1、ES中的倒排索引是什么。
倒排索引,是通过分词策略,形成了词和文章的映射关系表,这种词典+映射表即为倒排索引
2、ES是如何实现master选举的。
选举过程主要包括以下几个步骤:
心跳检测:
每个节点都会定期向集群发送心跳信号,告诉其他节点它仍然存活。如果某个节点在一段时间内没有发送心跳信号,那么它就会被认为已经死亡,选举会重新开始。
候选者列表:
当有节点想要成为 master 节点时,它会将自己添加到候选者列表中。候选者列表中的节点数量可以根据配置进行调整。
投票:
当一个节点成为候选者后,它会向集群中的其他所有节点发送投票请求。每个节点在收到请求后,会根据一定的规则决定是否投票给这个候选者。投票规则通常会考虑节点的健康状况、存储的数据量、负载情况等因素。
选举结果:
如果某个候选者得到了超过半数的投票,那么它就会成为新的 master 节点。如果两个或更多的候选者得到了相同的票数,那么集群将会再次进行选举。
3、如何解决ES集群的脑裂问题。
产生脑裂的可能原因:
网络问题:
集群间的网络延迟导致一些节点访问不到 master,认为 master 挂掉了从而选举出新的master,并对 master 上的分片和副本标红,分配新的主分片。
节点负载:
主节点的角色既为 master 又为 data,访问量较大时可能会导致 ES 停止响应造成大面积延迟,此时其他节点得不到主节点的响应认为主节点挂掉了,会重新选取主节点。
内存回收:
data 节点上的 ES 进程占用的内存较大,引发 JVM 的大规模内存回收,造成 ES 进程失去响应。
解决方案:
减少误判:
discovery.zen.ping_timeout 节点状态的响应时间,默认为 3s,可以适当调大,如果 master在该响应时间的范围内没有做出响应应答,判断该节点已经挂掉了。调大参数(如 6s,discovery.zen.ping_timeout:6),可适当减少误判。
选举触发:
discovery.zen.minimum_master_nodes:1,该参数是用于控制选举行为发生的最小集群主节点数量。当备选主节点的个数大于等于该参数的值,且备选主节点中有该参数个节点认为主节点挂了,进行选举。官方建议为(n/2)+1,n 为主节点个数(即有资格成为主节点的节点个数)
角色分离:
即 master 节点与 data 节点分离,限制角色
4、索引创建过程
官网图如下
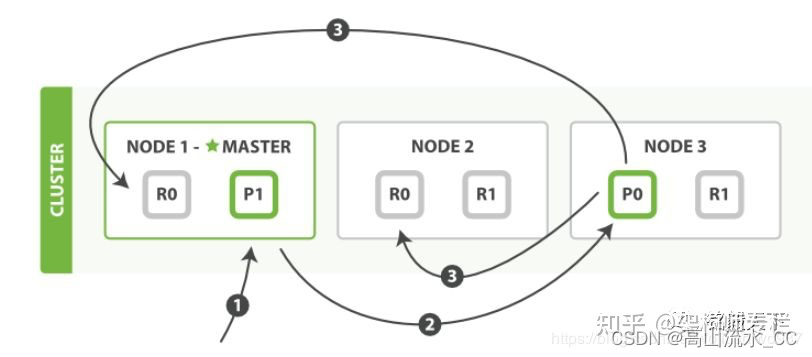
第一步:客户写集群某节点写入数据,发送请求。(如果没有指定路由/协调节点,请求的节点扮演路由节点的角色。)
第二步:节点1接受到请求后,使用文档_id来确定文档属于分片0。请求会被转到另外的节点,假定节点3。因此分片0的主分片分配到节点3上。
第三步:节点3在主分片上执行写操作,如果成功,则将请求并行转发到节点1和节点2的副本分片上,等待结果返回。所有的副本分片都报告成功,节点3将向协调节点(节点1)报告成功,节点1向请求客户端报告写入成功。
5、怎么保证读写的一致性
es怎么保证写的一致性
Elasticsearch(ES)保证写入一致性的方法主要依赖于其内置的一致性模型和配置。以下是一些关键点:
一致性级别:
ES 允许你设置索引的一致性级别,可以是 quorum(大多数节点可用)、one(单个节点可用)、all(所有节点可用)。
复制机制:
通过设置索引的复制分片策略,可以控制数据是被复制到多个节点上,以确保在某个节点失败时数据不丢失。
事务日志:
ES 在写入数据之前会先写入一个事务日志,确保即使数据节点失败,也能基于事务日志进行数据恢复。
文档版本控制:
ES 使用文档版本来保证写入的一致性,当你更新文档时,如果版本号匹配,则允许操作;否则,拒绝操作。
QUORUM 写入:
在执行写入操作时,只有大多数分片可用,操作才会成功。
6、更新和删除文档的过程
6.1、 删除和更新也都是写操作,但是Elasticsearch中的文档是不可变的,因此不能被删除或者改动以展示其变更;
6.2、 磁盘上的每个段都有一个相应的.del文件。当删除请求发送后,文档并没有真的被删除,而是在.del文件中被标记为删除。该文档依然能匹配查询,但是会在结果中被过滤掉。当段合并时,在.del文件中被标记为删除的文档将不会被写入新段。
6.3、 在新的文档被创建时,Elasticsearch会为该文档指定一个版本号,当执行更新时,旧版本的文档在.del文件中被标记为删除,新版本的文档被索引到一个新段。旧版本的文档依然能匹配查询,但是会在结果中被过滤掉。
7、分词器的类型
7.1、Standard Analyzer
标准分析器是默认分词器,如果未指定,则使用该分词器。
它基于Unicode文本分割算法,适用于大多数语言。
7.2、Whitespace Analyzer
基于空格字符切词。
7.3、Stop Analyzer
在simple Analyzer的基础上,移除停用词。
7.4、Keyword Analyzer
不切词,将输入的整个串一起返回。
7.5、自定义分词器
自定义分词器的在Mapping的Setting部分设置:
PUT my_custom_index { "settings":{ "analysis":{ "char_filter":{}, "tokenizer":{}, "filter":{}, "analyzer":{} } } }
脑海中还是上面的三部分组成的图示。其中:
“char_filter”:{},——对应字符过滤部分;
“tokenizer”:{},——对应文本切分为分词部分;
“filter”:{},——对应分词后再过滤部分;
“analyzer”:{}——对应分词器组成部分,其中会包含:1. 2. 3





![Linux主机重启后报错:[FAILED] Failed to start Switch Root.](https://img-blog.csdnimg.cn/direct/9ef41a9007ac4c759147649a72270f8d.png)