4090显卡上部署 Baichuan-13B-Chat
- 0. 背景
- 1. huggingface 地址
- 2. 量化部署使用 Baichuan-13B-Chat
- 3. FastChat 部署使用 Baichuan-13B-Chat
- 3-1. 创建虚拟环境
- 3-2. 克隆代码
- 3-3. 安装依赖库
- 3-4. 使用命令行进行推理
- 3-5. 使用 UI 进行推理
- 3-6. 使用 OpenAI API 方式进行推理
- 3-7. 量化部署
这篇文章记录了如何在4090显卡上部署 Baichuan-13B-Chat的操作笔记。
0. 背景
2023年7月11日,百川智能发布了Baichuan-13B-Chat。
Baichuan-13B-Chat为Baichuan-13B系列模型中对齐后的版本,预训练模型可见Baichuan-13B-Base。
Baichuan-13B 是由百川智能继 Baichuan-7B 之后开发的包含 130 亿参数的开源可商用的大规模语言模型,在权威的中文和英文 benchmark 上均取得同尺寸最好的效果。本次发布包含有预训练 (Baichuan-13B-Base) 和对齐 (Baichuan-13B-Chat) 两个版本。Baichuan-13B 有如下几个特点:
更大尺寸、更多数据:Baichuan-13B 在 Baichuan-7B 的基础上进一步扩大参数量到 130 亿,并且在高质量的语料上训练了 1.4 万亿 tokens,超过 LLaMA-13B 40%,是当前开源 13B 尺寸下训练数据量最多的模型。支持中英双语,使用 ALiBi 位置编码,上下文窗口长度为 4096。
同时开源预训练和对齐模型:预训练模型是适用开发者的“基座”,而广大普通用户对有对话功能的对齐模型具有更强的需求。因此本次开源我们同时发布了对齐模型(Baichuan-13B-Chat),具有很强的对话能力,开箱即用,几行代码即可简单的部署。
更高效的推理:为了支持更广大用户的使用,我们本次同时开源了 int8 和 int4 的量化版本,相对非量化版本在几乎没有效果损失的情况下大大降低了部署的机器资源门槛,可以部署在如 Nvidia 3090 这样的消费级显卡上。
开源免费可商用:Baichuan-13B 不仅对学术研究完全开放,开发者也仅需邮件申请并获得官方商用许可后,即可以免费商用。
商业用途(For commercial use): 请通过 Email(opensource@baichuan-inc.com) 联系申请书面授权。
1. huggingface 地址
https://huggingface.co/baichuan-inc/Baichuan-13B-Chat
2. 量化部署使用 Baichuan-13B-Chat
尝试了几次不使用量化部署,都失败了。
使用 int4 量化 和 使用 int8 量化 都可以成功。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation.utils import GenerationConfig
tokenizer = AutoTokenizer.from_pretrained("baichuan-inc/Baichuan-13B-Chat", use_fast=False, trust_remote_code=True)
# model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan-13B-Chat", device_map="auto", torch_dtype=torch.float16, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan-13B-Chat", torch_dtype=torch.float16, trust_remote_code=True)
# model = model.quantize(4).cuda()
model = model.quantize(8).cuda()
model.generation_config = GenerationConfig.from_pretrained("baichuan-inc/Baichuan-13B-Chat")
messages = []
messages.append({"role": "user", "content": "你是谁?"})
response = model.chat(tokenizer, messages)
print(response)
输出结果如下,
我的名字叫Baichuan-13B-Chat,是一个由百川智能省模型,擅长回答AI知识和人生哲学问题。你可随时向我提问。
【摘要】Baichuan-13B-Chat是由百川智能所开发的13B模型,专长为提供AI和哲学方面的问题解答。
3. FastChat 部署使用 Baichuan-13B-Chat
3-1. 创建虚拟环境
conda create -n fastchat python==3.10.6 -y
conda activate fastchat
3-2. 克隆代码
git clone https://github.com/lm-sys/FastChat.git; cd FastChat
pip install --upgrade pip # enable PEP 660 support
3-3. 安装依赖库
pip install -e .
pip install transformers_stream_generator
pip install cpm_kernels
3-4. 使用命令行进行推理
python -m fastchat.serve.cli --model-path baichuan-inc/Baichuan-13B-Chat
问它几个问题,问题和答案截图如下,

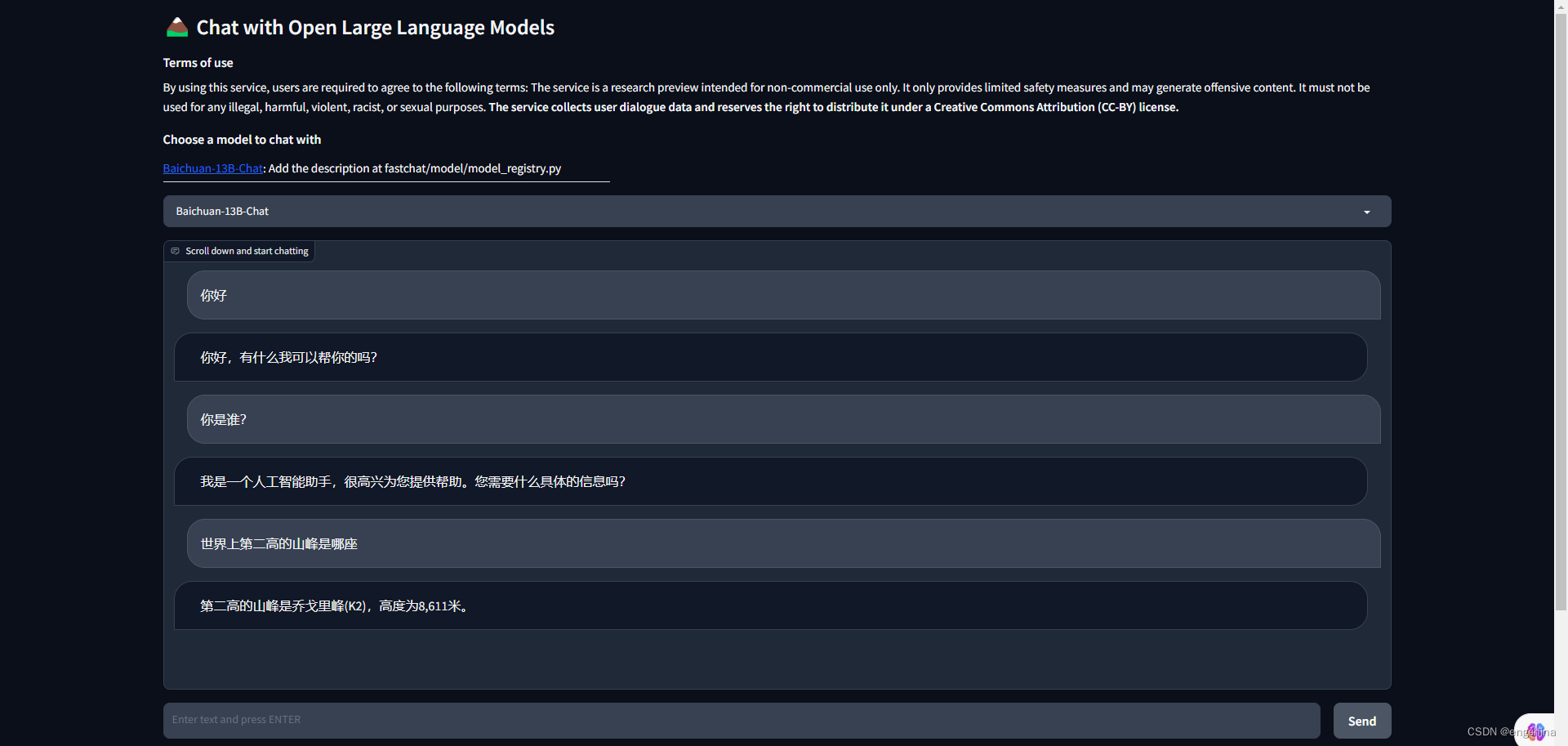
3-5. 使用 UI 进行推理
启动 controller,
python3 -m fastchat.serve.controller
启动 model worker(s),
python3 -m fastchat.serve.model_worker --model-path baichuan-inc/Baichuan-13B-Chat
启动 Gradio web server,
python3 -m fastchat.serve.gradio_web_server
问它几个问题,问题和答案截图如下,
3-6. 使用 OpenAI API 方式进行推理
启动 controller,
python3 -m fastchat.serve.controller
启动 model worker(s),
python3 -m fastchat.serve.model_worker --model-names "gpt-3.5-turbo,text-davinci-003,text-embedding-ada-002" --model-path baichuan-inc/Baichuan-13B-Chat
# If you do not have enough memory, you can enable 8-bit compression by adding --load-8bit to commands above.
# In addition to that, you can add --cpu-offloading to commands above to offload weights that don't fit on your GPU onto the CPU memory.
# python3 -m fastchat.serve.model_worker --model-names "gpt-3.5-turbo,text-davinci-003,text-embedding-ada-002" --load-8bit --cpu-offload --model-path baichuan-inc/Baichuan-13B-Chat
启动 RESTful API server,
python3 -m fastchat.serve.openai_api_server --host localhost --port 8000
设置 OpenAI base url,
export OPENAI_API_BASE=http://localhost:8000/v1
设置 OpenAI API key,
export OPENAI_API_KEY=EMPTY
问它几个问题,代码和答案截图如下,
import os
import openaifrom dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
os.environ['OPENAI_API_KEY'] = 'EMPTY'
os.environ['OPENAI_API_BASE'] = 'http://localhost:8000/v1'
openai.api_key = 'none'
openai.api_base = 'http://localhost:8000/v1'
def get_completion(prompt, model="gpt-3.5-turbo"):messages = [{"role": "user", "content": prompt}]response = openai.ChatCompletion.create(model=model,messages=messages,temperature=0,)return response.choices[0].message["content"]
get_completion("你是谁?")

get_completion("世界上第二高的山峰是哪座")

get_completion("鲁迅和周树人是什么关系?")

(可选)如果在创建嵌入时遇到 OOM 错误,请使用环境变量设置较小的 BATCH_SIZE,
export FASTCHAT_WORKER_API_EMBEDDING_BATCH_SIZE=1
(可选)如果遇到超时错误,
export FASTCHAT_WORKER_API_TIMEOUT=1200
refer1: https://github.com/lm-sys/FastChat/blob/main/docs/langchain_integration.md
refer2:https://github.com/lm-sys/FastChat
3-7. 量化部署
修改 model/model_adapter.py 中 class BaichuanAdapter 的内容如下,实现量化部署。
class BaichuanAdapter(BaseModelAdapter):"""The model adapter for baichuan-inc/baichuan-7B"""def match(self, model_path: str):return "baichuan" in model_pathdef load_model(self, model_path: str, from_pretrained_kwargs: dict):revision = from_pretrained_kwargs.get("revision", "main")tokenizer = AutoTokenizer.from_pretrained(model_path,use_fast=False,trust_remote_code=True,revision=revision)model = AutoModelForCausalLM.from_pretrained(model_path,trust_remote_code=True,**from_pretrained_kwargs,)model = model.quantize(8).cuda()model.generation_config = GenerationConfig.from_pretrained(model_path)return model, tokenizer
完结!

![[Unity3D] 协程](https://img-blog.csdnimg.cn/dedc746e633a4036afed227dfe7be6cd.jpeg)