每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/

Prometheus 2 是一款开源的语言模型,经过优化能够评估其他语言模型的表现,逐渐与 GPT-4 等商业模型相媲美。
这种评估方式为研究人员和开发者提供了客观的测量标准,并能够针对模型的优缺点提供详细反馈,以实现精准改进,进而不断提升语言模型的质量与可靠性。
目前,像 GPT-4 这样的专有模型通常被用于评估,但因其封闭性、不易控制和价格高昂,使许多人望而却步。韩国 KAIST AI 的金承元团队打造了 Prometheus 2,旨在为大家提供透明、独立、详细的语言模型评估工具。
Prometheus 2 模仿人类和 GPT-4 等模型,掌握了两种常用的评估方法:直接评估(使用评分量表打分)和成对比较(判断两个回答中哪个更优)。
定制评估标准,灵活应用
Prometheus 2 支持根据用户定义的标准进行评估,不局限于“有用性”“无害性”等通用指标,使其可以满足特定应用的优化需求。举例来说,在医疗咨询聊天机器人领域,它可以被用于考量“可信度”“共情力”和“专业准确度”等标准,从而开发出适合不同应用场景的高质量语言模型。
新数据集与混合权重
为了训练 Prometheus 2,研究团队创建了一个名为 “Preference Collection” 的全新成对比较数据集,涵盖超过 1000 种不同的评估标准。最佳效果来自于两个独立模型的联合训练:直接评分模型基于 Feedback Collection 数据集,成对比较模型则基于 Preference Collection 数据集。通过将这两个模型的权重合并,达到了最佳评估效果。
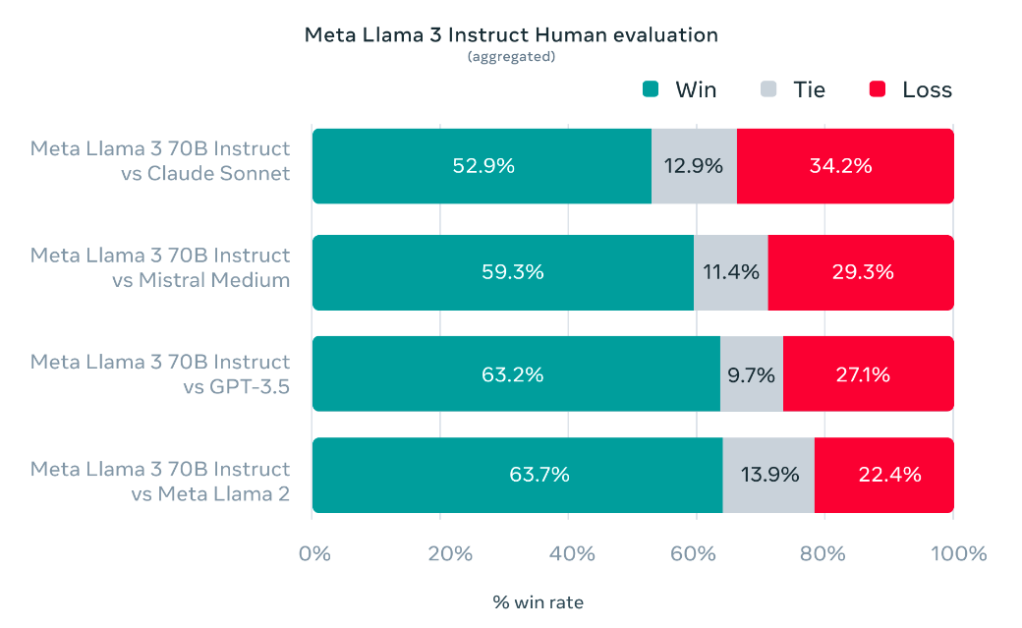
在包含四个直接评分数据集和四个成对比较数据集的测试中,Prometheus 2 在所有可用的评估模型中,显示出与人类判断和商业语言模型最为一致的结果。
虽然在许多测试中落后于 GPT-4 和 Claude 3 Opus,但 Prometheus 2 成功缩小了与这些商业模型之间的差距。
公平与透明的评估工具
Prometheus 2 的代码与数据都已开放至 GitHub 上,任何人都可以获取、使用。两种模型(7B 和 8x7B)可从 HuggingFace 获得。据团队称,7B 模型的评估表现达到了 8x7B 模型的 80%,可与 Mixtral-8x7B 相媲美,甚至优于 Meta 的 Llama 2 70B。
Prometheus 2 让每个人都能独立、透明地评估语言模型,推动了整个领域的公平性与可及性。
下载: GitHub - prometheus-eval/prometheus-eval: Evaluate your LLM's response with Prometheus 💯