目录
- 什么是CV-CUDA
- 环境准备
- 准备CV-CUDA静态库
- 解压
- 添加至变量
- 将PyBind静态库复制到env下
- 算子设计
- 前处理算子
- TensorRT模型加载
- 后处理函数
- 完整代码
- 输出演示
- 为什么重新写了?
- 结语
什么是CV-CUDA
NVIDIA CV-CUDA™ 是一个开源项目,用于构建云规模人工智能 (AI) 成像和计算机视觉 (CV) 应用程序。 它使用图形处理单元 (GPU) 加速来帮助开发人员构建高效的预处理和后处理管道。 它可以将吞吐量提高 10 倍以上,同时降低云计算成本。

环境准备
准备CV-CUDA静态库
首先我们需要访问CV-CUDA Github仓库
去下载与您系统架构相对应的静态库文件,以我为例,我需要下载:
- cvcuda-dev-0.7.0_beta-cuda11-x86_64-linux.tar.xz
- cvcuda-lib-0.7.0_beta-cuda11-x86_64-linux.tar.xz
- cvcuda-python3.10-0.7.0_beta-cuda11-x86_64-linux.tar.xz
- cvcuda-tests-0.7.0_beta-cuda11-x86_64-linux.tar.xz
请注意!下载的静态库的版本取决你的CUDA版本和目前正在使用的Python版本(这是由于PyBind11导致的)。
解压
tar -xvf cvcuda-dev-0.7.0_beta-cuda11-x86_64-linux.tar.xz
tar -xvf cvcuda-lib-0.7.0_beta-cuda11-x86_64-linux.tar.xz
tar -xvf cvcuda-python3.10-0.7.0_beta-cuda11-x86_64-linux.tar.xz
tar -xvf cvcuda-tests-0.7.0_beta-cuda11-x86_64-linux.tar.xz
添加至变量
所有解压后的静态库文件会被解压到一个名为opt的目录中,但是请注意,这个opt不是Linux根文件系统的/opt,请务必做出区分!
请在~/.bashrc文件中添加以下内容:
export LD_LIBRARY_PATH=$HOME/opt/nvidia/cvcuda0/lib/x86_64-linux-gnu
接下来使~/.bashrc生效并加载静态库
source ~/.bashrc && ldconfig
使用ldconfig命令检查静态库是否被加载:
ldconfig -p | grep nvcv
如果看到以下结果说明静态库已被加载成功:
libnvcv_types.so.0 (libc6,x86-64) => /usr/local/cuda/targets/x86_64-linux/lib/libnvcv_types.so.0
将PyBind静态库复制到env下
在您的解压目录下,应该有一个名为cvcuda.cpython-310-x86_64-linux-gnu.so的文件,请将此文件复制到以下路径:
$PYTHON_HOME/site-packages/
以我的情况为例,我所使用的是anaconda3,因此这个路径是:
/home/elin/anaconda3/envs/jetsonsim/lib/python3.10/site-packages
使用import命令来检查cvcuda是否可用:
>>> import cvcuda
>>>
如果没有报错则说明cvcuda已经被加载成功了。
算子设计
前处理算子
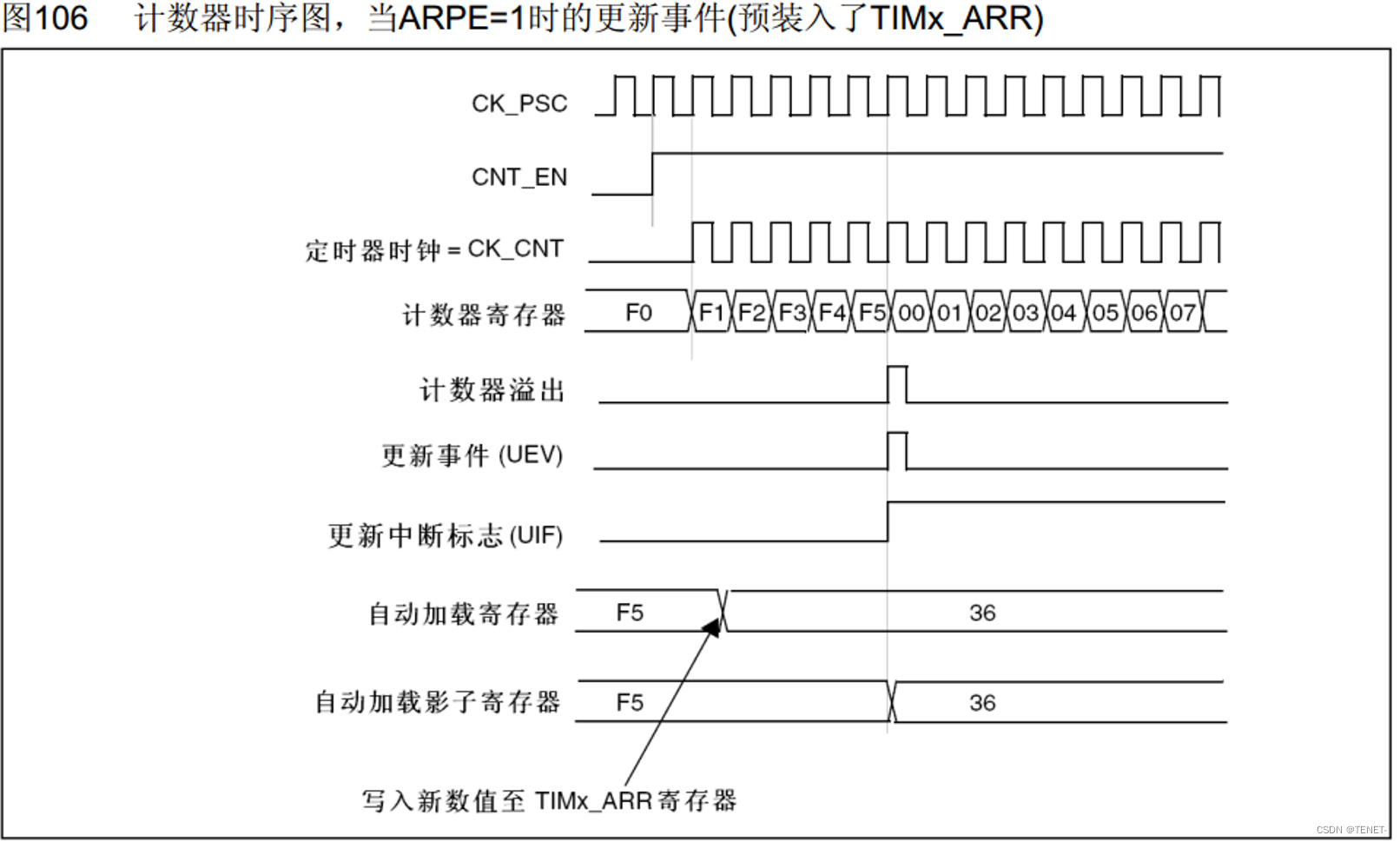
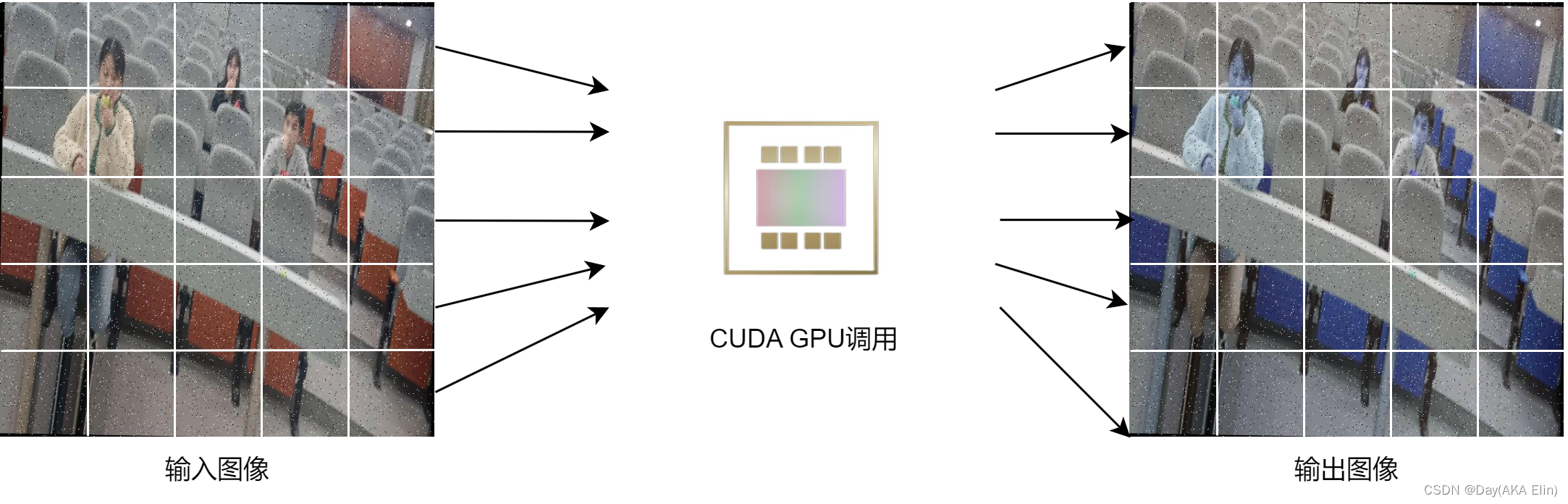
由于YOLOv8模型接受一个640x640,batch_size为1的RGB图像,因此我们的前处理算子可以设计成:
def preprocess(self,imageFrame:np.ndarray) -> torch.Tensor:# 首先将输入的Numpy矩阵转换成Pytorch张量imageFrame = torch.tensor(imageFrame,device="cuda",dtype=torch.uint8)self.imageHeight,self.imageWidth = imageFrame.shape[:2]# 由于OpenCV读取的图像是HWC格式,# 因此CVCUDA需要将图像张量按此格式进行转换imageTensor = cvcuda.as_tensor(imageFrame,"HWC")# 使用GPU上的色域转换和resize算子进行处理imageTensor = cvcuda.cvtcolor(imageTensor,cvcuda.ColorConversion.BGR2RGB)imageTensor = cvcuda.resize(imageTensor,(self.inputWidth,self.inputHeight,3))# 将CVCUDA张量转移成Pytorch张量# 由于CVCUDA张量并未实现运算符重载,所以这一步是必要的# 以便我们处进行二值化和后续TensorRT模型的推理imageData = torch.as_tensor(imageTensor.cuda(),device="cuda")imageData = imageData / 255.0# 使用维度转置将图像扩增至(1,3,640,640)imageData = imageData.transpose(0,2).transpose(1,2).unsqueeze(0)return imageData # 返回GPU张量,以避免TensorRT推理前的GPU显存拷贝
以下是前处理算子的工作示意图:
TensorRT模型加载
在TensorRT模型的加载上,我使用了NVIDIA提供的一个非常还用的工具:torch2trt,它提供了类似Pytorch的API以加载并调用TensorRT模型,您可以使用以下命令来安装torch2trt:
pip install git+https://github.com/NVIDIA-AI-IOT/torch2trt.git
在真正读取TensorRT模型之前,你仍然需要安装TensorRT的Python API,它通常位于您TensorRT解压路径下的
python目录下,请按照自己的Python版本按需安装。
接下来我们需要反序列化我们的YOLOv8 TensorRT模型:
import tensorrt as trt
from torch2trt import TRTModule
self.logger = trt.Logger(trt.Logger.INFO) # 初始化TensorRT日志类
# 反序列化YOLOv8模型
with open("../gpupipe/model/best.engine","rb") as f, trt.Runtime(self.logger) as runtime:self.engine = runtime.deserialize_cuda_engine(f.read())
# 使用torch2trt下TRTMoudle类来加载TensorRT引擎
self.TRTNet = TRTModule(input_names=[self.inputName],output_names=[self.outputName],engine=self.engine)
以上代码中:
- input_name:代表您的YOLOv8模型的输入名称,如果您使用的是Ultralytics的工具进行训练的话,那么该值通常为:
images。 - output_name:代表您的YOLOv8模型的输出名称,如果您使用的是Ultralytics的工具进行训练的话,那么该值通常为:
output0。 - engine:代表反序列化后的TensorRT二进制对象。
正如我们前面有提到的一样,torch2trt为开发者提供了类Pytorch的API,因此我们的推理函数十分简单:
def inference(self,processedFrame:torch.Tensor) -> torch.Tensor:return self.TRTNet(processedFrame)
后处理函数
本章是整个pipeline最为重要的部分,这里我会着重讲解。
YOLOv8的输出大小通常取决于nc(num_classes)的大小,无论任何尺寸的YOLOv8模型最终都将输出8400条记录。这也就意味着我们需要遍历8400xnc个数据项!!这显然是没办法用循环来实现的。
在CPU环境上,我使用了Pandas进行向量化处理,得到了约9-10FPS美妙的成绩,具体实现代码如下:
output = np.transpose(np.squeeze(output[0])) # 由于YOLOv8的输出是(1,nc,8400),为了方便处理所以需要转置
df = pd.DataFrame(output)
x_factor = self.imageWidth / self.inputWidth
y_factor = self.imageHeight / self.inputHeightdf['amax'] = np.amax(df.iloc[:,4:self.nc+4],axis=1)
df['argmax'] = np.where(df.iloc[:,4:self.nc+4]==df['amax'].values[:,None])[1]
df = df[df['amax'] > self.confidenceThres]
boxes = df.iloc[:,0:4].to_numpy()
scores = df['amax'].to_numpy()
class_ids = df['argmax'].to_numpy()# apply factor to boxes
boxes[:,0] = (boxes[:,0] - boxes[:,2]/2.0) * x_factor
boxes[:,1] = (boxes[:,1] - boxes[:,3]/2.0) * y_factor
boxes[:,2] = boxes[:,2] * x_factor
boxes[:,3] = boxes[:,3] * y_factor
在加速计算领域有一个常用的公式用于计算一个可并行算法的加速比,称之为阿姆达尔定律:
S = 1 ( 1 − p ) + p N S = \frac{1}{(1-p) + \frac{p}{N}} S=(1−p)+Np1
其中:
- S S S代表着加速
- P P P代表并行化后的代码运行时间占比
- N N N代表并行代码在执行时使用的内核数量
因此在忽略了 P P P的大小的情况下,以笔者的GeForce RTX3080Ti笔记本GPU为例,我的GPU包含7424个CUDA Cores,而我的12代12800HX具备8P+8E,总计16个内核。因此能够利用CUDA GPU加速特征提取显得尤为重要。
通过观察CPU代码可知:
- 每一条记录的前四位代表着锚点框的 x x x, y y y和长宽。
- 而后面的所有列均为每个类别的置信度信息
- 使用
amax和argmax来获取最佳类别信息
因此,我们使用Pytorch得到了如下的代码:
output = torch.transpose(torch.squeeze(output),0,1).cuda()
x_factor = self.imageWidth / self.inputWidth
y_factor = self.imageHeight / self.inputHeight# Process model output
argmax = torch.argmax(output[:,4:84],dim=1)
amax = torch.max(output[:,4:84],dim=1).values# Concate tensors
output = torch.cat((output,torch.unsqueeze(argmax,1),torch.unsqueeze(amax,1)),dim=1)
output = output[output[:,-1] > self.confidenceThres]boxes = output[:,:4]
class_ids = output[:,-2]
scores = output[:,-1]boxes[:,0] = (boxes[:,0] - boxes[:,2]/2.0) * x_factor
boxes[:,1] = (boxes[:,1] - boxes[:,3]/2.0) * y_factor
boxes[:,2] = boxes[:,2] * x_factor
boxes[:,3] = boxes[:,3] * y_factor
经过优化后,目前算子的运行速度大概在24-30FPS左右,提升了约2~3倍!
搞定了特征提取后,接下来我们要进行非极大值抑制和预测信息绘制了。
由于CV-CUDA对NMS算子的限制,我们需要确保输入的置信度分数和锚点框应满足一下大小:
- BBox(锚点框信息):(batch_size,shape,4),数据类型为
torch.int16 - score(置信度信息):(batch_size,1),数据类型建议为
torch.float32
以我的情况,我使用了如下的代码进行实现:
# 制备CVCUDA需要的数据类型和大小
boxes = boxes.to(torch.int16).reshape(1,-1,4)
scores = scores.to(torch.float32).reshape(1,-1)
class_ids = class_ids.to(torch.int16)
# 将Pytorch张量转换为CVCUDA张量,同时确保输入的张量使用torch.Tensor.contiguous()确保其内存是可连续的
cvcuda_boxes = cvcuda.as_tensor(boxes.contiguous().cuda())
cvcuda_scores = cvcuda.as_tensor(scores.contiguous().cuda())
# 使用NMS算法
nms_masks = cvcuda.nms(cvcuda_boxes,cvcuda_scores,self.confidenceThres,self.iouThres)
# 转换回Pytorch算子
nms_masks_pyt = torch.as_tensor(nms_masks.cuda(),device="cuda",dtype=torch.bool
)
需要指出的是,cvcuda的nms算子返回的是一个 ∈ [ 0 , 1 ] ∈[0,1] ∈[0,1]值域的掩码,因此我们需要将cvcuda张量转换为Pytorch的布尔类型张量,并使用torch.where()函数得到最终的NMS筛选索引:
# 将锚点框信息和置信度分数转换回原本的大小
boxes = boxes.reshape(-1,4)
scores = scores.reshape(-1)
# 拷贝到Numpy以方便进行遍历
indices = torch.where(nms_masks_pyt == 1)[1].cpu().numpy()
接下来我们需要创建两个列表,用于存储cvcuda.BndBoxI和cvcuda.Label对象。
bbox_list,text_list = [],[]
遍历所有经过NMS处理后的信息,并将对应的锚点框和标签进行存储:
for i in indices:box = boxes[i]score = scores[i]classIndex = class_ids[i]bbox_list.append(cvcuda.BndBoxI(box = tuple(box),thickness = 2,borderColor = tuple(self.colorPalette[classIndex].tolist()),fillColor = (0,0,0,0)))# 计算标签的X和Y坐标labelX = box[0]labelY = box[1] - 10 if box[1] - 10 > 10 else box[1] + 10text_list.append(cvcuda.Label(utf8Text = '{}: {}'.format(self.classes[classIndex],str(float(score.amax().cpu().numpy()) * 100)[0:5] + '%'),fontSize = 6,tlPos = (labelX,labelY),fontColor = (255,255,255),bgColor = tuple(self.colorPalette[classIndex].tolist())))
如果您想了解这些对象(或者C++结构体)的具体参数信息,详情可参阅CVCUDA的Types.hpp文件,该文件中包含了CVCUDA所有常见对象类型的定义信息。
在遍历了所有锚点框和类别后,我们需要将每个预测结果绘制到画面上,这就不得不提到CVCUDA又一个优化函数:cvcuda.osd_into()了。
以往我们使用CPU算子上需要使用类似于cv2.putText()和cv2.rectangle()函数进行渲染。在C++上,这或许比较理想,我们可以使用OpenMP来借助多线程优化这个过程。
可是现在的情况是Python,受限于GIL的限制,我们无法真正发挥多核处理器的优势,这也就意味着我们只能一个一个将预测信息绘制到画面上。
而cvcuda.osd_into()函数则允许CUDA GPU并行的将每个预测结果渲染到画面上,而不会像OpenCV那样一个个的单独渲染。
cvcuda.osd_into()函数接受三个参数:
- src_tensor:输入图像张量,接受HWC格式,或NHWC格式。
- dest_tensor:输出图像张量,和src一样接受HWC和NHWC格式
- elements:输入的
cvcuda.Elements()元素列表,用于渲染到目标图像上。
接下来是代码实现:
# Draw the bounding boxes and labels on the image
batch_bounding_boxes = cvcuda.Elements(elements=[bbox_list])
batch_text = cvcuda.Elements(elements=[text_list])cvcuda.osd_into(frame_hwc,frame_hwc,batch_bounding_boxes)
cvcuda.osd_into(frame_hwc,frame_hwc,batch_text)
最后我们将输入图像从cvcuda张量拷贝会Numpy矩阵渲染FPS信息(可选):
# calculate the FPS
self.fpsCounter += 1
elapsed = (datetime.now() - self.fpsTimer).total_seconds()
if elapsed > 1.0:self.fps = self.fpsCounter / elapsedself.fpsCounter = 0self.fpsTimer = datetime.now()
# draw the FPS counter
cv2.putText(outputFrame, "FPS: {:.2f}".format(self.fps), (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0,0,255),1, cv2.LINE_AA)
# draw current time on the top right of frame
cv2.putText(outputFrame, datetime.now().strftime("%Y %I:%M:%S%p"), (self.imageWidth - 150, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0,0,255),1, cv2.LINE_AA)
return outputFrame
完整代码
import cvcuda
import tensorrt as trt
from datetime import datetime
import yaml
import numpy as np
import torch
from torch2trt import TRTModule
import cv2
class VideoProcessor:def __init__(self) -> None: self.config = yaml.load(open("../gpupipe/config/data.yaml"), Loader=yaml.FullLoader)self.modelName = self.config['modelName']self.modelVersion = self.config['modelVersion']self.inputName = self.config['inputName']self.outputName = self.config['outputName']self.confidenceThres = self.config['confidenceThreshold']self.inputWidth, self.inputHeight = self.config['inputWidth'],self.config['inputHeight']self.iouThres = self.config['iouThreshold']self.classes = self.config["names"]self.colorPalette = np.random.uniform(0, 255, size=(len(self.classes), 3)).astype(np.uint8)# create a FPS counterself.fps = 0self.fpsCounter = 0self.fpsTimer = datetime.now()# Initalize TensorRT Engineself.logger = trt.Logger(trt.Logger.INFO)with open("../gpupipe/model/best.engine","rb") as f, trt.Runtime(self.logger) as runtime:self.engine = runtime.deserialize_cuda_engine(f.read())self.TRTNet = TRTModule(input_names=[self.inputName],output_names=[self.outputName],engine=self.engine)def preprocess(self,imageFrame:np.ndarray) -> torch.Tensor:# convet the image to a cuda tensorimageFrame = torch.tensor(imageFrame,device="cuda",dtype=torch.uint8)self.imageHeight,self.imageWidth = imageFrame.shape[:2]imageTensor = cvcuda.as_tensor(imageFrame,"HWC")imageTensor = cvcuda.cvtcolor(imageTensor,cvcuda.ColorConversion.BGR2RGB)imageTensor = cvcuda.resize(imageTensor,(self.inputWidth,self.inputHeight,3))# convert torch tensor to numpy arrayimageData = torch.as_tensor(imageTensor.cuda(),device="cuda")imageData = imageData / 255.0imageData = imageData.transpose(0,2).transpose(1,2).unsqueeze(0)return imageDatadef postProcess(self,inputFrame,output):frame_hwc = cvcuda.as_tensor(torch.as_tensor(inputFrame).cuda(),"HWC")output = torch.transpose(torch.squeeze(output),0,1).cuda()x_factor = self.imageWidth / self.inputWidthy_factor = self.imageHeight / self.inputHeight# Process model outputargmax = torch.argmax(output[:,4:84],dim=1)amax = torch.max(output[:,4:84],dim=1).values# Concate tensorsoutput = torch.cat((output,torch.unsqueeze(argmax,1),torch.unsqueeze(amax,1)),dim=1)output = output[output[:,-1] > self.confidenceThres]boxes = output[:,:4]class_ids = output[:,-2]scores = output[:,-1]boxes[:,0] = (boxes[:,0] - boxes[:,2]/2.0) * x_factorboxes[:,1] = (boxes[:,1] - boxes[:,3]/2.0) * y_factorboxes[:,2] = boxes[:,2] * x_factorboxes[:,3] = boxes[:,3] * y_factor# Convert to boxes dtype to 16bit Signed Integerboxes = boxes.to(torch.int16).reshape(1,-1,4)scores = scores.to(torch.float32).reshape(1,-1)class_ids = class_ids.to(torch.int16)# Converting to cvcuda tensorcvcuda_boxes = cvcuda.as_tensor(boxes.contiguous().cuda())cvcuda_scores = cvcuda.as_tensor(scores.contiguous().cuda())# Apply non-maximum suppression to filter out overlapping bounding boxesnms_masks = cvcuda.nms(cvcuda_boxes,cvcuda_scores,self.confidenceThres,self.iouThres)nms_masks_pyt = torch.as_tensor(nms_masks.cuda(),device="cuda",dtype=torch.bool)# Convert back boxes and scores into it's original shapeboxes = boxes.reshape(-1,4)scores = scores.reshape(-1)indices = torch.where(nms_masks_pyt == 1)[1].cpu().numpy()bbox_list,text_list = [],[]for i in indices:box = boxes[i]score = scores[i]classIndex = class_ids[i]bbox_list.append(cvcuda.BndBoxI(box = tuple(box),thickness = 2,borderColor = tuple(self.colorPalette[classIndex].tolist()),fillColor = (0,0,0,0)))labelX = box[0]labelY = box[1] - 10 if box[1] - 10 > 10 else box[1] + 10text_list.append(cvcuda.Label(utf8Text = '{}: {}'.format(self.classes[classIndex],str(float(score.amax().cpu().numpy()) * 100)[0:5] + '%'),fontSize = 6,tlPos = (labelX,labelY),fontColor = (255,255,255),bgColor = tuple(self.colorPalette[classIndex].tolist())))# Draw the bounding boxes and labels on the imagebatch_bounding_boxes = cvcuda.Elements(elements=[bbox_list])batch_text = cvcuda.Elements(elements=[text_list])cvcuda.osd_into(frame_hwc,frame_hwc,batch_bounding_boxes)cvcuda.osd_into(frame_hwc,frame_hwc,batch_text)outputFrame = torch.as_tensor(frame_hwc.cuda(),device="cuda").cpu().numpy()# calculate the FPSself.fpsCounter += 1elapsed = (datetime.now() - self.fpsTimer).total_seconds()if elapsed > 1.0:self.fps = self.fpsCounter / elapsedself.fpsCounter = 0self.fpsTimer = datetime.now()# draw the FPS countercv2.putText(outputFrame, "FPS: {:.2f}".format(self.fps), (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0,0,255),1, cv2.LINE_AA)# draw current time on the top right of framecv2.putText(outputFrame, datetime.now().strftime("%Y %I:%M:%S%p"), (self.imageWidth - 150, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0,0,255),1, cv2.LINE_AA)return outputFramedef inference(self,processedFrame:torch.Tensor) -> torch.Tensor:return self.TRTNet(processedFrame)def processing(self,frame):image_data = self.preprocess(frame)output = self.inference(image_data)outputFrame = self.postProcess(frame,output)return outputFrame
输出演示

为什么重新写了?
因为之前的Pipeline存在一些BUG,另外就是部分算子没有使用CVCUDA实现,而现在的Pipeline全部使用CVCUDA实现。
结语
这里是Day,如果觉得这篇博客有用的话,请留下你的赞和收藏,十分感谢!