ZooKeeper 搭建详细步骤之三(真集群)
ZooKeeper 搭建详细步骤之二(伪集群模式)
ZooKeeper 搭建详细步骤之一(单机模式)
ZooKeeper 及相关概念简介
搭建模式简述
ZooKeeper 的搭建模式包括单机模式、集群模式和伪集群模式,分别适用于不同的场景和需求,从简单的单节点测试环境到复杂的多节点高可用生产环境。在实际部署时,应根据系统的可用性要求、数据量、并发负载等因素选择合适的部署模式。
ZooKeeper 的搭建模式主要包括以下三种:
-
单机模式(Standalone Mode):
在单机模式下,ZooKeeper 仅在一个单独的服务器节点上运行。这种模式主要用于开发测试环境,便于快速部署和调试。由于只有一个节点,没有数据冗余和故障转移机制,因此不具备高可用性。单节点故障会导致整个服务不可用,不适用于生产环境。 -
集群模式(Cluster Mode / Distributed Mode):
集群模式是 ZooKeeper 在生产环境中推荐使用的部署模式。它由多个(通常为奇数个,如 3、5、7 等)独立的服务器节点组成一个 ZooKeeper 集群。每个节点既是服务提供者又是服务消费者,它们之间通过心跳机制保持通信,并通过 ZAB(ZooKeeper Atomic Broadcast)协议实现数据的复制、同步和一致性保证。集群模式提供了高可用性、容错性和可扩展性,即使部分节点发生故障,只要集群中存活节点的数量大于等于半数(即形成“多数派”),ZooKeeper 集群就能继续对外提供服务。 -
伪集群模式(Pseudo-Distributed Mode / Local Cluster Mode):
伪集群模式是在单台物理或虚拟机上模拟多节点集群的部署方式。在同一台机器上启动多个 ZooKeeper 服务实例,每个实例配置不同的端口、数据目录和身份标识(如服务器ID)。尽管所有节点实际上运行在同一台机器上,但从逻辑上看,它们形成了一个小型的 ZooKeeper 集群,能够模拟集群模式的行为,包括数据复制、节点选举等。伪集群模式常用于本地开发和测试环境,便于在单机上模拟多节点集群环境,验证分布式协调逻辑。
Zookeeper 下载
官网: Apache ZooKeeper官网 ,选择最新稳定版本进行下载
在国内,从官网的下载速度较慢,也可以选择国内镜像站下载,比如阿里镜像站:
阿里镜像: https://mirrors.aliyun.com/apache/zookeeper/
单机模式搭建
ZooKeeper单机模式是指在一台服务器上独立运行一个ZooKeeper服务节点,用于满足小型项目或测试环境中的协调服务需求。
搭建步骤概述
以下是 ZooKeeper 单机模式的详细安装和配置步骤:
- 下载 ZooKeeper:
- 下载文件一般为一个
.tar.gz或.zip格式的压缩包,例如apache-zookeeper-<version>-bin.tar.gz。- 保存至 linux 的 /opt/ 目录下。
-
解压文件:
-
将下载好的压缩包上传到目标服务器,并解压。对于
.tar.gz文件,可以使用以下命令:tar -xvzf apache-zookeeper-<version>-bin.tar.gz -
解压后,将会生成一个名为
apache-zookeeper-<version>-bin的目录,该目录即为ZooKeeper的安装目录。 -
为了方便配置,可以重命名 ZooKeeper 安装目录。
-
-
创建数据目录和日志目录:
-
根据ZooKeeper的配置要求,需要创建两个目录分别用于存放数据和日志:
mkdir /path/to/zookeeper_data mkdir /path/to/zookeeper_logs
-
-
示例中的
/path/to/应替换为你实际希望存储这些文件的路径,如/home/<username>/zookeeper/data和/home/<username>/zookeeper/logs。- 如果不需要单独存放日志时,data 和 logs 可以共用一个目录
-
配置ZooKeeper:
-
进入ZooKeeper安装目录下的
conf文件夹:cd apache-zookeeper-<version>-bin/conf -
复制或重命名示例配置文件
zoo_sample.cfg为zoo.cfg:cp zoo_sample.cfg zoo.cfg
-
-
编辑配置文件:
-
使用文本编辑器(如
vi、nano或emacs)打开zoo.cfg文件并进行如下配置:# 数据目录设置 dataDir=/path/to/zookeeper_data# 日志目录设置(如果需要单独存放日志) dataLogDir=/path/to/zookeeper_logs# 客户端连接端口 clientPort=2181将
/path/to/替换成你在第3步中创建的实际目录路径。
-
-
启动ZooKeeper:
-
返回到ZooKeeper的安装目录:
cd ../.. -
启动ZooKeeper服务:
bin/zkServer.sh start -
如果一切正常,你应该能看到类似于 “ZooKeeper JMX enabled by default” 和 “Using config: /path/to/apache-zookeeper--bin/conf/zoo.cfg” 的输出,接着是 “Starting zookeeper … STARTED” 表明服务已成功启动。
-
连接和验证
验证单机模式运行状态可以通过查看日志或客户端连接的方式来验证
可以通过以下方法检查ZooKeeper服务是否正常运行:
-
查看日志:检查在第3步中指定的
dataLogDir中的ZooKeeper日志文件,确认是否有启动成功的消息和其他异常信息。 -
使用命令行客户端:
-
在ZooKeeper安装目录下,执行命令行客户端以连接到本地ZooKeeper服务:
bin/zkCli.sh -server localhost:2181 -
如果连接成功,客户端将显示欢迎信息及提示符
[zkshell:0]。你可以尝试执行一些基本的命令,如ls /查看根节点下的子节点列表,验证ZooKeeper服务的响应。
-
通过以上步骤,您已经在单台服务器上成功安装并配置了 ZooKeeper 单机模式。此模式适用于不需要高可用性保证的小型应用场景或开发测试环境。在生产环境中,通常建议使用ZooKeeper集群模式以提供容错能力和数据一致性保障。
步骤举例演示
[zhang@node1 soft]$ pwd
/opt/soft
[zhang@node1 soft]$ ll
total 1042532
-rw-r--r--. 1 zhang zhang 14609453 Apr 20 15:37 apache-zookeeper-3.8.4-bin_.tar.gz
-rw-r--r--. 1 root root 492368219 Mar 13 16:08 hadoop-3.2.4.tar.gz
-rw-r--r--. 1 root root 143722924 Mar 13 16:08 jdk-8u281-linux-x64.tar.gz
# 解压到 /opt/apps 下
[zhang@node1 soft]$ tar -zxvf apache-zookeeper-3.8.4-bin_.tar.gz -C /opt/apps
#.......解压过程省略# 进入安装目录
[zhang@node1 soft]$ cd /opt/apps/
[zhang@node1 apps]$ ls
apache-zookeeper-3.8.4-bin flume hadoop-3.2.4 hive3.1 jdk jdk1.8.0_281
# 重命名
[zhang@node1 apps]$ mv apache-zookeeper-3.8.4-bin/ zookeeper# 进入 zookeeper 的安装目录
[zhang@node1 apps]$ cd zookeeper/
[zhang@node1 zookeeper]$ ls
bin conf docs lib LICENSE.txt NOTICE.txt README.md README_packaging.md
# 新建数据目录和日志目录
[zhang@node1 zookeeper]$ mkdir zk_data
[zhang@node1 zookeeper]$ mkdir zk_logs# 进入配置目录
[zhang@node1 zookeeper]$ cd conf
[zhang@node1 conf]$ ls
configuration.xsl logback.xml zoo_sample.cfg
# 使用已有的模板文件,复制命名为 zoo.cfg
[zhang@node1 conf]$ cp zoo_sample.cfg zoo.cfg
# 修改配置为 上面自定义的数据目录和日志目录
[zhang@node1 conf]$ vim zoo.cfg
修改配置文件 zoo.cfg :
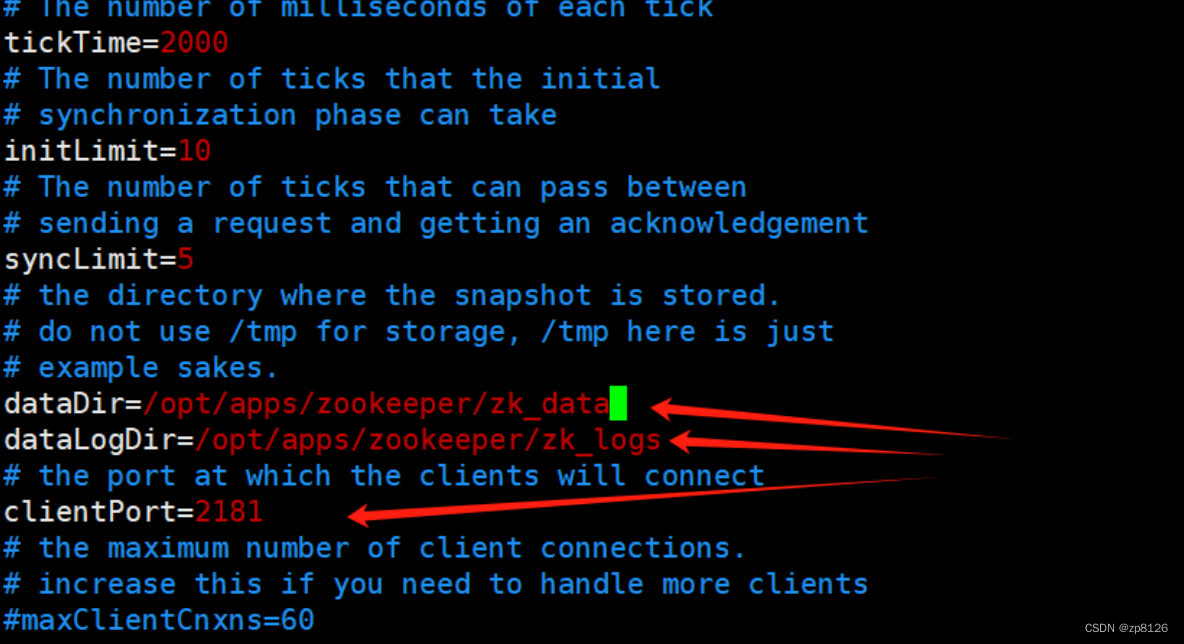
启动 ZooKeeper 服务
zookeeper 安装目录下的 bin 目录
bin/zkServer.sh start # 启动bin/zkServer.sh stop # 停止
修改环境变量(可选)
如果想在任何目录下都可以方便调用 zkServer 来启动 zookeeper 服务,可以配置环境变量。
例如,当前用户下的环境变量文件 ~/.bashrc
新增 ZK_HOME 和 修改 PATH
[zhang@node1 conf]$ vim ~/.bashrc
[zhang@node1 conf]$
修改内容如下图:
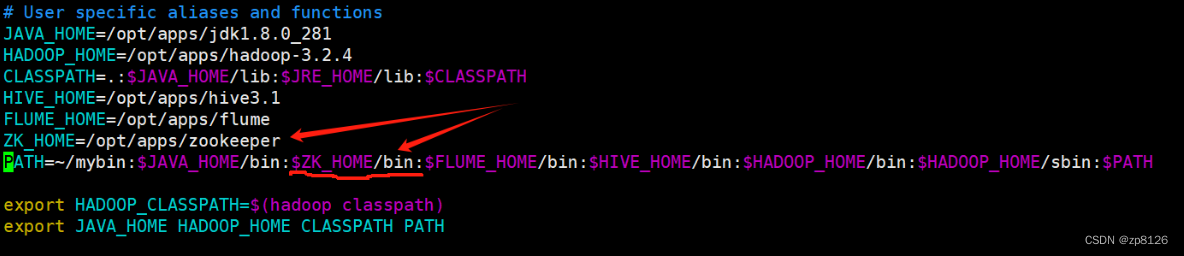
启动 ZooKeeper 服务
在安装目录的 bin 目录下
启动服务:bin/zkServer.sh start
停止服务:bin/zkServer.sh stop
重启服务:bin/zkServer.sh restart
[zhang@node1 zookeeper]$ pwd
/opt/apps/zookeeper
[zhang@node1 zookeeper]$ ls
bin conf docs lib LICENSE.txt NOTICE.txt README.md README_packaging.md zk_data zk_logs
# 在启动前可以先看下数据目录和日志目录下是没有任何文件的
[zhang@node1 zookeeper]$ ls zk_data
[zhang@node1 zookeeper]$ ls zk_logs/# 启动服务 (因配置了环境变量,所以这里可以直接使用)
[zhang@node1 zookeeper]$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/apps/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED# 启动成功后,查看数据和日志目录
[zhang@node1 zookeeper]$ ls zk_data
version-2 zookeeper_server.pid
[zhang@node1 zookeeper]$ ls zk_logs/
version-2# 也可以查看进程 多出一个 QuorumPeerMain
[zhang@node1 zookeeper]$ jps
29028 Jps
16533 NodeManager
28888 QuorumPeerMain
2777 NameNode
2906 DataNode
客户端连接
bin 目录下
连接本机默认端口 2181:zkClient.sh
连接指定主机端口:zkCli.sh -server node1:2181
在成功连接 ZooKeeper 后,进程中会多出 ZooKeeperMain 。退出后进程就会终止。
# 客户端连接
[zhang@node1 zookeeper]$ zkCli.sh
Connecting to localhost:2181
2024-04-21 18:33:17,582 [myid:] - INFO [main:o.a.z.Environment@98] - Client environment:zookeeper.version=3.8.4-9316c2a7a97e1666d8f4593f34dd6fc36ecc436c, built on 2024-02-12 22:16 UTC
2024-04-21 18:33:17,584 [myid:] - INFO [main:o.a.z.Environment@98] - Client environment:host.name=node1
2024-04-21 18:33:17,584 [myid:] - INFO [main:o.a.z.Environment@98] - Client environment:java.version=1.8.0_281
# .......省略启动过程
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
[zk: localhost:2181(CONNECTED) 0] # 退出客户端 quit
[zk: node1:2181(CONNECTED) 0] quit
WATCHER::
WatchedEvent state:Closed type:None path:null
2024-04-21 19:53:51,030 [myid:] - INFO [main:o.a.z.ZooKeeper@1232] - Session: 0x10004c5597e0000 closed
2024-04-21 19:53:51,031 [myid:] - INFO [main:o.a.z.u.ServiceUtils@45] - Exiting JVM with code 0
2024-04-21 19:53:51,031 [myid:] - INFO [main-EventThread:o.a.z.ClientCnxn$EventThread@569] - EventThread shut down for session: 0x10004c5597e0000
[zhang@node1 zookeeper]$
简单命名操作
# (CONNECTED) 表示当前是连接状态
# 创建节点 zk_test 并设置数据
[zk: node1:2181(CONNECTED) 5] create /zk_test Hello,World!
Created /zk_test
# 获取节点数据
[zk: node1:2181(CONNECTED) 6] get /zk_test
Hello,World!
# 获取节点数据及其他详细信息
[zk: node1:2181(CONNECTED) 8] get -s /zk_test
Hello,World!
cZxid = 0xc
ctime = Sun Apr 21 23:10:44 CST 2024
mZxid = 0xc
mtime = Sun Apr 21 23:10:44 CST 2024
pZxid = 0xc
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 12
numChildren = 0
# 查看根节点
[zk: node1:2181(CONNECTED) 16] ls /
[zk_test, zookeeper]
# 关闭连接
[zk: node1:2181(CONNECTED) 17] close
WATCHER::
WatchedEvent state:Closed type:None path:null
2024-04-21 23:15:52,787 [myid:] - INFO [main:o.a.z.ZooKeeper@1232] - Session: 0x10004c5597e0005 closed
2024-04-21 23:15:52,787 [myid:] - INFO [main-EventThread:o.a.z.ClientCnxn$EventThread@569] - EventThread shut down for session: 0x10004c5597e0005
# 状态变为 (CLOSED)
[zk: node1:2181(CLOSED) 18]
# 可以重新连接
[zk: node1:2181(CLOSED) 18] connect注意:
quit 和 close 不同
quit 退出客户端命令窗口,同时也关闭连接
close 只是关闭连接,并不退出客户端
到此,单机模式的配置、ZooKeeper 启动、客户端登录等介绍到这里,由于篇幅较长,集群的搭建和使用放在下一篇来详细介绍!
ZooKeeper 搭建详细步骤之三(真集群)
ZooKeeper 搭建详细步骤之二(伪集群模式)
ZooKeeper 搭建详细步骤之一(单机模式)
ZooKeeper 及相关概念简介