MySQL中的哈希索引(Hash Index)是一种特殊的数据库索引类型,它利用哈希表(Hash Table)的数据结构来存储索引项。哈希表通过哈希函数(Hash Function)将索引列的值转化为一个固定长度的哈希码(Hash Code),然后用这个哈希码作为索引项在表中定位数据记录的位置。这种方式使得对于等值查询(例如 WHERE column = value)能够非常快速,理想情况下接近O(1)的时间复杂度。
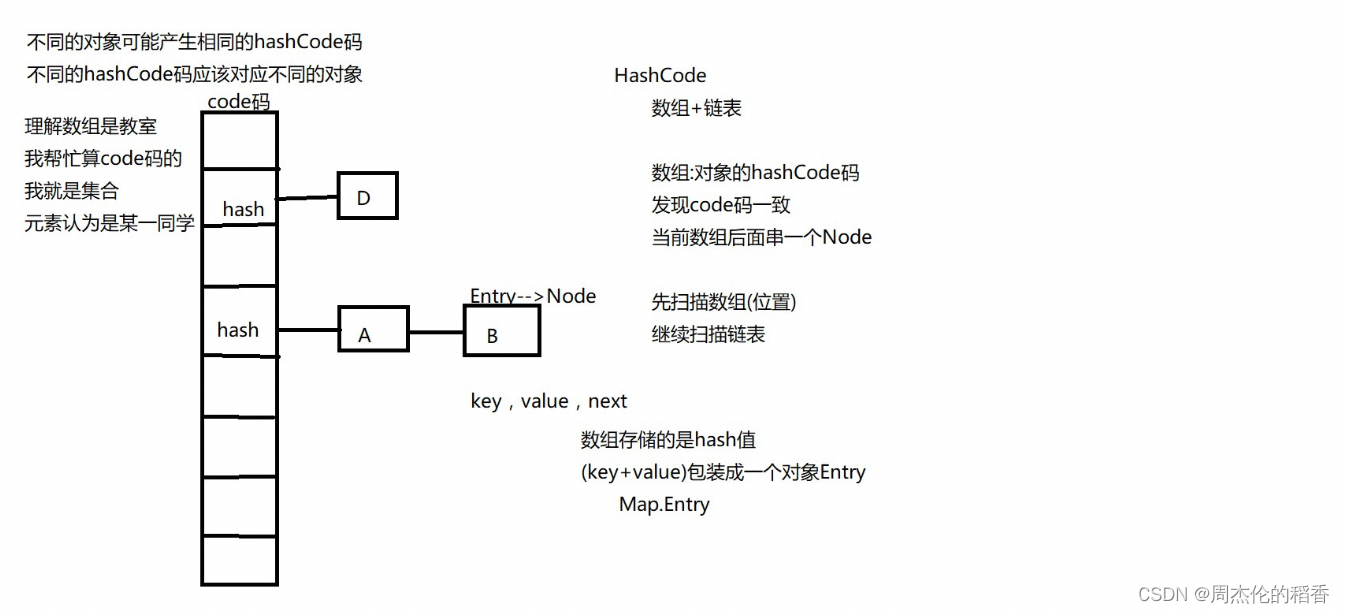
HASH冲突
哈希冲突(Hash Collision或Hash Collision),也称为哈希碰撞,是指在使用哈希函数将数据(如关键字key)映射到哈希表或哈希结构中的索引位置时,两个或多个不同的数据经过哈希处理后得到相同的哈希值,从而导致它们被映射到同一个索引位置的现象。由于哈希函数的输出范围通常是有限的,而输入数据的范围可能是无限的,因此在实际应用中,特别是在较大的数据集中,哈希冲突几乎是不可避免的。
例:如下图我们依次将这些数对 12取余,将这些数添加到对应的关键字里,但是当我们添加16时,我们发现,16和4在散列表的位置冲突了,我们必须给16安排到别的位置去。
解决方法
解决哈希冲突的常用方法包括:
链地址法
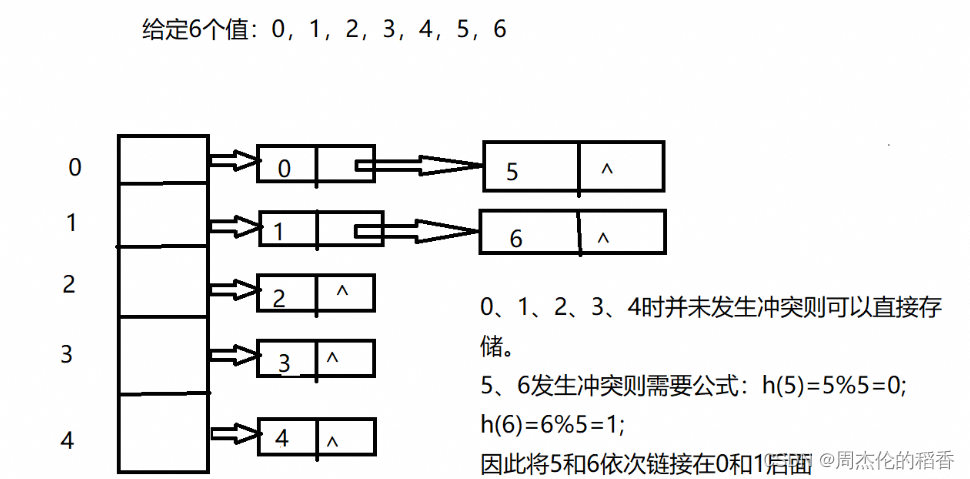
链地址法(Separate Chaining):每个哈希表的槽位(bucket)存储一个链表,所有映射到该槽位的元素都放入这个链表中。这样,即使多个键值对映射到同一索引,也可以通过遍历链表来找到对应的值。
例如:
开放地址法
线性探测(Linear Probing): 发生冲突时,从发生冲突的桶开始,顺序检查下一个桶,直到找到一个空桶为止。如果达到表末尾还没找到空位,则可能需要循环回表头继续探测(称为“闭合”或“循环”探测)。这种方法简单,但可能导致数据在表中的聚集,影响查找效率。
例如:

二次探测(Quadratic Probing): 探测序列是按照1^2, -1^2, 2^2, -2^2, ...这样的平方数距离进行,即每次探测步长逐步增加。这种探测方式试图减少聚集现象,提高查找效率。
例如:

双重散列(Double Hashing): 使用两个不同的哈希函数H1和H2,当H1(key)导致冲突时,使用H2(key)来决定步长,即每次探测的位置是H1(key) + i * H2(key),其中i是递增的探查序列。这种方法可以更有效地分散冲突,减少聚集。
建立公共溢出区
当哈希表的所有槽都被填满时,可以将额外的元素放入一个单独的溢出区或链表中。这种方法简单,但是查找效率较低,因为可能需要检查两个区域。
总结
- 不同的开放地址法主要是通过采用不同的探测步长(或称探测序列生成规则)来区分的。




![[VulnHub靶机渗透] Hackademic: RTB1](https://img-blog.csdnimg.cn/direct/85926679e44140de8d1d2fc264b1736c.png)