合集 ChatGPT 通过图形化的方式来理解 Transformer 架构
- 翻译: 什么是ChatGPT 通过图形化的方式来理解 Transformer 架构 深度学习一
- 翻译: 什么是ChatGPT 通过图形化的方式来理解 Transformer 架构 深度学习二
- 翻译: 什么是ChatGPT 通过图形化的方式来理解 Transformer 架构 深度学习三
- 翻译: 什么是ChatGPT 通过图形化的方式来理解 Transformer 架构 深度学习四
- 翻译: 什么是ChatGPT 通过图形化的方式来理解 Transformer 架构 深度学习五
- 翻译: 什么是ChatGPT 通过图形化的方式来理解 Transformer 架构 深度学习六
这个过程涉及两个不同的步骤。
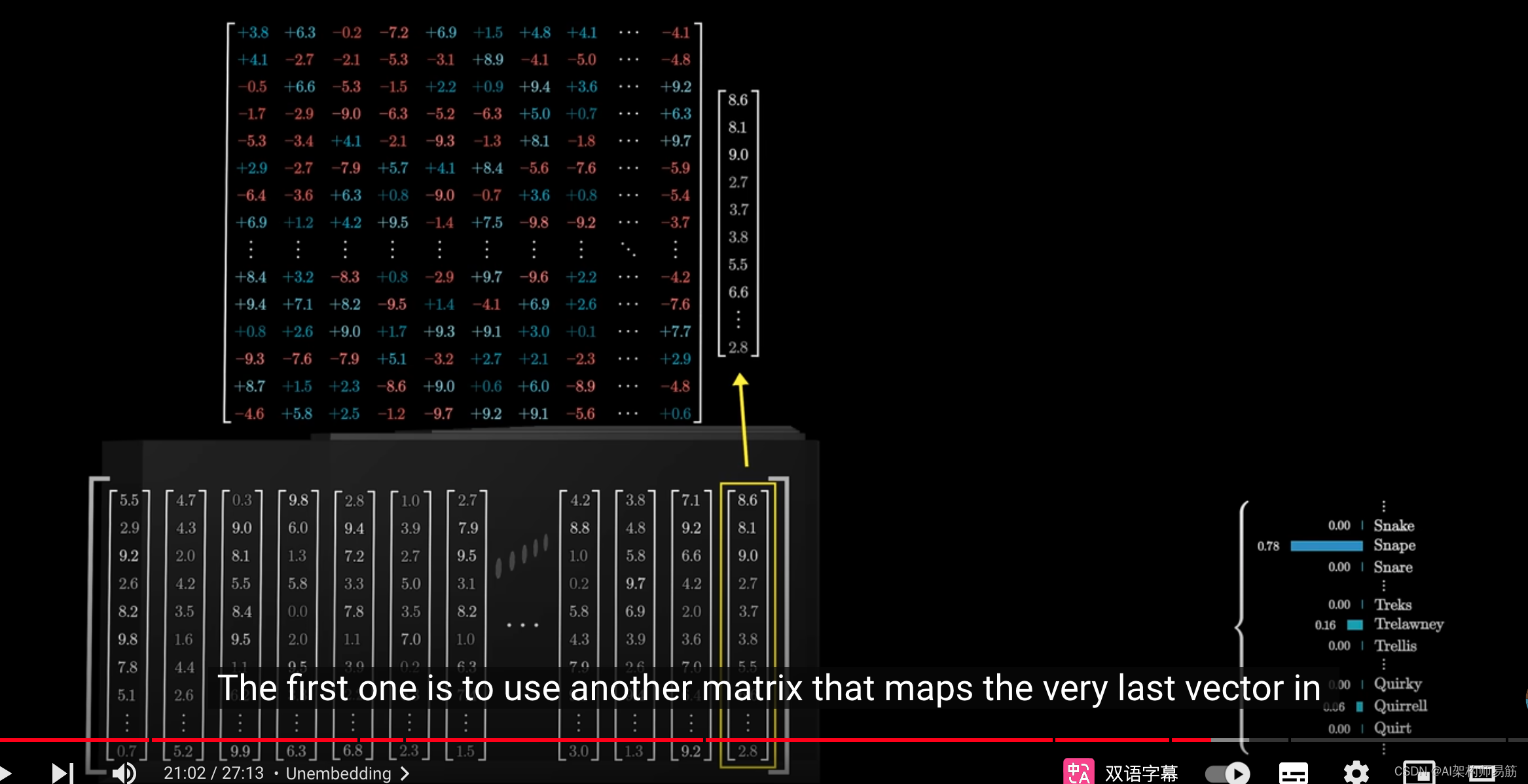
首先,使用另一个矩阵,将上下文中的最后一个向量
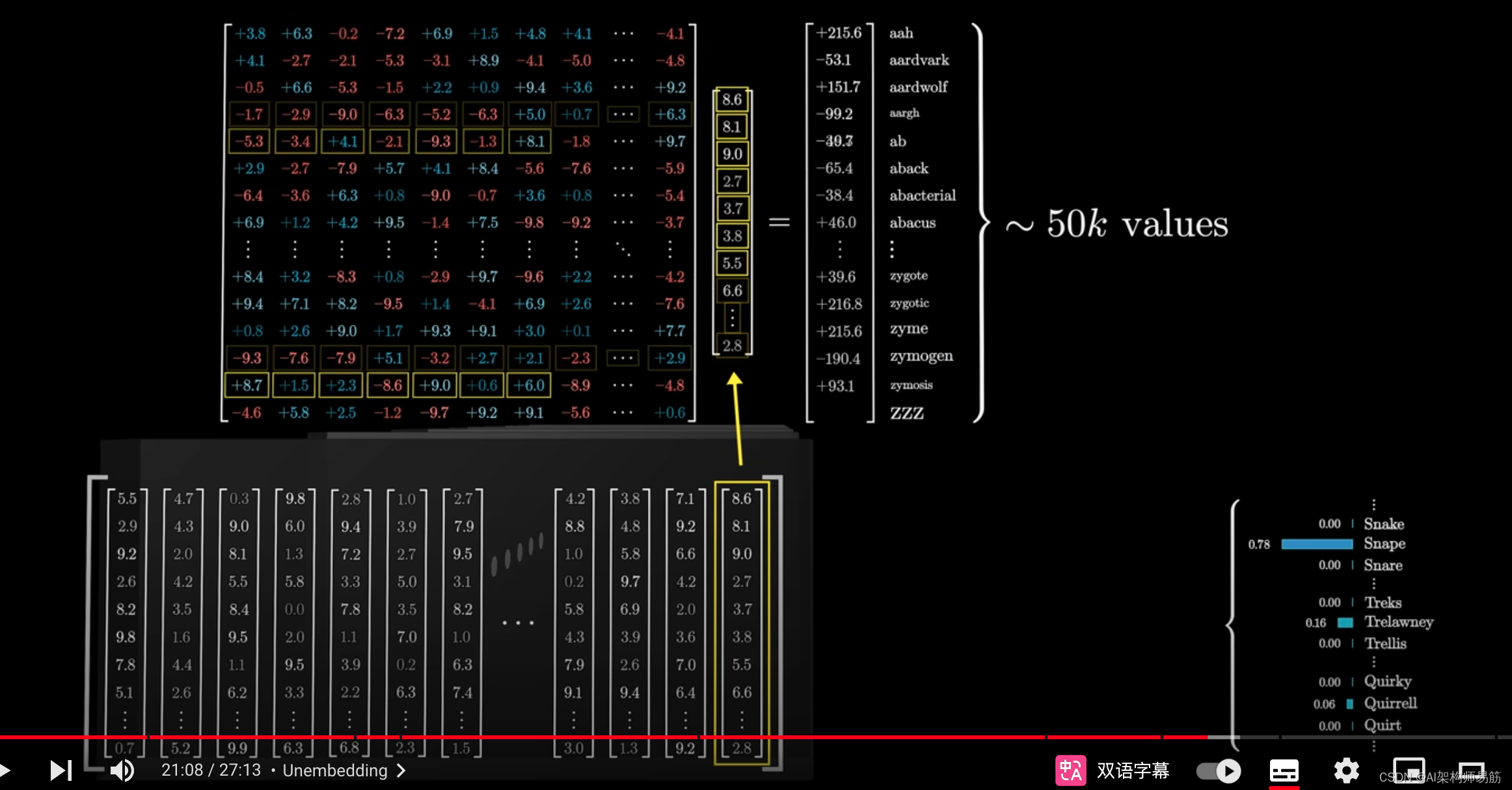
映射到一个包含50k个值的列表,每个值对应于词汇表中的一个token。

然后,使用一个函数将这些值转换为概率分布。
这个函数称为softmax,我们稍后会更多地讨论它。

但在此之前,你可能会觉得仅根据最后一个嵌入进行预测有点奇怪,因为最后一层中有数千个其他向量,每个向量都具有丰富的上下文含义。

这是因为在训练过程中,证明如果我们使用最后一层的每个向量
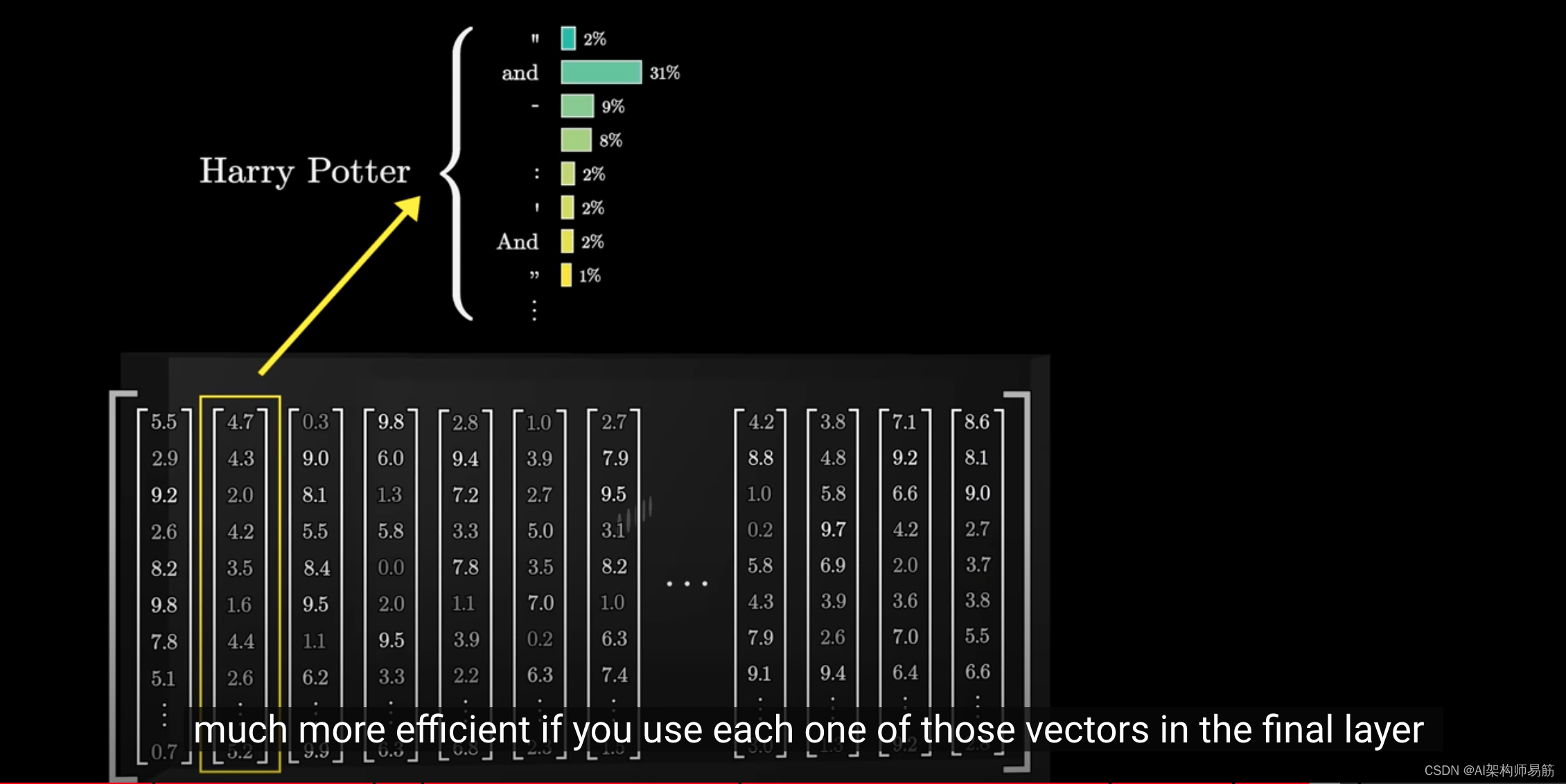

来预测之后可能发生的情况,这是一种更有效的方法。
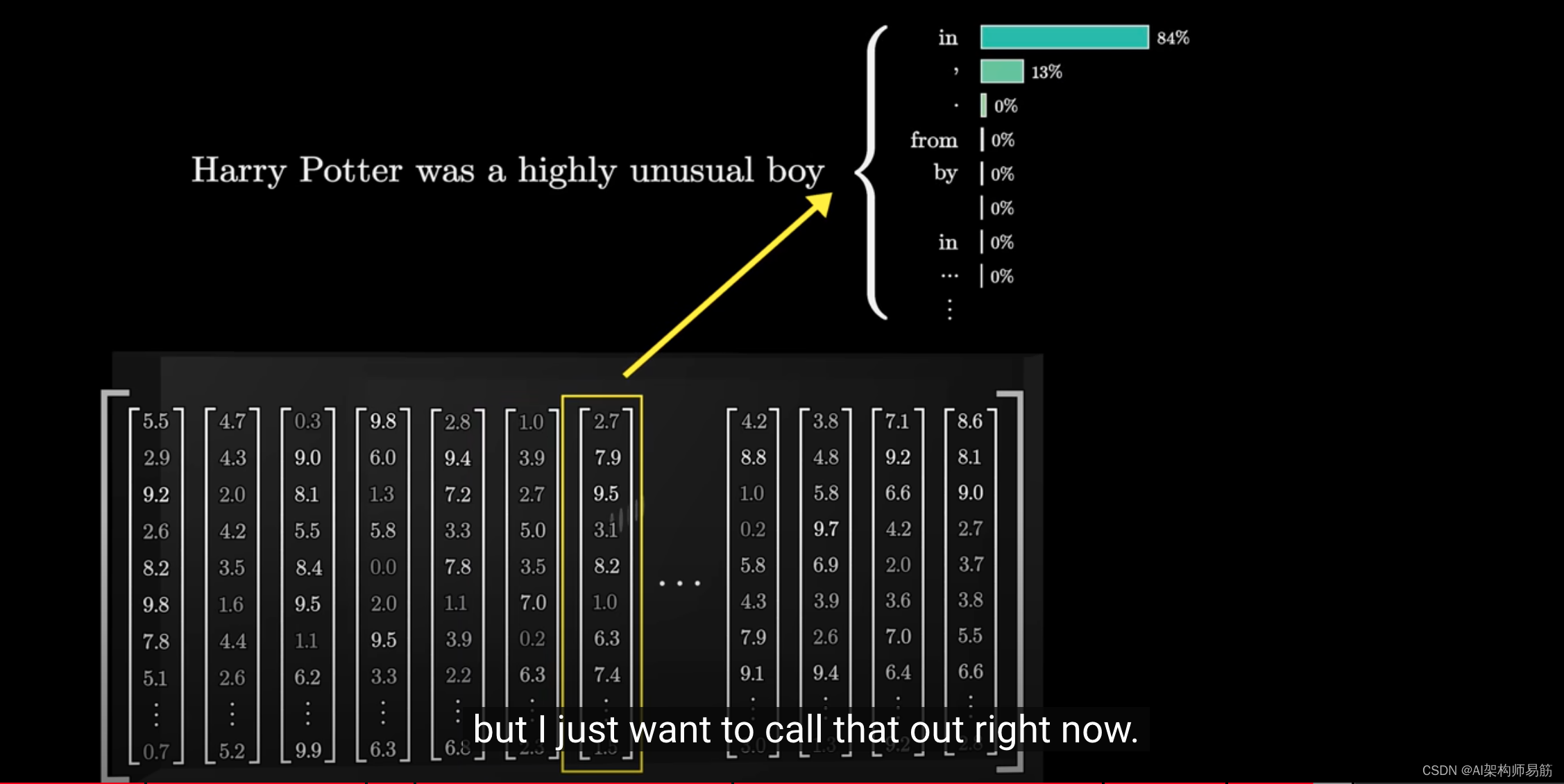
我们稍后会详细讨论训练的细节,但现在让我们简单地指出这一点。
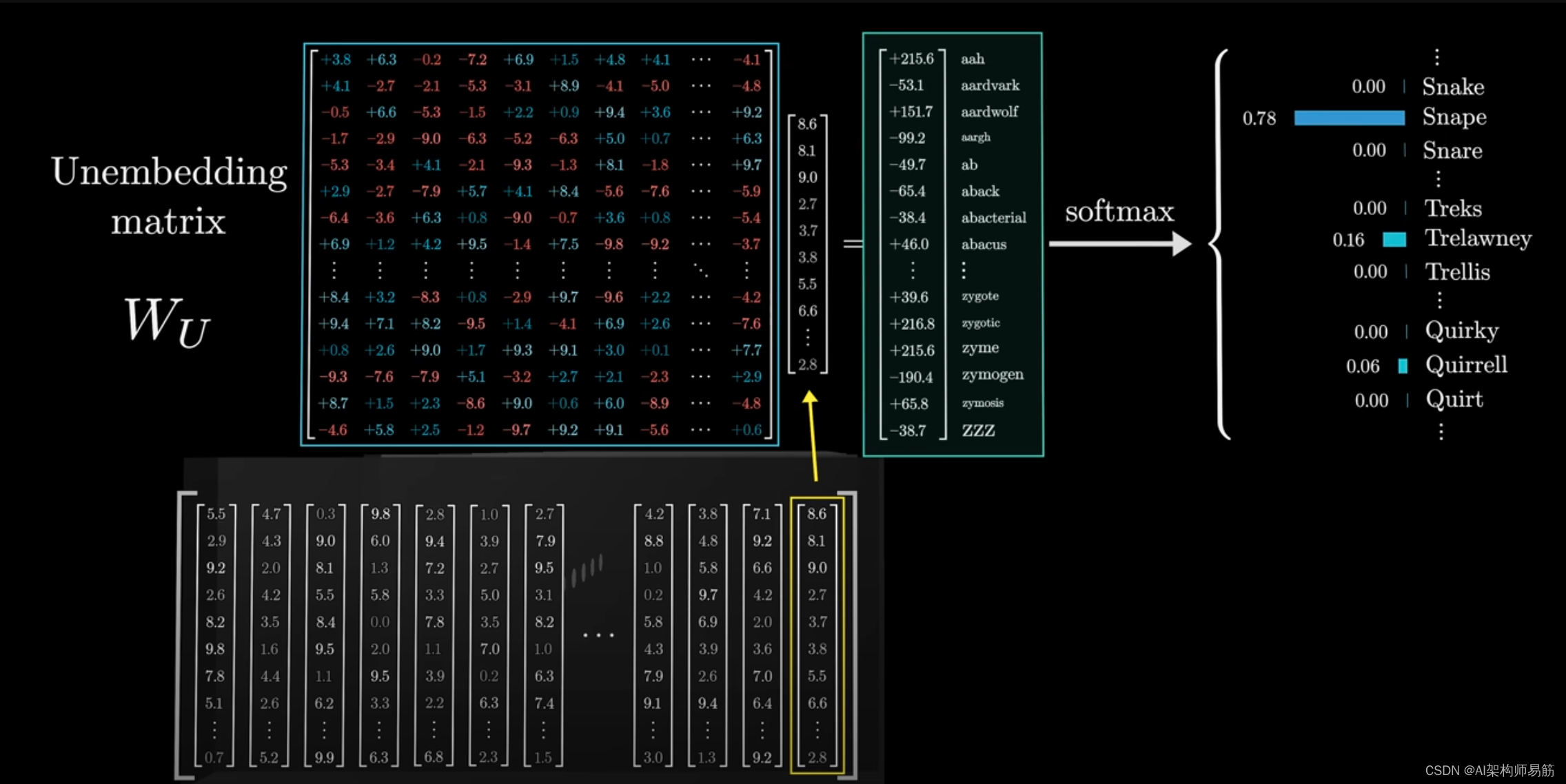
这个矩阵被称为unembedding matrix,我们用标签 W u W_u Wu来标记它。
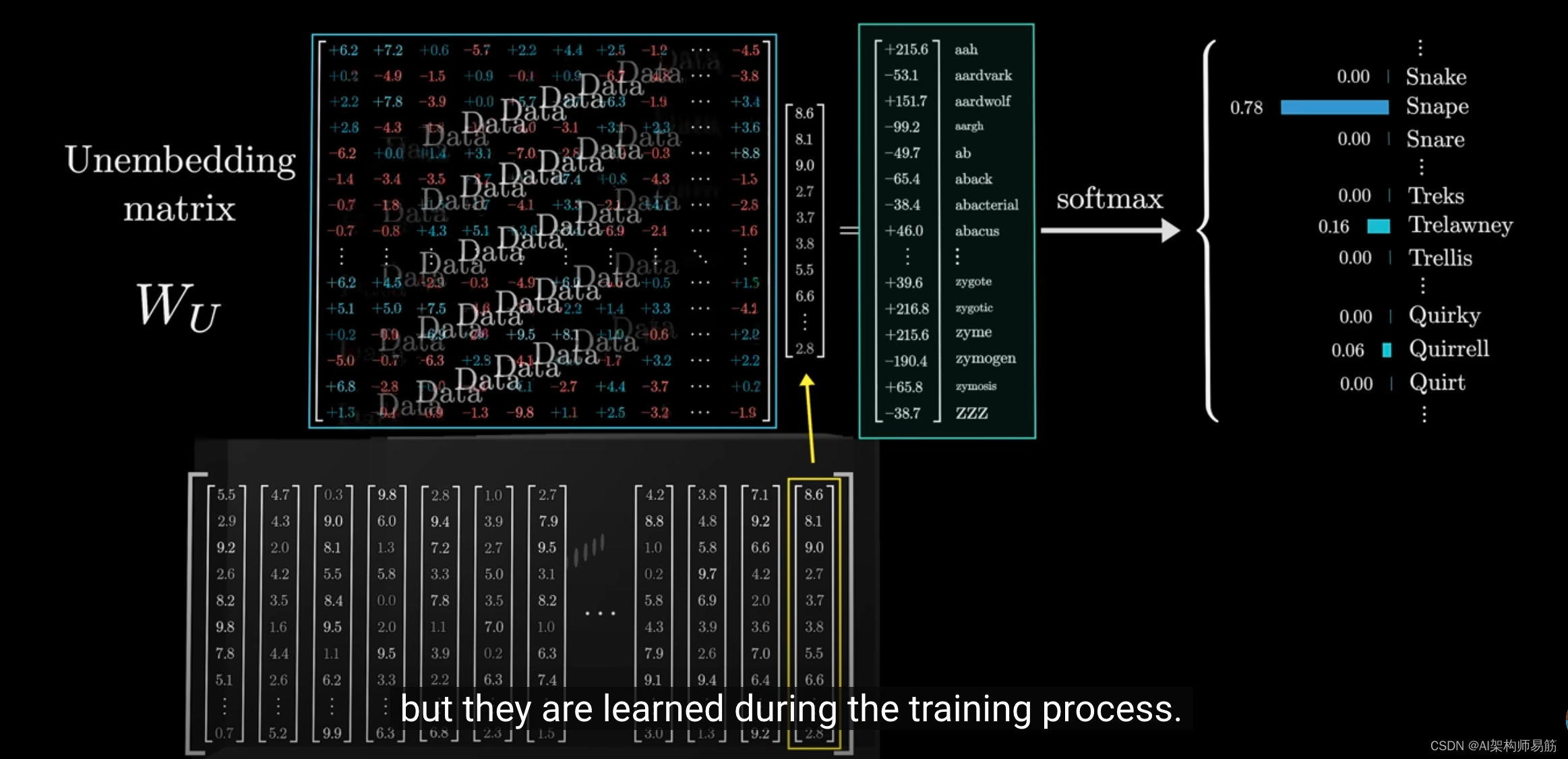
就像我们看到的加权矩阵一样,这个矩阵的初始值是随机的,但这些值在训练过程中会被更新。
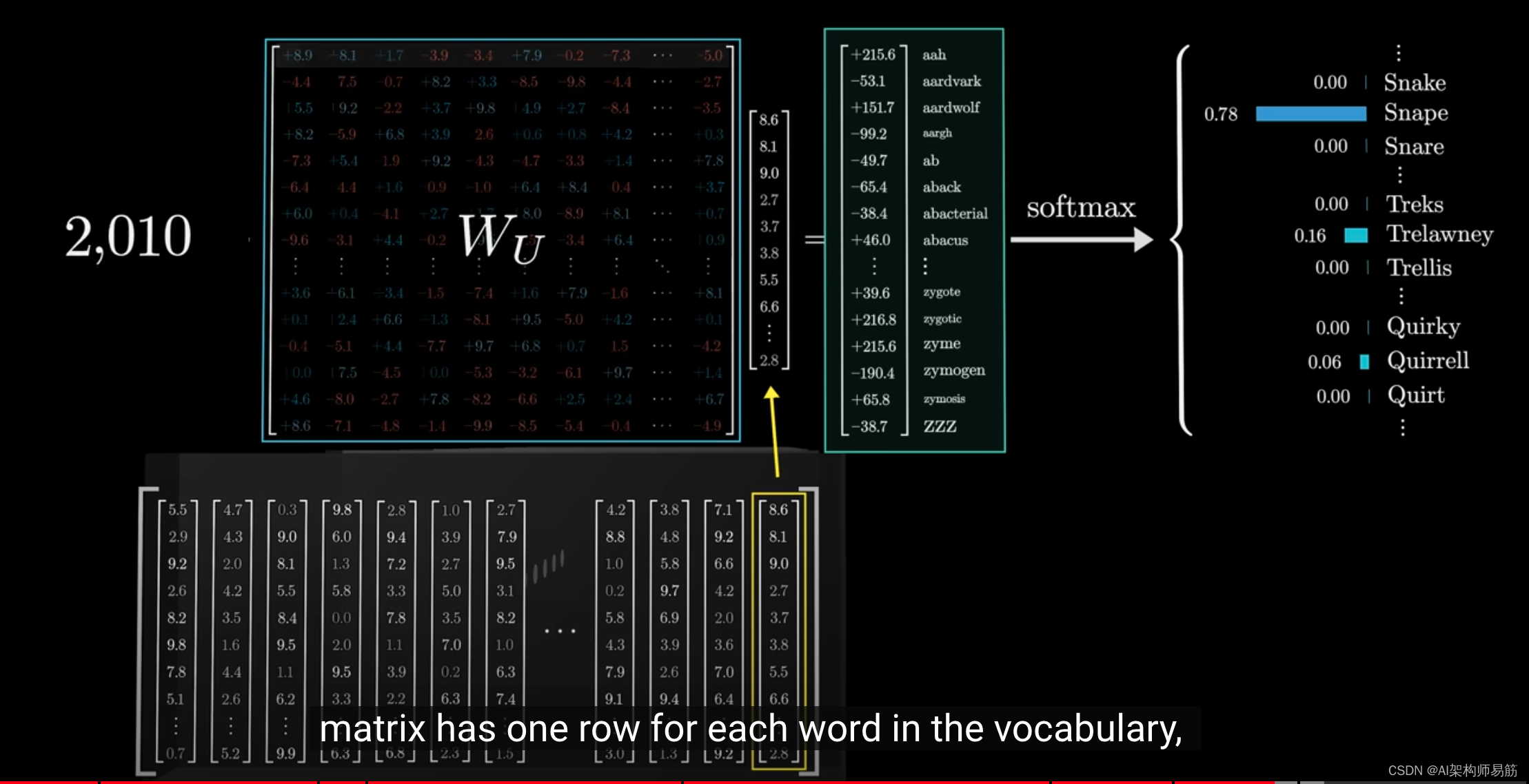
关于总参数数量的统计,这个unembedding matrix为词汇表中的每个词分配一行,
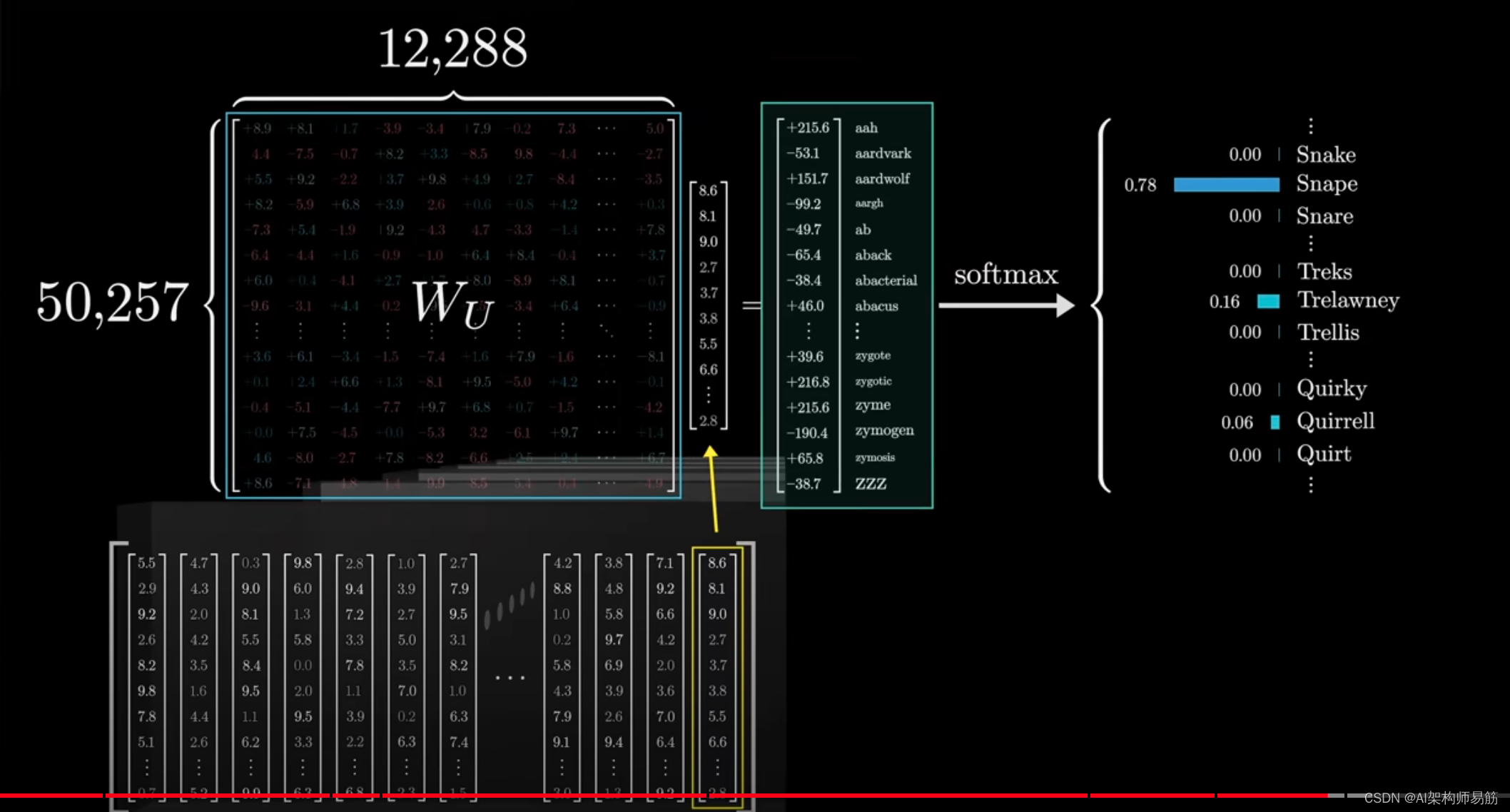
每行包含与嵌入维度相同数量的元素。
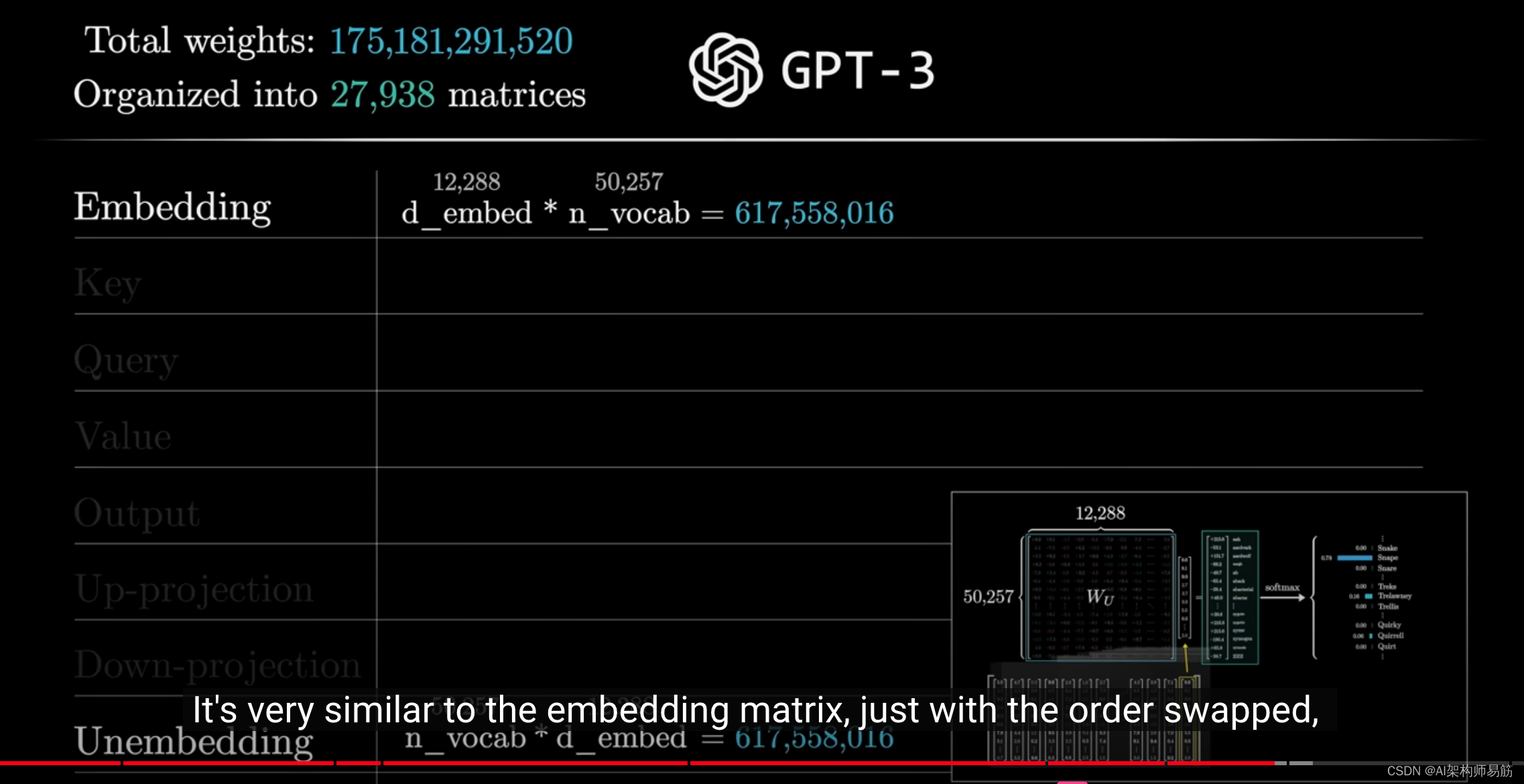
这与嵌入矩阵非常相似,只是通过反转顺序,因此它为网络增加了另外6.17亿个参数。

到目前为止,我们已经超过了10亿个参数,这只是我们最终要达到的1750亿个参数的一小部分。
参考
https://youtu.be/wjZofJX0v4M?si=DujTHghH5dYM3KpZ