文章目录
- 一、NIO(Non-blocking I/O,非阻塞I/O)
- 1、Channel(通道)与Buffer(缓冲区)
- 1.1、使用ByteBuffer读取文件
- 1.2、ByteBuffer 方法
- 1.2、ByteBuffer 结构
- 1.3、字符串与 ByteBuffer 互转
- 1.4 Scattering Reads:分散读取
- 1.5、Gathering Writes:集中写入
- 2、Selector(选择器)
- 3、多路复用
- 4、NIO的作用
- 二、BIO(Blocking I/O,阻塞I/O)
- 1、内容简介
- 2、示例简介
- 三、阻塞与非阻塞示例对比
- 1、阻塞示例
- 2、非阻塞示例
一、NIO(Non-blocking I/O,非阻塞I/O)
NIO( Non-blocking I/O,非阻塞I/O),在Java领域也称为New I/O,是一种 同步非阻塞 的I/O模型,也是 I/O多路复用 的基础。NIO已经被越来越多地应用到大型应用服务器,成为解决高并发与大量连接、I/O处理问题的有效方式。
NIO主要有三大核心部分:
Channel(通道):通道是数据传输的通道,用于连接设备并进行数据的读写操作。Buffer(缓冲区):缓冲区则是数据的中转站,用于存储通道读写的数据。Selector(选择器):选择器则是用于监听多个通道的状态变化,以实现I/O多路复用。
NIO的使用,主要涉及到以下几个步骤:
打开通道:通过调用相关方法打开通道,如FileChannel用于文件读写,SocketChannel用于网络通信等。创建缓冲区:创建合适类型的缓冲区,用于存储通道读写的数据。进行数据读写:通过通道和缓冲区进行数据读写操作。可以使用缓冲区的put()方法向缓冲区写入数据,使用get()方法从缓冲区读取数据。关闭通道:完成数据读写后,需要关闭通道以释放资源。
此外,NIO还提供了选择器(Selector)用于监听多个通道的状态变化。通过选择器,可以注册感兴趣的通道,并在通道状态发生变化时得到通知,从而实现I/O多路复用。
1、Channel(通道)与Buffer(缓冲区)
Channel(通道)表示打开到IO设备(如文件、套接字)的连接,它提供了 异步和双向的数据传输能力 ,可以更加高效地处理IO操作。与传统的IO流中的Stream相比,Channel允许我们 同时读取和写入数据 ,实现了 数据的双向流动 。此外,Channel的读写操作可以是异步的,这意味着读写操作可以在不阻塞当前线程的情况下进行,提高了系统的并发性和响应速度。
Buffer(缓冲区)则是一个用于特定基本数据类型的容器,它本质上是一个 内存块 ,既可以写入数据,也可以从中读取数据。在Java NIO中,Buffer主要用于与Channel进行交互。 数据从Channel读入Buffer,再从Buffer写入Channel,实现了数据的存储和传输 。Buffer内部有一些机制能够跟踪和记录缓冲区的状态变化情况,比如使用get()方法从缓冲区获取数据或者使用put()方法把数据写入缓冲区,都会引起缓冲区状态的变化。
Channel和Buffer之间的联系主要体现在它们共同协作完成数据的传输和存储。
Channel负责从IO设备中读取数据到Buffer,或者将Buffer中的数据写入到IO设备中。而Buffer则负责在内存中存储这些数据,供程序进行读取和写入操作。这种分工合作的方式使得Java NIO在处理大量数据时能够保持高效和稳定。
在Java NIO中,Channel(通道)和Buffer(缓冲区)是两个核心概念。
常见的Channel类型主要有以下四种,这四种通道类型涵盖了文件IO、TCP网络、UDP IO三类基础IO读写操作。
FileChannel:这是专门操作文件的通道,用于文件的数据读写。SocketChannel:这是套接字通道,主要用于套接字TCP连接的数据读写。ServerSocketChannel:这是服务器套接字通道(或称为服务器监听通道),它允许监听TCP连接请求,并为每个监听的请求创建一个SocketChannel通道。DatagramChannel:这是数据报通道,主要用于UDP的数据读写。
常见的Buffer类型主要包括以下几种,这些Buffer类型对应于Java的主要数据类型,并覆盖了能在IO中传输的所有Java基本数据类型。
ByteBuffer:字节缓冲器,用于存储字节数据。CharBuffer:字符缓冲器,用于存储字符数据。ShortBuffer:短整型缓冲器,用于存储短整型数据。IntBuffer:整型缓冲器,用于存储整型数据。LongBuffer:长整型缓冲器,用于存储长整型数据。FloatBuffer:浮点型缓冲器,用于存储浮点型数据。DoubleBuffer:双精度浮点型缓冲器,用于存储双精度浮点型数据。MappedByteBuffer:这是专门用于内存映射的一种ByteBuffer类型。
1.1、使用ByteBuffer读取文件
有一普通文本文件 data.txt,内容为:
1234567890abcd
使用 FileChannel 来读取文件内容,里面的具体方法会在代码下面进行解释。
@Slf4j
public class ChannelDemo1 {public static void main(String[] args) {try (RandomAccessFile file = new RandomAccessFile("helloword/data.txt", "rw")) {FileChannel channel = file.getChannel();ByteBuffer buffer = ByteBuffer.allocate(10);do {// 向 buffer 写入int len = channel.read(buffer);log.debug("读到字节数:{}", len);if (len == -1) {break;}// 切换 buffer 读模式buffer.flip();while(buffer.hasRemaining()) {log.debug("{}", (char)buffer.get());}// 切换 buffer 写模式buffer.clear();} while (true);} catch (IOException e) {e.printStackTrace();}}
}
输出
10:39:03 [DEBUG] [main] c.i.n.ChannelDemo1 - 读到字节数:10
10:39:03 [DEBUG] [main] c.i.n.ChannelDemo1 - 1
10:39:03 [DEBUG] [main] c.i.n.ChannelDemo1 - 2
10:39:03 [DEBUG] [main] c.i.n.ChannelDemo1 - 3
10:39:03 [DEBUG] [main] c.i.n.ChannelDemo1 - 4
10:39:03 [DEBUG] [main] c.i.n.ChannelDemo1 - 5
10:39:03 [DEBUG] [main] c.i.n.ChannelDemo1 - 6
10:39:03 [DEBUG] [main] c.i.n.ChannelDemo1 - 7
10:39:03 [DEBUG] [main] c.i.n.ChannelDemo1 - 8
10:39:03 [DEBUG] [main] c.i.n.ChannelDemo1 - 9
10:39:03 [DEBUG] [main] c.i.n.ChannelDemo1 - 0
10:39:03 [DEBUG] [main] c.i.n.ChannelDemo1 - 读到字节数:4
10:39:03 [DEBUG] [main] c.i.n.ChannelDemo1 - a
10:39:03 [DEBUG] [main] c.i.n.ChannelDemo1 - b
10:39:03 [DEBUG] [main] c.i.n.ChannelDemo1 - c
10:39:03 [DEBUG] [main] c.i.n.ChannelDemo1 - d
10:39:03 [DEBUG] [main] c.i.n.ChannelDemo1 - 读到字节数:-1
1.2、ByteBuffer 方法
Buffer 是非线程安全的
分配空间: 可以使用 allocate 方法为 ByteBuffer 分配空间,其它 buffer 类也有该方法。
Bytebuffer buf = ByteBuffer.allocate(16);
向 buffer 写入数据:
- 调用 channel 的 read 方法
- 调用 buffer 自己的 put 方法
int readBytes = channel.read(buf);
buf.put((byte)127);
切换至读模式:
buffer.flip()
从 buffer 读取数据:
- 调用 channel 的 write 方法
- 调用 buffer 自己的 get 方法
int writeBytes = channel.write(buf);
byte b = buf.get();
get 方法会让 position 读指针向后走,如果想重复读取数据
- 可以调用 rewind 方法将 position 重新置为 0
- 或者调用 get(int i) 方法获取索引 i 的内容,它不会移动读指针
切换至写模式:
buffer.clear();
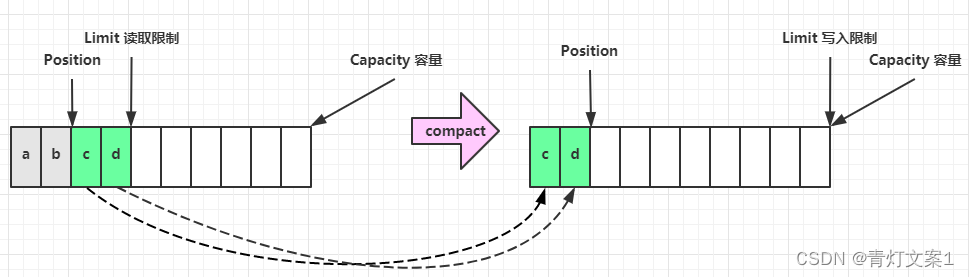
buffer.compact();
mark 和 reset
mark 是在读取时,做一个标记,即使 position 改变,只要调用 reset 就能回到 mark 的位置。
但是要注意:rewind 和 flip 都会清除 mark 位置
1.2、ByteBuffer 结构
capacity:容量,一般初始时要设置。position:写入位置和读取位置。limit:可表示容量,写入限制或者读取限制。
ByteBuffer 的初始状态:
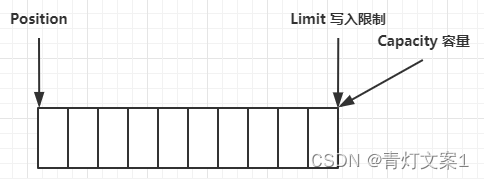
写模式下,position 是写入位置,limit 等于容量,下图表示写入了 4 个字节后的状态
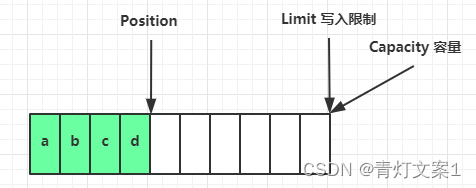
flip 动作发生后,position 切换为读取位置,limit 切换为读取限制
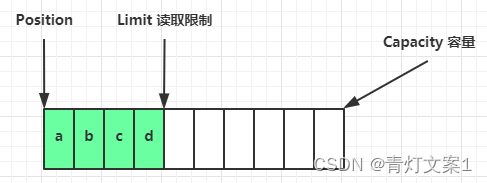
读取 4 个字节后,状态
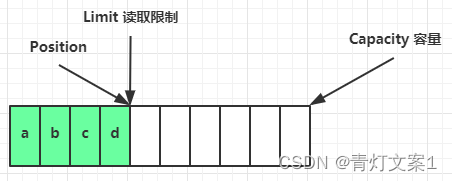
clear 动作发生后,状态
1.3、字符串与 ByteBuffer 互转
ByteBuffer buffer1 = StandardCharsets.UTF_8.encode("你好");
ByteBuffer buffer2 = Charset.forName("utf-8").encode("你好");debug(buffer1);
debug(buffer2);CharBuffer buffer3 = StandardCharsets.UTF_8.decode(buffer1);
System.out.println(buffer3.getClass());
System.out.println(buffer3.toString());
输出
+-------------------------------------------------+| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| e4 bd a0 e5 a5 bd |...... |
+--------+-------------------------------------------------+----------------++-------------------------------------------------+| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| e4 bd a0 e5 a5 bd |...... |
+--------+-------------------------------------------------+----------------+
class java.nio.HeapCharBuffer
你好
1.4 Scattering Reads:分散读取
有一个文本文件 3parts.txt
onetwothree
使用如下方式读取,可以将数据填充至多个 buffer
try (RandomAccessFile file = new RandomAccessFile("helloword/3parts.txt", "rw")) {FileChannel channel = file.getChannel();ByteBuffer a = ByteBuffer.allocate(3);ByteBuffer b = ByteBuffer.allocate(3);ByteBuffer c = ByteBuffer.allocate(5);channel.read(new ByteBuffer[]{a, b, c});a.flip();b.flip();c.flip();debug(a);debug(b);debug(c);
} catch (IOException e) {e.printStackTrace();
}
结果
+-------------------------------------------------+| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 6f 6e 65 |one |
+--------+-------------------------------------------------+----------------++-------------------------------------------------+| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 74 77 6f |two |
+--------+-------------------------------------------------+----------------++-------------------------------------------------+| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 74 68 72 65 65 |three |
+--------+-------------------------------------------------+----------------+
1.5、Gathering Writes:集中写入
使用集中写入,可以将多个 buffer 的数据填充至 channel
try (RandomAccessFile file = new RandomAccessFile("helloword/3parts.txt", "rw")) {FileChannel channel = file.getChannel();ByteBuffer d = ByteBuffer.allocate(4);ByteBuffer e = ByteBuffer.allocate(4);channel.position(11);d.put(new byte[]{'f', 'o', 'u', 'r'});e.put(new byte[]{'f', 'i', 'v', 'e'});d.flip();e.flip();debug(d);debug(e);channel.write(new ByteBuffer[]{d, e});
} catch (IOException e) {e.printStackTrace();
}
输出
+-------------------------------------------------+| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 66 6f 75 72 |four |
+--------+-------------------------------------------------+----------------++-------------------------------------------------+| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 66 69 76 65 |five |
+--------+-------------------------------------------------+----------------+
2、Selector(选择器)
在Java的NIO(New I/O)库中,Selector 是一个关键组件,它允许单个线程同时处理多个通道(Channel)上的I/O操作。你可以把 Selector 看作是一个可以监听多个通道上事件(如数据到达、通道就绪等)的监听器。这样,你就可以使用非阻塞I/O来实现高性能的I/O操作,而无需为每个通道都创建一个线程。
用一个生动的例子来解释 Selector 的工作原理:
想象一下,你是一家大型餐厅的老板,你的餐厅有很多桌子(通道),每个桌子上都可能坐着等待上菜的顾客。然而,你不可能一直在每张桌子旁边等待顾客点餐或询问是否需要更多服务,因为这样会非常低效。
为了更高效地管理这些桌子,你决定使用一个“服务员选择器”(Selector)。这个选择器会周期性地查看每张桌子,看看是否有顾客需要服务。具体来说,它可能会查看:
- 是否有顾客刚刚坐下并准备点餐(新的连接请求)。
- 是否有顾客举手示意服务员(数据到达,例如顾客点餐完成)。
- 是否有顾客已经离开并需要清理桌子(通道关闭)。
在这个例子中:
- 每张桌子就是一个
Channel(比如TCP套接字通道)。 - 服务员选择器(
Selector)就是用来监听这些桌子(通道)上事件的对象。 - 顾客举手示意服务员(数据到达)就是一个“就绪”事件,服务员(线程)可以处理这个事件,比如把菜品送到顾客的桌子上。
以下是一个简化的Java NIO代码示例,展示了如何使用 Selector:
Selector selector = Selector.open();// 假设我们有两个SocketChannel,channel1和channel2
SocketChannel channel1 = ...; // 创建并配置为非阻塞模式
SocketChannel channel2 = ...; // 创建并配置为非阻塞模式// 将channel注册到selector上,并指定我们关心的事件类型(如OP_READ)
channel1.register(selector, SelectionKey.OP_READ);
channel2.register(selector, SelectionKey.OP_READ);while (true) {// 等待至少一个通道就绪int readyChannels = selector.select();if (readyChannels == 0) continue;// 获取就绪的通道集合Set<SelectionKey> selectedKeys = selector.selectedKeys();Iterator<SelectionKey> keyIterator = selectedKeys.iterator();while (keyIterator.hasNext()) {SelectionKey key = keyIterator.next();if (key.isAcceptable()) {// 有新的连接请求,处理它...} else if (key.isReadable()) {// 数据已到达,从对应的通道读取数据...SocketChannel channel = (SocketChannel) key.channel();// ...读取数据...}// 处理完事件后,从集合中移除该键,避免重复处理keyIterator.remove();}
}
这个示例展示了如何使用 Selector 来监听多个 SocketChannel 上的事件,并在事件发生时进行相应的处理。通过这种方式,你可以实现高效的、基于事件的I/O处理,而无需为每个通道都创建一个线程。
3、多路复用
单线程可以配合 Selector 完成对多个 Channel 可读写事件的监控,这称之为多路复用。
- 多路复用仅针对网络 IO、普通文件 IO 没法利用多路复用。
- 如果不用 Selector 的非阻塞模式,线程大部分时间都在做无用功,而 Selector 能够保证。
- 有可连接事件时才去连接。
- 有可读事件才去读取。
- 有可写事件才去写入。
- 限于网络传输能力,Channel 未必时时可写,一旦 Channel 可写,会触发 Selector 的可写事件。
4、NIO的作用
- 提高系统的并发性能:NIO的非阻塞特性使得线程在等待I/O操作完成时可以继续执行其他任务,从而提高了系统的并发性能。
- 减少资源消耗:NIO通过I/O多路复用技术,可以用一个线程来管理多个通道,减少了线程切换的开销,降低了资源消耗。
- 适用于超大量长时间连接场景:NIO适用于需要支持大量长时间连接的场景,如服务器需要收集各个客户端的少量数据的情况。
需要注意的是,NIO的编程模型相对于传统的BIO(Blocking IO,阻塞IO)更为复杂,需要更多的理解和实践才能熟练掌握。同时,在选择使用NIO还是BIO时,需要根据具体的业务场景和需求进行权衡和选择。
总之,NIO是一种高效、灵活的I/O处理方式,适用于高并发、大量连接和I/O处理的场景。通过深入理解NIO的原理和使用方法,可以更好地利用NIO的优势,提高系统的性能和响应能力。
二、BIO(Blocking I/O,阻塞I/O)
在Java中,阻塞I/O(Blocking I/O)是一种常见的I/O模型。它描述了一种情况,即当一个线程发起一个I/O操作(如读或写)时,该线程会等待该操作完成,而在此期间,线程无法执行其他任务。只有当I/O操作完成后,线程才会继续执行后续的代码。
1、内容简介
阻塞I/O的主要包括以下几点:
- 线程等待:当线程发起I/O操作时,如果没有数据可读或可写,线程会被挂起,即进入等待状态。
- 操作完成:只有当I/O操作真正完成(例如,数据被读取或写入)后,线程才会从等待状态恢复,并继续执行后续的代码。
- 顺序执行:在阻塞I/O模型中,I/O操作是顺序执行的,即一个操作完成后,下一个操作才会开始。
阻塞I/O的作用体现在:
- 简化编程模型:对于简单的、顺序的I/O操作,阻塞I/O模型提供了一个直观且易于理解的编程方式。
- 资源利用:在某些情况下,阻塞I/O可以更有效地利用系统资源,因为它
避免了不必要的线程切换和上下文切换。
在Java中,使用阻塞I/O主要涉及以下几个步骤:
- 创建流:首先需要创建适当的输入流(如
FileInputStream)或输出流(如FileOutputStream)。 - 读写操作:使用流对象的
read()或write()方法进行数据的读取或写入。如果数据尚未准备好或写入尚未完成,线程将阻塞。 - 处理异常:注意处理可能出现的
IOException,这是I/O操作中常见的异常。 - 关闭流:完成I/O操作后,记得关闭流以释放资源。
2、示例简介
以下是一个简单的Java阻塞I/O示例,它展示了如何使用FileInputStream从文件中读取数据:
import java.io.FileInputStream;
import java.io.IOException;public class BlockingIOExample {public static void main(String[] args) {FileInputStream fis = null;try {fis = new FileInputStream("example.txt");byte[] buffer = new byte[1024];int bytesRead;while ((bytesRead = fis.read(buffer)) != -1) {// 处理读取到的数据}} catch (IOException e) {e.printStackTrace();} finally {if (fis != null) {try {fis.close();} catch (IOException e) {e.printStackTrace();}}}}
}
在这个示例中,当 fis.read(buffer) 被调用时,如果文件 example.txt 中没有更多的数据可读,线程将会阻塞,直到有数据可读或文件结束为止。
虽然阻塞I/O在某些情况下是简单且有效的,但在高并发或需要处理大量I/O操作的场景中,它可能会导致性能问题,因为线程在等待I/O操作完成时会处于空闲状态。在这种情况下,可以考虑使用Java NIO(非阻塞I/O)或其他并发编程技术来提高性能。
三、阻塞与非阻塞示例对比
1、阻塞示例
- 阻塞模式下,相关方法都会导致线程暂停。
ServerSocketChannel.accept会在没有连接建立时让线程暂停。- SocketChannel.read 会在没有数据可读时让线程暂停.
- 阻塞的表现其实就是线程暂停了,暂停期间不会占用 cpu,但线程相当于闲置。
- 单线程下,阻塞方法之间相互影响,几乎不能正常工作,需要多线程支持。
- 但多线程下,有新的问题,体现在以下方面。
- 32 位 jvm 一个线程 320k,64 位 jvm 一个线程 1024k,如果连接数过多,必然导致 OOM,并且线程太多,反而会因为频繁上下文切换导致性能降低。
- 可以采用线程池技术来减少线程数和线程上下文切换,但治标不治本,如果有很多连接建立,但长时间 inactive,会阻塞线程池中所有线程,因此不适合长连接,只适合短连接。
服务器端
// 使用 nio 来理解阻塞模式, 单线程
// 0. ByteBuffer
ByteBuffer buffer = ByteBuffer.allocate(16);
// 1. 创建了服务器
ServerSocketChannel ssc = ServerSocketChannel.open();// 2. 绑定监听端口
ssc.bind(new InetSocketAddress(8080));// 3. 连接集合
List<SocketChannel> channels = new ArrayList<>();
while (true) {// 4. accept 建立与客户端连接, SocketChannel 用来与客户端之间通信log.debug("connecting...");SocketChannel sc = ssc.accept(); // 阻塞方法,线程停止运行log.debug("connected... {}", sc);channels.add(sc);for (SocketChannel channel : channels) {// 5. 接收客户端发送的数据log.debug("before read... {}", channel);channel.read(buffer); // 阻塞方法,线程停止运行buffer.flip();debugRead(buffer);buffer.clear();log.debug("after read...{}", channel);}
}
客户端
SocketChannel sc = SocketChannel.open();
sc.connect(new InetSocketAddress("localhost", 8080));
System.out.println("waiting...");
2、非阻塞示例
- 非阻塞模式下,相关方法都会不会让线程暂停。
- 在
ServerSocketChannel.accept在没有连接建立时,会返回 null,继续运行。 SocketChannel.read在没有数据可读时,会返回 0,但线程不必阻塞,可以去执行其它SocketChannel的read或是去执行ServerSocketChannel.accept。- 写数据时,线程只是等待数据写入 Channel 即可,无需等 Channel 通过网络把数据发送出去。
- 在
- 但非阻塞模式下,即使没有连接建立,和可读数据,线程仍然在不断运行,白白浪费了 cpu。
- 数据复制过程中,线程实际还是阻塞的(AIO 改进的地方)。
服务器端,客户端代码不变
// 使用 nio 来理解非阻塞模式, 单线程
// 0. ByteBuffer
ByteBuffer buffer = ByteBuffer.allocate(16);
// 1. 创建了服务器
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.configureBlocking(false); // 非阻塞模式
// 2. 绑定监听端口
ssc.bind(new InetSocketAddress(8080));
// 3. 连接集合
List<SocketChannel> channels = new ArrayList<>();
while (true) {// 4. accept 建立与客户端连接, SocketChannel 用来与客户端之间通信SocketChannel sc = ssc.accept(); // 非阻塞,线程还会继续运行,如果没有连接建立,但sc是nullif (sc != null) {log.debug("connected... {}", sc);sc.configureBlocking(false); // 非阻塞模式channels.add(sc);}for (SocketChannel channel : channels) {// 5. 接收客户端发送的数据int read = channel.read(buffer);// 非阻塞,线程仍然会继续运行,如果没有读到数据,read 返回 0if (read > 0) {buffer.flip();debugRead(buffer);buffer.clear();log.debug("after read...{}", channel);}}
}