Redis的五个对象类型
字符串,哈希,列表,集合,有序集合
本节有关redis的内存模型
1.估算redis的内存使用情况
目前内存的价格比较的高,如果对于redis的内存使用情况能够进行计算,就可以选用合适的设备进行使用,可以有效的节省开支
2.优化内存占用
对于redis,选用合适的数据类型和编码,这样才能更好的利用redis现有的内存
3.分析解决问题
对于redis出现阻塞,内存占用等问题的时候,能够很快发现问题并解决
127.0.0.1:6379> info memory
# Memory
used_memory:1324768
used_memory_human:1.26M
used_memory_rss:11939840
used_memory_rss_human:11.39M
mem_fragmentation_ratio:9.30
mem_allocator:jemalloc-5.2.1
used_memory是redis分配器分配的内存总量,其中包括虚拟内存swap
used_memory_rss是redis内存占据操作系统的内存,和top/ps一致,包括内存和内存碎片
used_memory_human这个对于阅读比较的好
对于mem_fragmentation_ratio这个值来说的话,他是对于used_memory_rss/used_memory的比值,可以发现这个等式,如果redis启用了虚拟内存swap的话,这个比值就可能变成小于1,这个时候就需要对于redis进行问题排查,应为磁盘太慢了,对于内存增加的方法有,增加redis节点,对于redis的服务器内存进行增加,优化应用,也就是分为横向和纵向的区别
如果内存中并未存入什么数据,那么就会造成这个比值过大
mem_allocator这个参数是指当前使用的内存分配器的版本
Redis内存的划分
1.数据
数据是有内存分配器分配的内存,会被统计在used_memory中
五种类型,分别是字符串,哈希,列表,集合,有序集合,这五种类型是对外提供的,当然,在内部还有基数统计,位图,地理位置,对于对象需要进行redisObject,SDS的包装,才会被放到内存中去
2.进程本身需要的内存
redis本身的代码,例如代码,常量池,这些占据了几兆,这点空间可以忽略不计,然后应为不经过jemalloc的分配,所以不被记录到used_memory中
3.缓冲内存
缓冲内存包括客户端的缓冲区,复制积压缓冲区,AOF缓冲区等,其中客户端缓存客户端连接输入输出缓存;复制积压缓冲区用户部分复制功能,AOF缓冲区对于AOF进行重写,保存最近的写入命令。这部分是由jemalloc来分配的,所以记录到used_memory当中
4.内存碎片
对于数据进行频繁修改之后,数据之间的大小相差就很大,导致redis释放得空间在实际得物理内存中并没有释放,redis也无法合理利用,导致了内存碎片。内存碎片不会统计到used_memory当中。
内存碎片的产生是多方面的,和对于内存的操作,数据的特点等都有关,内存分配器也有关系,设计的好,内存碎片产生的也少,jemalloc在这方面做的很好
redis中的内存碎片很大的时候,可以进行安全重启,在重启之后,redis可以从备份的文件中读取数据,在内存中进行重排,为每个数据进行选择合适的内存单元,减小内存的碎片
redis数据的存储细节
前面提到,对于数据我们是需要对他进行封装,包装成redisObject,或者SDS
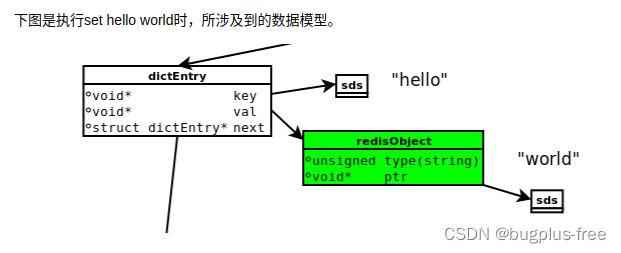
在这张图片中,可以看到dictEntry是基本的单位,每一个键值对都有一个dictEntry,然后就里面也有一个这样的指针,然后就指向过去,里面的key可以看到是存储在SDS结构中,然后就是值,这个值不是放在sds里面的,是存储在redisObject里面,然后type字段表面这是sds类型,然后ptr指针指向了sds对象所在的地址,里面存放着值,值也是需要sds结构进行存储的
之后就是jemalloc对于上面说的dictEntry对象、redisObject、SDS对象都进行了内存的分配,dictEntry这个对象有三个指针,也就是3*8字节为24字节,然后就向上取整,给他分配了一个32字节大小的内存单元
jemalloc
在redis对于内存分配器进行选择的时候,内存分配器有libc,jemalloc,tcmalloc,三个,当然默认的是jemalloc,这一个在64位系统中,对于内存空间进行了小中大的三个范围的划分,当然,在每一个范围内又进行了更加细致的划分,
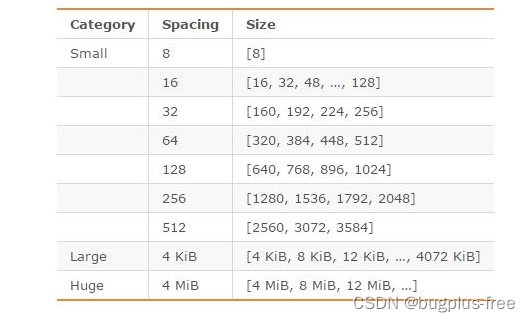
就像这里如果需要存储一个字节的对象,那么就需要字节的内存单元中
redisObject
在redis中有五种对象,现在有八种,不管哪一种,redis都不会进行直接存储,都会对于redisObject对象进行存储
redisObject对象中包含了redis对象的类型,内部编码,内存回收,共享对象等功能,都需要redisObject的支持,
typedef struct redisObject {unsigned type:4;unsigned encoding:4;unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */int refcount;void *ptr;
} robj;type,对象的类型,也就是那八个
直接使用type的命令
encoding 在字符串中有三种编码 int emmbstr raw
对于列表对象来说,元素少的时候,就是int型,如果元素多的话,会抓换成embstr类型
int是压缩列表,embstr是双端链表
lru记录的是对象最后一次被程序访问的时间,如果你想看,可以使用object idletime命令进行查看
这条指令并不会修改lru
lru和redis的内存回收算法是有关系的,如果是redis打开了maxmemory选项,那么内存回收算法选择的是volatile-lru或allkeys-lru,这两种算法,每当redis的内存超过maxmemory的时候,redis就会优先选择lru的空转时间最长的对象进行释放
还有一个refcount
这个东西是和共享对象有关的,新对象创建的时候,初始话为1,之后如果有新程序使用了该对象,这个refcount+1没使用了就-1,如果refcount=0的时候,说明对象占用的内存会被释放
redis目前的共享对象支持的只有整数值的字符串对象,但是其他八种都可能使用共享对象
这里要注意,本篇文章是redis3.0那个时候还是五种,这里的八种我认为是可以延伸的,如果有不正确的,请指正
哈希,列表可以使用这种整数值的字符串对象
一般来说会初始化10000个字符串对象,分别是0~9999,如果你使用的话,就是使用共享对象了
最新版好像是一个好大好大的值
这一万个数字是可以进行调整的,可以自己百度下自己的版本怎么调整
之后就只剩下一个ptr了
ptr就是指向具体的数据了,这里可以认为指向的就是SDS结构,这个ptr的大小个系统有关
redis的所占大小就可以算了type是4个比特,encoding也是4个比特,然后就是lru,这个就看你的版本了,4.0是24比特,3.0是22比特,然后就是refcount一个int,4个字节,然后就剩下一个ptr指针了,现在都是64位的系统,所以都是8个字节,然后算一算就是16字节
接下来就是SDS结构了
SDS是简单动态字符串(Simple Dynamic String)
struct sdshdr {int len;int free;char buf[];
};buf数组用来存放字符串的,len就是已经使用的长度,free就是还没有使用的长度
buf数组的长度就可以通过len+buf+1应为字符串都是末尾来个空字符'\0'来表示结束的
sds的优点为,可以在O(1)的情况下查找长度,获取字符串长度是O(1)的,这里我就想到了go语言中的切片slice了,里面也存在着cap最大容量上限
然后再缓冲区溢出方面,直接使用C字符串的api会导致溢出,如果字符串的长度增加的话,你没有分配内存就会导致缓冲区的溢出,这里的sds记录了长度,在对应的api造成缓冲区溢出的时候,可以自动分配内存,防止了缓冲区的溢出
在修改字符串内存方面的重分配,如果是C字符串的话,需要重新分配,也就是释放再重新申请,如果,字符串长度增大会导致内存缓冲区溢出,字符串长度减少时会造成内存泄漏。对于sds来说,应为有了len 和free,空间预分配之后,字符串长度增大在重新分配的概率就小很多,应为一般我们都会分配多一点内存给他们,在内存释放方面,对于值进行修改之后,直接修改len和free就可以了,所以也很方便
对于二进制数据来说,C字符串不可以存,但是sds是可以进行存储的,应为二进制数据中可能有'\0'这种,但是sds中有len这个长度,所以可以规避这个错误
如果sds里面存储的是文本数据时可以使用C字符串的函数,但是二进制数据不行,应为这个可能是以'\0'数据也可能在数据里面,会出错
在打印日志以及不更改字符串的情况下,才会使用C字符串,不然一般都是使用sds结构体
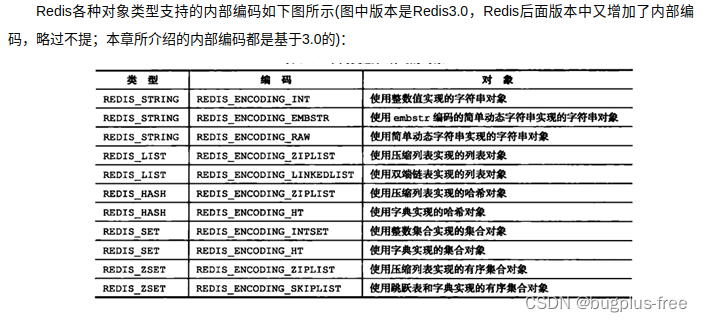
转换过程是不可逆的
只能是小内存编码向大内存编码进行转换