会议简介 Brief Introduction
2025年第四届信息与通信工程国际会议(JCICE 2025)
会议时间:2025年7月25日-27日
召开地点:中国哈尔滨
大会官网:www.jcice.org
由黑龙江大学和成都信息工程大学主办,江苏科技大学协办的2025年第四届信息与通信工程国际会议(JCICE 2025)将于2025年7月25至27日在中国哈尔滨召开。会议将围绕“信息与通信工程”的最新研究领域而展开,为研究人员、工程师、专家学者以及行业专业人士提供一个交流与探讨最新研究成果的平台,并为与会者们交流新的思想和应用经验建立业务或研究关系。在会议期间您将有机会聆听到行业前沿的学术报告,见证该领域的成果与进步。现热忱欢迎从事相关技术研究的专家学者及学生踊跃投稿并参加本次会议。
重要信息 Highlights
截稿时间:2025年2月13日
录用通知:投稿后两周内
论文出版 Publication
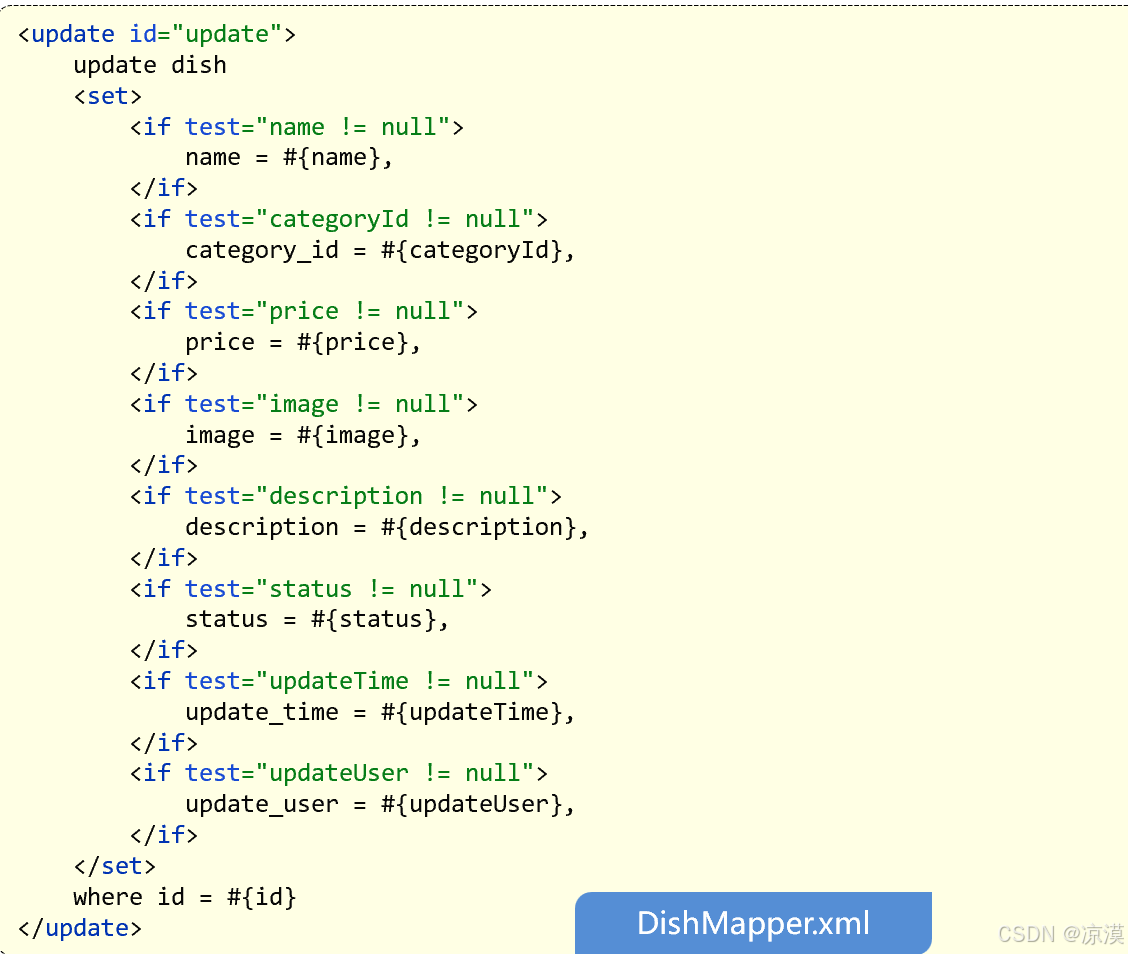
所有被大会接收的论文将收录至会议在线论文集,并提交至Ei Compendex, Scopus等主流数据库检索。
往届主旨报告人 Keynote Speakers

Prof. Zhu Han
IEEE Fellow, AAAS Fellow
美国休斯顿大学

黄德双教授
IEEE Fellow, IAPR Fellow, AAIA Fellow
宁波东方理工大学

廖晓峰教授
IEEE Fellow, AIAA Fellow
重庆大学
征稿主题 Call for Paper
JCICE 2025主题涵盖信息与通信工程及其相关领域,横跨理论基础和应用研究。所征集的主题包括但不限于:
移动计算
网络协议
数据通讯
数据挖掘
自然语言处理
网络和数据安全
数据库和数据管理
宽带访问控制
移动无线上网
多媒体和图像处理
协同定位数据访问和管理
移动网络流量工程、性能和优化
人工神经网络和模糊系统
移动系统设计、实现和应用
更多征稿主题请访问:https://www.jcice.org/cfp
参会方式 Type of Attendence
1.作者参会:一篇会议录用文章允许一名作者参会;
2.主讲嘉宾:申请主题演讲,由会务组审核;
3.口头演讲:申请口头报告,时间为15分钟;
4.海报参会:申请海报参会,根据官网模板准备海报,再录制5分钟视频;
5.视频参会:录制15分钟个人视频即可;
6.听众参会:不投稿仅参会,可参与问答,也可演讲及展示。
投稿方式 Submission Method
1.会议邮箱:contact@jcice.org
2.CMT在线投稿:https://cmt3.research.microsoft.com/User/Login?ReturnUrl=%2FJCICE2025
请作者按照官网模板格式进行排版。排版好的论文全稿(Word+PDF版)发送至CMT在线系统或者会议邮箱。
投稿要求 Submission Type
1. 大会官方语言为英语,必须为全英文稿件,且应具有学术或实用价值,未在国内外学术期刊或会议发表过;
2. 保证文章原创性,未在国内外公开刊物或其它学术会议上发表过。
3. 文章篇幅一般在5-12页之间,不少于5页,含公式图表等,超过5页将收取超页费;
4. 作者可通过iThenticate或其他查询系统自费查重,重复率不得超过20%,由文章重复率引起的被拒稿将由作者自行承担责任;
5.文章录用:若您的文章被录用,我们将以邮件形式通知您,您将收到以下文件:录用通知、审稿意见表、中文注册表。
联系我们 Contact us
会议秘书:梁老师
会议官网:www.jcice.org
会议邮箱:contact@jcice.org