ClickHouse高原理与实践
- 1 ClickHouse的特性
- 1.1. OLAP
- 1.2. 列式存储
- 1.3. 表引擎
- 1.4. 向量化执行
- 1.5. 分区
- 1.6. 副本与分片
- 1.7 其他特性
- 2. ClickHouse模块设计
- 2.1 Parser分析器与Interpreter解释器
- 2.2 Storage
- 2.3 Column与Field
- 2.4 DataType
- 2.5 Block
- 2.6 Cluster与Replication
- 3. MergeTree表引擎
- 3.1 数据分区
- 3.2 分区目录生成规则
- 3.3 存储结构
- 3.4 一级索引
- 3.5 压缩数据块
- 3.6. 数据标记文件
- 3.7 数据查询和写入过程
- 4. 分片与副本的原理
- 4.1 ZooKeeper在ClickHouse中的作用
- 4.2 Distributed表
- 5. ClickHouse实践
- 6. 疑问和思考
- 7. 参考文档
ClickHouse是俄罗斯公司Yandex研发的一款开源的,用于OLAP( Online Analytical Processing,联机分析,即通过多种不同的维度审视数据。OLAP具有多维度、快速响应、聚合计算、数据切片等特点)的列式存储的数据库管理系统。
ClickHouse名称的来源是Click Stream,Data WareHouse,即基于点击事件流的数据仓库。
ClickHouse设计的初衷就是以最快的速度进行GROUP BY查询和过滤,它充分利用了列式存储,数据压缩,向量化执行,数据分片等架构特性,并且在算法选择上精益求精,因此具备了极高的实时查询性能。
ClickHouse是一款关系型数据库,支持了大部分标准SQL,具备完备的DBMS功能(DDL、DML、权限控制、数据备份与恢复、分布式管理),因此使用起来较友好。
1 ClickHouse的特性
1.1. OLAP
ClickHouse是一个OLAP数据库。OLAP(Online Analytical Processing),即联机分析处理或多维分析,它指的是通过多种不同的维度审视数据,通常会涉及到复杂的聚合计算。体现在关系模型的数据库,我们查看某个维度的数据,就是通过聚合函数计算指标数据并汇总(GROUP BY)到这个维度。在数据量非常大,汇总维度非常多的情况下,就会对数据库的性能要求非常高,而ClickHouse正是为了解决这个场景的问题而诞生的。
广告投放业务的数据BI,就是一种典型的OLAP场景:从媒体拉取的展点消数据和计算的用户行为的转化数据的数据量非常庞大,用户希望在时间、媒体、代理商、平台、账户、广告组、素材等多个维度自定义地组合起来查看和分析数据。
1.2. 列式存储
ClickHouse是列式存储的数据库,数据按列组织存储到一起,它的特点是:
- 缩小查询数据时扫描数据的范围,比如一张表有50个列,我们需要取其中5个列分析,那么列式存储只需要扫描这5个列的列数据即可,而行式存储则需要扫描所有数据,再对每行数据取出这5个列;
- 利于数据压缩,同一列的数据,其业务含义相同,则数据重复的可能性会更高,进而数据压缩时压缩率更高;
- 查询时数据扫描范围更小,数据传输大小也更小,所以列式存储的数据库有优秀的查询性能。
- 相对的是写操作时,行存储数据库只需要找到该行数据对应的索引位置写入数据即可,而列式存储需要将数据的每个列写入相应的列存储文件,因此列式存储数据库写性能不佳。

1.3. 表引擎
ClickHouse为适配不同业务场景,提供了几十种表引擎:
- MergeTree(合并树)家族:最常用的引擎,它具有支持索引、数据分区、数据副本的特点;
- 基于外部存储构建表的表引擎:HDFS、MySQL、Kafka等,其特点是直接其他存储系统读写数据,相当于对其他存储系统做了一个代理;
- 面向内存查询的表引擎:Memory、Set、Buffer等,此类表引擎在数据表被加载时,会将数据全部加载至内存,因此其拥有良好的查询性能。Memory表引擎被作为临时表而广泛地应用于ClickHouse内部;Set表引擎则具有去重的能力,且拥有物理存储,数据不会丢失,但是Set表引擎不能被查询,只能作为IN语句的右侧条件;
- Log家族表引擎:为小数据量(百万级以下),一次写入多次查询的场景而设计,拥有物理存储;
- 接口类型: Merge、 Dictionary 、Distributed,它们不是存储数据的表引擎,而是用于整合其他数据表。Merge表引擎可以作为代理查询任意数据的数据表,并最终合成一个结果集返回; Dictionary表引擎是数据字典的一层代理封装,它可以取代字典函数,让用户通过数据表查询字典; Distributed表引擎是分布式表的代理,用于分发读写请求到集群中的各个节点;
1.4. 向量化执行
向量化执行是一种将数据转换为向量形式以进行计算和分析的方法。其主要思想是将数据存储在多维数组或矩阵中,并通过使用向量和矩阵操作来执行计算。这种方法可以利用底层硬件的并行性,并且通常比使用循环和条件语句的传统方法更高效。
ClickHouse使用了CPU的SIMD指令(Single Instruction Multiple Data,即用单条指令操作多条数据),实现了向量化执行。基于向量化执行和列式存储,优化了循环处理的场景,从而提升了逻辑计算的性能。
1.5. 分区
定义:MergeTree家族表引擎的表支持数据分区,把数据按分区键区分,每个分区用单独的文件存储。这里的分区是对本地数据(同一个节点)的纵向切分,并不是把分区分到不同节点;
目的:ClickHouse分区的目的是在查询时缩小扫描数据的范围,从而提升查询性能;
使用:创建MergeTree家族表的时候可以通过PARTITION BY语句指定分区键, ClickHouse按分区键生成分区目录,插入数据时属于同一个分区的数据会被合并到同一个分区目录;
其他:MergeTree家族表引擎的特性都是基于同一个分区的数据的,比如具有去重能力的ReplacingMergeTree,它只能保证同一个分区的数据是不重复的;
1.6. 副本与分片
副本:ClickHouse的Replicated家族(以Replicated为前缀)的表引擎支持数据副本,如ReplicatedMergeTree ,ClickHouse通过ZooKeeper的分布式协同的能力实现副本之间的同步,它是多主架构,可以在任意副本上执行读写操作。通过数据副本, ClickHouse降低了丢失数据的风险;
分片:ClickHouse的Distributed表引擎支持数据分片(数据水平切分,将数据分布到不同的节点)。通过数据分片的能力,降低单个节点处理的数据容量,从而提升性能;
1.7 其他特性
完备的DBMS((Database Management System)功能:支持DDL(动态创建、修改、删除库表)、DML(增删查改)、权限控制(用户粒度设置库表操作权限)、数据备份与恢复(提供数据导出导入功能)、分布式管理(集群模式,自动管理多个数据库节点)等;
关系型数据库:ClickHouse是关系型数据库,使用表、行和列来组织和管理数据。提供了数据库、表、视图、函数等传统数据库的概念,并支持大部分标准SQL;
多主架构:集群中的每个节点角色对等,该架构的优点是资源利用率较高的同时降低了单点故障的风险;缺点是节点间数据同步延迟问题和同步难度大;
2. ClickHouse模块设计
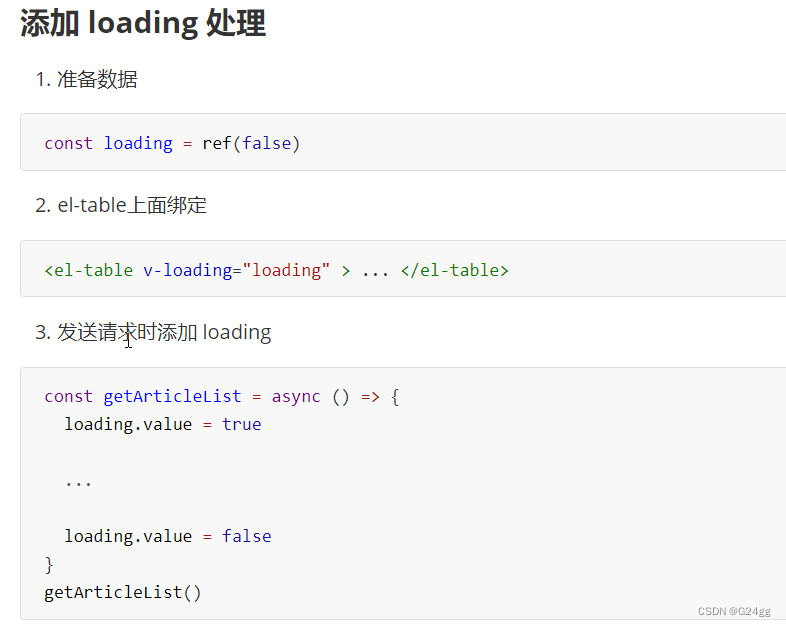
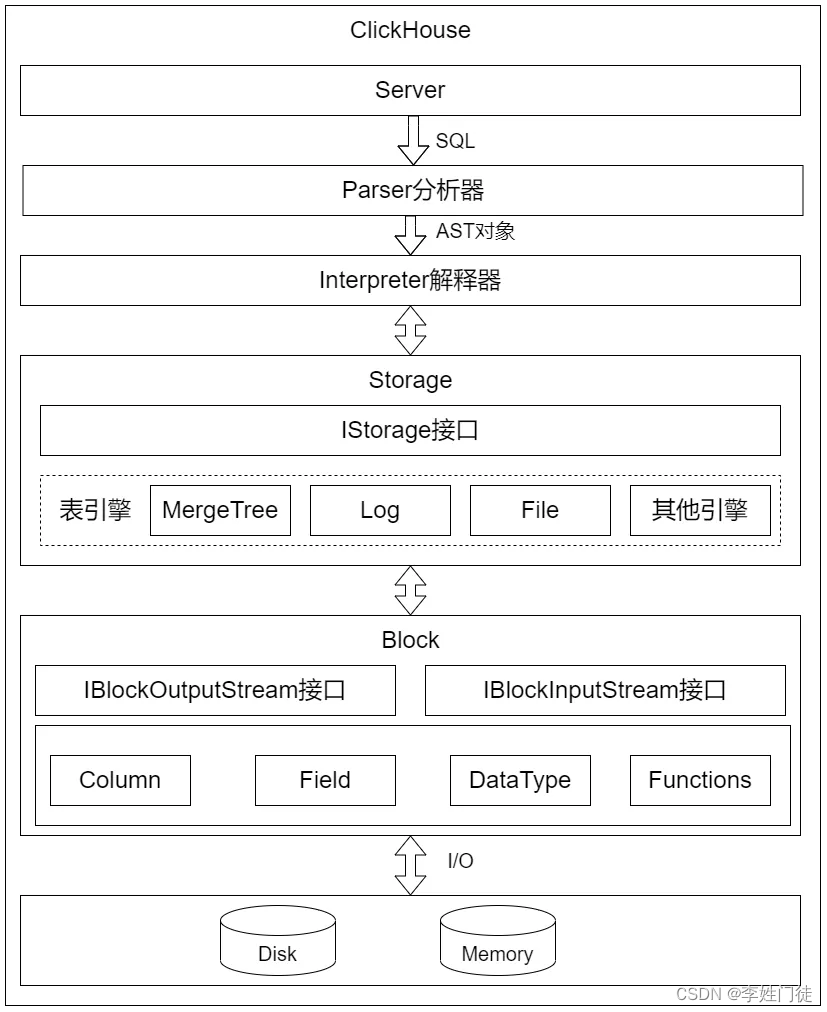
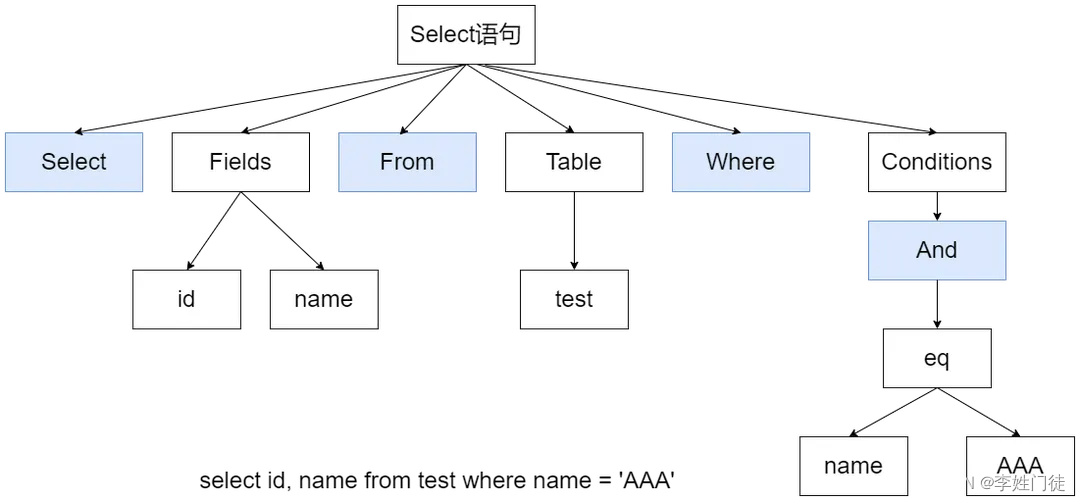
ClickHouse处理SQL时:
- 首先由Parser分析器解析SQL,创建AST( Abstract Syntax Tree ,抽象语法树)对象。
- 然后由Interpreter解释器解释AST对象,聚合所需的资源,执行分支判断、设置参数等业务逻辑,并根据表引擎调用相应IStorage接口。
- IStorage根据AST查询语句的指示要求,返回IBlockStream对象。
- 最后Interpreter通过IBlockStream对象建立查询执行管道,完成数据查询和进一步的处理等。
2.1 Parser分析器与Interpreter解释器
Parser分析器负责解析SQL,创建AST对象,根据SQL语句类型(Select、Insert、Update、Alter等)不同,由不同的Parser进行解析处理。 Intercepter解释器解析AST对象,创建查询的执行管道,执行分支判断、设置参数、调用IStorage接口等业务逻辑,最后返回IBlock对象,以线程的形式建立起一个查询执行管道。
2.2 Storage
ClickHouse底层设计没有Table对象,而是用IStorage接口,定义了DDL、read和write方法。IStorage根据AST查询语句的要求,返回指定列的原始数据,并交由Intercepter进一步对数据进行加工、计算和过滤。 IStorage接口的函数,根据表引擎的不同,由不同的子类实现。
2.3 Column与Field
ClickHouse是列式存储数据库,内存中的一列数据用一个Column对象表示。IColumn接口定义了对数据进行各种关系运算的方法(例如插入数据的insertRangeFrom和insertFrom方法、用于分页的cut、用于过滤的filter方法),这些方法根据数据类型的不同,由相应的对象实现(ColumnString、ColumnUInt8等)。 如果需要操作单列中的一行数据,则需要使用Field对象。Field对象使用了聚合的设计模式,其内部聚合了Null、UInt64、String和Array等13种数据类型及相应的处理逻辑。
2.4 DataType
DataType负责数据的序列化和反序列化,根据数据格式不同,IDataType接口定义了多种正反序列化的方法。具体实现也是根据数据类型不同,由不同的对象实现,如DataTypeString、DataTypeArray。 Datatype不负责数据的读取,而是聚合了Column和Field,由后者读取数据。
2.5 Block
Block对象负责处理ClickHouse内部的数据操作,它的本质是由Column、DataType和列名字符串构成的三元组。Block对象对Column和DataType做了进一步的抽象和封装,简化了使用过程,从而仅通过Block对象就能完成一系列的数据操作。 Block以流的形式操作数据,流操作有两个顶层接口,IBlockInputStream负责数据的读取和关系运算,IBlockOutputStream负责将数据输出到下一环节。基于不同的表引擎,和不同的操作类型,IBlockInputStream接口共有60多个实现类,IBlockOutputStream接口有20多种实现类。
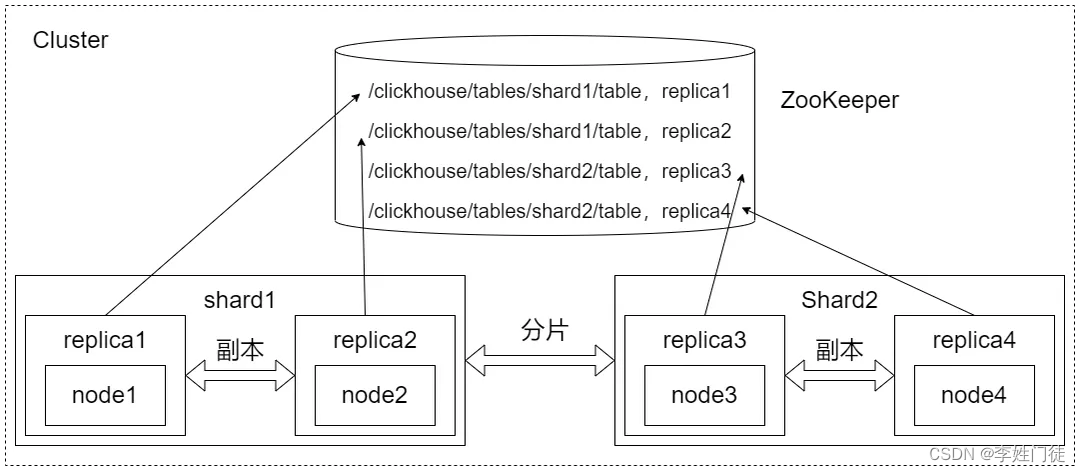
2.6 Cluster与Replication
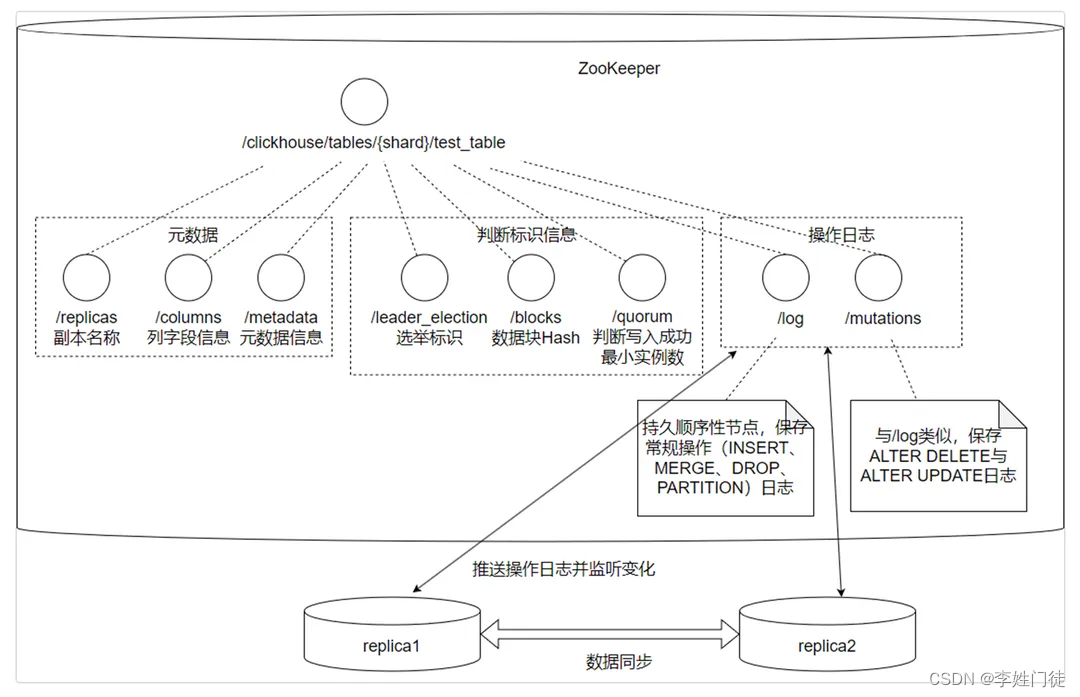
ClickHouse的集群由分片(Shard)组成,每个分片通过副本(Replica)组成,ClickHouse的1个节点(Node)只能拥有1个分片,分片只是一个物理概念,其物理承载由副本承担。 ClickHouse副本之间数据的同步依赖于ZooKeeper的分布式协同的能力,ZooKeeper为每个分片创建一个根路径,在路径下创建一系列监听节点记录表的元数据(副本名称、列字段信息、主键分区键信息等),判断标识信息和操作日志。
3. MergeTree表引擎
ClickHouse的众多表引擎中,合并树((MergeTree)及其家族(*MergeTree)最为强大,只有合并树系列的表引擎才支持主键索引、数据分区、数据副本和数据采样这些特性。
家族中其他的表引擎则在MergeTree的基础之上各有所长。例如ReplacingMergeTree表引擎具有删除重复数据的特性,而SummingMergeTree表引擎则会按照排序键自动聚合数据,给MergeTree加上Replicated前缀,则变为支持数据副本的表引擎。
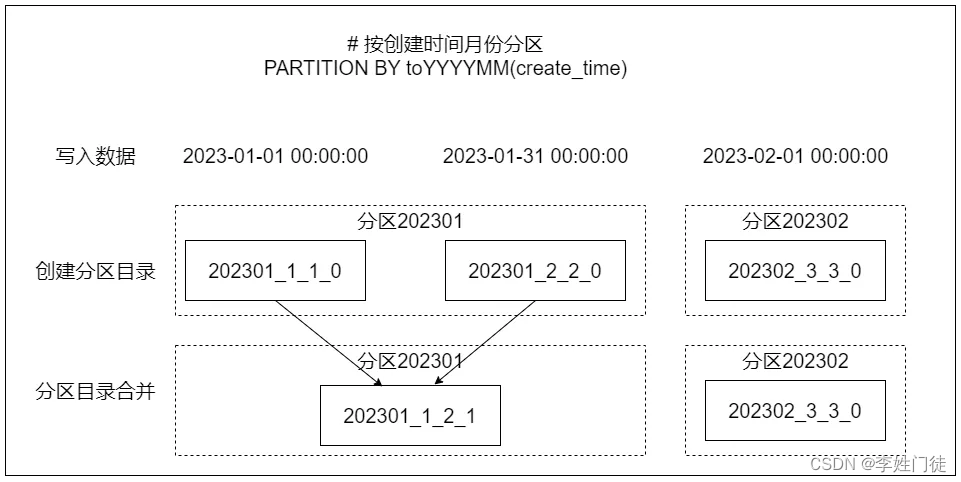
3.1 数据分区
- MergeTree支持数据分区,这里的分区指的是对本地数据的纵向切分,其目的是缩小查询时扫描数据的范围。
- MergeTree通过分区键(通过声明表时的PARTITION BY表达式)指定表数据如何进行分区,如果分区键的字段类型是整型或日期类型,则各个分区的ID为分区键的值的字符串形式,如果是其他类型,则取Hash值作为分区ID。如果没有指定分区键,则默认生成all分区。
- MergeTree的分区目录并不是在数据表被创建之后就存在的,而是在数据写入过程中被创建的。并且随着每一批数据的写入(一次INSERT语句),MergeTree都会生成一批新的分区目录。即便不同批次写入的数据属于相同分区,也会生成不同的分区目录,在之后的某个时刻(写入后的10~15分钟,也可以手动执行optimize查询语句),ClickHouse会通过后台任务再将属于相同分区的多个目录合并成一个新的目录。
3.2 分区目录生成规则
分区目录名称由分区ID,MinBlockNum,MaxBlockNum和level这4个值用下划线拼接组成。 BlockNum为表内全局自增,每次创建新目录时加1。创建新目录时,该目录的MinBlockNum和MaxBlockNum直接取当前的BlockNum值。合并目录时,MinBlockNum取同分区目录最小的MinBlockNum,MaxBlockNum取同分区目录最大的MaxBlockNum。 创建目录时level值取0,每次合并时,level加1。
3.3 存储结构
MergeTree表引擎中数据是有物理存储的,数据默认存储在/var/lib/clickhouse/data目录,data目录的下一级是数据库目录,数据库目录下是各个表的目录。在表目录下,数据文件以分区目录的形式被组织存放。
分区目录下,保存着表的数据文件、索引文件、标记文件等。
每个列字段都拥有一个与之对应的[column].bin数据文件和标记文件[column].mrk,前者以压缩格式存储列数据,后者保存一列数据中每一行数据,在.bin文件中的偏移量。

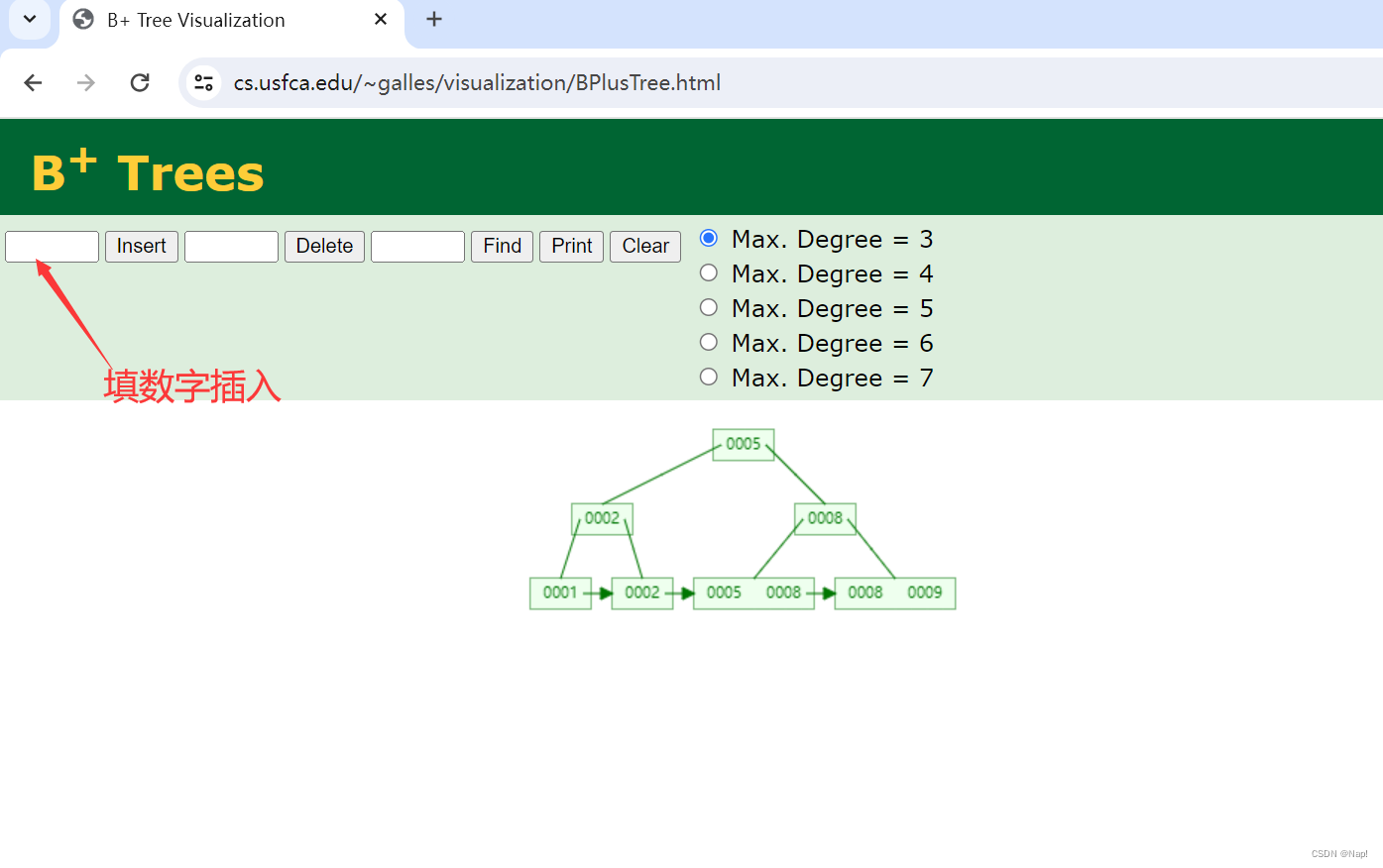
3.4 一级索引
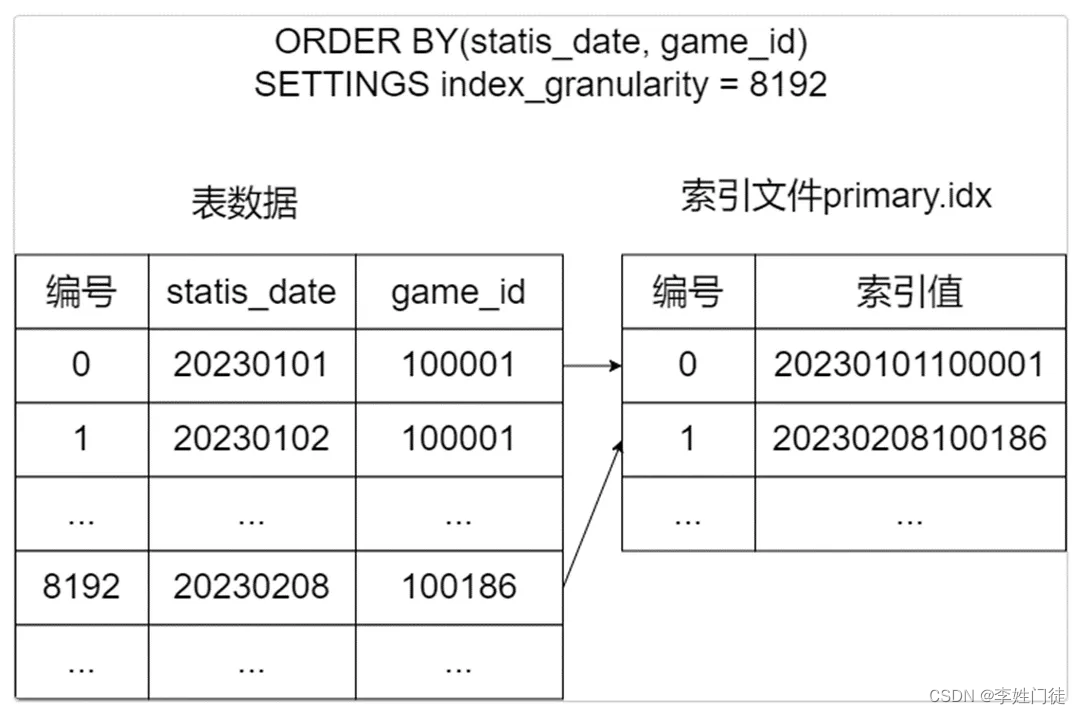
- 通过PRIMARY KEY声明主键或ORDER BY表达式声明排序键,MergeTree就会生成一级索引并保存至primary.idx文件内,primary.idx文件常驻内存,取用速度极快。
- MergeTree的一级索引是稀疏索引,每一行索引标记对应的是一段数据,而设置索引的间隔则是通过index_granularity参数(创建表时通过SETTINGS表达式设置,默认值为8192)。
- 每个索引值根据主键或排序键生成,例如排序键声明为ORDER BY(statis_date, game_id),则第1个索引值为第1行数据的statis_date与game_id的值紧密连接的字符串值,第2个索引值为第(1+index_granularity)行数据的statis_date与game_id值连接,依次类推。
3.5 压缩数据块
.bin文件存储了列字段的数据,它并不是紧密地将数据写入文件,而是以压缩数据块的方式排列在一起。
一个压缩数据块由头信息和压缩数据两部分组成,头信息保存了压缩算法类型、压缩后的数据字节大小和压缩前的数据字节大小。
MergeTree在写入数据时,会按照索引粒度(每index_granularity条数据为一批)创建压缩数据块,并根据一批数据压缩前的大小size,生成一定数量的压缩块,size被控制在64KB-1MB。
压缩数据块的设计,也是为了缩小查询数据时扫描数据的范围,根据索引可以确定需要查找的数据所在的压缩块,而不用扫描整个.bin文件。通过压缩也降低了存储空间并加速了数据传输效率。考虑到数据的压缩和解压也需要消耗一定的性能,所以MergeTree控制了每个压缩块的数据大小,在性能损耗和压缩率之间寻求平衡。
3.6. 数据标记文件
MergeTree使用数据标记文件(.mrk文件)保存索引区间对应的数据压缩块的偏移量信息,它与一级索引是一一对齐的,即通过索引值和数据标记文件,就可以定位到该索引值对应的数据压缩块。
一行数据标记数据使用一个元组表示,元组包含两个整型的偏移量,分别表示此段索引区间的数据在对应的.bin压缩文件中,压缩数据块的起始偏移量(第几个压缩数据块),以及该压缩块解压后,未压缩数据的起始偏移量。

3.7 数据查询和写入过程
写入数据时,首先是生成分区目录(后续在某一时刻,同分区的目录会合并到一起)。在分区目录内,接着按照index_granularity索引粒度(每index_granularity条数据为一批),生成一级索引文件primary.idx,为每个列字段生成.mrk数据标记文件和.bin压缩数据文件(以压缩数据块的形式写入)。
查询数据时,首先借助分区索引(Partition By)确认数据所在的分区目录(如果根据where条件无法确定目录,则扫描所有分区目录),然后根据一级索引确认索引数据段和对应的数据标记文件(如果where条件匹配不到索引,则扫描目录内索引的最大区间),最后根据数据标记文件,确认数据所在的压缩数据块。最后MergeTree会以多线程的形式同时读取多个压缩数据块。
4. 分片与副本的原理
4.1 ZooKeeper在ClickHouse中的作用
ClickHouse Replicated家族表引擎的表支持数据副本的能力,它借助了ZooKeeper的分布式协同能力,借助ZooKeeper的消息日志广播功能,实现多个副本之间的同步(数据写入修改、分区合并、元数据修改)。
在创建ReplicatedMergeTree的表时,需要指定zk_path和副本名称replica_name。ZooKeeper会以zk_path为根路径,为这张表创建一组监听节点,这些节点用于记录表的元数据(副本名称、列字段信息、主键分区键信息等)、判断标识信息(主副选举信息、判断写入成功最低实例数等)和操作日志(副本需要执行的指令等)。
ClickHouse每个副本在本地完成操作后,会推送操作日志到/log节点,并且每个副本都会监听/log节点的变化,拉取操作日志并执行,从而实现副本间的同步。
4.2 Distributed表
ClickHouse通过Distributed表引擎的表作为代理来管理集群内数据的路由、分发、写入、查询等工作,它自身不存储数据,而是作为数据分片的代理,将请求路由到相应的本地表。从实体层面看,一张分片表由任意非Distributed表引擎的本地表和Distributed表引擎的分布式表这两部分组成。
创建Distributed表时需要指定集群、数据库和表名称,以及分片键。分片键要求返回一个整型的值,可以取某个整型的表字段,或者是某个字段的hash,还可以用rand()函数。集群配置中会设置每个分片的权重值weight,插入数据时根据shard_value%(sum(weight))(分片键计算的值对集群总权重取余),即可确定数据落在哪个分片。
Distributed分布式表写入:两种实现方式:一是借助外部系统计算写入数据属于哪个分片,直接写入到对应的本地表,此方式拥有更好的写入性能;二是通过Distributed表引擎代理写入分片数据。在任意一个节点的分片表写入数据时,它会根据分区规则划分数据,如果是属于本分片的数据,则直接写入,如果是其他分片的数据,则连接远程节点发送数据。
Distributed表查询:在任意一个节点的分片表查询数据时,按照分片数量将查询拆分成若干个针对本地表的子查询,然后向各个分片发起查询,最后汇总返回。

5. ClickHouse实践
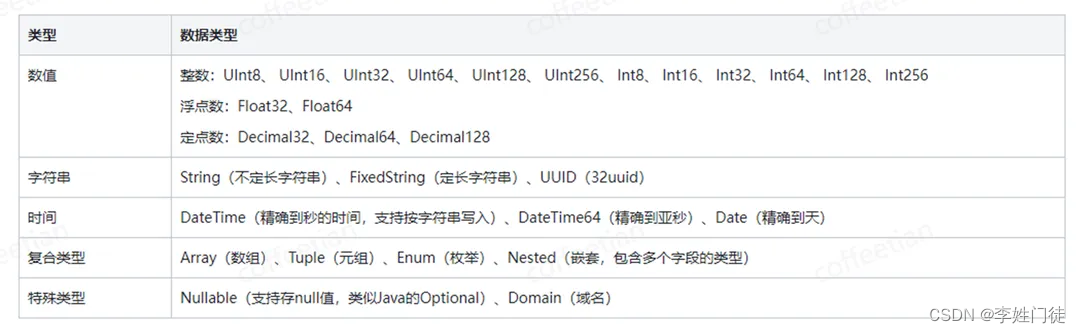
数据类型
ClickHouse除了支持数值、字符串、日期时间这些传统数据库的基础数据类型,还支持几种复合类型和特殊类型。这使得ClickHouse的数据表达能力更加丰富立体。
部分查询场景ClickHouse会做类型检查,比如字段类型是字符串/日期,WHERE语句传数值;数值类型与字符串类型做计算;这些情况都会报错。
SELECT
ClickHouse是列式存储数据,SQL语句设计的字段数量会直接影响到查询时扫描的数据块范围,所以SELECT语句查询的列数量要尽可能少。
别名问题:默认情况下,如果别名和列名相同,则别名不能再次出现在其他的聚合表达式中。该问题可以通过设置prefer_column_name_to_alias 参数调整,但还是建议别名不要和列名相同。
WHERE与PREWHERE
WHERE条件语句字段需尽量使用主键/排序键的字段,才能借助索引优化查询速度。
PREWHERE语句:只能用于MergeTree系列的表引擎,其作用与WHERE相同,使用PREWHERE时,首先只会读取PREWHERE指定的列字段数据,用于数据过滤的条件判断。待数据过滤之后再读取SELECT声明的列字段以补全其余属性。所以在一些场合下,PREWHERE相比WHERE而言,处理的数据量更少,性能更高。
GROUP BY
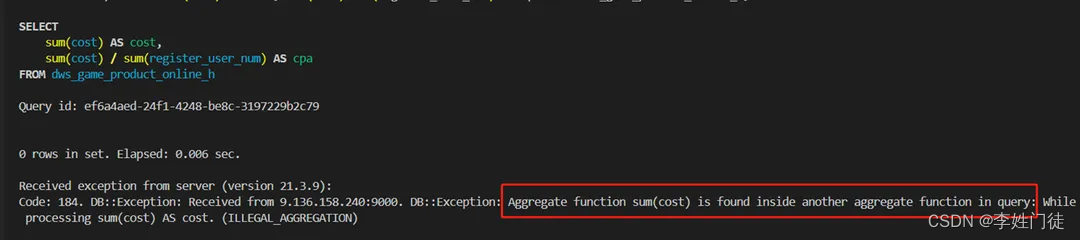
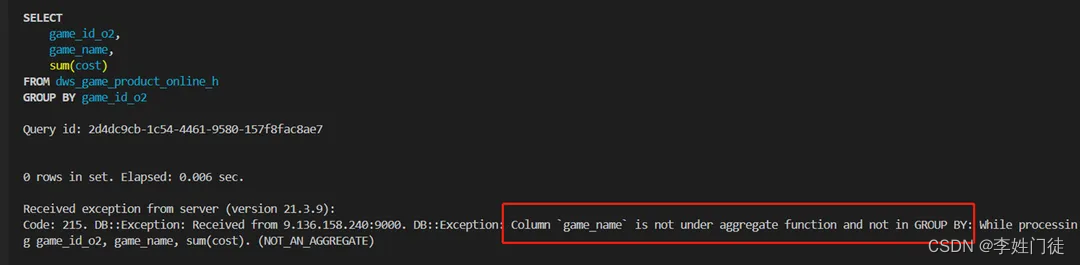
GROUP BY语句是ClickHouse最凸显性能的地方。使用GROUP BY语句时,非GROUP BY的列不能直接用于SELECT语句,必须使用聚合函数,否则会报错。
对于GROUP BY语句,ClickHouse还提供了WITH TOTALS语句(使用时放在整个查询语句最后)用于计算汇总数据。
JOIN
ClickHouse的JOIN查询没有缓存的支持,即使是连续执行相同的SQL,也都会生成一次全新的执行计划;
在执行JOIN查询时,无论使用的是哪种连接方式,右表都会被全部加载到内存中与左表进行比较,所以应该将数据量小的表放在右侧;
在多表的连接查询时,查询会转换成两两连接的形式,这种“滚雪球”式的查询很可能带来性能问题;
WITH
ClickHouse支持CTE(Common Table Expression,公共表表达式),以增强查询语句的表达,即通过WITH关键词定义一段查询子句并指定别名,后续查询语句就可以通过这个别名使用这个子句。
语法:WITH {变量}/{表达式}/{子查询} AS {alias} SELECT…
6. 疑问和思考
暂无
7. 参考文档
暂无