文章目录
- 1.线程/协程/异步:并发对应硬件资源是cpu,线程是操作系统如何利用cpu资源的一种抽象
- 2.并发:cpu,线程
- 2.1 可见性:volatile
- 2.2 原子性(读写原子):AtomicInteger/synchronized
- 2.3 CPU:由控制器和运算器组成,通过总线与其他设备连接
- 3.IO多路复用:硬盘和网卡
- 3.1 select:select是系统调用函数,system是一个C/C++的库函数
- 3.2 poll:pollfds数组替代bitmap
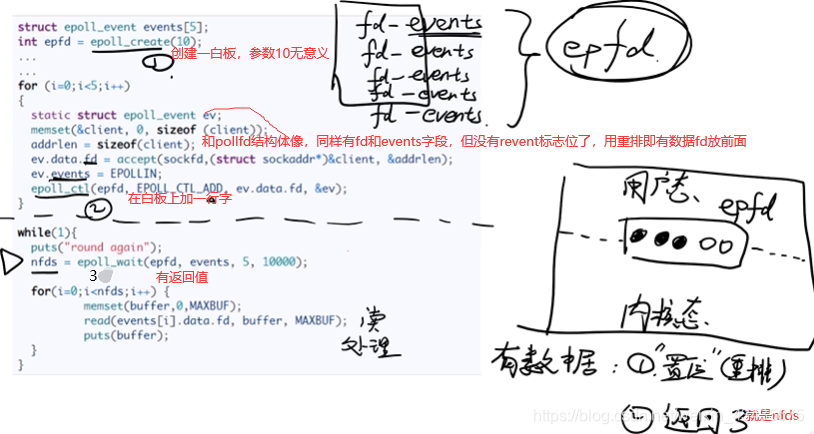
- 3.3 epoll:epfd是共享内存,不需要用户态切换到内核态
- 4.操作系统内存管理与分类:分页,页大小位数=偏移量
- 4.1 内存条/总线/DMA(硬件):CPU和DMA是同级,两者对总线控制是轮换隔离
- 4.2 用户态和内核态:程序运行过程中可能处于内核态,也可能处于用户态,某一时刻处于用户态,下一时刻可能切换到用户态(但必须有触发条件)
- 4.3 分页:为了减少碎片问题
- 4.4 分段:程序内部的内存管理即分段(对虚拟地址分成多个段),堆区和栈区就是程序的段。text(代码段,存程序本身二进制字节码),data(数据段,存程序中一些静态的变量)
- 4.5 brk:用户无法操作硬件如内存条,必须交给内核帮我们操作完了再把结果给我们
- 4.6 mmap:pidstat,缺页缺的是内存还是磁盘
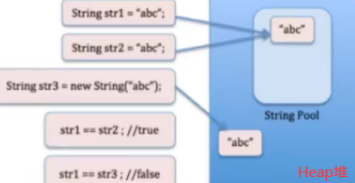
- 4.7 逃逸分析:对象在声明后只有在当前运行的函数中调用,那么将这个对象栈上申请空间而不是在堆上,因为在栈上申请的对象,函数执行完后会直接清理,大大减轻了GC压力
1.线程/协程/异步:并发对应硬件资源是cpu,线程是操作系统如何利用cpu资源的一种抽象
线程(操作系统级别概念)是cpu调度的最小单位,cpu并不在意是哪个进程,cpu就是轮换着线程来运行并不需要知道这个线程是属于哪个进程的。左边单核cpu(不是单线程),3个线程(任务都是读取文件)交叉运行完。
通过以下两点大大提高了cpu利用率,因而线程想提高效率和io密切相关。
1.DMA过程中cpu一段时间不被线程阻塞。2.DMA进行数据读取时可复用,因为cpu的总线程具有多条线路,所以DMA可充分利用这些线路,实现并行读取这些文件。

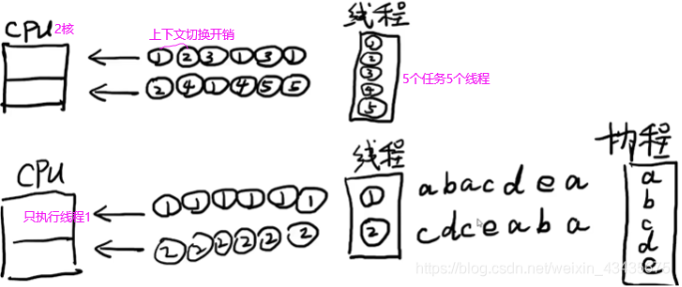
多线程需调用系统底层API才能开辟,在多线程开辟过程中浪费时间,并且在线程运行中上下文切换部分(左边切换多次,右边切换三次)有用户态和内核态转换耗,效率浪费在cpu切换时间点上。所以服务端连接的客户端不活跃多(即io次数少),考虑单线程(io多路复用或nio)或协程。上面的1,2,3线程都有io,所以多线程效率高。
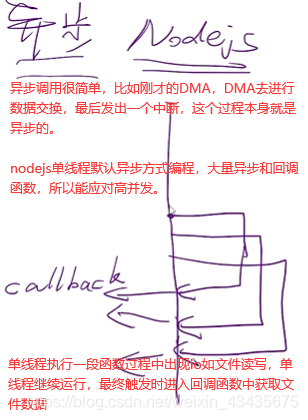
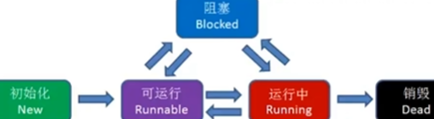
如何利用cpu资源?os给了我们两种抽象即进程和线程。进程是系统资源分配,调度和管理的最小单位,比如去任务管理器查看使用内存时是看的哪个进程或哪个程序使用了多少内存而不是哪个线程,如果是哪个线程根本不知道是哪个程序里的线程,没法管理。一个进程的内存空间是一套完整的虚拟内存地址空间,这个进程中所有线程都共享这一套地址空间。如下线程的5种状态,只有运行中是占用cpu资源的。
线程执行有性能损耗,这些损耗来自线程的创建销毁和切换,线程本质向cpu申请计算资源,用户态转内核态。
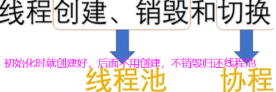
协程是用户自定义线程但与os的线程不同,协程不进入内核态。自己创建一套API,协程利用线程资源。
2.并发:cpu,线程
2.1 可见性:volatile
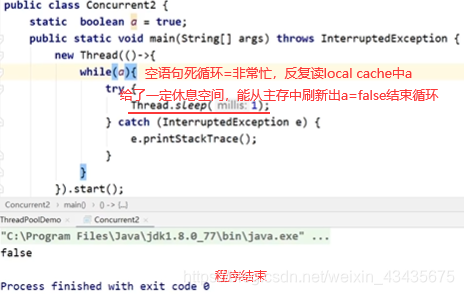
如下程序一直没结束即while(a)这线程没结束:一个线程对a写了false,但是对另一个线程并不可见。
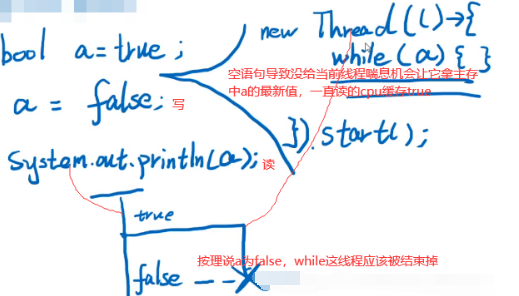
如下第一个core为主线程,第二个core为开辟的线程。
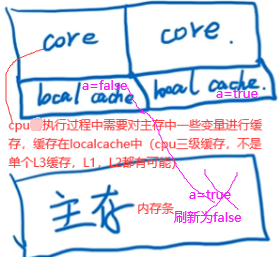
如上线程2不能立即读到线程1写后的最新变量值(线程1写,线程2读),多线程不可见性。如何解决多线程不可见性:加volatile关键字使a在主存和localcache间强制刷新一致。

2.2 原子性(读写原子):AtomicInteger/synchronized
如果线程1和2都进行基于读的变量再对读的变量再进行写,最典型操作i++,T1和T2都进行i++操作。
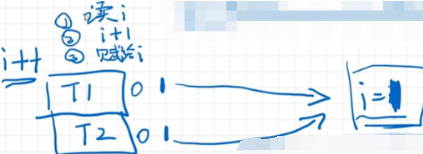
一开始i=0,经过两个线程两次i++操作结果变成了1,这显然是不对的,并且这种情况下不能用volatile保证这样操作的正确性(两个线程既有读操作,又有基于读操作的写操作,可见性只保证一个线程写另一个线程读是正确的,这里可见性不适用)。

现在想做的是将读操作和写操作合为一步,要么同时发生要么同时不发生(原子性)。在保证原子性同时一定以保证可见性为前提(不是并列关系,AtomicInteger类里本质上就是volatile),本身不可见的话没办法保证原子性。

也可用synchronized同步关键字来保证原子性发生,同步关键字同一时间只有一个线程进入代码段。

volatile可见性关键字最轻量级(保证一个线程写,一个线程读能读到最新的值),AtomicInteger(保证既有读操作又有写操作如i++这种场景下能保证操作的原子性)基于volatile,synchronized最重量级(能保证整个代码块中所有操作都是原子性的)。多线程情况下需要自增请使用Atomicxxx类来实现。
2.3 CPU:由控制器和运算器组成,通过总线与其他设备连接

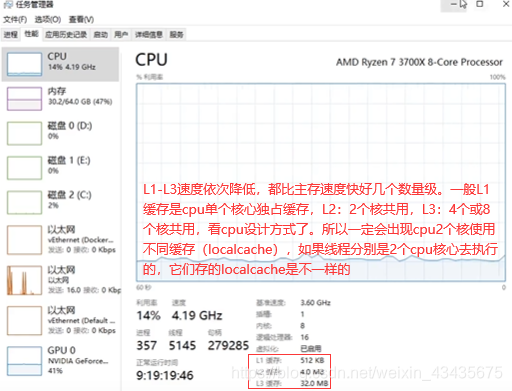
内存,cpu,io是编程中三个最重要的点。南桥(桥就是连接)连接带宽要求低的设备如是一些鼠标键盘硬盘usb设备等。北桥(集成到了cpu内部)负责带宽比较高的设备如pcie显卡,pcie硬盘,内存RAM需高速访问。如下是cpu常见参数,8核16线程(超线程)。

系统架构=处理器指令集,如下常见的6种指令集,X86_64基于X86,ARM不是其他嵌入式类,cortex A系列等。

2个物理cpu,1个物理cpu有38个逻辑核【76个线程/频率/处理单元processor)】。CPU就intel和amd。CPU(S):所有cpu的总逻辑核数。socket:物理cpu数量。top -d 1。

应对并发:1.动静分离,cdn加速资源。2.水平扩展,nginx集群。3.微服务化,多用多分配资源。4.缓存redis减少io寻找。5.队列,秒杀系统采用。
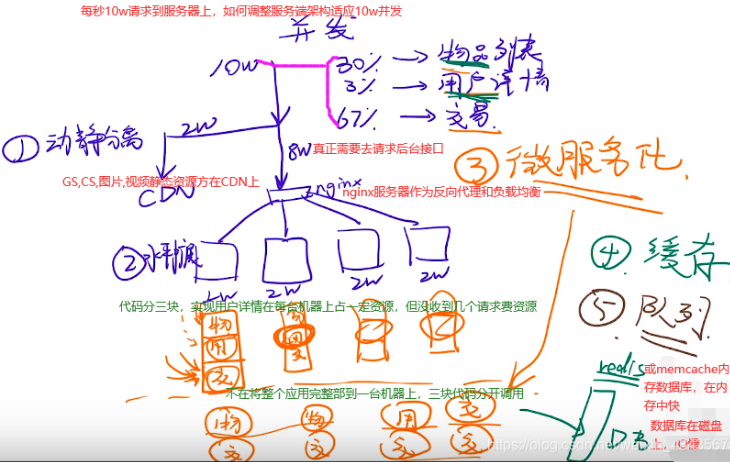
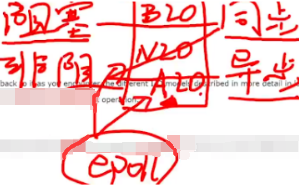
3.IO多路复用:硬盘和网卡
如下A,B。。都是客户端,方框是服务端。首先想到应对并发,写一个多线程程序,每个传上来的请求都是一个线程,现在很多rpc框架用了这种方式,多线程存在弊端:cpu上下文切换,因而多线程不是最好的解决方案,转回单线程。如下while(1)…for…就是单线程。

3.1 select:select是系统调用函数,system是一个C/C++的库函数
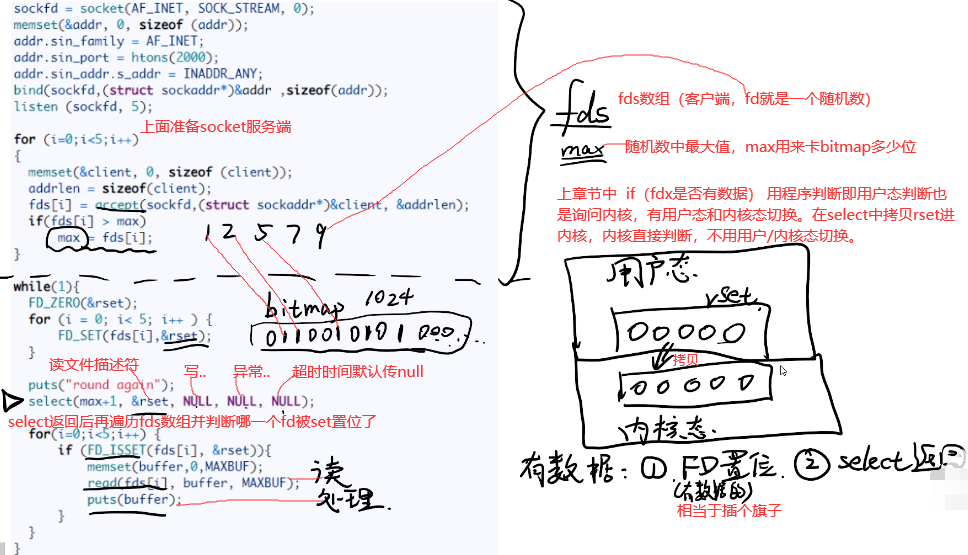
while(1)中FD_ZERO将rset初始化0,用FD_SET将有数据的fd插个旗子,并赋给reset。

3.2 poll:pollfds数组替代bitmap
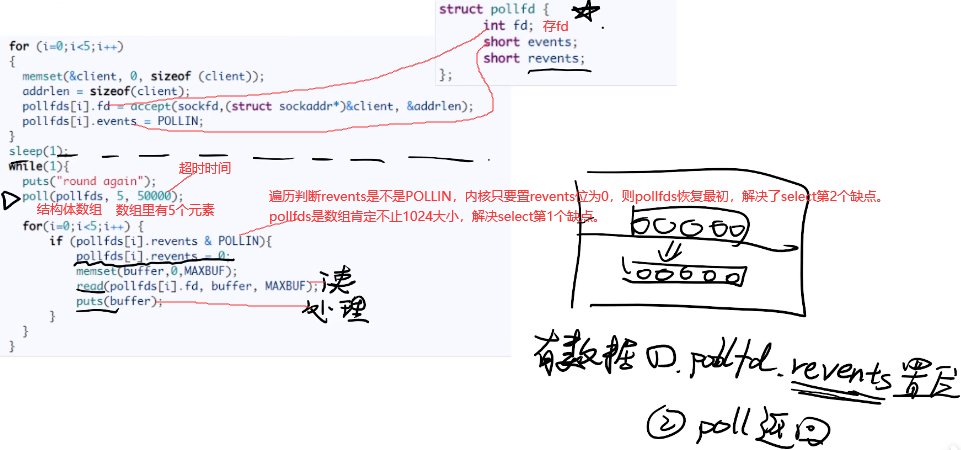
3.3 epoll:epfd是共享内存,不需要用户态切换到内核态
epoll_wait和前面select和poll不一样,有返回值。最后只遍历nfds,不需要轮询,时间复杂度为O(1)。epoll解决select的4个缺点。redis,nginx,javaNIO/AIO都用的是epoll,多路io复用借助了硬件上优势DMA。
IO模型(BIO/NIO/AIO):阻塞:发起io读取数据的线程中函数不能返回。同步:拿到io读取完的数据之后,对数据的处理是在接收数据线程的上下文后紧接着处理。异步:回调函数中进行数据处理



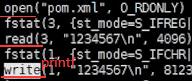
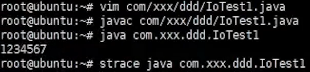
如上看出java比C语言系统调用多的多,因为java要启动jvm虚拟机,jvm要读jdk的lib库等很多操作。如上并没有发现open…xml操作,因为java程序主要启动jvm进程,jvm进程可能又起了很多线程去真正运行main函数,所以加-f。

4.操作系统内存管理与分类:分页,页大小位数=偏移量
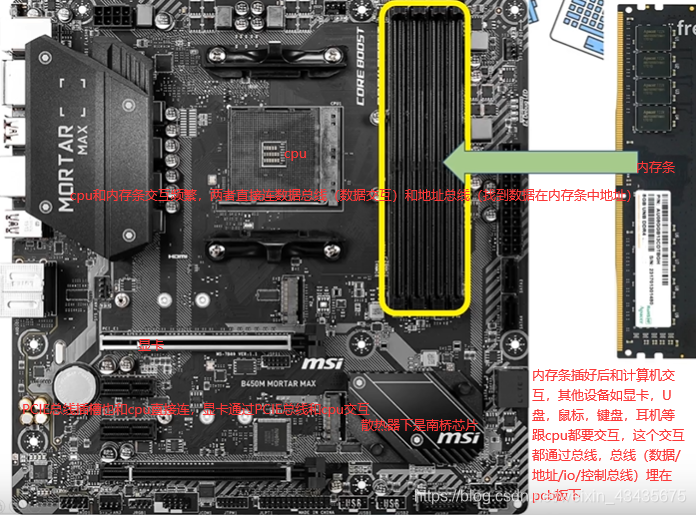
4.1 内存条/总线/DMA(硬件):CPU和DMA是同级,两者对总线控制是轮换隔离
io总线 (包括PCIE总线)最常见的USB(通用串行总线),南桥PCH里有一个DMA控制器,南桥PCH接不太占用带宽的设备如USB/硬盘/网卡/声卡。
Nodejs是单线程,但在读文件时,文件还没读完却可以执行下面几行程序,文件读完后触发一个回调。因为单线程按理来说cpu直接读磁盘中文件的话,应该一直读取这文件,读完前不能进行其他操作,它怎么做到执行其他操作的呢?需要有硬件支持即DMA,读文件操作是非常机械劳动,cpu资源宝贵不能干这种活,下面xxx是内存地址。

cpu要想进行数据搬运,用memcpy(占用cpu资源)。把要访问的源地址,目的地址,还有长度告诉DMA外设搬运,搬运完成产生中断告诉cpu,这样不占用cpu资源。内核怎么管理DMA呢(dma内存申请部分+dma硬件部分)?dma访问物理地址,cpu访问虚地址,需要一个函数实现物理地址和虚地址的转换,还有一种函数如何申请一段既能被cpu访问又能被dma访问的内存,这是内核需关注的问题,内核提供一系列的内存申请函数在doc目录下查找。
问题:dma访问的物理内存不经过cpu cache,假设cpu写一段数据,数据还缓存在cache中,dma从内存中搬运,此时数据不对,所以要将cpu cache刷新到内存。同样,假设网卡发了一段数据到内存,dma去读,此时不能将cpu cache刷新到内存,在dma中断时将cpu cache无效掉。
4.2 用户态和内核态:程序运行过程中可能处于内核态,也可能处于用户态,某一时刻处于用户态,下一时刻可能切换到用户态(但必须有触发条件)
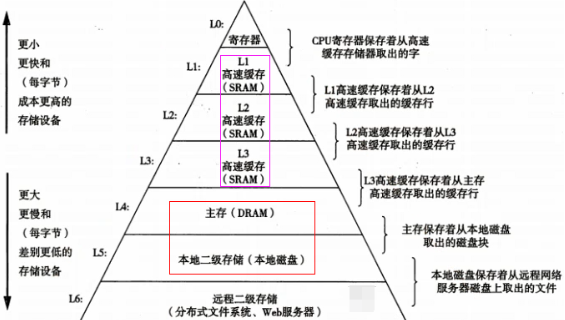
读写文件和申请内存是用户态转内核态的两个例子。malloc的两种实现方式brk和mmap,两者只选一种。brk和mmap申请的都是虚拟内存,不是物理内存,想真拿到物理内存空间还要第一次访问时发现虚拟内存地址未映射到物理内存地址,于是促发一个缺页中断(也叫缺页异常,os中异常和中断有很多类似地方)。C语言是malloc,而java和c++中new对象申请内存空间,也是经过这么过程。
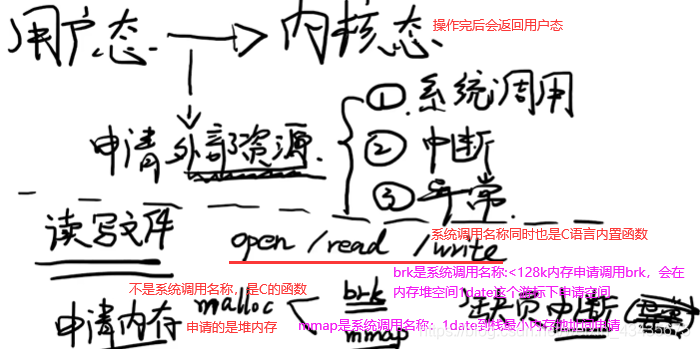
查看linux内核中有多少系统调用:man syscalls如下。第四类信息相关,如获取cpu信息等。管道pipe是进程间通信。open,read,write是文件相关,同时也是对磁盘操作,也可归到设备这类。mmap是文件和内存的映射,mmap申请内存也是对磁盘设备操作,也可属于第三类。

逻辑地址(逻辑/虚拟/进程内存):程序自身看到的内存地址空间,是抽象地址。逻辑地址需映射到物理内存才能完成对内存操作,那为什么程序操作是虚拟的逻辑地址,不能直接操作物理地址即对内存条操作?因为程序是写死的(操作的地址是固定的),而硬件内存条哪些地址被占用了一直变化,因为os是多进程的,当前进程需要操作的地址,其他进程在使用,这样不能使用这块地址了,所以说除非是单进程机器,否则为了进程安全必须做出逻辑地址和物理地址的映射。
所以必须要有逻辑地址,必须要有映射。如何映射?如下固定偏移量映射:程序1的偏移量(初始位置)是0,程序2的偏移量(初始位置)200:如果程序1操作的逻辑地址是100,那么映射的物理地址也100(因为偏移量0);如果程序2操作的逻辑地址是50,映射到物理内存250(因为偏移量200)。
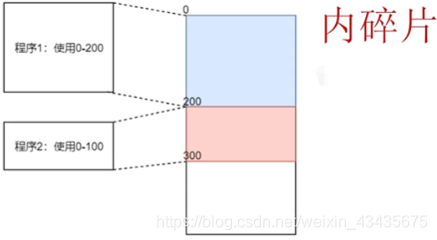
如上看上去简单高效,但存在两个缺陷,第一个缺陷:程序使用的内存无法计算的,随时间推移,进程使用的内存不断变化。这里我们说程序1使用200的内存,这种说法本身不太对的,因为我们没法去限定一个程序使用的内存大小,当然你可以说我估算了这程序使用的最大内存就是200,但这也代表整个200的一段内存中,程序使用的内存绝大多数时间都小于200。蓝色区域中内存使用率并不高,其中存在很多没有利用起来的内存,我们把没利用起来的内存叫内碎片。
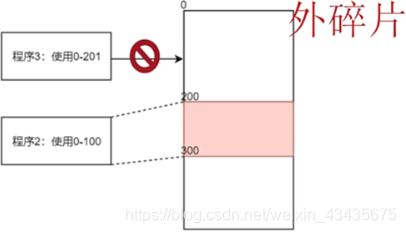
第二个缺陷:当程序运行完,内存被释放,比如程序1执行完后,0-200这块地址被释放出来了,此时程序3使用了内存大小是201,这时程序3没法直接使用0-200这段内存了,假设很长一段时间内都没有占用200以内的内存这样的程序被创建,那么0-200一直被闲置,称这段内存为外碎片。
4.3 分页:为了减少碎片问题
将内存空间包括逻辑内存(左,页,地址连续)和物理内存(右,帧,地址不连续)都进行切分,分成固定大小很多片,每一片称它为页。页到帧的映射需要有个表来维系,这个表就叫页表即pagetable(pagetable不仅存了页号帧号,还存了当前这一页读写权限等等)。
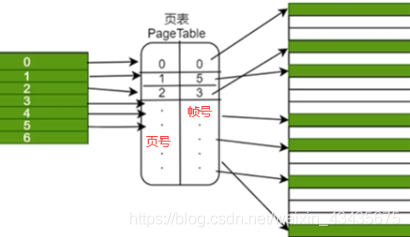
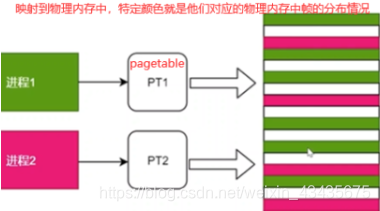
页表是每个进程都需要维护的,因为每个进程映射关系是互相独立的,所以不能共用映射表,每个进程有自己的pagetable。
32位os物理地址有2的32次方个即4000000000个地址(内存的一个地址里住着一字节Byte数据)即4GB。32位程序以为自己拥有4GB内存,如两个32位程序,一个使用了2GB内存,另一个使用了3GB内存。但整个物理机只有4GB内存,造成虚拟地址可能比物理地址大,多出来部分可将虚拟地址的页映射到磁盘上。但映射到磁盘上导致下一次读映射到磁盘上这一页内存时会触发一个缺页中断进入到内核态,整个会产生一个大(major)错误。linux下这磁盘部分又叫swapping(与物理帧交换)。
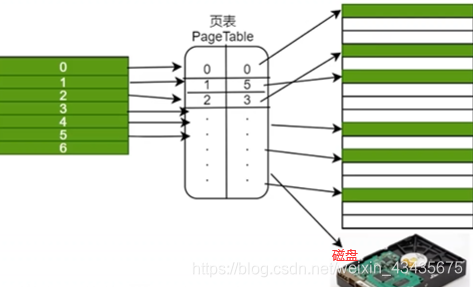
分页小结:1.分页使得每个程序都有很大的逻辑地址空间,通过映射磁盘和高效置换算法,使得内存无限大。
2.分页使不同进程的内存隔离,保证了安全(不同进程各自维系了一个页表,只要页表中value即帧号这一栏不互相冲突,保证不同程序间内存隔离,保证安全性)。
3.分页降低了内存碎片问题。
4.缺点:页表存在我们主存中即存在内存中,如果我们要对某一个内存进行访问的话其实要读取两次内存。因为先读取页表,从页表中拿到对应帧号,再拿帧号去内存中再查询一遍,对内存操作有两次读取【时间上要优化(将页表集成到cpu中的mmu硬件中称为快表,先查快表,查不到查页表)】。页表存在主存中占空间【空间上要优化(多级页表)】。
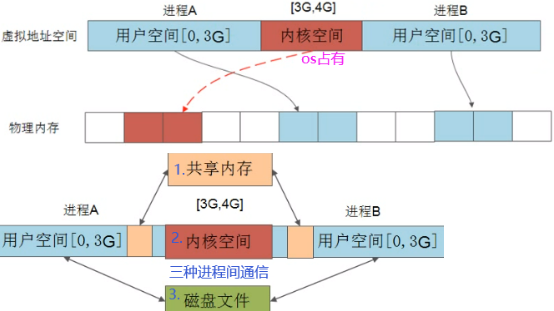
4.4 分段:程序内部的内存管理即分段(对虚拟地址分成多个段),堆区和栈区就是程序的段。text(代码段,存程序本身二进制字节码),data(数据段,存程序中一些静态的变量)
不同程序共享内核(kernel space)这1G空间,共享内存如Libraries函数库(so/dll文件)。

函数参数传递是复制传递即将实参复制一份给形参,因而形参的改变不会影响实参,但是如果参数是指针,那么复制的就是地址的值,通过星号下钻该地址就能修改地址内变量的值。我们把包括结构体在内的基础类型传参称为值传递,而指针的传递称为引用传递。
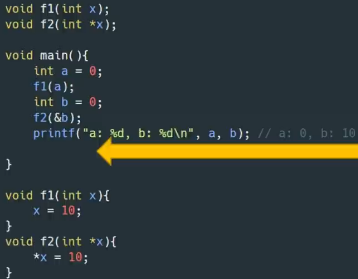
如下从main函数开始。
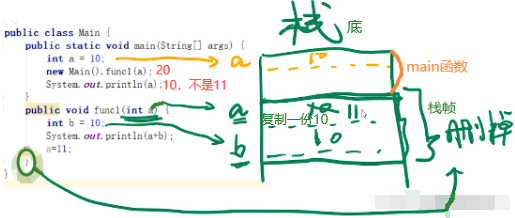
像c、golang是有指针和地址概念,而对于java、python、js等语言,对象的变量名本身就是个指针,因而传递对象就是引用传递。
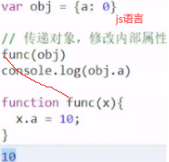
父函数main()在子函数f()入栈之前会留出子函数f()返回值的内存空间,子函数返回值与父函数的入参(这里父函数没有入参,打比方)一样是复制传递。
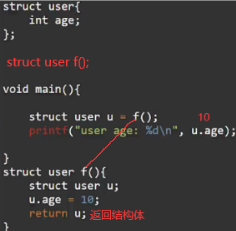
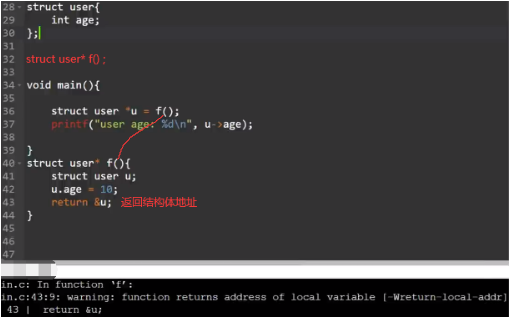
但是返回值如果是指针,可能会导致父函数调用该地址内变量时,子函数已经出栈,导致访问错误。同情况也会出现在全局变量属性赋值时。这些都属于变量逃逸,像go、rust、java会自动进行逃逸分析,将逃逸的变量创建到所有函数共享的全局空间中,这就是堆(heap)。
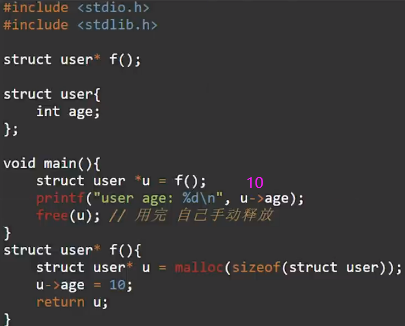
堆内存的释放复杂,像c语言需手动释放,忘记或多次释放都会带来问题,而像java、golang、js、python等是有gc机制能定期自动释放,这会导致性能下降,无法胜任系统级别和硬件编程。
上下文切换:P1进程还没运行完,其中一些信息如程序计数器、变量、程序运行到哪了即context(执行环境,上下文)保存到内核的栈,P2再加载进来运行。调度算法:FIFO(first in first out)非抢占式,谁先来谁先被调度,缺点需等待长时间的进程执行完,其他进程才能分到CPU。STF(short time first)非抢占式,谁的进程时间短,谁先被调度,需要同时到达,不然缺点是长时间进程先到达,后面进程也要等待。STCF(short time complete first)抢占式,谁时间短先被执行,再切回去执行时间长的,缺点是如1000ms的进程一直被抢占导致3000ms才执行完,响应时间太长。RR轮询即cpu将1s分成很多时间片,把这些时间片分给每一个进程,1s多个进程是在并行的。
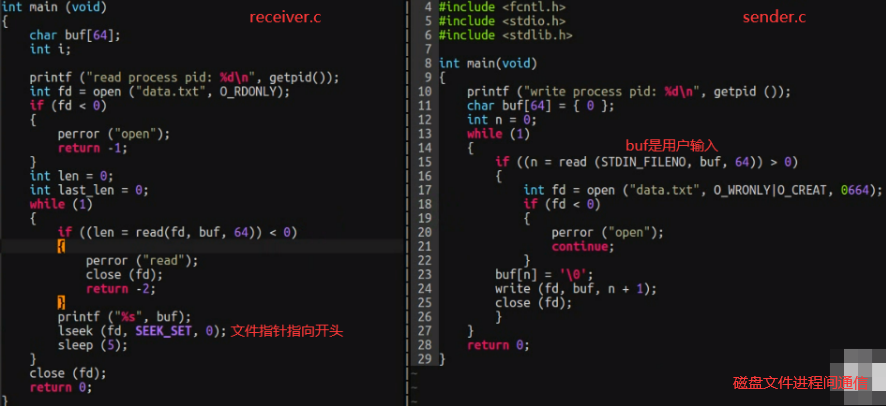
一个cpu多个进程,这些进程放在哪?用什么数据结构存储?进程队列:全局队列(多个cpu一个队列)和局部队列(每个cpu有自己队列)。进程优先级:不是每一个进程都有相同优先级,如下不是ps aux(显示STAT列就是进程状态)。
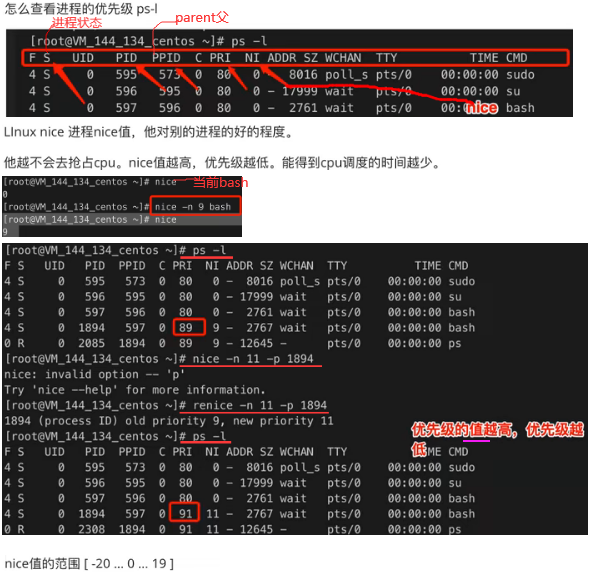
linux调度器:O(n)调度器即遍历进程队列,找到优先级最高的进程。O(1)调度器即优先级0-139映射成140个格子即0或1的bitmap,cpu找到1的格子去执行进程队列(链表或其他数据结构),和hashmap一样。

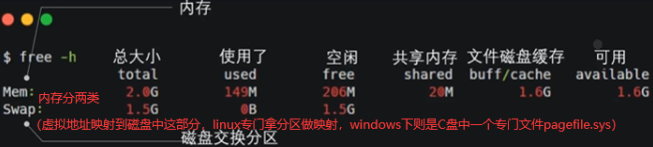
如下free206M和available1.6G能用的是哪个?是1.6G。used包含shared,free是真正的空闲,没有任何东西在使用的大小。文件磁盘缓存指读过的文件暂时帮我们缓存到内存中下次再读的时候直接从内存中拿出来就能加速对文件读写操作。比如说现在free的空间只有206M,我有个程序要用1G内存,能用吗?能,buffer/cache这边1.6G中有800M扔出去释放掉+206M=1G给程序。
buff/cache中间为什么有个/,较早内核中free-h看分buffcache(以磁盘扇区【硬件扇区】为单位直接对磁盘缓存)和pagecache(以页【文件系统】为单位对磁盘文件缓存)两项。两项有重复的地方,文件本质也是磁盘。
4.5 brk:用户无法操作硬件如内存条,必须交给内核帮我们操作完了再把结果给我们
C语言中有sbrk库函数是对brk的一个封装,如下brk申请内存,内存是连续的,并不是说在堆空间随便找内存就把空间给你。
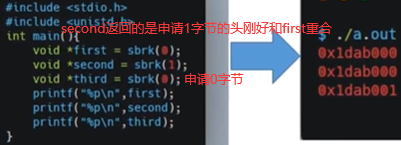
当前我们对第5,6,7,8四个字节赋int值123。只有第一个字节通brk申请出,却给第5-8字节赋值,这样会不会报错呢?不会,主要原因是在上节讲到的操系内存的分页管理所导致的,也就是说brk申请内存申请最小单位为1页,一般系统中页大小4k,所以brk看似申请1字节其实申请了一页(4096个字节),所以第5-8字节也属于4096字节里,也是当前进程所能支配的内存,所以不报错。
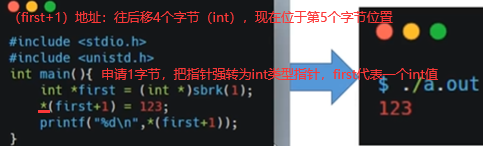
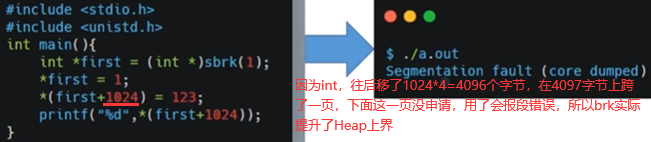
如下+号相当于向后移动1024个int,如下报段错误。
4.6 mmap:pidstat,缺页缺的是内存还是磁盘
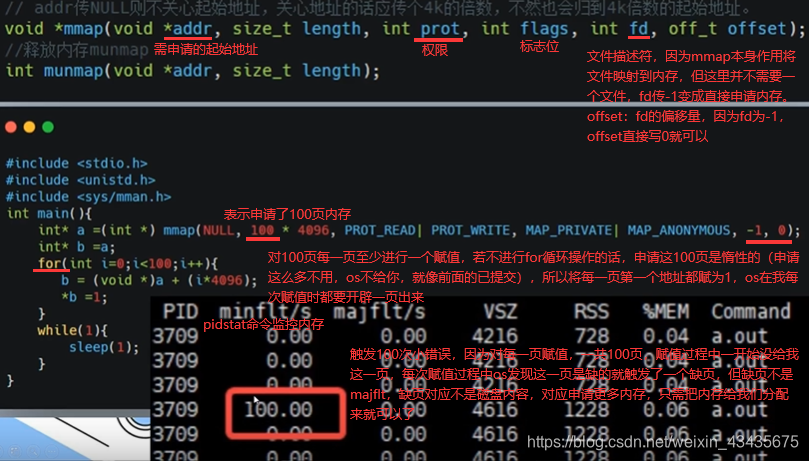
mmap还有直接将磁盘文件映射到内存作用,类似read,不是malloc。
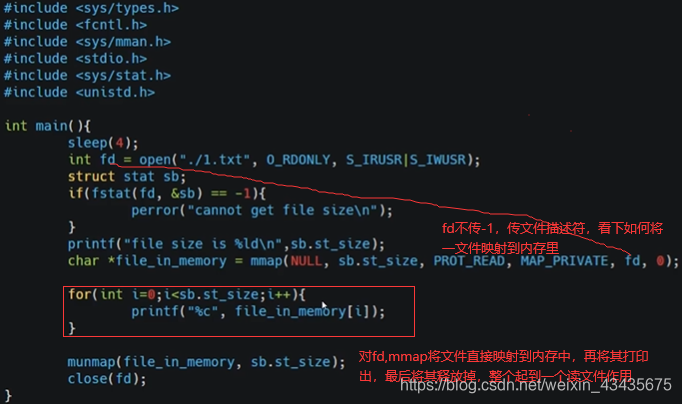
如下触发大错误因为对文件的映射,将文件映射到内存,也是惰性的,这文件没有直接读到内存里,而是当真正需读文件里内容时才会映射到内存里。第一次触发是上面for循环里打印文件内容时到内存中读,发现这一页在查页表时对应是磁盘就触发一个缺页错误,对应是磁盘,触发majflt,将磁盘内容加载到内存中,之后就是一些小错误了。-p:指定进程号。-r:显示各个进程的内存使用统计。grep -v grep过滤掉包含grep的行。最后1是输出1次信息。
read系统调用进入内核态,内核态将文件内容加载到内核空间(如下kernel space),内核空间给它复制到用户空间,再从内核态切换到用户态,然后用户的程序就可读到文件的内容了,有个文件-内核空间-用户空间周转过程。
mmap直接将文件进行了映射,一开始在页表中填充的是磁盘disk即FILE文件,一开始mmap是惰性的直接对应磁盘文件,真正读取时触发缺页将文件加载到内存。
mmap这么牛干嘛还用read函数?mmap虽减少了内核空间到用户空间拷贝(0拷贝),但mmap没法利用前面讲的buffer/cache对文件缓冲这么一块空间,而且mmap第一次触发的缺页异常耗时不一定比read少。
4.7 逃逸分析:对象在声明后只有在当前运行的函数中调用,那么将这个对象栈上申请空间而不是在堆上,因为在栈上申请的对象,函数执行完后会直接清理,大大减轻了GC压力
如下只有第一个线程安全。

Boolean、Byte的所有对象,都是预先创建好的(类加载的时候)。Character、Short、Integer、Long是-128~127的对象是预先创建好的(Character没有负数)。
现象:new Integer(1)则是从创建好的缓存中,直接拿出,因而是同一个:错,new的是新的对象,原因:为了节省内存,这些数字使用概率很高,早就创建好,之后都用同一个,是提高效率的做法。

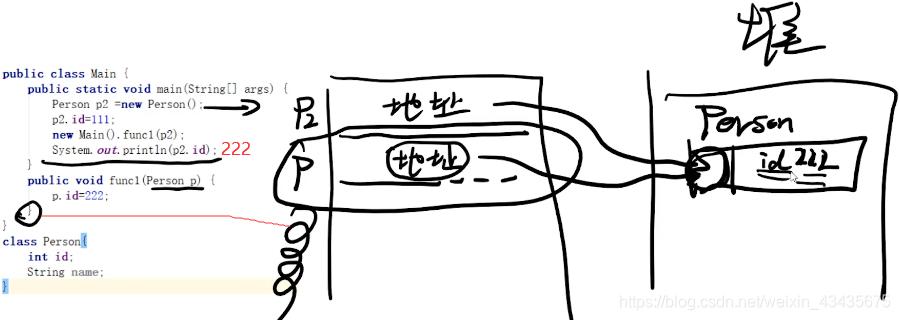
如下是对象类型。func1结束后栈上清空了,但是堆上怎么清空呢?引出GC。main函数静态存方法区。java基础数据类型都是值类型,指针也是值类型,因而直接存到内存,不是存地址去寻址。

如下引用类型传地址,和上面形参a不同。