目录
1.程序功能描述
2.测试软件版本以及运行结果展示
3.核心程序
4.本算法原理
4.1 遗传算法(GA)原理
4.2 BP神经网络原理
4.3 遗传优化BP神经网络结合应用
4.4 遗传算法简要改进
5.完整程序
1.程序功能描述
基于改进遗传优化的BP神经网络金融序列预测算法matlab仿真。对比BP神经网络,遗传优化bp神经网络以及改进遗传优化BP神经网络。
2.测试软件版本以及运行结果展示
MATLAB2022A版本运行
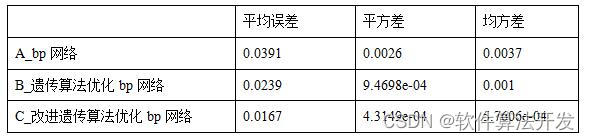
三个算法的误差对比:
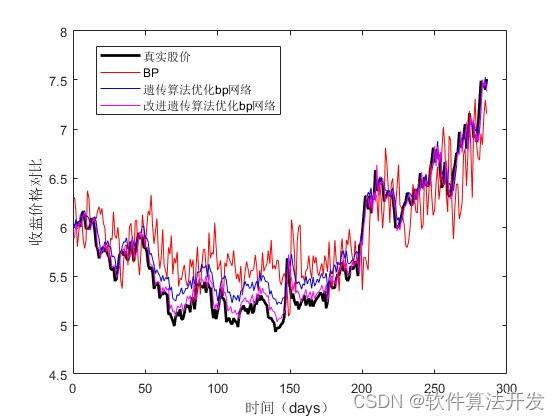
三个算法的数据预测曲线对比:

3.核心程序
..............................................................................
%构建BP网络
net = newff(train_data,train_aim,Num_Hidden);ERR1 = [];
ERR2 = [];
ERR3 = [];
for j = 1:5j%通过改进遗传算法优化BP参数net = func_newGA2(net,Num_In,Num_Hidden,Num_Out,train_data,train_aim);%网络训练net.trainParam.showWindow = 0;net = train(net,train_data,train_aim);outputs = sim(net,test_data);d1 = test_aim*(Maxs-Mins) + Mins;d2 = outputs*(Maxs-Mins) + Mins;ERR1 = [ERR1,mean(abs(d1-d2)./d2) ];ERR2 = [ERR2,mean((abs(d1-d2)./d2).^2) ];ERR3 = [ERR3,std((abs(d1-d2)./d2).^2) ];
endfigure;
plot(d1,'b');
hold on
plot(d2,'r');
legend('真实股价','预测股价');
xlabel('时间(days)');
ylabel('收盘价格对比');disp('平均误差:');
mean(ERR1)
disp('平方差:');
mean(ERR2)
disp('均方差:');
mean(ERR3)save r2.mat d1 d2
04_004m4.本算法原理
基于遗传优化的BP(Backpropagation)神经网络金融序列预测是一种结合了遗传算法(Genetic Algorithm, GA)的优化能力和BP神经网络强大非线性拟合能力的混合预测模型。这种模型在处理金融时间序列数据,如股票价格、汇率、商品期货价格等,具有独特的优势,因为它能够有效应对金融市场的复杂性、非线性和不确定性。
4.1 遗传算法(GA)原理
遗传算法是一种启发式搜索算法,灵感来源于自然界中的生物进化过程,包括选择、交叉(杂交)和变异三大基本操作。其目标是通过迭代搜索找到问题的最优解或近似最优解。
-
编码:首先,将问题的解(在这里是BP神经网络的权重和阈值)编码为染色体(Chromosome),通常采用二进制编码或实数编码。
-
适应度函数:定义一个评价标准(Fitness Function),衡量每个解的质量。在金融序列预测中,适应度函数通常是预测误差的倒数或负对数,即预测误差越小,适应度越高。

其中,yi是实际观测值,y^i是预测值,N是样本数。
-
选择:基于轮盘赌选择法等策略,选择适应度高的个体进入下一代,以模拟自然界中的“适者生存”。
-
交叉:随机选择两个个体进行基因交换,以产生新的后代,促进多样性。
-
变异:以一定概率随机改变某些基因值,增加搜索空间的探索范围。
-
终止条件:当达到预设的遗传代数(Generation)或适应度达到预设阈值时,算法停止,输出当前最优解。
4.2 BP神经网络原理
BP神经网络是一种多层前馈网络,包括输入层、隐藏层和输出层。它通过反向传播误差来调整网络权重,实现对输入数据的非线性拟合。

4.3 遗传优化BP神经网络结合应用
将遗传算法引入BP神经网络的训练过程,主要用来优化网络的初始权重和阈值,以期找到更优的网络参数配置,从而提高预测精度。
-
初始化:使用遗传算法生成一组BP神经网络的初始参数(权重和阈值)。
-
遗传操作:对这批参数进行选择、交叉和变异操作,生成新的一代参数。
-
BP训练:将每一代遗传产生的参数配置应用到BP神经网络中,进行前向传播和反向传播学习,计算适应度。
-
迭代优化:重复遗传操作和BP训练过程,直到满足停止条件,如适应度不再显著提高或达到预设的遗传代数。
-
预测:利用经过遗传优化的BP神经网络对金融序列进行预测,输出预测值。
4.4 遗传算法简要改进
进行遗传算法的关键点之一是保证种群的多样性。遗传算法的交叉和变异的判断,就是根据每个染色体个体的最大适应度值和平均适应度的差值的大小来判断,即:
![]()
当差值较大的时候,说明染色体差异较大,当差值较小的时候,说明染色体差异较小,当差异较小的时候,就会容易出现局部收敛。为了防止这种情况出现,我们需要自适应的调整这种变异概率和交叉概率。

5.完整程序
VVV