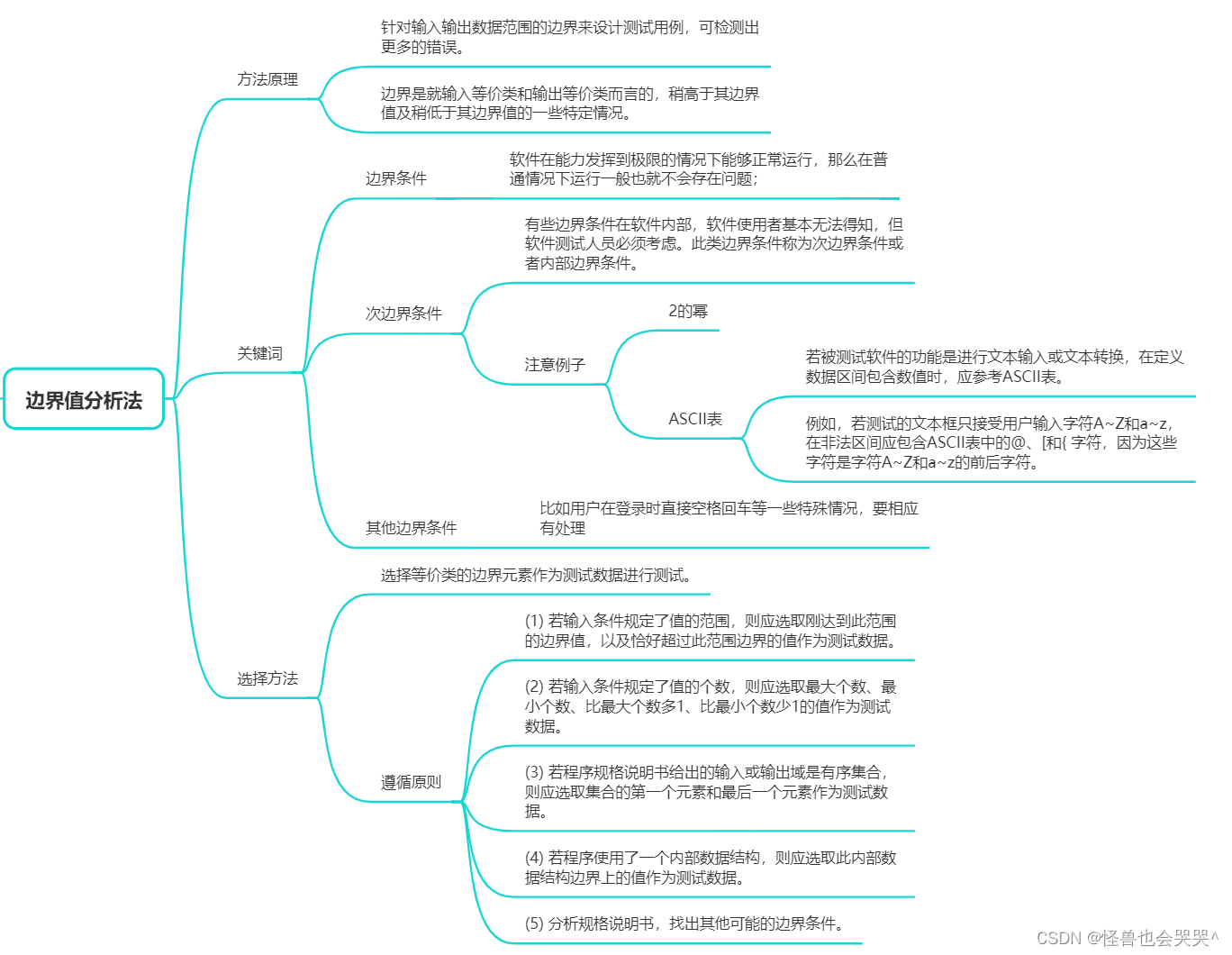
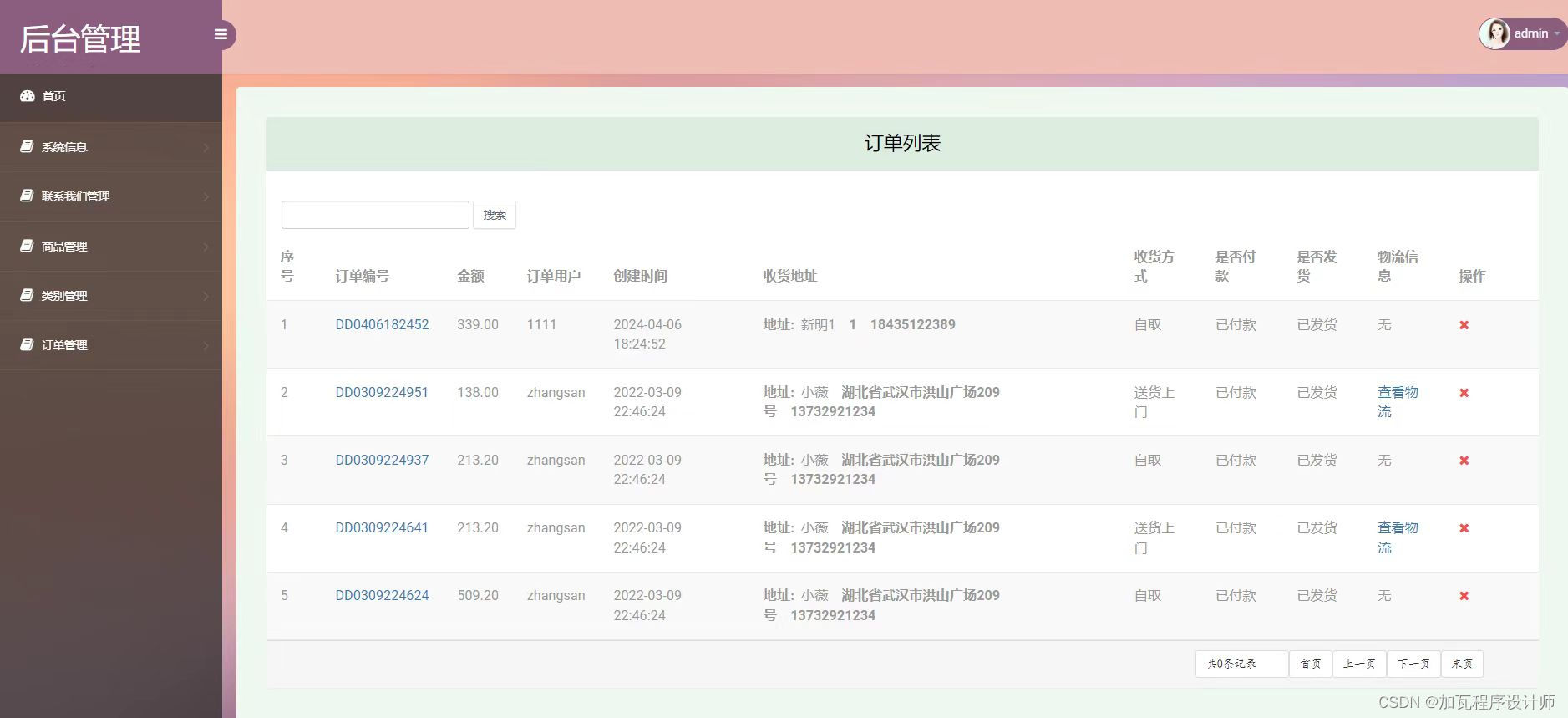
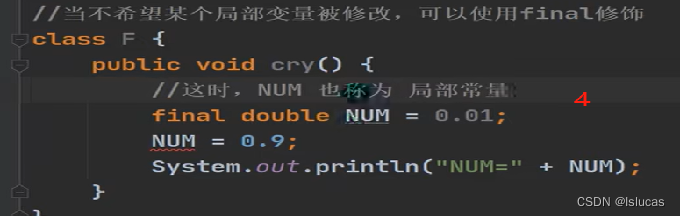
概述
SparkSQL,顾名思义,就是Spark生态体系中的构建在SparkCore基础之上的一个基于SQL的计算模块。SparkSQL的前身不叫SparkSQL,而叫Shark,最开始的时候底层代码优化,sql的解析、执行引擎等等完全基于Hive,总之Shark的执行速度要比hive高出一个数量级,但是hive的发展制约了Shark,所以在15年中旬的时候,shark负责人,将shark项目结束掉,重新独立出来的一个项目,就是sparksql,不再依赖hive,做了独立的发展,逐渐的形成两条互相独立的业务:SparkSQL和Hive-On-Spark。在SparkSQL发展过程中,同时也吸收了Shark有些的特点:基于内存的列存储,动态字节码优化技术。
SparkSQL特点
Integrated
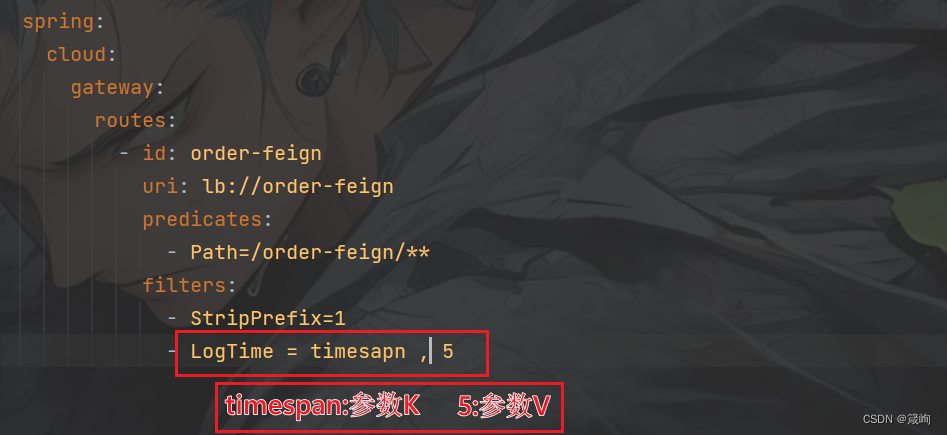
强大的整合能力,可以在spark程序中混合SQL查询操作,如图-1所示。

图-1 SparkSQL特点之integrated
Uniform Data Access
统一的数据访问接口,使得sparksql可以非常便捷的进行数据访问操作,如图-2所示。

图-2 SparkSQL特点之uniform data access
Hive Integration
SparkSQL一个非常重要的功能,就是读写hive中的数据,所以对于hive的强大支持,就是sparksql重要的能力之一,如图-3所示。

图-3 SparkSQL特点之hive integration
Standard Connectivity:
SparkSQL强大的功能的同时,为了方便一些BI组件的调用数据,也提供了支持JDBC/ODBC,使得对数据访问变得多元化,功能完整化,如下图-4所示。

图-4 SparkSQL特点之Standard Connectivity
总结
SparkSQL就是Spark生态体系中用于处理结构化数据的一个模块。结构化数据是什么?存储在关系型数据库中的数据,就是结构化数据;半结构化数据是什么?类似xml、json等的格式的数据被称之为半结构化数据;非结构化数据是什么?音频、视频、图片等为非结构化数据。
换句话说,SparkSQL处理的就是二维表数据。