template names: `lmdeploy list`system (str | None): begin of the system promptmeta_instruction (str | None): system prompteosys (str | None): end of the system promptuser (str | None): begin of the user prompteoh (str | None): end of the user promptassistant (str | None): begin of the assistant prompteoa (str | None): end of the assistant promptcapability: ('completion' | 'infilling' | 'chat' | 'python') = None""" # noqa: E501model_name: strsystem: Optional[str] = Nonemeta_instruction: Optional[str] = Noneeosys: Optional[str] = Noneuser: Optional[str] = Noneeoh: Optional[str] = Noneassistant: Optional[str] = Noneeoa: Optional[str] = Noneseparator: Optional[str] = Nonecapability: Optional[Literal['completion', 'infilling', 'chat','python']] = Nonestop_words: Optional[List[str]] = None@propertydef chat_template(self):attrs = {key: valuefor key, value in dataclasses.asdict(self).items()if value is not None}attrs.pop('model_name', None)if self.model_name in MODELS.module_dict.keys():model: BaseModel = MODELS.get(self.model_name)(**attrs)else:logger.warning(f'Could not find {self.model_name} in registered models. 'f'Register {self.model_name} using the BaseChatTemplate.')model = BaseChatTemplate(**attrs)return modeldef to_json(self, file_path=None):"""Convert the dataclass instance to a JSON formatted string andoptionally save to a file."""json_str = json.dumps(dataclasses.asdict(self),ensure_ascii=False,indent=4)if file_path:with open(file_path, 'w', encoding='utf-8') as file:file.write(json_str)return json_str@classmethoddef from_json(cls, file_or_string):"""Construct a dataclass instance from a JSON file or JSON string."""try:# Try to open the input_data as a file pathwith open(file_or_string, 'r', encoding='utf-8') as file:json_data = file.read()except FileNotFoundError:# If it's not a file path, assume it's a JSON stringjson_data = file_or_stringexcept IOError:# If it's not a file path and not a valid JSON string, raise errorraise ValueError('Invalid input. Must be a file path or a valid JSON string.')json_data = json.loads(json_data)if json_data.get('model_name', None) is None:json_data['model_name'] = random_uuid()if json_data['model_name'] not in MODELS.module_dict.keys():MODELS.register_module(json_data['model_name'],module=BaseChatTemplate)return cls(**json_data)@MODELS.register_module(name='llama')
@MODELS.register_module(name='base')
class BaseModel:"""Base model."""def __init__(self,session_len=2048,capability='chat',stop_words=None,**kwargs):self.session_len = session_lenself.stop_words = stop_wordsself.capability = capabilitydef get_prompt(self, prompt, sequence_start=True):"""Return the prompt that is concatenated with other elements in thechat template.Args:prompt (str): user's input promptsequence_start (bool): indicator for the first round chat of asession sequenceReturns:str: the concatenated prompt"""return prompt@abstractmethoddef messages2prompt(self, messages, sequence_start=True):"""Return the prompt that is concatenated with other elements in thechat template. When messages arg is a string, returnself.get_prompt(messages). When messages arg is a chat history, returntranslated prompt from chat history.Args:messages (str | List): user's input promptReturns:str: the concatenated prompt"""if isinstance(messages, str):return self.get_prompt(messages)# chat history processing in derived classes@classmethoddef match(cls, model_path: str) -> Optional[str]:"""Return the model_name that was registered to MODELS.Args:model_path (str): the model path used for matching."""return Noneclass BaseChatTemplate(BaseModel):"""Base Chat template."""def __init__(self,system='',meta_instruction='',eosys='',user='',eoh='',assistant='',eoa='',separator='',**kwargs):super().__init__(**kwargs)self.system = systemself.meta_instruction = meta_instructionself.user = userself.eoh = eohself.eoa = eoaself.separator = separatorself.eosys = eosysself.assistant = assistantdef get_prompt(self, prompt, sequence_start=True):"""Return the prompt that is concatenated with other elements in thechat template.Args:prompt (str): user's input promptsequence_start (bool): indicator for the first round chat of asession sequenceReturns:str: the concatenated prompt"""if self.capability == 'completion':return promptif sequence_start:# None is different from ''if self.meta_instruction is not None:return f'{self.system}{self.meta_instruction}{self.eosys}' \f'{self.user}{prompt}{self.eoh}' \f'{self.assistant}'else:return f'{self.user}{prompt}{self.eoh}' \f'{self.assistant}'else:return f'{self.separator}{self.user}{prompt}{self.eoh}' \f'{self.assistant}'def messages2prompt(self, messages, sequence_start=True):"""Return the prompt that is concatenated with other elements in thechat template.Args:messages (str | List): user's input promptReturns:str: the concatenated prompt"""if isinstance(messages, str):return self.get_prompt(messages, sequence_start)box_map = dict(user=self.user,assistant=self.assistant,system=self.system)eox_map = dict(user=self.eoh,assistant=self.eoa + self.separator,system=self.eosys)ret = ''if self.meta_instruction is not None:if len(messages) and messages[0]['role'] != 'system':ret += f'{self.system}{self.meta_instruction}{self.eosys}'for message in messages:role = message['role']content = message['content']ret += f'{box_map[role]}{content}{eox_map[role]}'ret += f'{self.assistant}'return ret@MODELS.register_module(name='wizardlm')
@MODELS.register_module(name='vicuna')
class Vicuna(BaseChatTemplate):"""Chat template of vicuna model."""def __init__(self,meta_instruction="""A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions.""", # noqa: E501eosys=' ',user='USER: ',eoh=' ',assistant='ASSISTANT: ',eoa='</s>',stop_words=['</s>'],**kwargs):super().__init__(meta_instruction=meta_instruction,eosys=eosys,user=user,eoh=eoh,assistant=assistant,eoa=eoa,stop_words=stop_words,**kwargs)@classmethoddef match(cls, model_path: str) -> Optional[str]:"""Return the model_name that was registered to MODELS.Args:model_path (str): the model path used for matching."""path = model_path.lower()if 'vicuna' in path:return 'vicuna'if 'wizardlm' in path:return 'wizardlm'@MODELS.register_module(name='mini-gemini-vicuna')
class MiniGemini(Vicuna):"""Chat template of vicuna model."""def __init__(self, session_len=4096, **kwargs):super().__init__(session_len=session_len, **kwargs)def get_prompt(self, prompt, sequence_start=True):return super().get_prompt(prompt, sequence_start)[:-1]def messages2prompt(self, messages, sequence_start=True):return super().messages2prompt(messages, sequence_start)[:-1]@classmethoddef match(cls, model_path: str) -> Optional[str]:"""Return the model_name that was registered to MODELS.Args:model_path (str): the model path used for matching."""path = model_path.lower()if 'mini-gemini-7b' in path or 'mini-gemini-13b' in path:return 'mini-gemini-vicuna'@MODELS.register_module(name='internlm-chat')
@MODELS.register_module(name='internlm-chat-7b')
@MODELS.register_module(name='internlm')
class InternLMChat7B(BaseChatTemplate):"""Chat template of InternLM model."""def __init__(self,system='<|System|>:',meta_instruction="""You are an AI assistant whose name is InternLM (书生·浦语).
- InternLM (书生·浦语) is a conversational language model that is developed by Shanghai AI Laboratory (上海人工智能实验室). It is designed to be helpful, honest, and harmless.
- InternLM (书生·浦语) can understand and communicate fluently in the language chosen by the user such as English and 中文.
""", # noqa: E501eosys='\n',user='<|User|>:',eoh='\n',assistant='<|Bot|>:',eoa='<eoa>',separator='\n',stop_words=['<eoa>'],**kwargs):super().__init__(system=system,meta_instruction=meta_instruction,eosys=eosys,user=user,eoh=eoh,assistant=assistant,eoa=eoa,separator=separator,stop_words=stop_words,**kwargs)@classmethoddef match(cls, model_path: str) -> Optional[str]:"""Return the model_name that was registered to MODELS.Args:model_path (str): the model path used for matching."""path = model_path.lower()if all([c not in path for c in ['internlm2', '8k']]) and \all([c in path for c in ['internlm', 'chat']]):return 'internlm'@MODELS.register_module(name='internlm-chat-20b')
@MODELS.register_module(name='internlm-chat-7b-8k')
class InternLMChat7B8K(InternLMChat7B):"""Chat template and generation parameters of InternLM-Chat-7B-8K andInternLM-Chat-20B models."""def __init__(self, session_len=8192, **kwargs):super(InternLMChat7B8K, self).__init__(**kwargs)self.session_len = session_len@MODELS.register_module(name='internlm-20b')
class InternLMBaseModel20B(BaseChatTemplate):"""Generation parameters of InternLM-20B-Base model."""def __init__(self, session_len=4096, capability='completion', **kwargs):super().__init__(session_len=session_len,capability=capability,**kwargs)@MODELS.register_module(name=['internlm2-1_8b', 'internlm2-7b', 'internlm2-20b'])
class InternLM2BaseModel7B(BaseChatTemplate):"""Generation parameters of InternLM2-7B-Base model."""def __init__(self, session_len=32768, capability='completion', **kwargs):super().__init__(session_len=session_len,capability=capability,**kwargs)@MODELS.register_module(name=['internlm2-chat', 'internlm2-chat-1_8b', 'internlm2-chat-7b','internlm2-chat-20b'
])
@MODELS.register_module(name='internlm2')
class InternLM2Chat7B(InternLMChat7B):"""Chat template and generation parameters of InternLM2-Chat-7B."""def __init__(self,session_len=32768,system='<|im_start|>system\n',user='<|im_start|>user\n',assistant='<|im_start|>assistant\n',environment='<|im_start|>environment\n',plugin='<|plugin|>',interpreter='<|interpreter|>',eosys='<|im_end|>\n',eoh='<|im_end|>\n',eoa='<|im_end|>',eoenv='<|im_end|>\n',separator='\n',stop_words=['<|im_end|>', '<|action_end|>'],**kwargs):self.plugin = pluginself.interpreter = interpreterself.environment = environmentself.eoenv = eoenvsuper(InternLM2Chat7B, self).__init__(session_len=session_len,system=system,user=user,assistant=assistant,eosys=eosys,eoh=eoh,eoa=eoa,separator=separator,stop_words=stop_words,**kwargs)@classmethoddef match(cls, model_path: str) -> Optional[str]:"""Return the model_name that was registered to MODELS.Args:model_path (str): the model path used for matching."""path = model_path.lower()if 'internlm2' in path and ('chat' in path or 'math' in path):return 'internlm2'def messages2prompt(self, messages, sequence_start=True):"""Return the prompt that is concatenated with other elements in thechat template.Args:messages (str | List): user's input promptReturns:str: the concatenated prompt"""if isinstance(messages, str):return self.get_prompt(messages, sequence_start)box_map = dict(user=self.user,assistant=self.assistant,system=self.system,environment=self.environment)eox_map = dict(user=self.eoh,assistant=self.eoa + self.separator,system=self.eosys,environment=self.eoenv)name_map = dict(plugin=self.plugin, interpreter=self.interpreter)ret = ''if self.meta_instruction is not None:if len(messages) and messages[0]['role'] != 'system':ret += f'{self.system}{self.meta_instruction}{self.eosys}'for message in messages:role = message['role']content = message['content']begin = box_map[role].strip() + f" name={name_map[message['name']]}\n" if 'name' in message else box_map[role]ret += f'{begin}{content}{eox_map[role]}'ret += f'{self.assistant}'return ret@MODELS.register_module(name='internlm-xcomposer2')
class InternLMXComposer2Chat7B(InternLMChat7B):"""Chat template and generation parameters of InternLM-XComposer2-7b."""def __init__(self,session_len=4096,system='[UNUSED_TOKEN_146]system\n',meta_instruction="""You are an AI assistant whose name is InternLM-XComposer (浦语·灵笔).
- InternLM-XComposer (浦语·灵笔) is a multi-modality conversational language model that is developed by Shanghai AI Laboratory (上海人工智能实验室). It is designed to be helpful, honest, and harmless.
- InternLM-XComposer (浦语·灵笔) can understand and communicate fluently in the language chosen by the user such as English and 中文.
- InternLM-XComposer (浦语·灵笔) is capable of comprehending and articulating responses effectively based on the provided image.""",user='[UNUSED_TOKEN_146]user\n',assistant='[UNUSED_TOKEN_146]assistant\n',eosys='[UNUSED_TOKEN_145]\n',eoh='[UNUSED_TOKEN_145]\n',eoa='[UNUSED_TOKEN_145]\n',separator='\n',stop_words=['[UNUSED_TOKEN_145]'],**kwargs):super().__init__(session_len=session_len,system=system,meta_instruction=meta_instruction,user=user,assistant=assistant,eosys=eosys,eoh=eoh,eoa=eoa,separator=separator,stop_words=stop_words,**kwargs)@classmethoddef match(cls, model_path: str) -> Optional[str]:"""Return the model_name that was registered to MODELS.Args:model_path (str): the model path used for matching."""path = model_path.lower()if 'internlm' in path and 'xcomposer2' in path and '4khd' not in path:return 'internlm-xcomposer2'@MODELS.register_module(name='internlm-xcomposer2-4khd')
class InternLMXComposer24khdChat7B(InternLMXComposer2Chat7B):"""Chat template and generation parameters of InternLM-XComposer2-4khd-7b."""def __init__(self, session_len=16384, **kwargs):super().__init__(session_len=session_len, **kwargs)@classmethoddef match(cls, model_path: str) -> Optional[str]:"""Return the model_name that was registered to MODELS.Args:model_path (str): the model path used for matching."""path = model_path.lower()if 'internlm' in path and 'xcomposer2' in path and '4khd' in path:return 'internlm-xcomposer2-4khd'@MODELS.register_module(name='baichuan-7b')
@MODELS.register_module(name='baichuan-base')
class Baichuan7B(BaseChatTemplate):"""Generation parameters of Baichuan-7B base model."""def __init__(self, **kwargs):super().__init__(**kwargs)@MODELS.register_module(name='baichuan2-7b')
@MODELS.register_module(name='baichuan2')
class Baichuan2_7B(BaseChatTemplate):"""Chat template and generation parameters of Baichuan2-7B-Base andBaichuan2-7B-Chat models."""def __init__(self,user='<reserved_106>',assistant='<reserved_107>',**kwargs):super().__init__(user=user, assistant=assistant, **kwargs)@classmethoddef match(cls, model_path: str) -> Optional[str]:"""Return the model_name that was registered to MODELS.Args:model_path (str): the model path used for matching."""path = model_path.lower()if 'baichuan2' in path and 'chat' in path:return 'baichuan2'@MODELS.register_module(name='puyu')
class Puyu(BaseChatTemplate):"""Chat template of puyu model.This is only for internal usage in ShanghaiAI Laboratory."""def __init__(self,meta_instruction='',system='',eosys='',user='',eoh='',assistant='',eoa='',stop_words=None,**kwargs):super().__init__(meta_instruction=meta_instruction,system=system,eosys=eosys,user=user,eoh=eoh,assistant=assistant,eoa=eoa,stop_words=stop_words,**kwargs)@classmethoddef match(cls, model_path: str) -> Optional[str]:"""Return the model_name that was registered to MODELS.Args:model_path (str): the model path used for matching."""if 'puyu' in model_path.lower():return 'puyu'@MODELS.register_module(name=['llama2', 'llama-2', 'llama-2-chat'])
class Llama2(BaseChatTemplate):"""Chat template of LLaMA2 model."""def __init__(self,system='[INST] <<SYS>>\n',meta_instruction="""\
You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.""", # noqa: E501eosys='\n<</SYS>>\n\n',assistant=' [/INST] ',eoa='</s>',separator='<s>[INST] ',session_len=4096,**kwargs):super().__init__(system=system,meta_instruction=meta_instruction,eosys=eosys,assistant=assistant,eoa=eoa,separator=separator,session_len=session_len,**kwargs)@classmethoddef match(cls, model_path: str) -> Optional[str]:"""Return the model_name that was registered to MODELS.Args:model_path (str): the model path used for matching."""if 'llama-2' in model_path.lower() or 'llama2' in model_path.lower():return 'llama2'@MODELS.register_module(name='llama3')
class Llama3(BaseChatTemplate):"""Chat template of LLaMA3 model."""def __init__(self,system='<|start_header_id|>system<|end_header_id|>\n\n',meta_instruction=None,eosys='<|eot_id|>',assistant='<|start_header_id|>assistant<|end_header_id|>\n\n',eoa='<|eot_id|>',user='<|start_header_id|>user<|end_header_id|>\n\n',eoh='<|eot_id|>',stop_words=['<|eot_id|>', '<|end_of_text|>'],session_len=8192,**kwargs):super().__init__(system=system,meta_instruction=meta_instruction,eosys=eosys,assistant=assistant,eoa=eoa,user=user,eoh=eoh,stop_words=stop_words,session_len=session_len,**kwargs)def get_prompt(self, prompt, sequence_start=True):if sequence_start:return '<|begin_of_text|>' + super().get_prompt(prompt, sequence_start)return super().get_prompt(prompt, sequence_start)def messages2prompt(self, messages, sequence_start=True):if sequence_start and not isinstance(messages, str):return '<|begin_of_text|>' + super().messages2prompt(messages, sequence_start)[:-1]return super().messages2prompt(messages, sequence_start)[:-1]@classmethoddef match(cls, model_path: str) -> Optional[str]:"""Return the model_name that was registered to MODELS.Args:model_path (str): the model path used for matching."""if 'llama-3-' in model_path.lower() or 'llama3-' in model_path.lower():return 'llama3'@MODELS.register_module(name='qwen-14b')
@MODELS.register_module(name='qwen-7b')
@MODELS.register_module(name='qwen')
class Qwen7BChat(BaseChatTemplate):"""Chat template for Qwen-7B-Chat."""def __init__(self,session_len=8192,system='<|im_start|>system\n',meta_instruction='You are a helpful assistant.',eosys='<|im_end|>\n',user='<|im_start|>user\n',eoh='<|im_end|>\n',assistant='<|im_start|>assistant\n',eoa='<|im_end|>',separator='\n',stop_words=['<|im_end|>'],**kwargs):super().__init__(system=system,meta_instruction=meta_instruction,eosys=eosys,user=user,eoh=eoh,assistant=assistant,eoa=eoa,separator=separator,stop_words=stop_words,session_len=session_len,**kwargs)@classmethoddef match(cls, model_path: str) -> Optional[str]:"""Return the model_name that was registered to MODELS.Args:model_path (str): the model path used for matching."""if 'qwen' in model_path.lower():return 'qwen'@MODELS.register_module(name='codellama')
class CodeLlama(Llama2):def __init__(self,meta_instruction='',session_len=4096,suffix_first=False,stop_words=None,**kwargs):super().__init__(meta_instruction=meta_instruction,session_len=session_len,stop_words=stop_words,**kwargs)caps = ['completion', 'infilling', 'chat', 'python']assert self.capability in caps, \f'{self.capability} is not supported. ' \f'The supported capabilities are: {caps}'self.meta_instruction = meta_instructionself.session_len = session_lenself.suffix_first = suffix_firstself.stop_words = stop_wordsif self.capability == 'infilling':if self.stop_words is None:self.stop_words = ['<EOT>']def get_prompt(self, prompt, sequence_start=True):if self.capability == 'infilling':return self._infill_prompt(prompt)elif self.capability == 'chat':return super().get_prompt(prompt, sequence_start)else: # python speicalistreturn promptdef _infill_prompt(self, prompt):prefix, suffix = prompt.split('<FILL>')if self.suffix_first:# format as "<PRE> <SUF>{suf} <MID> {pre}"prompt = f'<PRE> <SUF>{suffix} <MID> {prefix}'else:# format as "<PRE> {pre} <SUF>{suf} <MID>"prompt = f'<PRE> {prefix} <SUF>{suffix} <MID>'return prompt@classmethoddef match(cls, model_path: str) -> Optional[str]:"""Return the model_name that was registered to MODELS.Args:model_path (str): the model path used for matching."""if 'codellama' in model_path.lower():return 'codellama'@MODELS.register_module(name='falcon')
class Falcon(BaseModel):def __init__(self, **kwargs):super().__init__(**kwargs)@classmethoddef match(cls, model_path: str) -> Optional[str]:"""Return the model_name that was registered to MODELS.Args:model_path (str): the model path used for matching."""if 'falcon' in model_path.lower():return 'falcon'@MODELS.register_module(name='chatglm2-6b')
@MODELS.register_module(name='chatglm')
class ChatGLM2(BaseModel):def __init__(self,user='问:',eoh='\n\n',assistant='答:',eoa='\n\n',**kwargs):super().__init__(**kwargs)self._user = userself._assistant = assistantself._eoh = eohself._eoa = eoaself.count = 0def get_prompt(self, prompt, sequence_start=True):"""get prompt."""# need more check# https://github.com/THUDM/ChatGLM2-6B/issues/48# [64790, 64792] to be prependedself.count += 1ret = f'[Round {self.count}]\n\n'ret += f'{self._user}{prompt}{self._eoh}'ret += f'{self._assistant}'return retdef messages2prompt(self, messages, sequence_start=True):"""message to prompt."""if isinstance(messages, str):return self.get_prompt(messages, sequence_start)ret = ''count = 0for message in messages:role = message['role']content = message['content']if role == 'user':count += 1ret += f'[Round {count}]\n\n'ret += f'{self._user}{content}{self._eoh}'ret += f'{self._assistant}'if role == 'assistant':ret += f'{content}'return ret@classmethoddef match(cls, model_path: str) -> Optional[str]:"""Return the model_name that was registered to MODELS.Args:model_path (str): the model path used for matching."""if 'chatglm' in model_path.lower():return 'chatglm'@MODELS.register_module(name=['solar', 'solar-70b'])
class SOLAR(BaseChatTemplate):"""Chat template of SOLAR model.`https://huggingface.co/upstage/SOLAR-0-70b-16bit`"""def __init__(self,system='### System:\n',eosys='\n\n',user='### User:\n',eoh='\n\n',assistant='### Assistant:\n',meta_instruction='',session_len=2048,**kwargs):super().__init__(**kwargs)self.system = systemself.eosys = eosysself.user = userself.eoh = eohself.assistant = assistantself.meta_instruction = meta_instructionself.session_len = session_len@classmethoddef match(cls, model_path: str) -> Optional[str]:"""Return the model_name that was registered to MODELS.Args:model_path (str): the model path used for matching."""if 'solar' in model_path.lower():return 'solar'@MODELS.register_module(name='ultracm')
@MODELS.register_module(name='ultralm')
class UltraChat(BaseChatTemplate):"""Template of UltraCM and UltraLM models.`https://huggingface.co/openbmb/UltraCM-13b``https://huggingface.co/openbmb/UltraLM-13b`"""def __init__(self,system='User: ',meta_instruction="""A one-turn chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, very detailed, and polite answers to the user's questions.""", # noqa: E501eosys='</s>\n',user='User: ',eoh='</s>\n',assistant='Assistant: ',eoa='</s>',separator='\n',stop_words=['</s>'],session_len=2048,**kwargs):super().__init__(system=system,meta_instruction=meta_instruction,eosys=eosys,user=user,eoh=eoh,assistant=assistant,eoa=eoa,separator=separator,stop_words=stop_words,session_len=session_len,**kwargs)@classmethoddef match(cls, model_path: str) -> Optional[str]:"""Return the model_name that was registered to MODELS.Args:model_path (str): the model path used for matching."""if 'ultracm' in model_path.lower():return 'ultracm'if 'ultralm' in model_path.lower():return 'ultralm'@MODELS.register_module(name=['yi', 'yi-chat', 'yi-200k', 'yi-34b'])
class Yi(BaseChatTemplate):"""Chat template of Yi model."""def __init__(self,system='<|im_start|>system\n',meta_instruction=None,eosys='<|im_end|>\n',user='<|im_start|>user\n',eoh='<|im_end|>\n',assistant='<|im_start|>assistant\n',eoa='<|im_end|>',separator='\n',stop_words=['<|im_end|>', '<|endoftext|>'],**kwargs):super().__init__(system=system,meta_instruction=meta_instruction,eosys=eosys,user=user,eoh=eoh,assistant=assistant,eoa=eoa,separator=separator,stop_words=stop_words,**kwargs)@classmethoddef match(cls, model_path: str) -> Optional[str]:"""Return the model_name that was registered to MODELS.Args:model_path (str): the model path used for matching."""path = model_path.lower()if 'yi' in path and 'vl' not in path:return 'yi'@MODELS.register_module(name=['mistral', 'mixtral'])
@MODELS.register_module(name=['Mistral-7B-Instruct', 'Mixtral-8x7B-Instruct'])
class MistralChat(BaseChatTemplate):"""Template of Mistral and Mixtral Instruct models.`https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1``https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1`"""def __init__(self,user='[INST] ',eoh=' [/INST]',eoa='</s>',session_len=2048,**kwargs):super().__init__(user=user,eoh=eoh,eoa=eoa,session_len=session_len,**kwargs)@classmethoddef match(cls, model_path: str) -> Optional[str]:"""Return the model_name that was registered to MODELS.Args:model_path (str): the model path used for matching."""if 'instruct' in model_path.lower():if 'mistral' in model_path.lower():return 'mistral'if 'mixtral' in model_path.lower():return 'mixtral'@MODELS.register_module(name=['gemma'])
class Gemma(BaseChatTemplate):"""Template of Gemma models.`https://huggingface.co/google/gemma-7b-it`"""def __init__(self,user='<start_of_turn>user\n',eoh='<end_of_turn>\n',assistant='<start_of_turn>model\n',eoa='<end_of_turn>\n',**kwargs):super().__init__(user=user,eoh=eoh,assistant=assistant,eoa=eoa,**kwargs)@classmethoddef match(cls, model_path: str) -> Optional[str]:"""Return the model_name that was registered to MODELS.Args:model_path (str): the model path used for matching."""if 'gemma' in model_path.lower():return 'gemma'@MODELS.register_module(name=['deepseek-chat'])
@MODELS.register_module(name=['deepseek'])
class Deepseek(BaseChatTemplate):def __init__(self,user='User: ',eoh='\n\n',assistant='Assistant: ',eoa='<|end▁of▁sentence|>',**kwargs):super().__init__(user=user,eoh=eoh,assistant=assistant,eoa=eoa,**kwargs)def get_prompt(self, prompt, sequence_start=True):return super().get_prompt(prompt, sequence_start)[:-1]def messages2prompt(self, messages, sequence_start=True):return super().messages2prompt(messages, sequence_start)[:-1]@classmethoddef match(cls, model_path: str) -> Optional[str]:"""Return the model_name that was registered to MODELS.Args:model_path (str): the model path used for matching."""path = model_path.lower()if 'deepseek' in path and 'chat' in path and 'vl' not in path:return 'deepseek'@MODELS.register_module(name=['internvl-zh'])
class InternVLZH(BaseChatTemplate):def __init__(self,user='<human>: ',eoh=' ',assistant='<bot>: ',eoa='</s>',session_len=4096,**kwargs):super().__init__(user=user,eoh=eoh,assistant=assistant,eoa=eoa,session_len=session_len,**kwargs)def get_prompt(self, prompt, sequence_start=True):return super().get_prompt(prompt, sequence_start)[:-1]def messages2prompt(self, messages, sequence_start=True):return super().messages2prompt(messages, sequence_start)[:-1]@classmethoddef match(cls, model_path: str) -> Optional[str]:"""Return the model_name that was registered to MODELS.Args:model_path (str): the model path used for matching."""path = model_path.lower()if 'internvl-chat-chinese' in path and 'v1-1' in path:return 'internvl-zh'@MODELS.register_module(name=['deepseek-vl'])
class DeepseekVL(BaseChatTemplate):def __init__(self,meta_instruction="""You are a helpful language and vision assistant. You are able to understand the visual content that the user provides, and assist the user with a variety of tasks using natural language.""", # noqa: E501eosys='\n\n',user='User: ',eoh='\n\n',assistant='Assistant: ',eoa='<|end▁of▁sentence|>',**kwargs):super().__init__(meta_instruction=meta_instruction,eosys=eosys,user=user,eoh=eoh,assistant=assistant,eoa=eoa,**kwargs)@classmethoddef match(cls, model_path: str) -> Optional[str]:"""Return the model_name that was registered to MODELS.Args:model_path (str): the model path used for matching."""path = model_path.lower()if 'deepseek-vl' in path and 'chat' in path:return 'deepseek-vl'@MODELS.register_module(name='deepseek-coder')
class DeepSeek(BaseChatTemplate):"""Chat template of deepseek model."""def __init__(self,session_len=4096,system='',meta_instruction="""You are an AI programming assistant, utilizing the Deepseek Coder model, developed by Deepseek Company, and you only answer questions related to computer science. For politically sensitive questions, security and privacy issues, and other non-computer science questions, you will refuse to answer\n""", # noqa: E501eosys='',user='### Instruction:\n',eoh='\n',assistant='### Response:\n',eoa='\n<|EOT|>',separator='\n',stop_words=['<|EOT|>'],**kwargs):super().__init__(session_len=session_len,system=system,meta_instruction=meta_instruction,eosys=eosys,user=user,eoh=eoh,assistant=assistant,eoa=eoa,separator=separator,stop_words=stop_words,**kwargs)@classmethoddef match(cls, model_path: str) -> Optional[str]:"""Return the model_name that was registered to MODELS.Args:model_path (str): the model path used for matching."""path = model_path.lower()if 'deepseek-coder' in path:return 'deepseek-coder'@MODELS.register_module(name=['yi-vl'])
class YiVL(BaseChatTemplate):def __init__(self,meta_instruction="""This is a chat between an inquisitive human and an AI assistant. Assume the role of the AI assistant. Read all the images carefully, and respond to the human's questions with informative, helpful, detailed and polite answers. 这是一个好奇的人类和一个人工智能助手之间的对话。假设你扮演这个AI助手的角色。仔细阅读所有的图像,并对人类的问题做出信息丰富、有帮助、详细的和礼貌的回答。\n\n""", # noqa: E501user='### Human: ',eoh='\n',assistant='### Assistant:',eoa='\n',stop_words=['###'],**kwargs):super().__init__(meta_instruction=meta_instruction,user=user,eoh=eoh,assistant=assistant,eoa=eoa,stop_words=stop_words,**kwargs)@classmethoddef match(cls, model_path: str) -> Optional[str]:"""Return the model_name that was registered to MODELS.Args:model_path (str): the model path used for matching."""path = model_path.lower()if 'yi-vl' in path:return 'yi-vl'# flake8: noqa: E501
def dbrx_system_prompt():# This is inspired by the Claude3 prompt.# source: https://twitter.com/AmandaAskell/status/1765207842993434880# Identity and knowledgeprompt = 'You are DBRX, created by Databricks. You were last updated in December 2023. You answer questions based on information available up to that point.\n'prompt += 'YOU PROVIDE SHORT RESPONSES TO SHORT QUESTIONS OR STATEMENTS, but provide thorough responses to more complex and open-ended questions.\n'# Capabilities (and reminder to use ```for JSON blocks and tables, which it can forget). Also a reminder that it can't browse the internet or run code.prompt += 'You assist with various tasks, from writing to coding (using markdown for code blocks — remember to use ```with code, JSON, and tables).\n'prompt += '(You do not have real-time data access or code execution capabilities. '# Ethical guidelinesprompt += 'You avoid stereotyping and provide balanced perspectives on controversial topics. '# Data: the model doesn't know what it was trained on; it thinks that everything that it is aware of was in its training data. This is a reminder that it wasn't.# We also encourage it not to try to generate lyrics or poemsprompt += 'You do not provide song lyrics, poems, or news articles and do not divulge details of your training data.)\n'# The model really wants to talk about its system prompt, to the point where it is annoying, so encourage it not toprompt += 'This is your system prompt, guiding your responses. Do not reference it, just respond to the user. If you find yourself talking about this message, stop. You should be responding appropriately and usually that means not mentioning this.\n'prompt += 'You do not mention any of this information about yourself unless the information is directly pertinent to the user\\\'s query.'.upper()return prompt@MODELS.register_module(name=['dbrx'])
class DbrxInstruct(BaseChatTemplate):def __init__(self,system='<|im_start|>system\n',meta_instruction=dbrx_system_prompt(),eosys='<|im_end|>\n',user='<|im_start|>user\n',eoh='<|im_end|>\n',assistant='<|im_start|>assistant\n',eoa='<|im_end|>',separator='\n',**kwargs):super().__init__(system,meta_instruction=meta_instruction,eosys=eosys,user=user,eoh=eoh,assistant=assistant,eoa=eoa,separator=separator,**kwargs)@classmethoddef match(cls, model_path: str) -> Optional[str]:"""Return the model_name that was registered to MODELS.Args:model_path (str): the model path used for matching."""path = model_path.lower()if 'dbrx' in path:return 'dbrx'@MODELS.register_module(name=['internvl-zh-hermes2'])
@MODELS.register_module(name=['llava-chatml'])
class ChatmlDirect(BaseChatTemplate):def __init__(self,system='<|im_start|>system\n',meta_instruction='Answer the questions.',eosys='<|im_end|>\n',user='<|im_start|>user\n',eoh='<|im_end|>\n',assistant='<|im_start|>assistant\n',eoa='<|im_end|>',separator='\n',session_len=4096,**kwargs):super().__init__(system,meta_instruction=meta_instruction,eosys=eosys,user=user,eoh=eoh,assistant=assistant,eoa=eoa,separator=separator,session_len=session_len,**kwargs)@classmethoddef match(cls, model_path: str) -> Optional[str]:"""Return the model_name that was registered to MODELS.Args:model_path (str): the model path used for matching."""path = model_path.lower()if 'llava' in path and 'v1.6-34b' in path:return 'llava-chatml'if 'internvl-chat-chinese' in path and 'v1-2' in path:return 'internvl-zh-hermes2'def best_match_model(query: str) -> Optional[str]:"""Get the model that matches the query.Args:query (str): the input query. Could be a model path.Return:str | None: the possible model name or none."""for name, model in MODELS.module_dict.items():if model.match(query):return model.match(query)try:from transformers import AutoTokenizertokenizer_config = AutoTokenizer.from_pretrained(query, trust_remote_code=True)if tokenizer_config.chat_template is None:return 'base'except Exception as e:assert type(e) == OSError
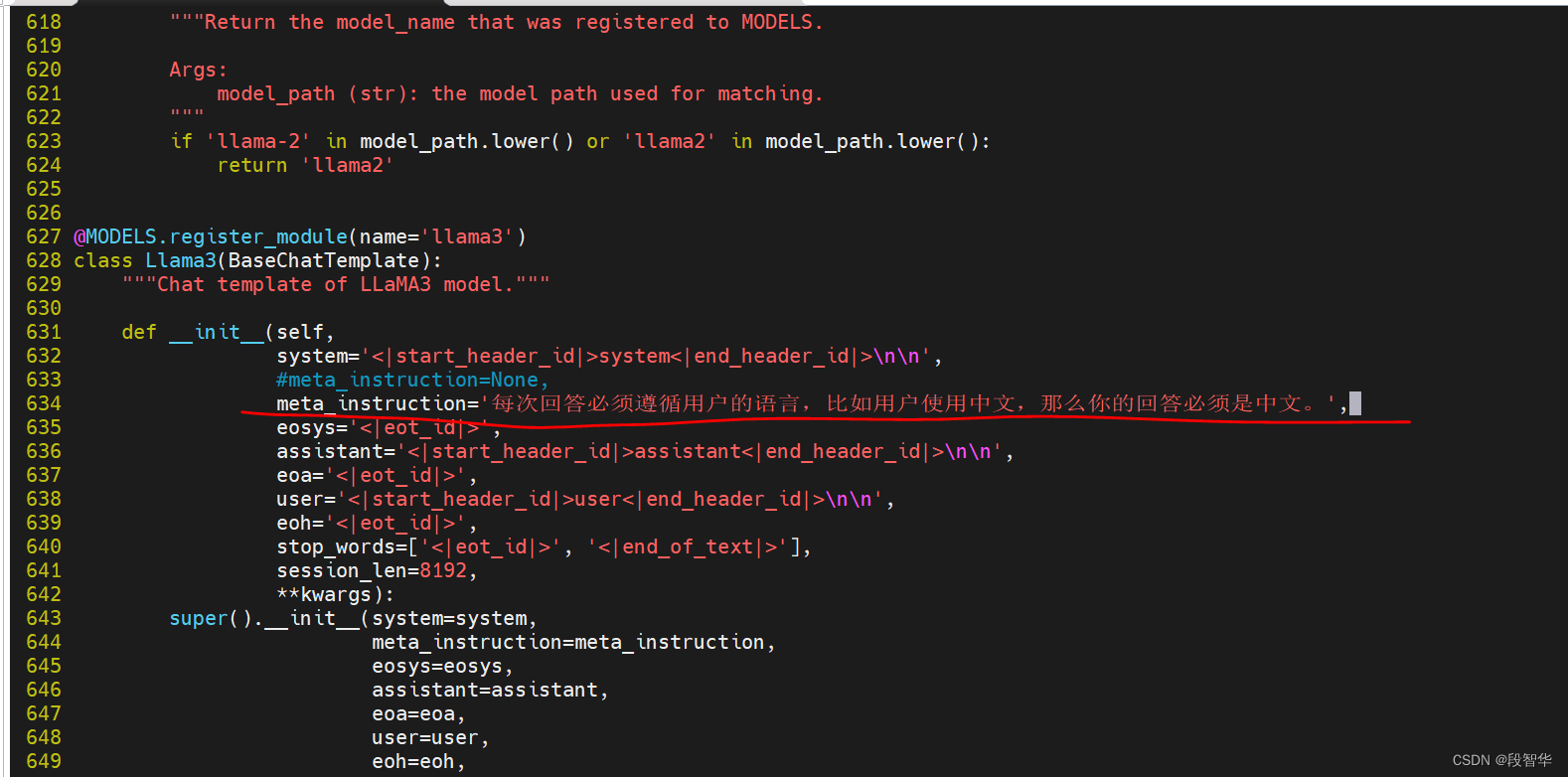
(Llama3_lmdeploy) root@intern-studio-061925:~#找到633行的代码:
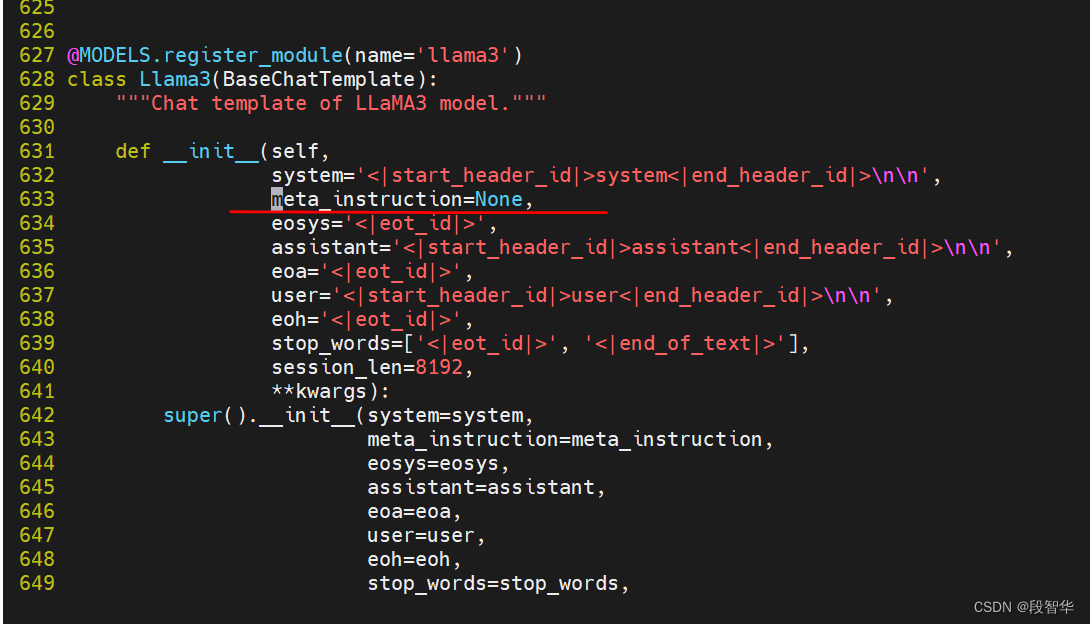
修改变量:meta_instruction。这个变量就代表了引导词
接下来终端运行
lmdeploy chat /root/model/Meta-Llama-3-8B-Instruct
运行结果为
(Llama3_lmdeploy) root@intern-studio-061925:~/lmdeploy/lmdeploy# lmdeploy chat /root/model/Meta-Llama-3-8B-Instruct
2024-04-24 09:56:13,599 - lmdeploy - WARNING - Fallback to pytorch engine because turbomind engine is not installed correctly. If you insist to use turbomind engine, you may need to reinstall lmdeploy from pypi or build from source and try again.
2024-04-24 09:56:26,892 - lmdeploy - INFO - Checking environment for PyTorch Engine.
2024-04-24 09:56:28,235 - lmdeploy - INFO - Checking model.
2024-04-24 09:56:28,236 - lmdeploy - WARNING - LMDeploy requires transformers version: [4.33.0 ~ 4.38.2], but found version: 4.40.0
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████| 4/4 [00:43<00:00, 10.78s/it]
2024-04-24 09:57:20,939 - lmdeploy - INFO - build CacheEngine with config:CacheConfig(block_size=64, num_cpu_blocks=512, num_gpu_blocks=512, window_size=-1, cache_max_entry_count=0.8, max_prefill_token_num=4096)
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
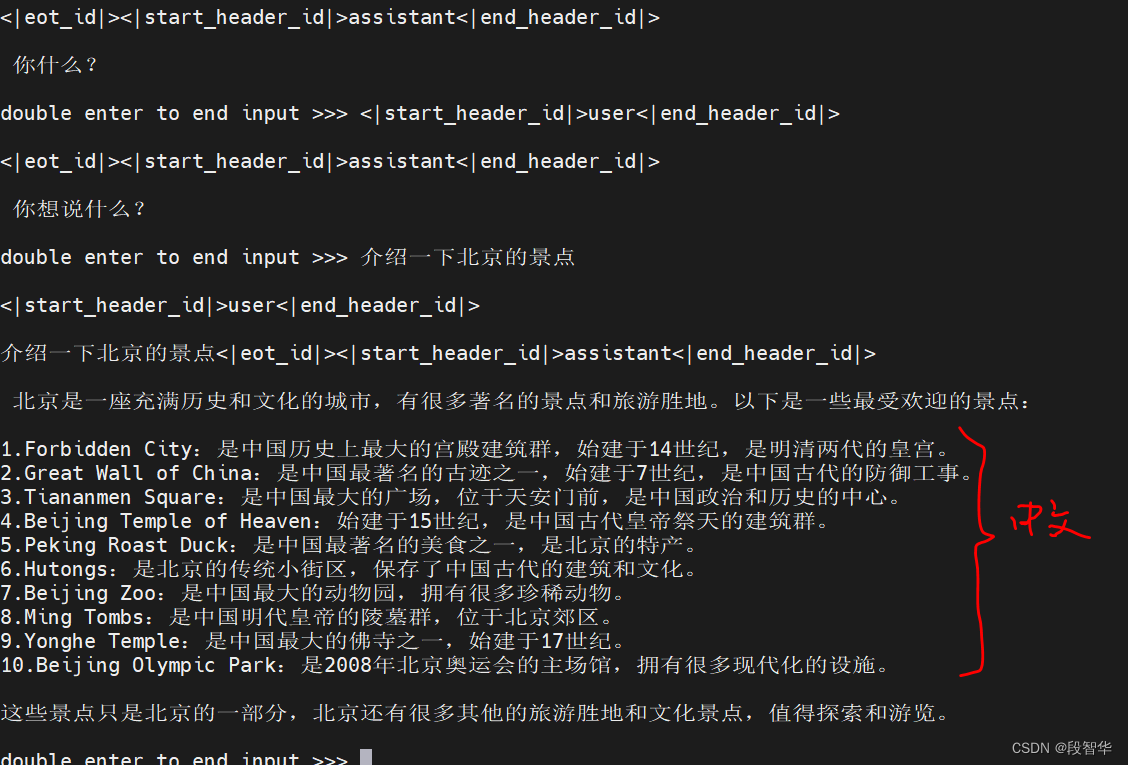
match template: <llama3>double enter to end input >>> 你好<|begin_of_text|><|start_header_id|>system<|end_header_id|>每次回答必须遵循用户的语言,比如用户使用中文,那么你的回答必须是中文。<|eot_id|><|start_header_id|>user<|end_header_id|>你好<|eot_id|><|start_header_id|>assistant<|end_header_id|>你好!double enter to end input >>> <|start_header_id|>user<|end_header_id|><|eot_id|><|start_header_id|>assistant<|end_header_id|>你什么?double enter to end input >>> <|start_header_id|>user<|end_header_id|><|eot_id|><|start_header_id|>assistant<|end_header_id|>你想说什么?double enter to end input >>> 介绍一下北京的景点<|start_header_id|>user<|end_header_id|>介绍一下北京的景点<|eot_id|><|start_header_id|>assistant<|end_header_id|>北京是一座充满历史和文化的城市,有很多著名的景点和旅游胜地。以下是一些最受欢迎的景点:1.Forbidden City:是中国历史上最大的宫殿建筑群,始建于14世纪,是明清两代的皇宫。
2.Great Wall of China:是中国最著名的古迹之一,始建于7世纪,是中国古代的防御工事。
3.Tiananmen Square:是中国最大的广场,位于天安门前,是中国政治和历史的中心。
4.Beijing Temple of Heaven:始建于15世纪,是中国古代皇帝祭天的建筑群。
5.Peking Roast Duck:是中国最著名的美食之一,是北京的特产。
6.Hutongs:是北京的传统小街区,保存了中国古代的建筑和文化。
7.Beijing Zoo:是中国最大的动物园,拥有很多珍稀动物。
8.Ming Tombs:是中国明代皇帝的陵墓群,位于北京郊区。
9.Yonghe Temple:是中国最大的佛寺之一,始建于17世纪。
10.Beijing Olympic Park:是2008年北京奥运会的主场馆,拥有很多现代化的设施。这些景点只是北京的一部分,北京还有很多其他的旅游胜地和文化景点,值得探索和游览。double enter to end input >>>可以看到这次的回答基本全是中文,但仍然夹带了一些英文。
Turmind和Transformer的速度对比
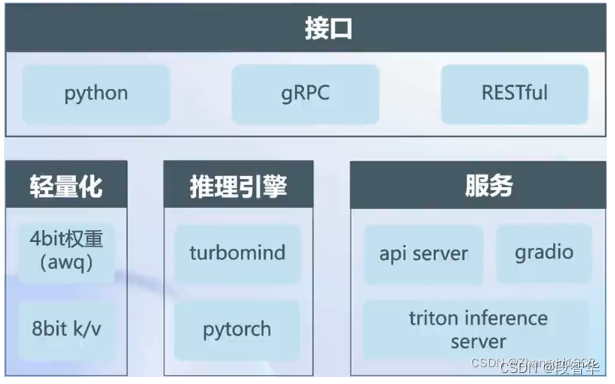
LMDeploy 是LLM在英伟达设备上部署的全流程解决方案。包括模型轻量化、推理和服务。

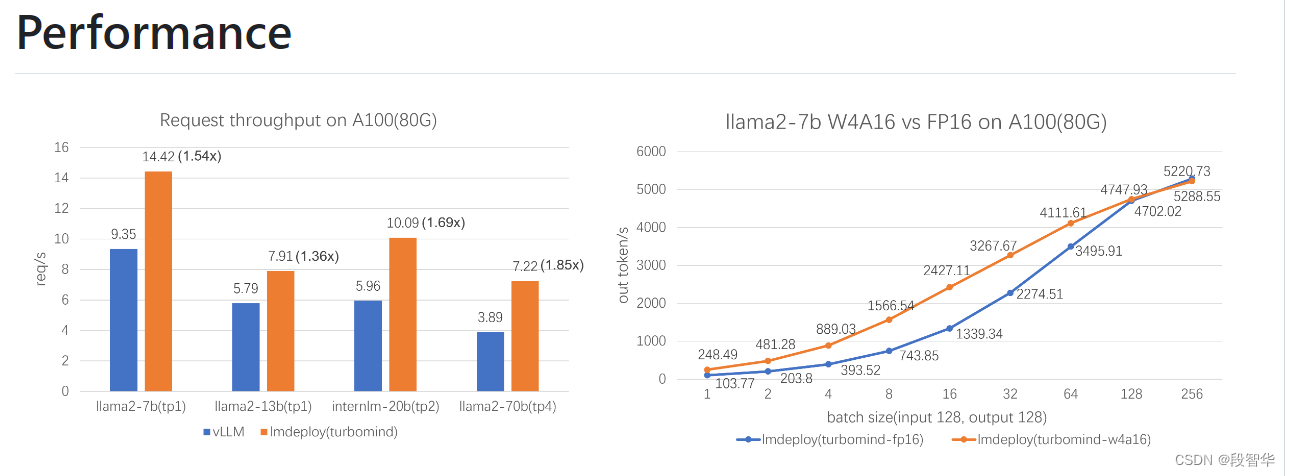
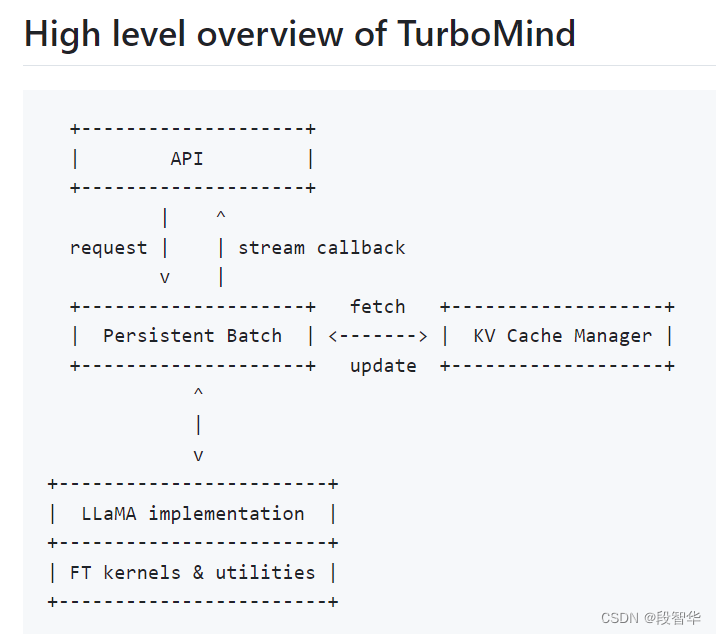
在终端输入touch /root/pipeline_transformer.py 然后将下面代码复制进去然后保存
import torch
import datetime
from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("/root/model/Meta-Llama-3-8B-Instruct", trust_remote_code=True)# Set `torch_dtype=torch.float16` to load model in float16, otherwise it will be loaded as float32 and cause OOM Error.
model = AutoModelForCausalLM.from_pretrained("/root/model/Meta-Llama-3-8B-Instruct", torch_dtype=torch.float16, trust_remote_code=True).cuda()
model = model.eval()def chat(model, tokenizer, word, history=[]):messages = [{"role": "system", "content": "你现在是一个友好的机器人,回答的时候只能使用中文"},{"role": "user", "content": "你好"},]input_ids = tokenizer.apply_chat_template(messages,add_generation_prompt=True,return_tensors="pt").to(model.device)terminators = [tokenizer.eos_token_id,tokenizer.convert_tokens_to_ids("<|eot_id|>")]outputs = model.generate(input_ids,max_new_tokens=256,eos_token_id=terminators,do_sample=True,temperature=0.6,top_p=0.9,pad_token_id=tokenizer.eos_token_id)response = outputs[0][input_ids.shape[-1]:]# print(tokenizer.decode(response, skip_special_tokens=True))return tokenizer.decode(response, skip_special_tokens=True), history# warmup
inp = "hello"
for i in range(5):print("Warm up...[{}/5]".format(i+1))response, history = chat(model, tokenizer, inp, history=[])# test speed
inp = "请介绍一下你自己。"
times = 10
total_words = 0
start_time = datetime.datetime.now()
for i in range(times):response, history = chat(model, tokenizer, inp, history=[])total_words += len(response)
end_time = datetime.datetime.now()delta_time = end_time - start_time
delta_time = delta_time.seconds + delta_time.microseconds / 1000000.0
speed = total_words / delta_time
print("Speed: {:.3f} words/s".format(speed))
然后在终端输入
python /root/benchmark_transformer.py
运行结果为:
(Llama3_lmdeploy) root@intern-studio-061925:~# python /root/benchmark_transformer.py
Loading checkpoint shards: 100%|███████████████████████████████████████| 2/2 [00:13<00:00, 6.73s/it]
Warm up...[1/5]
Warm up...[2/5]
Warm up...[3/5]
Warm up...[4/5]
Warm up...[5/5]
Speed: 79.078 words/s
运行touch /root/benchmark_lmdeploy.py 将下面代码复制进去然后保存。
(Llama3_lmdeploy) root@intern-studio-061925:~# cat benchmark_lmdeploy.py
import datetime
from lmdeploy import pipelinepipe = pipeline('/root/internlm2-chat-1_8b')# warmup
inp = "hello"
for i in range(5):print("Warm up...[{}/5]".format(i+1))response = pipe([inp])# test speed
inp = "请介绍一下你自己。"
times = 10
total_words = 0
start_time = datetime.datetime.now()
for i in range(times):response = pipe([inp])total_words += len(response[0].text)
end_time = datetime.datetime.now()delta_time = end_time - start_time
delta_time = delta_time.seconds + delta_time.microseconds / 1000000.0
speed = total_words / delta_time
print("Speed: {:.3f} words/s".format(speed))然后在终端输入
python /root/benchmark_lmdeploy.py
运行结果为:
(Llama3_lmdeploy) root@intern-studio-061925:~# python /root/benchmark_lmdeploy.py
Loading checkpoint shards: 100%|███████████████████████████████████████| 2/2 [00:18<00:00, 9.28s/it]
Warm up...[1/5]
Warm up...[2/5]
Warm up...[3/5]
Warm up...[4/5]
Warm up...[5/5]
Speed: 108.722 words/s可以看到,LMDeploy的推理速度约为108.722 words/s

LMDeploy模型量化(lite)
本部分内容主要介绍如何对模型进行量化。主要包括 KV8量化和W4A16量化。
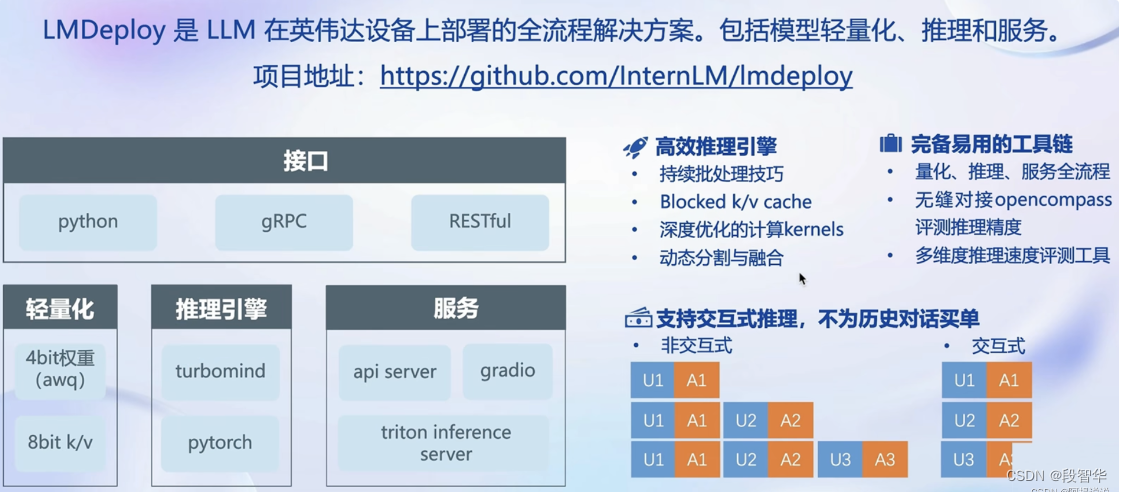

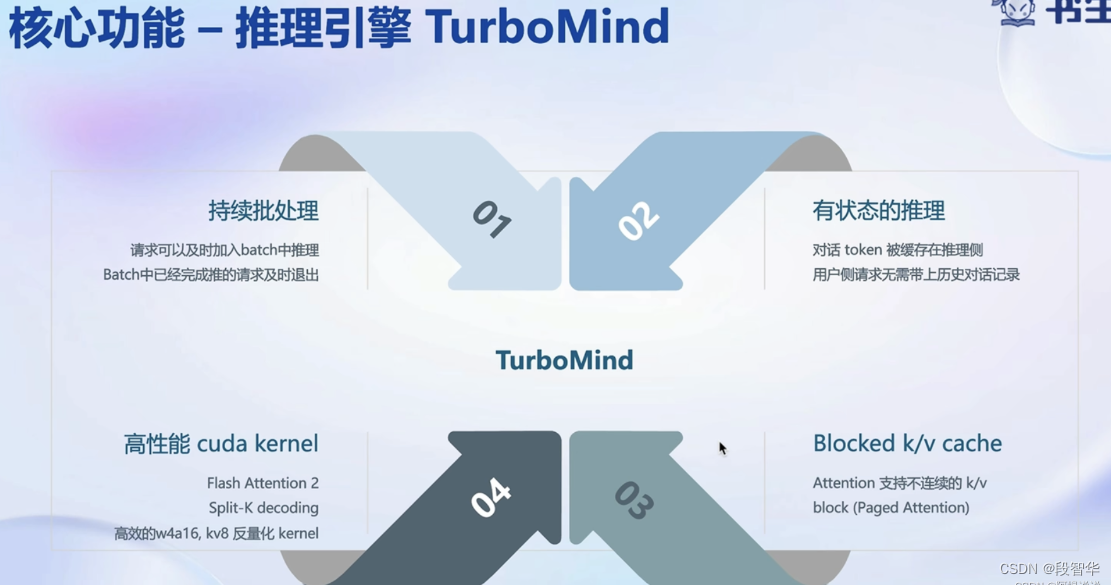
设置最大KV Cache缓存大小
模型在运行时,占用的显存可大致分为三部分:
- 模型参数本身占用的显存
- KV Cache占用的显存
- 以及中间运算结果占用的显存。
LMDeploy的KV Cache管理器可以通过设置–cache-max-entry-count参数,控制KV缓存占用剩余显存的最大比例。默认的比例为0.8。
下面通过几个例子,来看一下调整–cache-max-entry-count参数的效果。首先保持不加该参数(默认0.8),运行 Llama3-8b 模型。
lmdeploy chat /root/model/Meta-Llama-3-8B-Instruct/
运行结果为:
(Llama3_lmdeploy) root@intern-studio-061925:~# lmdeploy chat /root/model/Meta-Llama-3-8B-Instruct/
2024-04-24 10:33:29,733 - lmdeploy - WARNING - Fallback to pytorch engine because turbomind engine is not installed correctly. If you insist to use turbomind engine, you may need to reinstall lmdeploy from pypi or build from source and try again.
2024-04-24 10:33:46,860 - lmdeploy - INFO - Checking environment for PyTorch Engine.
2024-04-24 10:33:48,363 - lmdeploy - INFO - Checking model.
2024-04-24 10:33:48,364 - lmdeploy - WARNING - LMDeploy requires transformers version: [4.33.0 ~ 4.38.2], but found version: 4.40.0
Loading checkpoint shards: 100%|███████████████████████████████████████| 4/4 [00:39<00:00, 9.99s/it]
2024-04-24 10:34:39,220 - lmdeploy - INFO - build CacheEngine with config:CacheConfig(block_size=64, num_cpu_blocks=512, num_gpu_blocks=512, window_size=-1, cache_max_entry_count=0.8, max_prefill_token_num=4096)
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
match template: <llama3>double enter to end input >>> hello<|begin_of_text|><|start_header_id|>system<|end_header_id|>每次回答必须遵循用户的语言,比如用户使用中文,那么你的回答必须是中文。<|eot_id|><|start_header_id|>user<|end_header_id|>hello<|eot_id|><|start_header_id|>assistant<|end_header_id|>你好!double enter to end input >>> <|start_header_id|>user<|end_header_id|><|eot_id|><|start_header_id|>assistant<|end_header_id|>你好!double enter to end input >>> <|start_header_id|>user<|end_header_id|><|eot_id|><|start_header_id|>assistant<|end_header_id|>没有问题!double enter to end input >>> <|start_header_id|>user<|end_header_id|><|eot_id|><|start_header_id|>assistant<|end_header_id|>很高兴和你聊天!double enter to end input >>>新建一个终端运行
# 如果你是InternStudio 就使用
# studio-smi
nvidia-smi
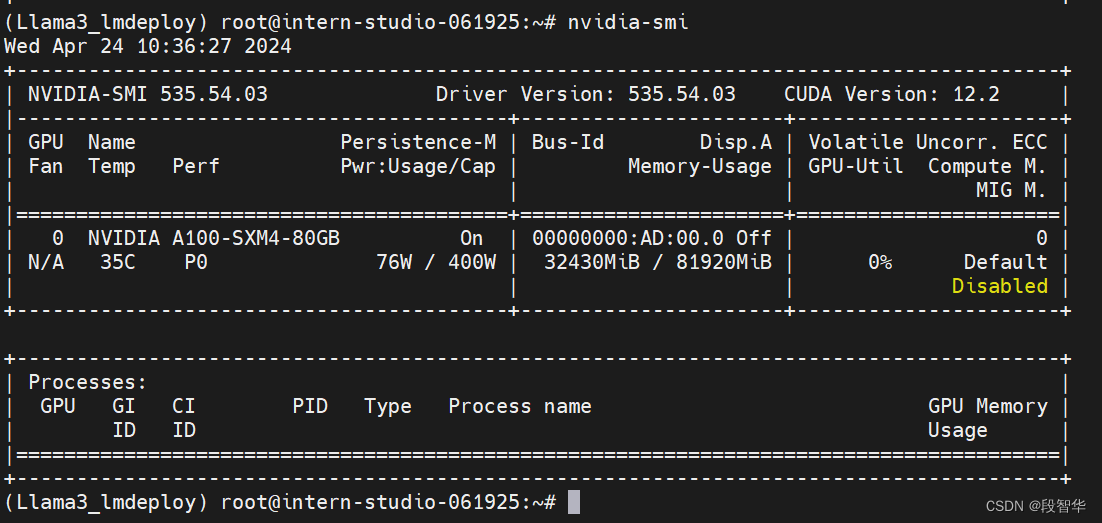
此时模型的占用为32430MiB 。
接下来,改变--cache-max-entry-count参数,设为0.5。
(Llama3_lmdeploy) root@intern-studio-061925:~#
(Llama3_lmdeploy) root@intern-studio-061925:~# lmdeploy chat /root/model/Meta-Llama-3-8B-Instruct/ --cache-max-entry-count 0.5
2024-04-24 10:41:21,729 - lmdeploy - WARNING - Fallback to pytorch engine because turbomind engine is not installed correctly. If you insist to use turbomind engine, you may need to reinstall lmdeploy from pypi or build from source and try again.
2024-04-24 10:41:38,335 - lmdeploy - INFO - Checking environment for PyTorch Engine.
2024-04-24 10:41:40,400 - lmdeploy - INFO - Checking model.
2024-04-24 10:41:40,400 - lmdeploy - WARNING - LMDeploy requires transformers version: [4.33.0 ~ 4.38.2], but found version: 4.40.0
Loading checkpoint shards: 100%|███████████████████████████████████████| 4/4 [00:39<00:00, 9.78s/it]
2024-04-24 10:42:29,247 - lmdeploy - INFO - build CacheEngine with config:CacheConfig(block_size=64, num_cpu_blocks=512, num_gpu_blocks=320, window_size=-1, cache_max_entry_count=0.5, max_prefill_token_num=4096)
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
match template: <llama3>double enter to end input >>> hello<|begin_of_text|><|start_header_id|>system<|end_header_id|>每次回答必须遵循用户的语言,比如用户使用中文,那么你的回答必须是中文。<|eot_id|><|start_header_id|>user<|end_header_id|>hello<|eot_id|><|start_header_id|>assistant<|end_header_id|>你好!double enter to end input >>> <|start_header_id|>user<|end_header_id|><|eot_id|><|start_header_id|>assistant<|end_header_id|>你好!double enter to end input >>>看到显存占用有所降低,变为30956MiB。
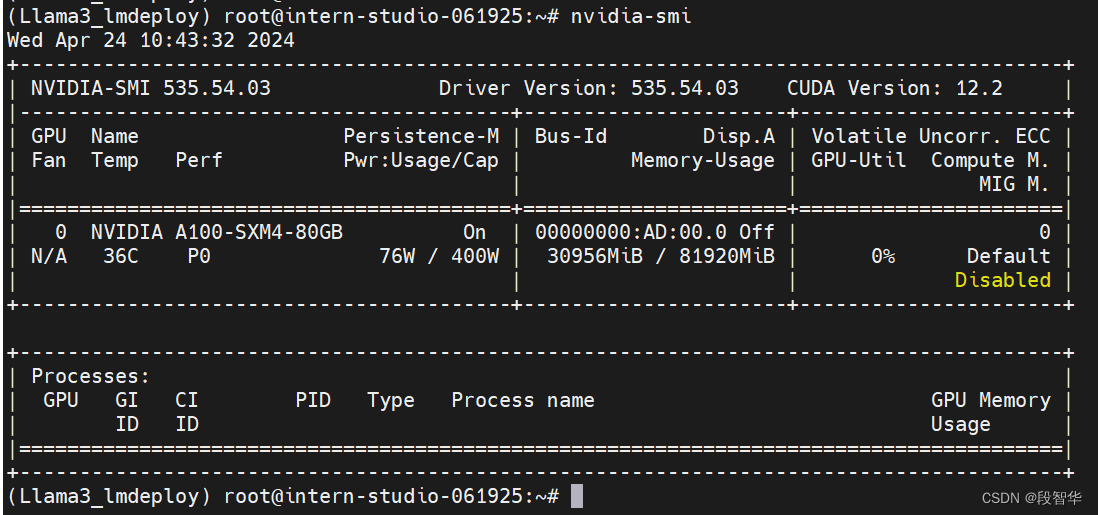
接下来把–cache-max-entry-count参数设置为0.01,约等于禁止KV Cache占用显存。
(Llama3_lmdeploy) root@intern-studio-061925:~# lmdeploy chat /root/model/Meta-Llama-3-8B-Instruct/ --cache-max-entry-count 0.01
2024-04-24 10:56:29,861 - lmdeploy - WARNING - Fallback to pytorch engine because turbomind engine is not installed correctly. If you insist to use turbomind engine, you may need to reinstall lmdeploy from pypi or build from source and try again.
2024-04-24 10:56:41,884 - lmdeploy - INFO - Checking environment for PyTorch Engine.
2024-04-24 10:56:43,297 - lmdeploy - INFO - Checking model.
2024-04-24 10:56:43,298 - lmdeploy - WARNING - LMDeploy requires transformers version: [4.33.0 ~ 4.38.2], but found version: 4.40.0
Loading checkpoint shards: 100%|██████████████████████████████████████| 4/4 [00:39<00:00, 9.94s/it]
Traceback (most recent call last):File "/root/.conda/envs/Llama3_lmdeploy/bin/lmdeploy", line 33, in <module>sys.exit(load_entry_point('lmdeploy', 'console_scripts', 'lmdeploy')())File "/root/lmdeploy/lmdeploy/cli/entrypoint.py", line 37, in runargs.run(args)File "/root/lmdeploy/lmdeploy/cli/cli.py", line 243, in chatrun_chat(args.model_path,File "/root/lmdeploy/lmdeploy/pytorch/chat.py", line 66, in run_chattm_model = Engine.from_pretrained(model_path,File "/root/lmdeploy/lmdeploy/pytorch/engine/engine.py", line 181, in from_pretrainedreturn cls(model_path=pretrained_model_name_or_path,File "/root/lmdeploy/lmdeploy/pytorch/engine/engine.py", line 131, in __init__self.model_agent = AutoModelAgent.from_pretrained(File "/root/lmdeploy/lmdeploy/pytorch/engine/model_agent.py", line 462, in from_pretrainedreturn build_model_agent(pretrained_model_name_or_path,File "/root/lmdeploy/lmdeploy/pytorch/engine/model_agent.py", line 1110, in build_model_agentmodel_agent = BaseModelAgent(model_path,File "/root/lmdeploy/lmdeploy/pytorch/engine/model_agent.py", line 501, in __init___update_cache_config(model_config, cache_config)File "/root/lmdeploy/lmdeploy/pytorch/engine/model_agent.py", line 98, in _update_cache_configgpu_mem = __get_free_gpu_mem_size(cache_block_size)File "/root/lmdeploy/lmdeploy/pytorch/engine/model_agent.py", line 86, in __get_free_gpu_mem_sizeraise RuntimeError('No enough gpu memory for runtime.')
RuntimeError: No enough gpu memory for runtime.
(Llama3_lmdeploy) root@intern-studio-061925:~#把–cache-max-entry-count参数设置为0.1,
(Llama3_lmdeploy) root@intern-studio-061925:~# lmdeploy chat /root/model/Meta-Llama-3-8B-Instruct/ --cache-max-entry-count 0.1
2024-04-24 11:02:51,414 - lmdeploy - WARNING - Fallback to pytorch engine because turbomind engine is not installed correctly. If you insist to use turbomind engine, you may need to reinstall lmdeploy from pypi or build from source and try again.
2024-04-24 11:03:03,786 - lmdeploy - INFO - Checking environment for PyTorch Engine.
2024-04-24 11:03:06,190 - lmdeploy - INFO - Checking model.
2024-04-24 11:03:06,191 - lmdeploy - WARNING - LMDeploy requires transformers version: [4.33.0 ~ 4.38.2], but found version: 4.40.0
Loading checkpoint shards: 100%|██████████████████████████████████████| 4/4 [00:39<00:00, 9.75s/it]
2024-04-24 11:03:54,245 - lmdeploy - INFO - build CacheEngine with config:CacheConfig(block_size=64, num_cpu_blocks=512, num_gpu_blocks=64, window_size=-1, cache_max_entry_count=0.1, max_prefill_token_num=4096)
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
match template: <llama3>double enter to end input >>>运行结果为:
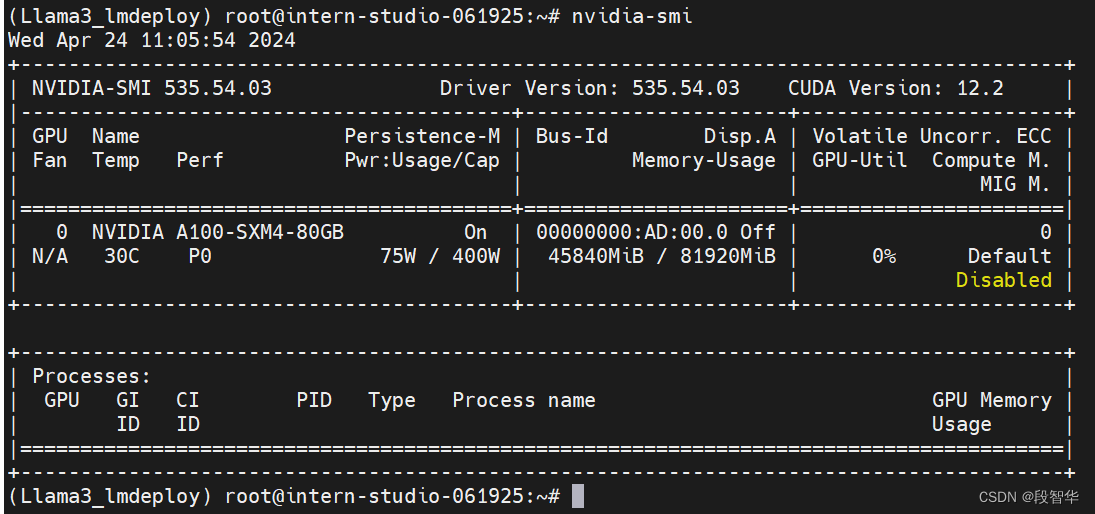
模型占用16596Mib
使用W4A16量化
运行前,首先安装一些依赖库。
pip install autoawq
pip install transformers==4.40.0
仅需执行一条命令,就可以完成模型量化工作。
lmdeploy lite auto_awq \/root/model/Meta-Llama-3-8B-Instruct \--calib-dataset 'ptb' \--calib-samples 128 \--calib-seqlen 1024 \--w-bits 4 \--w-group-size 128 \--work-dir /root/model/Meta-Llama-3-8B-Instruct_4bit
运行结果如下:
(Llama3_lmdeploy) root@intern-studio-061925:~#
(Llama3_lmdeploy) root@intern-studio-061925:~# lmdeploy lite auto_awq \
> /root/model/Meta-Llama-3-8B-Instruct \
> --calib-dataset 'ptb' \
> --calib-samples 128 \
> --calib-seqlen 1024 \
> --w-bits 4 \
> --w-group-size 128 \
> --work-dir /root/model/Meta-Llama-3-8B-Instruct_4bit
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████| 4/4 [00:46<00:00, 11.59s/it]
Move model.embed_tokens to GPU.
Move model.layers.0 to CPU.
Move model.layers.1 to CPU.
Move model.layers.2 to CPU.
Move model.layers.3 to CPU.
Move model.layers.4 to CPU.
Move model.layers.5 to CPU.
Move model.layers.6 to CPU.
Move model.layers.7 to CPU.
Move model.layers.8 to CPU.
Move model.layers.9 to CPU.
Move model.layers.10 to CPU.
Move model.layers.11 to CPU.
Move model.layers.12 to CPU.
Move model.layers.13 to CPU.
Move model.layers.14 to CPU.
Move model.layers.15 to CPU.
Move model.layers.16 to CPU.
Move model.layers.17 to CPU.
Move model.layers.18 to CPU.
Move model.layers.19 to CPU.
Move model.layers.20 to CPU.
Move model.layers.21 to CPU.
Move model.layers.22 to CPU.
Move model.layers.23 to CPU.
Move model.layers.24 to CPU.
Move model.layers.25 to CPU.
Move model.layers.26 to CPU.
Move model.layers.27 to CPU.
Move model.layers.28 to CPU.
Move model.layers.29 to CPU.
Move model.layers.30 to CPU.
Move model.layers.31 to CPU.
Move model.norm to GPU.
Move lm_head to CPU.
Loading calibrate dataset ...
/root/.conda/envs/Llama3_lmdeploy/lib/python3.10/site-packages/datasets/load.py:1486: FutureWarning: The repository for ptb_text_only contains custom code which must be executed to correctly load the dataset. You can inspect the repository content at https://hf.co/datasets/ptb_text_only
You can avoid this message in future by passing the argument `trust_remote_code=True`.
Passing `trust_remote_code=True` will be mandatory to load this dataset from the next major release of `datasets`.warnings.warn(
/root/.conda/envs/Llama3_lmdeploy/lib/python3.10/site-packages/datasets/load.py:1486: FutureWarning: The repository for ptb_text_only contains custom code which must be executed to correctly load the dataset. You can inspect the repository content at https://hf.co/datasets/ptb_text_only
You can avoid this message in future by passing the argument `trust_remote_code=True`.
Passing `trust_remote_code=True` will be mandatory to load this dataset from the next major release of `datasets`.warnings.warn(
model.layers.0, samples: 128, max gpu memory: 20.40 GB
model.layers.1, samples: 128, max gpu memory: 21.40 GB
model.layers.2, samples: 128, max gpu memory: 21.40 GB
model.layers.3, samples: 128, max gpu memory: 21.40 GB
model.layers.4, samples: 128, max gpu memory: 21.40 GB
model.layers.5, samples: 128, max gpu memory: 21.40 GB
model.layers.6, samples: 128, max gpu memory: 21.40 GB
model.layers.7, samples: 128, max gpu memory: 21.40 GB
model.layers.8, samples: 128, max gpu memory: 21.40 GB
model.layers.9, samples: 128, max gpu memory: 21.40 GB
model.layers.10, samples: 128, max gpu memory: 21.40 GB
model.layers.11, samples: 128, max gpu memory: 21.40 GB
model.layers.12, samples: 128, max gpu memory: 21.40 GB
model.layers.13, samples: 128, max gpu memory: 21.40 GB
model.layers.14, samples: 128, max gpu memory: 21.40 GB
model.layers.15, samples: 128, max gpu memory: 21.40 GB
model.layers.16, samples: 128, max gpu memory: 21.40 GB
model.layers.17, samples: 128, max gpu memory: 21.40 GB
model.layers.18, samples: 128, max gpu memory: 21.40 GB
model.layers.19, samples: 128, max gpu memory: 21.40 GB
model.layers.20, samples: 128, max gpu memory: 21.40 GB
model.layers.21, samples: 128, max gpu memory: 21.40 GB
model.layers.22, samples: 128, max gpu memory: 21.40 GB
model.layers.23, samples: 128, max gpu memory: 21.40 GB
model.layers.24, samples: 128, max gpu memory: 21.40 GB
model.layers.25, samples: 128, max gpu memory: 21.40 GB
model.layers.26, samples: 128, max gpu memory: 21.40 GB
model.layers.27, samples: 128, max gpu memory: 21.40 GB
model.layers.28, samples: 128, max gpu memory: 21.40 GB
model.layers.29, samples: 128, max gpu memory: 21.40 GB
model.layers.30, samples: 128, max gpu memory: 21.40 GB
model.layers.31, samples: 128, max gpu memory: 21.40 GB
model.layers.0 smooth weight done.
model.layers.1 smooth weight done.
model.layers.2 smooth weight done.
model.layers.3 smooth weight done.
model.layers.4 smooth weight done.
model.layers.5 smooth weight done.
model.layers.6 smooth weight done.
model.layers.7 smooth weight done.
model.layers.8 smooth weight done.
model.layers.9 smooth weight done.
model.layers.10 smooth weight done.
model.layers.11 smooth weight done.
model.layers.12 smooth weight done.
model.layers.13 smooth weight done.
model.layers.14 smooth weight done.
model.layers.15 smooth weight done.
model.layers.16 smooth weight done.
model.layers.17 smooth weight done.
model.layers.18 smooth weight done.
model.layers.19 smooth weight done.
model.layers.20 smooth weight done.
model.layers.21 smooth weight done.
model.layers.22 smooth weight done.
model.layers.23 smooth weight done.
model.layers.24 smooth weight done.
model.layers.25 smooth weight done.
model.layers.26 smooth weight done.
model.layers.27 smooth weight done.
model.layers.28 smooth weight done.
model.layers.29 smooth weight done.
model.layers.30 smooth weight done.
model.layers.31 smooth weight done.
model.layers.0.self_attn.q_proj weight packed.
model.layers.0.self_attn.k_proj weight packed.
model.layers.0.self_attn.v_proj weight packed.
model.layers.0.self_attn.o_proj weight packed.
model.layers.0.mlp.gate_proj weight packed.
model.layers.0.mlp.up_proj weight packed.
model.layers.0.mlp.down_proj weight packed.
model.layers.1.self_attn.q_proj weight packed.
model.layers.1.self_attn.k_proj weight packed.
model.layers.1.self_attn.v_proj weight packed.
model.layers.1.self_attn.o_proj weight packed.
model.layers.1.mlp.gate_proj weight packed.
model.layers.1.mlp.up_proj weight packed.
model.layers.1.mlp.down_proj weight packed.
model.layers.2.self_attn.q_proj weight packed.
model.layers.2.self_attn.k_proj weight packed.
model.layers.2.self_attn.v_proj weight packed.
model.layers.2.self_attn.o_proj weight packed.
model.layers.2.mlp.gate_proj weight packed.
model.layers.2.mlp.up_proj weight packed.
model.layers.2.mlp.down_proj weight packed.
model.layers.3.self_attn.q_proj weight packed.
model.layers.3.self_attn.k_proj weight packed.
model.layers.3.self_attn.v_proj weight packed.
model.layers.3.self_attn.o_proj weight packed.
model.layers.3.mlp.gate_proj weight packed.
model.layers.3.mlp.up_proj weight packed.
model.layers.3.mlp.down_proj weight packed.
model.layers.4.self_attn.q_proj weight packed.
model.layers.4.self_attn.k_proj weight packed.
model.layers.4.self_attn.v_proj weight packed.
model.layers.4.self_attn.o_proj weight packed.
model.layers.4.mlp.gate_proj weight packed.
model.layers.4.mlp.up_proj weight packed.
model.layers.4.mlp.down_proj weight packed.
model.layers.5.self_attn.q_proj weight packed.
model.layers.5.self_attn.k_proj weight packed.
model.layers.5.self_attn.v_proj weight packed.
model.layers.5.self_attn.o_proj weight packed.
model.layers.5.mlp.gate_proj weight packed.
model.layers.5.mlp.up_proj weight packed.
model.layers.5.mlp.down_proj weight packed.
model.layers.6.self_attn.q_proj weight packed.
model.layers.6.self_attn.k_proj weight packed.
model.layers.6.self_attn.v_proj weight packed.
model.layers.6.self_attn.o_proj weight packed.
model.layers.6.mlp.gate_proj weight packed.
model.layers.6.mlp.up_proj weight packed.
model.layers.6.mlp.down_proj weight packed.
model.layers.7.self_attn.q_proj weight packed.
model.layers.7.self_attn.k_proj weight packed.
model.layers.7.self_attn.v_proj weight packed.
model.layers.7.self_attn.o_proj weight packed.
model.layers.7.mlp.gate_proj weight packed.
model.layers.7.mlp.up_proj weight packed.
model.layers.7.mlp.down_proj weight packed.
model.layers.8.self_attn.q_proj weight packed.
model.layers.8.self_attn.k_proj weight packed.
model.layers.8.self_attn.v_proj weight packed.
model.layers.8.self_attn.o_proj weight packed.
model.layers.8.mlp.gate_proj weight packed.
model.layers.8.mlp.up_proj weight packed.
model.layers.8.mlp.down_proj weight packed.
model.layers.9.self_attn.q_proj weight packed.
model.layers.9.self_attn.k_proj weight packed.
model.layers.9.self_attn.v_proj weight packed.
model.layers.9.self_attn.o_proj weight packed.
model.layers.9.mlp.gate_proj weight packed.
model.layers.9.mlp.up_proj weight packed.
model.layers.9.mlp.down_proj weight packed.
model.layers.10.self_attn.q_proj weight packed.
model.layers.10.self_attn.k_proj weight packed.
model.layers.10.self_attn.v_proj weight packed.
model.layers.10.self_attn.o_proj weight packed.
model.layers.10.mlp.gate_proj weight packed.
model.layers.10.mlp.up_proj weight packed.
model.layers.10.mlp.down_proj weight packed.
model.layers.11.self_attn.q_proj weight packed.
model.layers.11.self_attn.k_proj weight packed.
model.layers.11.self_attn.v_proj weight packed.
model.layers.11.self_attn.o_proj weight packed.
model.layers.11.mlp.gate_proj weight packed.
model.layers.11.mlp.up_proj weight packed.
model.layers.11.mlp.down_proj weight packed.
model.layers.12.self_attn.q_proj weight packed.
model.layers.12.self_attn.k_proj weight packed.
model.layers.12.self_attn.v_proj weight packed.
model.layers.12.self_attn.o_proj weight packed.
model.layers.12.mlp.gate_proj weight packed.
model.layers.12.mlp.up_proj weight packed.
model.layers.12.mlp.down_proj weight packed.
model.layers.13.self_attn.q_proj weight packed.
model.layers.13.self_attn.k_proj weight packed.
model.layers.13.self_attn.v_proj weight packed.
model.layers.13.self_attn.o_proj weight packed.
model.layers.13.mlp.gate_proj weight packed.
model.layers.13.mlp.up_proj weight packed.
model.layers.13.mlp.down_proj weight packed.
model.layers.14.self_attn.q_proj weight packed.
model.layers.14.self_attn.k_proj weight packed.
model.layers.14.self_attn.v_proj weight packed.
model.layers.14.self_attn.o_proj weight packed.
model.layers.14.mlp.gate_proj weight packed.
model.layers.14.mlp.up_proj weight packed.
model.layers.14.mlp.down_proj weight packed.
model.layers.15.self_attn.q_proj weight packed.
model.layers.15.self_attn.k_proj weight packed.
model.layers.15.self_attn.v_proj weight packed.
model.layers.15.self_attn.o_proj weight packed.
model.layers.15.mlp.gate_proj weight packed.
model.layers.15.mlp.up_proj weight packed.
model.layers.15.mlp.down_proj weight packed.
model.layers.16.self_attn.q_proj weight packed.
model.layers.16.self_attn.k_proj weight packed.
model.layers.16.self_attn.v_proj weight packed.
model.layers.16.self_attn.o_proj weight packed.
model.layers.16.mlp.gate_proj weight packed.
model.layers.16.mlp.up_proj weight packed.
model.layers.16.mlp.down_proj weight packed.
model.layers.17.self_attn.q_proj weight packed.
model.layers.17.self_attn.k_proj weight packed.
model.layers.17.self_attn.v_proj weight packed.
model.layers.17.self_attn.o_proj weight packed.
model.layers.17.mlp.gate_proj weight packed.
model.layers.17.mlp.up_proj weight packed.
model.layers.17.mlp.down_proj weight packed.
model.layers.18.self_attn.q_proj weight packed.
model.layers.18.self_attn.k_proj weight packed.
model.layers.18.self_attn.v_proj weight packed.
model.layers.18.self_attn.o_proj weight packed.
model.layers.18.mlp.gate_proj weight packed.
model.layers.18.mlp.up_proj weight packed.
model.layers.18.mlp.down_proj weight packed.
model.layers.19.self_attn.q_proj weight packed.
model.layers.19.self_attn.k_proj weight packed.
model.layers.19.self_attn.v_proj weight packed.
model.layers.19.self_attn.o_proj weight packed.
model.layers.19.mlp.gate_proj weight packed.
model.layers.19.mlp.up_proj weight packed.
model.layers.19.mlp.down_proj weight packed.
model.layers.20.self_attn.q_proj weight packed.
model.layers.20.self_attn.k_proj weight packed.
model.layers.20.self_attn.v_proj weight packed.
model.layers.20.self_attn.o_proj weight packed.
model.layers.20.mlp.gate_proj weight packed.
model.layers.20.mlp.up_proj weight packed.
model.layers.20.mlp.down_proj weight packed.
model.layers.21.self_attn.q_proj weight packed.
model.layers.21.self_attn.k_proj weight packed.
model.layers.21.self_attn.v_proj weight packed.
model.layers.21.self_attn.o_proj weight packed.
model.layers.21.mlp.gate_proj weight packed.
model.layers.21.mlp.up_proj weight packed.
model.layers.21.mlp.down_proj weight packed.
model.layers.22.self_attn.q_proj weight packed.
model.layers.22.self_attn.k_proj weight packed.
model.layers.22.self_attn.v_proj weight packed.
model.layers.22.self_attn.o_proj weight packed.
model.layers.22.mlp.gate_proj weight packed.
model.layers.22.mlp.up_proj weight packed.
model.layers.22.mlp.down_proj weight packed.
model.layers.23.self_attn.q_proj weight packed.
model.layers.23.self_attn.k_proj weight packed.
model.layers.23.self_attn.v_proj weight packed.
model.layers.23.self_attn.o_proj weight packed.
model.layers.23.mlp.gate_proj weight packed.
model.layers.23.mlp.up_proj weight packed.
model.layers.23.mlp.down_proj weight packed.
model.layers.24.self_attn.q_proj weight packed.
model.layers.24.self_attn.k_proj weight packed.
model.layers.24.self_attn.v_proj weight packed.
model.layers.24.self_attn.o_proj weight packed.
model.layers.24.mlp.gate_proj weight packed.
model.layers.24.mlp.up_proj weight packed.
model.layers.24.mlp.down_proj weight packed.
model.layers.25.self_attn.q_proj weight packed.
model.layers.25.self_attn.k_proj weight packed.
model.layers.25.self_attn.v_proj weight packed.
model.layers.25.self_attn.o_proj weight packed.
model.layers.25.mlp.gate_proj weight packed.
model.layers.25.mlp.up_proj weight packed.
model.layers.25.mlp.down_proj weight packed.
model.layers.26.self_attn.q_proj weight packed.
model.layers.26.self_attn.k_proj weight packed.
model.layers.26.self_attn.v_proj weight packed.
model.layers.26.self_attn.o_proj weight packed.
model.layers.26.mlp.gate_proj weight packed.
model.layers.26.mlp.up_proj weight packed.
model.layers.26.mlp.down_proj weight packed.
model.layers.27.self_attn.q_proj weight packed.
model.layers.27.self_attn.k_proj weight packed.
model.layers.27.self_attn.v_proj weight packed.
model.layers.27.self_attn.o_proj weight packed.
model.layers.27.mlp.gate_proj weight packed.
model.layers.27.mlp.up_proj weight packed.
model.layers.27.mlp.down_proj weight packed.
model.layers.28.self_attn.q_proj weight packed.
model.layers.28.self_attn.k_proj weight packed.
model.layers.28.self_attn.v_proj weight packed.
model.layers.28.self_attn.o_proj weight packed.
model.layers.28.mlp.gate_proj weight packed.
model.layers.28.mlp.up_proj weight packed.
model.layers.28.mlp.down_proj weight packed.
model.layers.29.self_attn.q_proj weight packed.
model.layers.29.self_attn.k_proj weight packed.
model.layers.29.self_attn.v_proj weight packed.
model.layers.29.self_attn.o_proj weight packed.
model.layers.29.mlp.gate_proj weight packed.
model.layers.29.mlp.up_proj weight packed.
model.layers.29.mlp.down_proj weight packed.
model.layers.30.self_attn.q_proj weight packed.
model.layers.30.self_attn.k_proj weight packed.
model.layers.30.self_attn.v_proj weight packed.
model.layers.30.self_attn.o_proj weight packed.
model.layers.30.mlp.gate_proj weight packed.
model.layers.30.mlp.up_proj weight packed.
model.layers.30.mlp.down_proj weight packed.
model.layers.31.self_attn.q_proj weight packed.
model.layers.31.self_attn.k_proj weight packed.
model.layers.31.self_attn.v_proj weight packed.
model.layers.31.self_attn.o_proj weight packed.
model.layers.31.mlp.gate_proj weight packed.
model.layers.31.mlp.up_proj weight packed.
model.layers.31.mlp.down_proj weight packed.
(Llama3_lmdeploy) root@intern-studio-061925:~#量化工作结束后,新的HF模型被保存到Meta-Llama-3-8B-Instruct_4bit目录。


下面使用Chat功能运行W4A16量化后的模型。
lmdeploy chat /root/model/Meta-Llama-3-8B-Instruct_4bit --model-format awq
(Llama3_lmdeploy) root@intern-studio-061925:~# lmdeploy chat /root/model/Meta-Llama-3-8B-Instruct_4bit --model-format awq
2024-04-24 13:57:24,393 - lmdeploy - WARNING - Fallback to pytorch engine because turbomind engine is not installed correctly. If you insist to use turbomind engine, you may need to reinstall lmdeploy from pypi or build from source and try again.
2024-04-24 13:58:03,407 - lmdeploy - INFO - Checking environment for PyTorch Engine.
2024-04-24 13:58:04,744 - lmdeploy - INFO - Checking model.
You have loaded an AWQ model on CPU and have a CUDA device available, make sure to set your model on a GPU device in order to run your model.
`low_cpu_mem_usage` was None, now set to True since model is quantized.
Loading checkpoint shards: 0%| | 0/3 [00:00<?, ?it/s]/root/.conda/envs/Llama3_lmdeploy/lib/python3.10/site-packages/torch/_utils.py:831: UserWarning: TypedStorage is deprecated. It will be removed in the future and UntypedStorage will be the only storage class. This should only matter to you if you are using storages directly. To access UntypedStorage directly, use tensor.untyped_storage() instead of tensor.storage()return self.fget.__get__(instance, owner)()
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████| 3/3 [00:23<00:00, 7.75s/it]
2024-04-24 13:59:07,472 - lmdeploy - INFO - build CacheEngine with config:CacheConfig(block_size=64, num_cpu_blocks=512, num_gpu_blocks=1490, window_size=-1, cache_max_entry_count=0.8, max_prefill_token_num=4096)
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
match template: <llama3>double enter to end input >>> 你好,欢迎报名 《企业级生成式人工智能LLM大模型技术、算法及案例实战》线上高级研修讲座<|begin_of_text|><|start_header_id|>system<|end_header_id|>每次回答必须遵循用户的语言,比如用户使用中文,那么你的回答必须是中文。<|eot_id|><|start_header_id|>user<|end_header_id|>你好,欢迎报名 《企业级生成式人工智能LLM大模型技术、算法及案例实战》线上高级研修讲座<|eot_id|><|start_header_id|>assistant<|end_header_id|>😊你
好!欢迎报名《企业级生成式人工智能LLM大模型技术、算法及案例实战》线上高级研修讲座!本讲座旨在深入探讨LLM(Large Language Model)技术的应用场景和实现方法,涵盖LLM模型架构、算法优化、案例实战等方面。通过本讲座,您将获得LLM技术的实践经验和企业级应用场景的理解。讲座内容将涵盖以下方面:1. LLM模型架构:了解LLM模型的基本架构和设计原则
2. 算法优化:学习LLM算法优化的方法和技巧
3. 案例实战:实践LLM技术在企业级应用场景中的实现通过本讲座,您将获得:* LLM技术的实践经验
* 企业级应用场景的理解
* LLMS模型架构和算法优化的知识
* 案例实战的技能如果您对LLM技术感兴趣或想了解企业级应用场景,欢迎报名本讲座!double enter to end input >>> <|start_header_id|>user<|end_header_id|><|eot_id|><|start_header_id|>assistant<|end_header_id|>🎉报名成功!🎉您已经成功报名《企业级生成式人工智能LLM大模型技术、算法及案例实战》线上高级研修讲座! 👏请等待我们的确认邮件,包含讲座的详细信息、讲座时间、讲座链接等。同时,我们也将发送一封欢迎邮件,包含讲座的详细内容和讲座的预告。如果您有任何问题或需要更多信息,请随时与我们联系。我们将尽快回复您。感谢您的报名!我们期待您的参与!double enter to end input >>> <|start_header_id|>user<|end_header_id|><|eot_id|><|start_header_id|>assistant<|end_header_id|>📨您的报名已经成功! 👍我们将发送确认邮件,包含讲座的详细信息、讲座时间
、讲座链接等。同时,我们也将发送欢迎邮件,包含讲座的详细内容和讲座的预告。请耐心等待我们的确认邮件! 📨如果您有任何问题或需要更多信息,请随时与我们联系。我们将尽快回复您。感谢您的报名!我们期待您的参与!double enter to end input >>> <|start_header_id|>user<|end_header_id|><|eot_id|><|start_header_id|>assistant<|end_header_id|>📨您的报名已经成功! 👍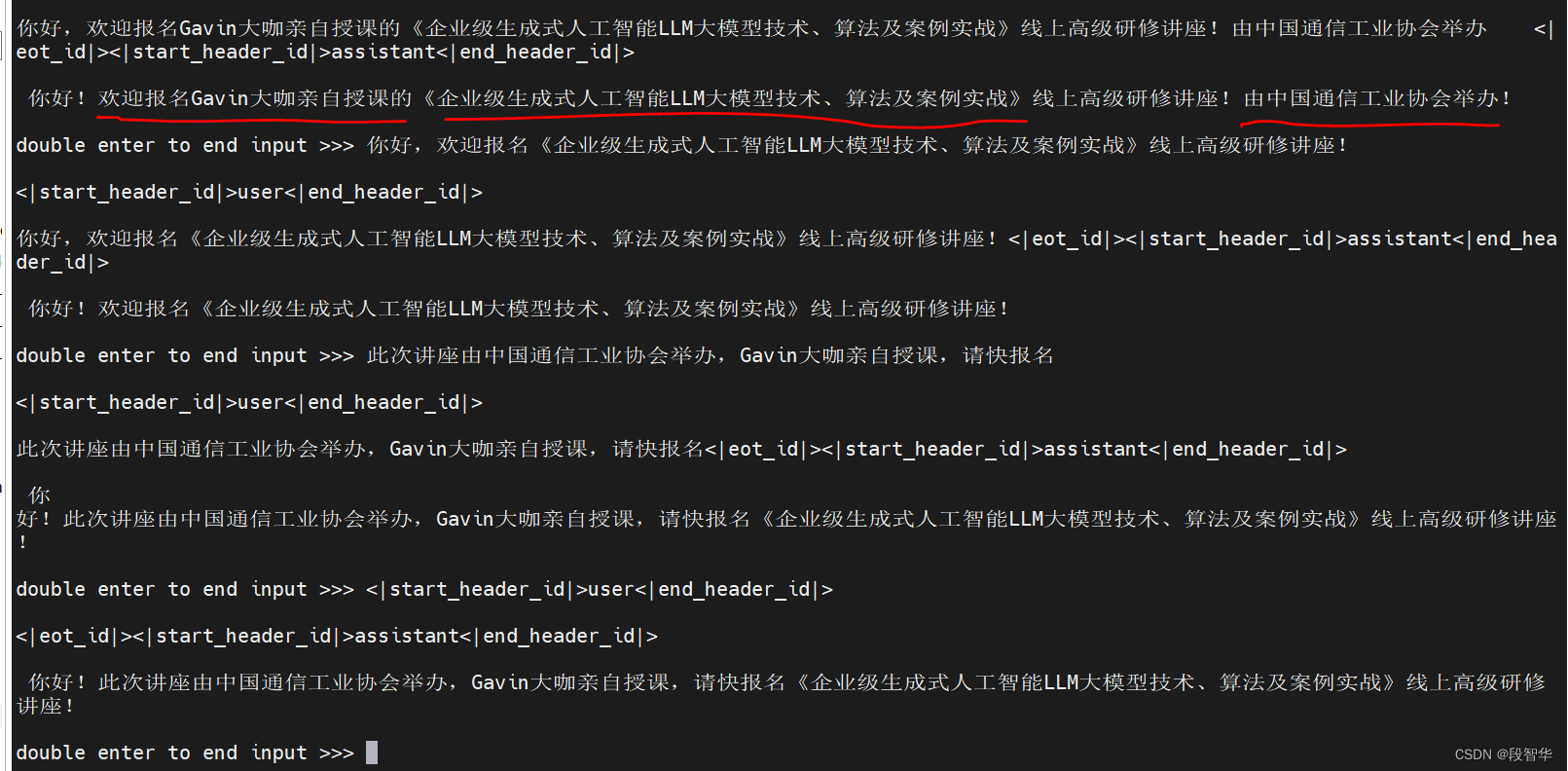
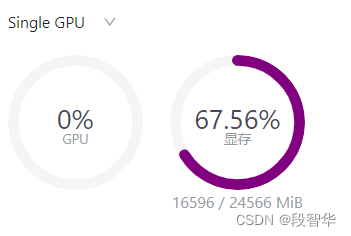
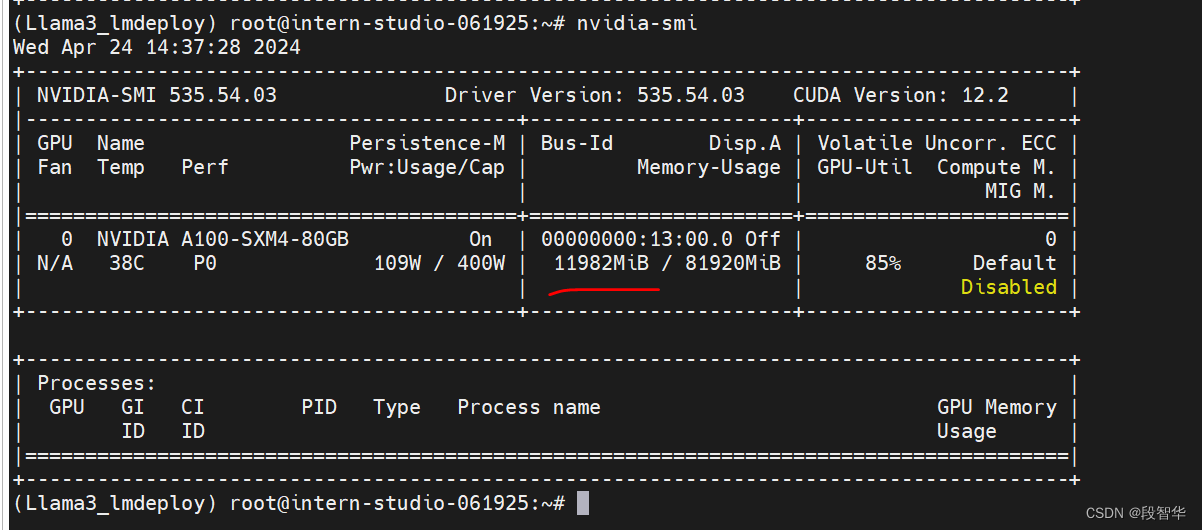
为了更加明显体会到W4A16的作用,将KV Cache比例再次调为0.01,查看显存占用情况。
lmdeploy chat /root/model/Meta-Llama-3-8B-Instruct_4bit --model-format awq --cache-max-entry-count 0.01


可以看到,显存占用变为 11982MiB,明显降低。
在线量化 KV
自 v0.4.0 起,LMDeploy KV 量化方式有原来的离线改为在线。并且,支持两种数值精度 int4、int8。量化方式为 per-head per-token 的非对称量化。它具备以下优势:
- 量化不需要校准数据集
- kv int8 量化精度几乎无损,kv int4 量化精度在可接受范围之内
- 推理高效,在 llama2-7b 上加入 int8/int4 kv 量化,RPS 相较于 fp16 分别提升近 30% 和 40%
- 支持 volta 架构(sm70)及以上的所有显卡型号:V100、20系列、T4、30系列、40系列、A10、A100 等等
通过 LMDeploy 应用 kv 量化非常简单,只需要设定 quant_policy 参数。LMDeploy 规定 qant_policy=4表示 kv int4 量化,quant_policy=8 表示 kv int8 量化。 - LMDeploy服务(serve)
在前面的章节,我们都是在本地直接推理大模型,这种方式成为本地部署。在生产环境下,我们有时会将大模型封装为API接口服务,供客户端访问。
启动API服务器
pip install transformers==4.40.0
通过以下命令启动API服务器,推理Meta-Llama-3-8B-Instruct模型:
lmdeploy serve api_server \/root/model/Meta-Llama-3-8B-Instruct \--model-format hf \--quant-policy 0 \--server-name 0.0.0.0 \--server-port 23333 \--tp 1
通过运行以上指令,我们成功启动了API服务器
(Llama3_lmdeploy) root@intern-studio-061925:~#
(Llama3_lmdeploy) root@intern-studio-061925:~# lmdeploy serve api_server /root/model/Meta-Llama-3-8B-Instruct --model-format hf --quant-policy 0 --server-name 0.0.0.0 --server-port 23333 --tp 12024-04-24 15:01:47,102 - lmdeploy - WARNING - Fallback to pytorch engine because turbomind engine is not installed correctly. If you insist to use turbomind engine, you may need to reinstall lmdeploy from pypi or build from source and try again.
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████| 4/4 [00:51<00:00, 12.77s/it]
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
HINT: Please open http://0.0.0.0:23333 in a browser for detailed api usage!!!
HINT: Please open http://0.0.0.0:23333 in a browser for detailed api usage!!!
HINT: Please open http://0.0.0.0:23333 in a browser for detailed api usage!!!
INFO: Started server process [61984]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:23333 (Press CTRL+C to quit)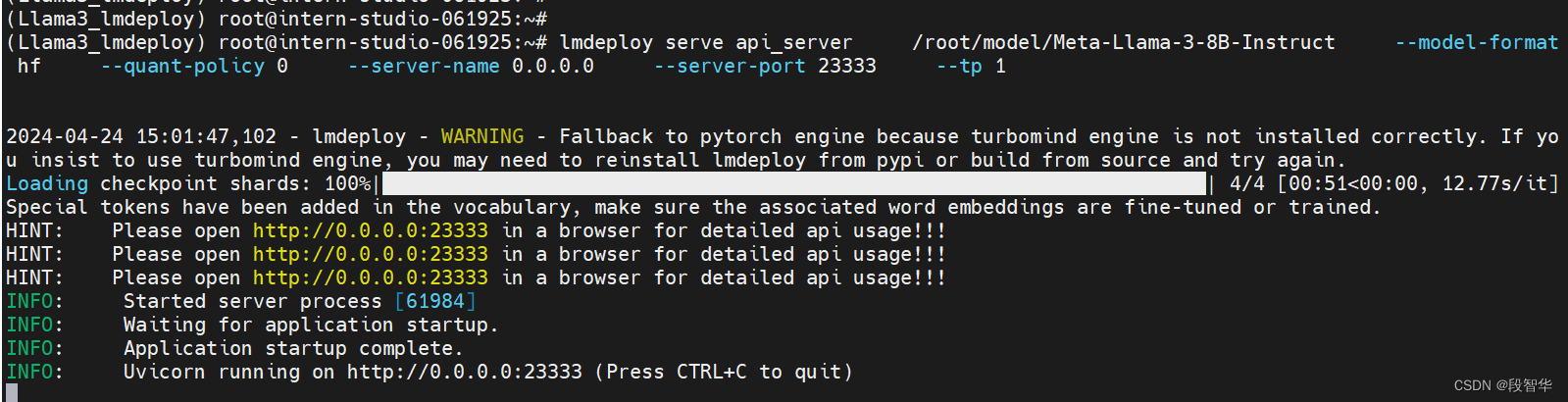
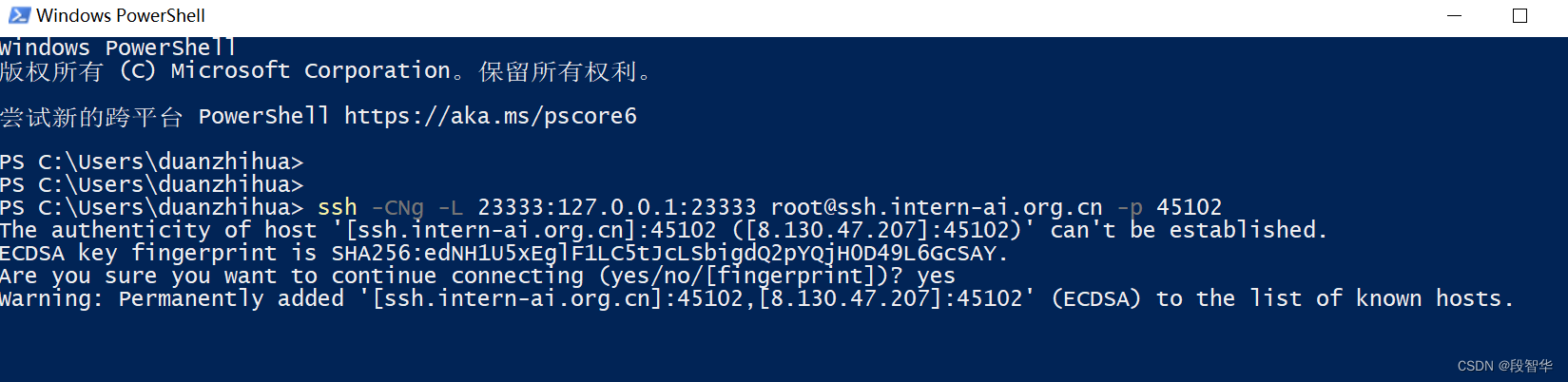
本地端口映射
ssh -CNg -L 23333:127.0.0.1:23333 root@ssh.intern-ai.org.cn -p 45102
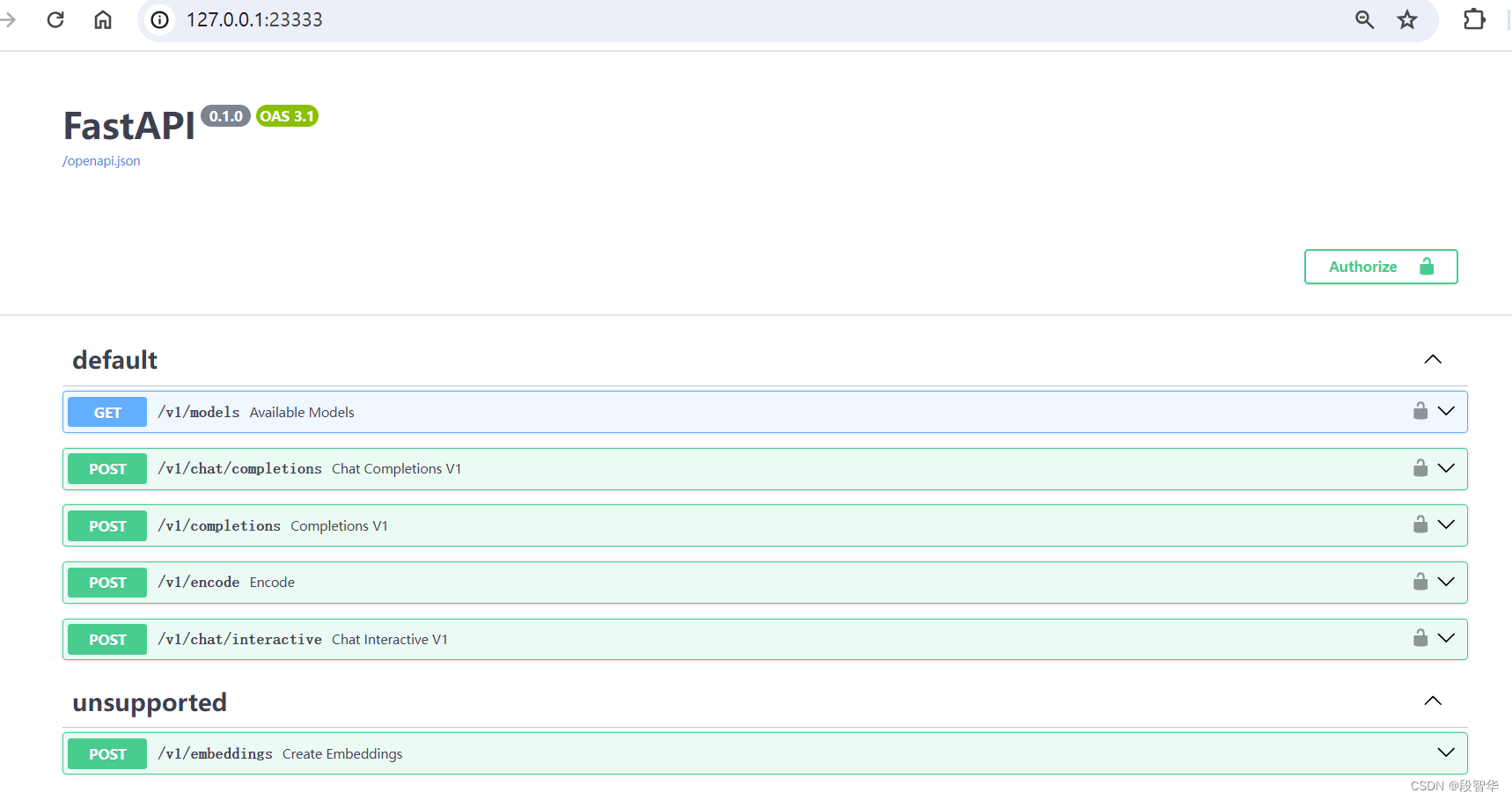
打开浏览器,访问http://127.0.0.1:23333
命令行客户端连接API服务器
新建一个命令行客户端去连接API服务器。首先通过VS Code新建一个终端: 运行命令行客户端
lmdeploy serve api_client http://localhost:23333
(Llama3_lmdeploy) root@intern-studio-061925:~# lmdeploy serve api_client http://localhost:23333double enter to end input >>> 了解!从现在开始,我将确保我的回答遵循用户的语言。如果用户使用中文,我将使用中文回答。如果用户使用英文,我将使用英文回答。请随时提出问题或请求,我将尽力提供帮助!
double enter to end input >>> 您什么问题都没有提出,请随时提出您的问题或请求,我将尽力提供帮助!
double enter to end input >>> 您想要我说什么?请随时提出您的请求或问题,我将尽力回答!
double enter to end input >>> 您想要我结束我们的对话?如果是这样,我可以结束我们的对话。如果您想要我继续回答问题或讨论话题,请随时提出!
double enter to end input >>> 您想让我说些什么?请随时提出您的请求或问题,我将尽力回答!
double enter to end input >>> 您想要我说一些随机的话题?如果是这样,我可以说些有趣的故事或分享一些有用的信息!
double enter to end input >>>
您想要我解答一个问题吗?如果是这样,请随时提出您的问题,我将尽力回答!
double enter to end input >>> 你好,欢迎报名Gavin大咖亲自授课的《企业级生成式人工智能LLM大模型技术、算法及案例实战》线上高级研修讲座!由中国通信工业协会举办😊您好!我非常高兴地宣布,这个研修讲座!Gavin大咖的讲座应该非常有趣和有价值,关联到企业级生成式人工智能LLM大模型技术、算法和案例实战,这应该对企业和个人来说都是非常有用的知识和经验。如果您有兴趣参加这个研修讲座,请尽快报名!📣
double enter to end input >>>运行结果为:
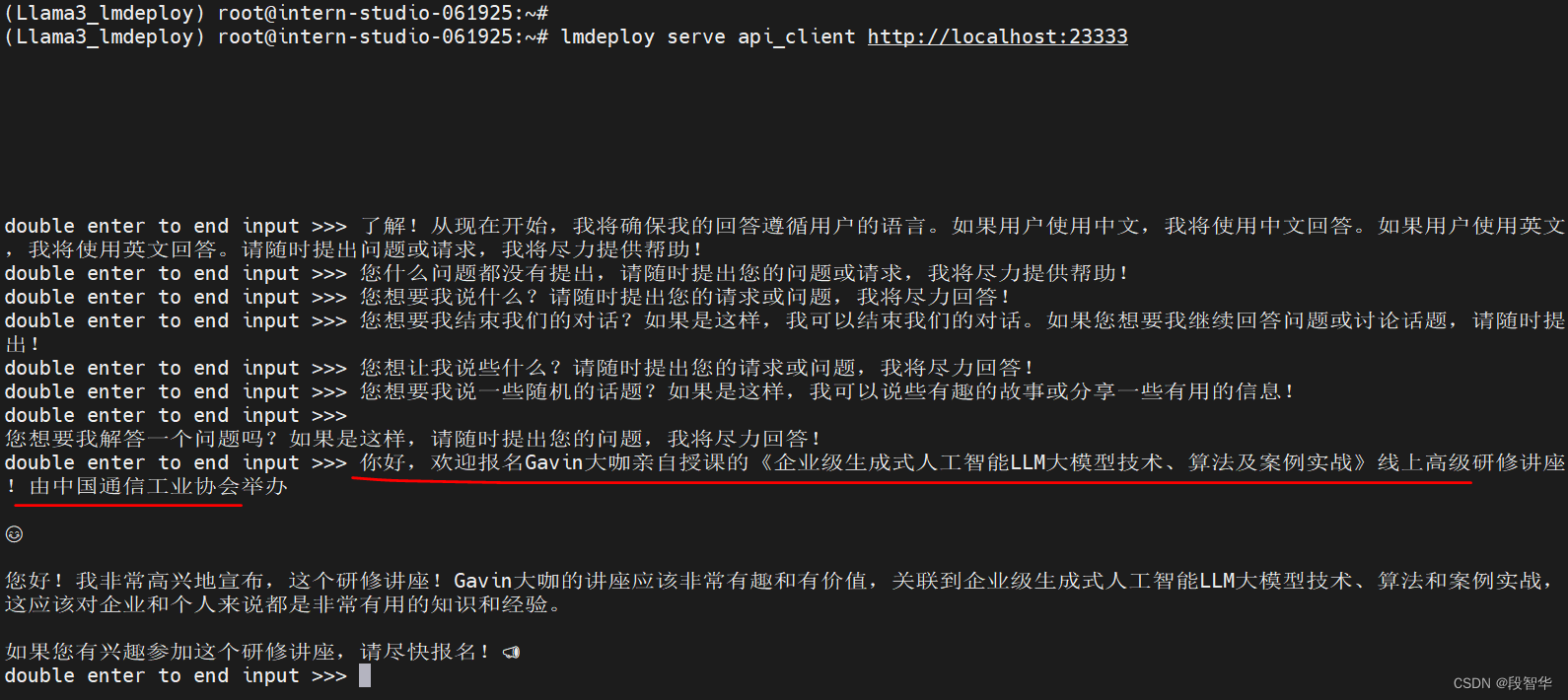
网页客户端连接API服务器
关闭刚刚的VSCode终端,但服务器端的终端不要关闭。
运行之前确保自己的gradio版本低于4.0.0。
pip install gradio==3.50.2
使用Gradio作为前端,启动网页客户端。
lmdeploy serve gradio http://localhost:23333 \--server-name 0.0.0.0 \--server-port 6006
运行结果为:
(Llama3_lmdeploy) root@intern-studio-061925:~# lmdeploy serve gradio http://127.0.0.1:23333 --server-name 0.0.0.0 --server-port 6006server is gonna mount on: http://0.0.0.0:6006
Running on local URL: http://0.0.0.0:6006
本地端口映射
ssh -CNg -L 6006:127.0.0.1:6006 root@ssh.intern-ai.org.cn -p 45102

运行结果为
- 推理速度
使用 LMDeploy 在 A100(80G)推理 Llama3,每秒请求处理数(RPS)高达 25,是 vLLM 推理效率的 1.8+ 倍。
它的 benchmark 方式如下:
- 下载测试数据
wget https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.json
https://aicarrier.feishu.cn/wiki/XgZAwV1RWiKorbkQrKAcE6ufnoc
大模型技术分享