简介:问题设置
什么是机器学习?
机器学习是关于构建具有可调参数的程序,这些参数可以自动调整,以便通过适应先前看到的数据来改善其行为。机器学习可以被认为是人工智能的一个子领域,因为这些算法可以被视为构建模块,使计算机通过以某种方式泛化而不仅仅是像数据库系统那样存储和检索数据项来学习更智能的行为。

我们将在这里看两个非常简单的机器学习任务。第一个是分类任务:图中显示了一组二维数据,根据两个不同的类标签进行着色。分类算法可以用来在两个点簇之间画出一条分界线:通过画出这条分界线,我们已经学会了一个可以推广到新数据的模型:如果你要把另一个点放在未标记的平面上,这个算法现在可以预测它是蓝色还是红色的点。

我们要看的下一个简单任务是回归任务:一组数据的简单最佳拟合线。同样,这是一个将模型拟合到数据的例子,但我们这里的重点是模型可以对新数据进行概括。该模型已经从训练数据中学习,并且可以用于预测测试数据的结果:在这里,我们可能会得到一个x值,并且该模型将允许我们预测y值。
scikit—learn数据
scikit-learn中实现的机器学习算法期望数据存储在二维数组或矩阵中。数组可以是numpy数组,在某些情况下也可以是scipy.sparse矩阵。数组的大小预计为[n_samples,n_features] · n_samples:样本数:每个样本都是要处理的项目(例如分类)。一个样本可以是一个文档、一张图片、一个声音、一个视频、一个天文物体、数据库或CSV文件中的一行,或者任何你可以用一组固定的数量性状来描述的东西。
n_features:可用于以定量方式描述每个项目的特征或独特性状的数量。特征通常是实值的,但在某些情况下可以是布尔值或离散值。
提示:特征的数量必须提前确定。然而,它可以是非常高维的(例如,数百万个特征),对于给定的样本,它们中的大多数都是零。在这种情况下,scipy.sparse矩阵可能很有用,因为它们比NumPy数组更节省内存。
一个简单的例子:鸢尾花数据集应用程序问题
作为简单数据集的示例,让我们看一下 scikit-learn 存储的虹膜数据。 假设我们想识别鸢尾花的种类。 该数据由三种不同种类的鸢尾花的测量值组成:


请记住,每个样本必须有固定数量的特征,并且每个样本的特征编号 i 必须是类似的数量。
用Scikit加载数据-学习
scikit-learn嵌入iris CSV文件的副本沿着一个函数,将其加载到NumPy数组中:
![]()
每个样本花的特征存储在数据集的data属性中:

每个样本的类别信息存储在数据集的 target 属性中:

类的名称存储在最后一个属性中,即 target_names:
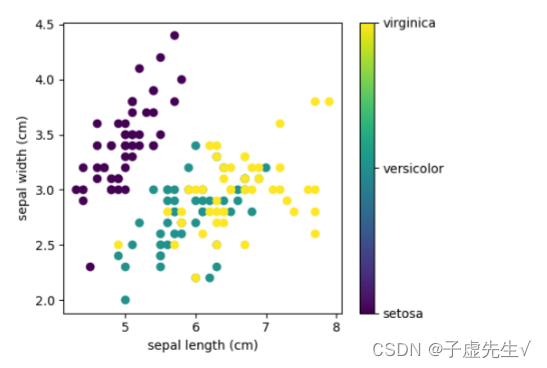
 该数据是四维的,但我们可以使用散点图一次可视化其中两个维度:
该数据是四维的,但我们可以使用散点图一次可视化其中两个维度: