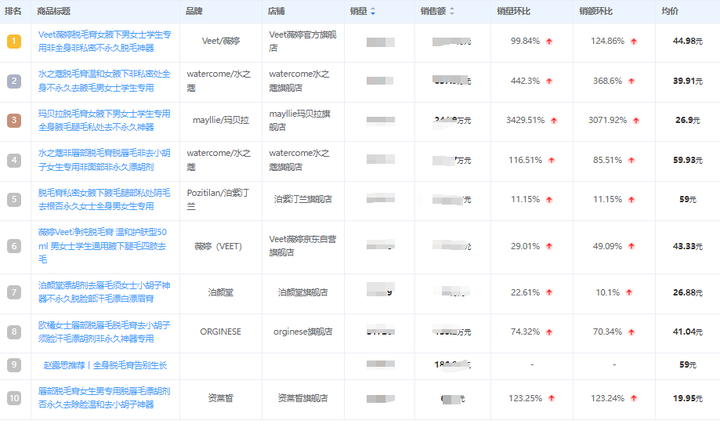
目录
- 概述
- 一、语法
- 二、常用单变量绘图
- 1. 直方图(histplot)
- 2. 核密度预估图(kdeplot)
- 3. 计数柱状图(countplot)
- 三、常用多变量绘图
- 1.散点图
- (1) scatterplot
- (2)regplot 散点图+拟合回归线
- (3)jointplot 散点图+直方图
- 2.蜂巢图
- 3. 2D KDE图
- 4.箱线图(boxplot)
- 5.小提琴图(violinplot)
- 四、Seaborn主题和样式
- 结语
概述
Seaborn是一个基于Matplotlib的Python数据可视化库,它提供了一种简单而美观的界面,帮助初学者轻松创建各种统计图表和数据可视化效果。
Seaborn的设计哲学以美学为中心,致力于创建最佳的数据可视化,同时也保持着与Python生态系统的高度兼容性,可以轻松集成到Python数据分析以及机器学习的工作流程中。Seaborn拥有丰富的可视化函数,能够创建多种类型的图表,包括折线图、柱状图、散点图、核密度图、热力图等等。
相比Matplotlib而言,Seaborn的绘图接口更为集成,通过少量参数设置就能实现大量封装绘图。多数图表具有统计学含义,例如分布、关系、统计、回归等。此外,它对Pandas和Numpy数据类型支持非常友好,风格设置也更为多样,包括风格、绘图环境和颜色配置等。
在进行EDA(Exploratory Data Analysis,探索性数据分析)过程中,Seaborn往往更为高效。然而,需要注意的是,Seaborn与Matplotlib的关系是互为补充而非替代,多数场合中Seaborn是绘图首选,而在某些特定场景下则仍需用Matplotlib进行更为细致的个性化定制。
总的来说,Seaborn是一个功能强大且易于使用的数据可视化库,无论是初学者还是有一定经验的数据分析师,都可以从中获得帮助,更好地理解和展示数据。
一、语法
import seaborn as sns
sns.图表类型plot(data=Dataframe, x='列1',y='列2',hue='类别型' )
参数解释:
- x, y:
x:指定用于柱状图横坐标的变量名(类别型数据)。
y:指定用于柱状图纵坐标的变量名(数值型数据),即每个类别的值。 - data:
指定绘图所需的数据集,通常是一个 pandas DataFrame。 - hue:
用于将数据进行分组的变量名。这个变量将决定每个柱子中的不同颜色分段,用于表示另一个分类维度的信息。
二、常用单变量绘图
1. 直方图(histplot)
语法:
sns.histplot(data=Dataframe,x=列,y=列,bins=n,kda=False,hue='分类变量')
参数:
-
data:
要绘制直方图的数据集,通常是一个 pandas DataFrame 或 Series,也可以是其他可以被转换为数组的数据类型。 -
x, y:
x 和 y 用于指定要绘制直方图的数据列。对于单变量直方图,通常只需要指定 x 参数。如果指定了 y 参数,则绘制的是二维直方图(或称为热图)。 -
bins:
指定直方图的区间数量。可以是整数(表示区间数量)或区间边界的序列。 -
kde
是否使用 Kernel Density Estimation (KDE) 来绘制数据的概率密度曲线(核密度预估图)。 -
hue:
指定用于分组绘制直方图的分类变量。不同组的直方图会以不同的颜色显示。(用于多变量时)
sns.histplot(data=tip,x='total_bill',bins= 10,kde= True)
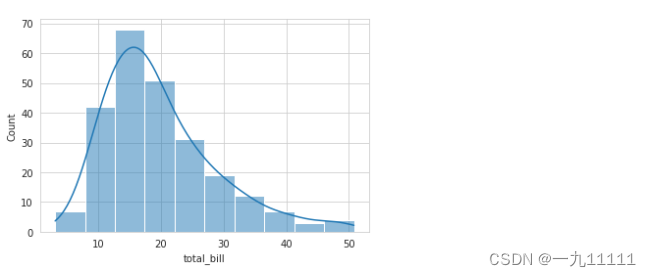
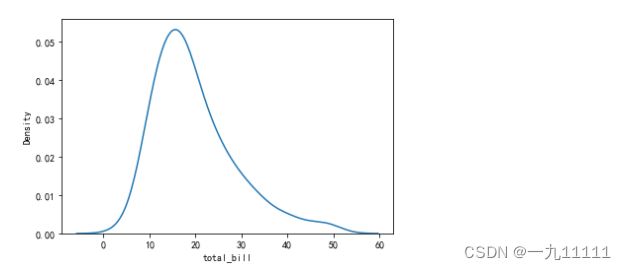
2. 核密度预估图(kdeplot)
sns.kdeplot(data=tip,x='total_bill')
图表展示:
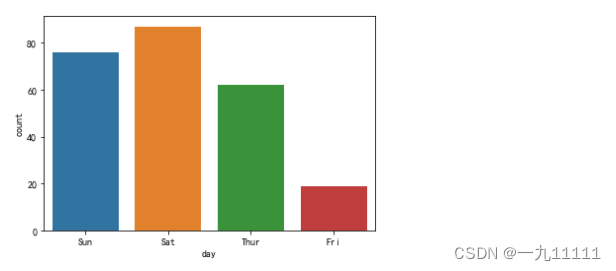
3. 计数柱状图(countplot)
sns.countplot(data=tip,x='day')
图表展示:
三、常用多变量绘图
1.散点图
(1) scatterplot
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 正常显示汉字
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
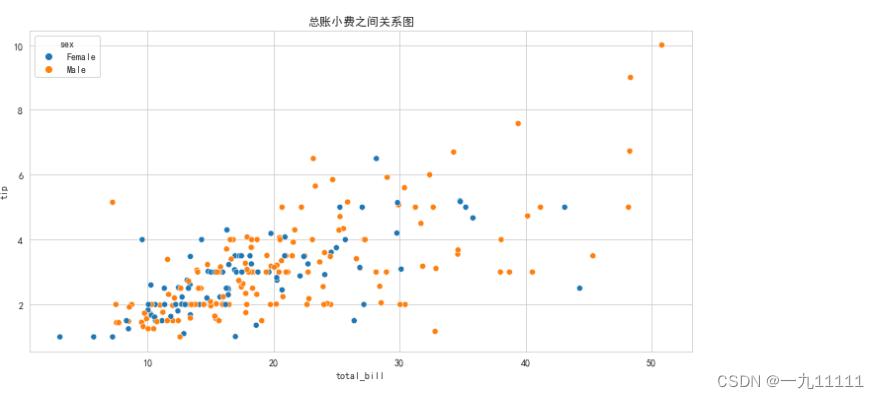
# 散点图
# 1. 绘制画布
fig, ax = plt.subplots(figsize=(12, 6))
# 2. 绘制散点图, x轴: 总账单, y轴: 小费, hue: 基于哪列分组
sns.scatterplot(data=tips, x='total_bill', y='tip', hue='sex')
# 3. 设置标题
ax.set_title('总账小费之间关系图')
# 4. 绘制图片
plt.show()
图表展示:
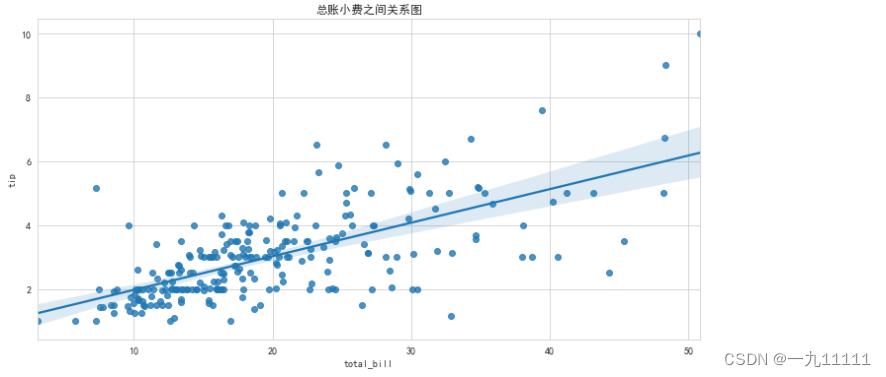
(2)regplot 散点图+拟合回归线
fit_reg参数: 默认是True 会拟合一条直线 就是利用这一份数据 跑了线性回归
# 散点图
# 1. 绘制画布
fig, ax = plt.subplots(figsize=(12, 6))# 2. 绘制散点图
# fit_reg 默认是True 会拟合一条直线 就是利用这一份数据 跑了线性回归
# fit_reg=False 可以关掉
sns.regplot(data=tips, x='total_bill', y='tip', fit_reg=True)
# 3. 设置标题
ax.set_title('总账小费之间关系图')
# 4. 绘图
plt.show()
图表展示:
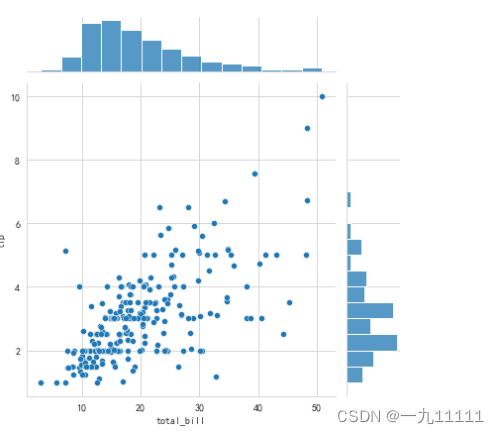
(3)jointplot 散点图+直方图
# 2. 绘制散点图
sns.jointplot(data=tips, x='total_bill', y='tip')
图表展示:
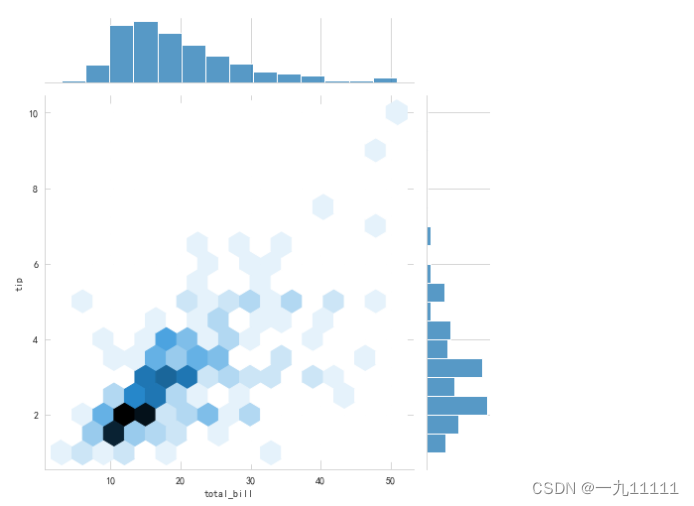
2.蜂巢图
kinde=‘hex’, 加了这个属性就是 蜂巢图, 不加就是散点图.
height 作用为改变图表大小
# kinde='hex', 加了这个属性就是 蜂巢图, 不加就是散点图.
# sns.jointplot(data=tips, x='total_bill', y='tip', height=12) # 散点图, 每行每列再绘制直方图.
sns.jointplot(data=tips, x='total_bill', y='tip', kind='hex', height=12) # 蜂巢图, 每行每列再绘制直方图.
plt.show()
图表展示:
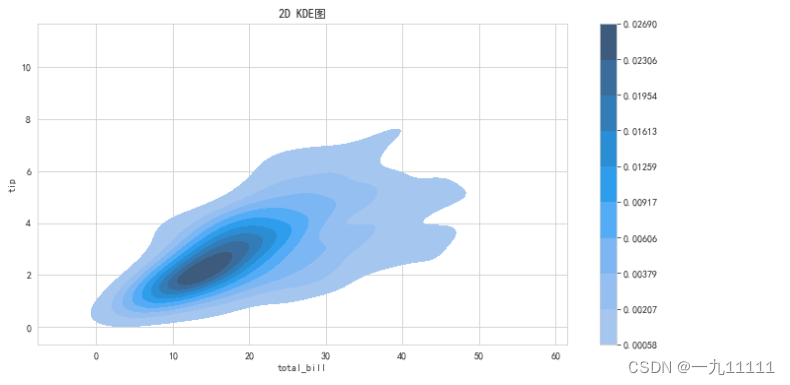
3. 2D KDE图
2D KDE图,即二维核密度估计图(Kernel Density Estimation plot),是一种在二维平面上展示数据概率密度分布的可视化工具。在统计学和数据可视化中,KDE用于估计一个变量的概率密度函数,对于二维数据,可以估计两个变量之间的联合概率密度。
# 一维KDE 只传入x, 或者 只转入Y
# 二维KDE x,y 都传入
# fill=True 是否填充曲线内的颜色
# cbar=True 是否显示 右侧的颜色示意条
fig, ax = plt.subplots(figsize=(12, 6))
sns.kdeplot(data=tips, x='total_bill', y='tip', fill=True, cbar=True)
ax.set_title('2D KDE图')
plt.show()
图表展示:
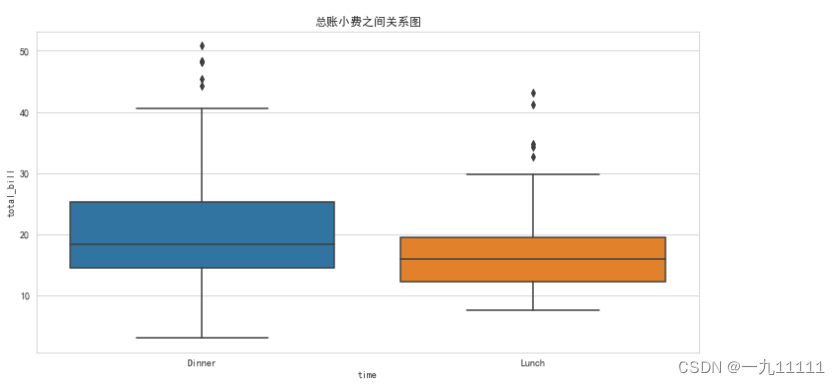
4.箱线图(boxplot)
箱线图(Box Plot),又称为箱型图、盒须图、盒状图或箱状图,是一种用作显示一组数据分散情况资料的统计图。因形状如箱子而得名。在各种领域也经常被使用,常见于品质管理。它主要用于反映原始数据的分布特征,还可以进行多组数据分布特征的比 较。箱线图的绘制方法是:先找出一组数据的上边缘、下边缘、中位数和两个四分位数,然后, 连接两个四分位数画出箱体,再将上边缘和下边缘与箱体相连接,中位数在箱体中间。
箱线图包含的主要数据和含义如下:
中位数(Q2):数据集的中位数,即数据集中处于中间位置的数。在箱线图中,中位数以一条线表示,位于箱体的中间。
上四分位数(Q3):数据集中大于或等于所有数据75%的数。在箱线图中,上四分位数是箱体顶部的线。
下四分位数(Q1):数据集中小于或等于所有数据25%的数。在箱线图中,下四分位数是箱体底部的线。
上边缘(最大值):数据集中的最大值,但不包括任何可能被视为异常值的点。在箱线图中,上边缘以一条线表示,位于箱体上方的短线上。
下边缘(最小值):数据集中的最小值,同样不包括异常值。在箱线图中,下边缘以一条线表示,位于箱体下方的短线上。
此外,箱线图通常还会标出异常值,这些点通常远离箱体的主体部分,可能表示数据中的错误、测量误差或特殊事件。
# 箱线图: 用于显示多种统计信息:最小值,1/4分位,中位数,3/4分位,最大值,以及离群值(如果有)
# 1. 绘制画布, 坐标
fig, ax = plt.subplots(figsize=(12, 6))
# 2. 绘制 箱线图.
sns.boxplot(data=tips, x='time', y='total_bill')
ax.set_title('总账小费之间关系图')
plt.show()
代码实现:
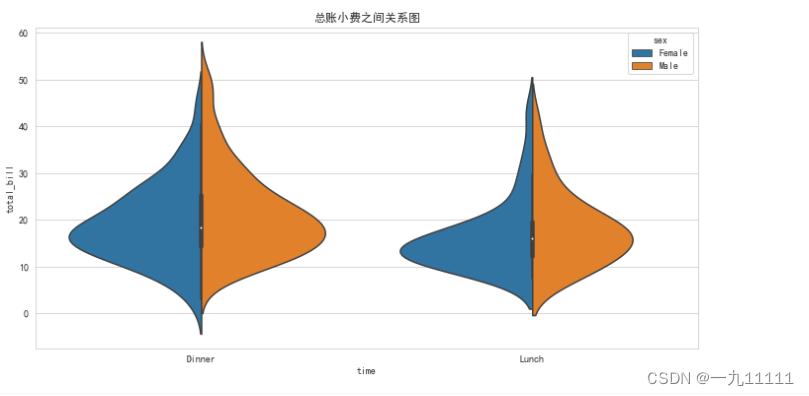
5.小提琴图(violinplot)
小提琴图(Violin Plot)是一种数据可视化图表,它结合了箱线图和核密度图的特点,用于展示数据的分布和概率密度。小提琴图通常用于比较多个组或类别之间的数据分布,以及观察单个变量的分布情况。
小提琴图的主体部分是一组垂直排列的“小提琴”形状,每个小提琴代表一个数据组或类别。小提琴的宽度表示数据点在该位置的密度,越宽表示该位置的数据点越多,越窄则表示数据点越少。中间的黑色粗线条表示四分位数的范围,即25%至75%的数据分布范围。从小提琴的顶部和底部延伸出来的细线(称为“须”),表示数据的最大值和最小值或95%的置信区间。
与箱线图相比,小提琴图的优势在于除了显示中位数、四分位数等统计数据外,还展示了数据的整体分布形状,从而提供了更丰富的信息。
# 多变量, 通过 颜色区分.
# 例如: 使用violinplot函数时,可以通过hue参数按性别(sex)给图着色, 可以为“小提琴”的左右两半着不同颜色,用于区分性别# white, dark, whitegrid, darkgrid, ticks
# sns.set_style('ticks')fig, ax = plt.subplots(figsize=(12, 6))
sns.violinplot(data=tips, x='time', y='total_bill', hue='sex', split=True) # hue='性别'
ax.set_title('总账小费之间关系图')
plt.show()
图表展示:
四、Seaborn主题和样式
上面的Seaborn图都采用了默认样式,可以使用sns.set_style函数更改样式。
该函数只要运行一次,后续绘图的样式都会发生变化
Seaborn有5种样式:
- darkgrid 黑色网格(默认)
- whitegrid 白色网格
- dark 黑色背景
- white 白色背景
- ticks 刻度线
语法:
sns.set_style('主题名')fig,ax = plt.subplots()
ax = sns.violinplot(x='time',y='total_bill',hue='sex',data = tips,split = True)
结语
到目前为止panda入门已经学完了,接下来就是运用pandas强大的功能去完成实际的项目啦。
本系列博客主要深入介绍了Pandas这个强大的Python数据处理库,其核心功能和应用场景。我们详细探讨了以下几个方面:
-
核心数据结构:Pandas提供了两个核心数据结构——DataFrame和Series。DataFrame是一个二维的、大小可变的、可以存储多种类型数据的表格型数据结构,它非常适合存储和处理现实世界中的表格数据,如CSV文件或数据库中的数据。Series则是一维数组型数据结构,用于处理单一类型的数据序列。
-
数据操作功能:Pandas提供了丰富的数据操作功能,包括数据筛选、排序、分组聚合、数据转换等。这些功能使得用户可以轻松地对数据进行各种复杂的操作,从而满足不同的数据处理和分析需求。
-
数据处理流程:我们学习了Pandas在数据处理流程中的应用,包括数据读取、数据清洗、数据转换和数据输出等步骤。Pandas能够方便地处理缺失值、异常值,提供数据重塑和合并等功能,使数据处理流程更加高效和自动化。
-
与其他库的集成:Pandas能够与其他Python库无缝集成,如NumPy用于数值计算、Matplotlib、seaborn用于数据可视化等。这种集成性使得Pandas在数据处理和分析领域具有更广泛的应用前景。
-
性能优化:我们还探讨了如何在使用Pandas时进行优化,包括利用向量化操作提高性能、选择合适的数据类型减少内存占用等。这些优化技巧能够帮助我们更高效地使用Pandas处理大规模数据集。
下次的专栏就是机器学习啦,如果学习的途中有疑问,欢迎在评论区留言,有时间的话,一定会回复哈!!