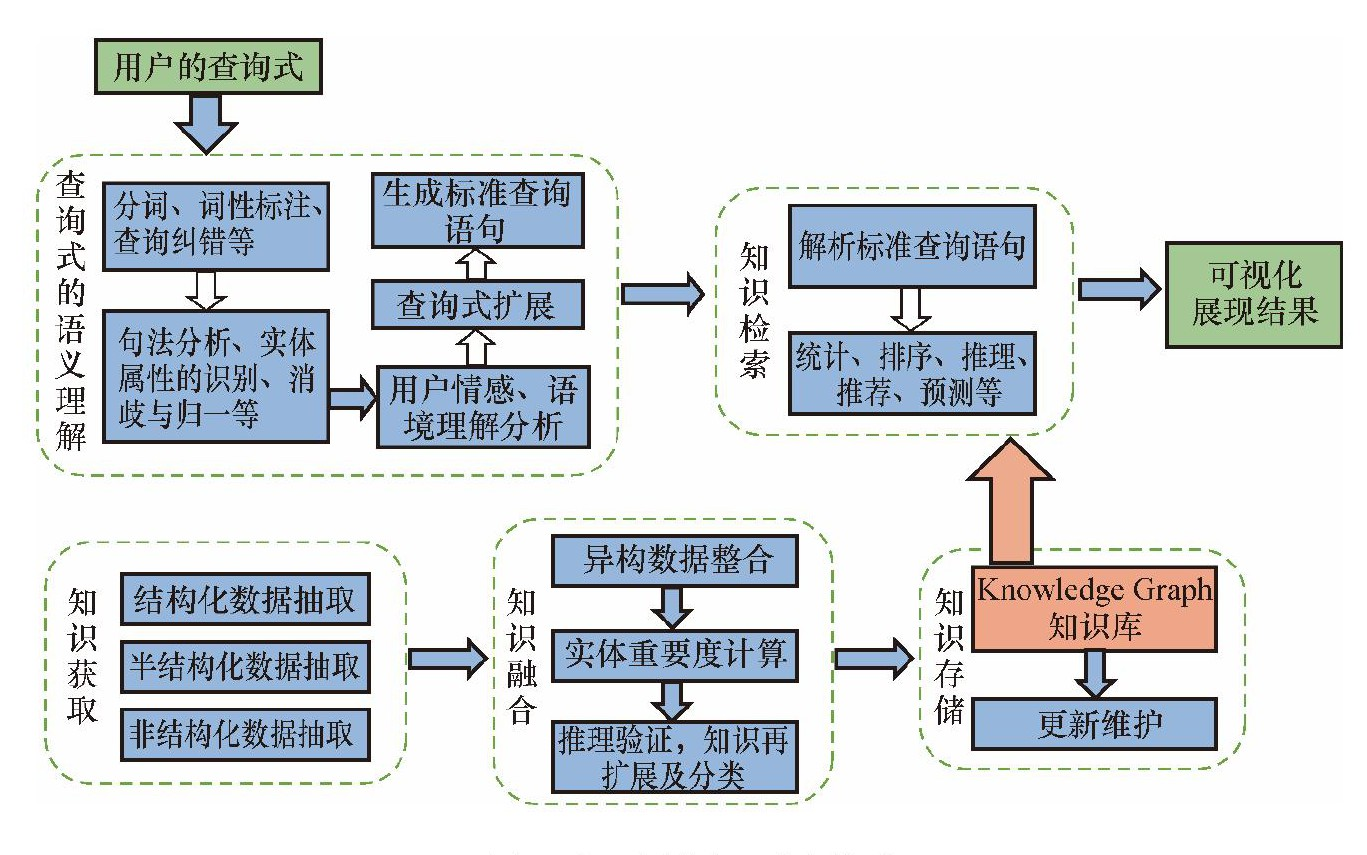
在CodeFuse接入实际业务的过程中,大模型的推理成本以及生成内容的准确性是产品规模落地的两个核心考量因素。为了降低推理成本,我们研发了CodeFuse-ModelCache语义缓存加速功能,通过引入Cache机制,缓存已经计算的结果,当接收到类似请求后直接提取缓存结果返回给用户。另一方面,为了提升代码生成的准确度,我们引入了few shot机制,在输入大模型之前拼接一些类似的代码片段,帮助大模型更好的理解希望生成的目标代码。上述两个核心功能的实现都依赖于向量数据库(Vector Data Management Systems, VDMS)存储并检索相似的请求或者代码片段。为了提高相似性搜索的效率和灵活性,VDMS公开了许多可调索引参数和系统参数供用户指定。然而,由于VDMS的固有特性,VDMS的自动性能调优面临着一些关键挑战,现有的自动调优方法无法很好地解决这些挑战。
在本文中,我们介绍VDTuner,这是一种基于学习的VDMS自动性能调优框架,利用多目标贝叶斯优化。VDTuner克服了与VDMS相关的挑战,首先无需任何先验知识即可有效地探索复杂的多维参数空间。其次,它能够在搜索速度和召回率之间实现良好的平衡,提供高性能配置。广泛的评估表明,与默认设置相比,VDTuner 可以显著提高VDMS性能(搜索速度提升14.12%,召回率提升186.38%),并且与最先进的基线相比效率更高(达到相同性能的调优速度快3.57倍)。此外,VDTuner 可根据特定的用户偏好进行扩展。
VDTuner由蚂蚁集团联合南开大学共同完成,相关成果已经在CodeFuse产品多个场景落地,提升语义缓存加速以及RAG场景相似召回模块的性能,论文已被ICDE 2024接收, 技术细节可以查看预印版本:http://arxiv.org/abs/2404.10413

1. 引言
近年来,大语言模型(Large Language Models, LLM)的出现,将人工智能技术的发展推向了前所未有的繁荣阶段。在LLM应用场景中,通常将非结构化多媒体数据转换为嵌入向量,作为强大的知识库,以克服对话中的幻觉问题。因此,各种专用的矢量数据管理系统(Vector Data Management System, VDMS)旨在为这些载体提供高效、可扩展和可靠的管理。大语言模型应用的蓬勃发展使得高效的VDMS成为LLM时代的基础设施。许多流行的 VDMS,例如 Milvus 和 Qdrant,现在拥有庞大的用户群和特别活跃的社区。
VDMS具有三个显著特点。首先,与许多传统数据库一样,VDMS通常会公开许多可调节系统参数,这些参数对性能有重大影响。其次,VDMS专为海量向量数据的相似性搜索而构建,涉及一个重要的索引查询步骤,该步骤要求用户指定一种索引类型和多个索引参数。第三,VDMS同时包含两个关键性能指标:搜索速度和召回率。尽管传统数据库的自动配置已被广泛研究,现有文献均未考虑VDMS的专用自动配置解决方案。因此,在本文中,我们旨在解决以下问题:如何自动配置VDMS参数以最大限度地提高搜索速度和召回率?
虽然我们观察到自动配置 VDMS 具有巨大的性能改进潜力,但为 VDMS 设计最高效的性能调优方法并非易事。首先,VDMS的参数是错综复杂的相互依赖的,因此要找到最佳的VDMS配置,需要探索复杂的多维搜索空间。其次,VDMS有两个相互冲突的性能指标(即召回率和搜索速度),同时优化这两个指标具有挑战性。第三,不同索引类型的可调参数不同。在有限的调整预算内确定最合适的索引类型具有挑战性。
为了提高传统数据库的性能,已经提出了许多自动调优解决方案。然而,它们在调整VDMS的效率和最佳性方面都存在不足。随机和模拟退火等朴素搜索方法由于不能有效地利用历史信息而缺乏效率。 启发式策略通常采用一些数值优化技术,开销很低,但由于没有考虑参数之间的复杂依赖关系,它们通常存在性能不稳定和局部最优的问题。 基于学习的策略,如贝叶斯优化和强化学习在数据库调优方面也获得了很多关注。虽然他们可以学习复杂的配置空间,实现高性能,但在VDMS调优中,面对不同索引类型的冲突目标和非固定参数空间时,效率仍不足。
为了应对上述挑战,我们提出了VDTuner,一个VDMS的自动调优框架,旨在最大限度地提高搜索速度和召回率。VDTuner具有许多非常有前景的功能,非常适合VDMS调优:(1)不需要有关VDMS的先验知识;(2)能够高效探索复杂的多维参数空间;(3)能够在搜索速度和召回率之间取得良好的平衡。VDTuner 的核心思想是利用多目标贝叶斯优化 (Multi-Objective Bayesian optimization,MOBO),这是一种用于求解黑盒函数的多目标优化问题的流行技术。然而,将MOBO应用于VDMS调优并不容易,我们提出了许多新技术来应对这些挑战。
我们进行了广泛的实验来评估VDTuner。结果表明,与默认设置相比,VDTuner可以显著提高搜索速度和召回率(分别高达14.12%和186.38%),这证实了自动配置VDMS的必要性。此外,VDTuner在VDMS性能和调优效率方面优于最先进的基线,且具有显着优势 (调优速度快1.48倍至3.57倍)。总而言之,做出了以下贡献:
- 我们进行了广泛的初步研究,以确定VDMS调优的主要挑战,并分析VDMS调优中现有解决方案的缺陷。
- 我们提出了VDTuner,一个VDMS的性能调优框架,它利用多目标贝叶斯优化来发现VDMS的最佳配置,最大限度地提高搜索速度和召回率。
- 我们对VDTuner进行了全面评估,以验证其性能并分析其高效的原因。我们证明 VDTuner 以显着的优势击败了所有基线。
2. 背景和研究动机
2.1. 向量数据库
向量数据库管理系统(Vector Data Management Systems,VDMS)是专为高效管理大规模向量数据而构建的数据管理系统。其中,最关键的功能是相似性搜索,即在存储的所有数据中搜索给定新向量的前K个相似向量。向量数据库具有以下显著特点:
多个组件。为增强弹性和灵活性,主流向量数据库架构通常由多个专用功能层(如访问层、协调层、工作节点层和存储层)组成。每一层都包含多个协同工作的组件。在Milvus中,例如,数据协调器和索引协调器分别管理数据节点和索引节点的拓扑结构。这些组件公开了向量数据库的多个可调参数(称为“系统参数”),以满足不同场景的需求。
多种索引类型。相似性搜索的复杂性要求在向量数据库中集成多种近似最近邻搜索(Approximate Nearest Neighbor Search,ANNS)算法,如乘积量化(Product Quantization,PQ)。每个ANNS算法对应一个向量数据库的索引选项,即“索引类型”,因此,向量数据库通常需要维护多种索引类型。例如,索引类型IVF_PQ内部采用PQ算法,而索引类型HNSW(Hierarchical Navigable Small World Graph)采用基于图的ANNS算法。用户在进行索引查询时需指定索引类型(如HNSW)和该索引类型的参数(称为“索引参数”)的值(如节点度M和搜索范围efConstruction)。这种索引查询方式通常能够显著提升大型数据集上相似性搜索的效率。
多种性能指标。不同的ANNS算法表现出不同的搜索速度(即每秒处理的请求数)和召回率(即正确检索到的向量与正确向量总数的比率)。同时,对于同一ANNS算法,不同的索引参数也会导致性能的变化。因此,用户通常关注两个关键指标:搜索速度和召回率。他们共同衡量了向量数据库在相似性搜索过程中的性能表现。
2.2. 自动调优向量数据库的挑战
虽然向量数据库的参数设置会极大地影响其性能,但自动调优向量数据库面临着许多挑战。
首先,向量数据库参数错综复杂地相互依赖,因此找到最佳向量数据库配置需要探索复杂的多维搜索空间。以流行的向量数据库Milvus为例,官方推荐的性能调优索引和系统参数总共有 16 个维度,并且大多数参数的值是连续的。由此产生的空间非常大,因此不可能穷尽所有可能的配置。另一种方法是单独考虑每个参数以降低搜索复杂性。不幸的是,这是不可行的,因为 向量数据库 配置彼此错综复杂地相互依赖。图1显示了配置两个系统参数(segment_maxSize 和 segment_sealProportion)的示例。颜色越深表示搜索速度或召回率越好。可以看出,一个参数的性能受到另一参数的影响。例如,大多数 segment_sealProportion 值(高于 0.1)可以在较大 segment_maxSize(= 1000)下获得较高的搜索速度,而如果 segment_maxSize 限制为 100,则segment_sealProportion 需要高于 0.9。
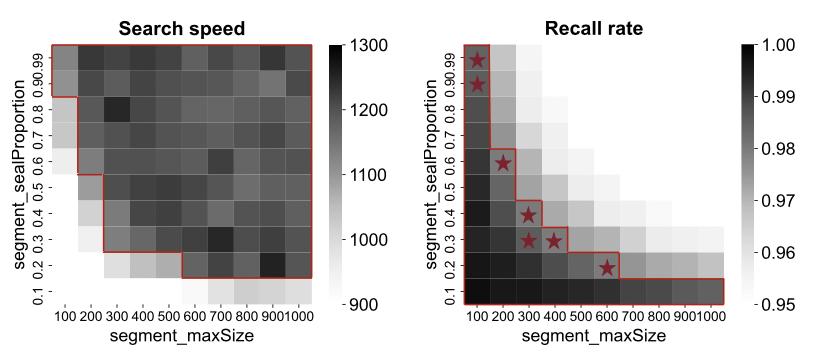
图1 复杂配置空间:不同系统配置的搜索速度和召回率。红线标识了配置优于默认设置的高质量空间。星星标记了对这两个目标来说都是最佳的配置。
同样,索引和系统参数之间也存在相互依赖关系。如图2所示,不同系统配置下的最佳索引类型可能不同:对于系统配置1和2,IVF_FLAT是最佳的,而在系统配置3和4下HNSW变得更好。这是因为某些索引配置在相似性搜索中可能有更高的段大小要求。不幸的是,即使对于专家来说,这些相互依赖性也不容易理解,因为向量数据库正处于快速发展阶段。 Milvus 几乎每隔几天或几周更新一次,参数的数量和范围频繁变化。因此,一种有前途的方法应该协调调整这些参数,而不需要任何先验领域知识。
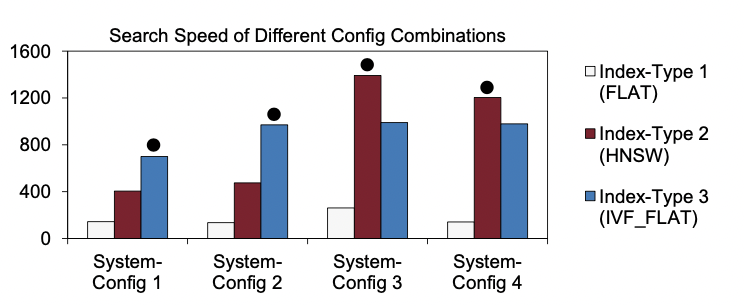
图2 最佳索引类型随系统配置变化
其次,向量数据库关注两个重要指标(搜索速度和召回率),找到一个在相互冲突的目标之间取得良好平衡的配置具有挑战性。如前所述,有两个重要指标(搜索速度和召回率)来衡量向量数据库的性能。然而,很难找到对这两个指标都最佳的配置,因为它们本质上是冲突的。如图1所示,高搜索速度配置和高召回率配置(用红线标记)彼此非常不同。仅优化一个目标可能会导致另一个目标的性能显著下降。例如,最高召回率配置的搜索速度令人无法接受,仅为默认值的 28.8%。因此,一个智能的方法必须在相互冲突的目标之间取得平衡,从而在不牺牲或较少牺牲任何目标(用红星标记)的情况下找到最佳配置。缓解这一困难的一种简单方法是将索引类型简单地固定为“公认的最佳索引类型”。不幸的是,在所有情况下都没有赢家。图3(a) 和 (b) 说明了索引类型在两个数据集下的性能。如果用户希望最大化搜索速度,同时保持召回率高于 0.8,那么在数据集 1 中,SCANN 是一个足够好的选择。然而,在数据集 2 中,HNSW 成为最佳选择,因为大多数索引类型都无法保持合理的召回率。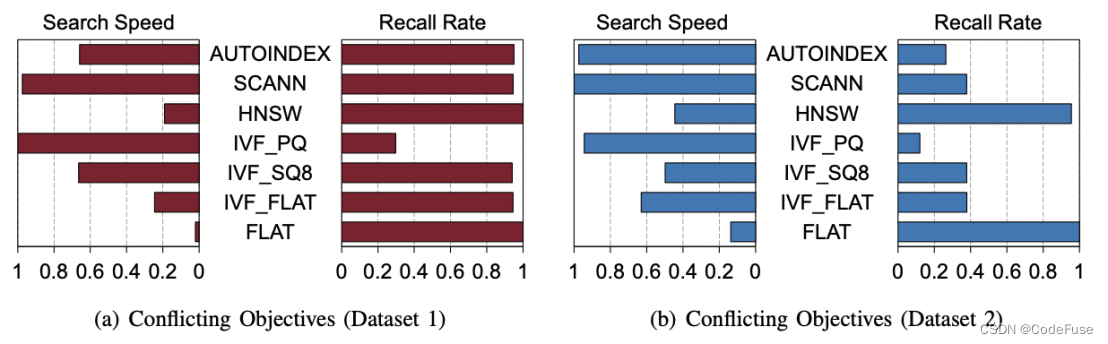
图3 不同数据集最佳索引类型(兼顾搜索速度和召回率)不同
最后,不同索引类型的可调参数不同,而在有限的调优预算内确定最合适的索引类型具有挑战性。
有许多索引类型可以在向量数据库中选择,但是每种索引类型下的可调参数是不同的。表1显示了 Milvus 中可选的索引类型以及相应的可调参数。可以看出,虽然某些参数在不同索引类型之间共享,但不同索引类型的可调参数组合却有很大不同(例如,IVF_FLAT 和 IVF_PQ 都有参数 nlist 和 nprobe,而 IVF_PQ 具有唯一参数 m 和 nbits)。这可能会给自动配置向量数据库带来额外的复杂性,因为大多数现有的调整方法假设一组固定的可调参数,即参数及其范围不会改变。
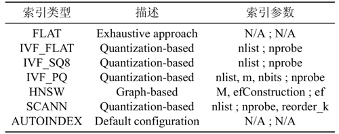
表1索引类型以及对应的可调索引参数
解决这个问题的一个自然想法是单独调整每个索引类型的参数。然而,这很耗时,因为最终只能选择一种索引类型进行搜索。另外,仅优化最优指标类型也很棘手,因为通过简单的抽样方法很难找到最佳指标类型。图4显示了每种索引类型的性能随样本数量的变化(通过均匀采样)。可以看出,不同的索引类型有不同程度的性能变化,因此很难区分哪一种是最优的。例如,如果只根据前10个样本选择最好的索引类型,那么绿色的就是最好的。然而,红色实际上更好,因为它随后超过了绿色。请注意,确定最合适的索引类型需要远远超过 10 个样本,因为需要为每个索引类型收集多个样本才能进行比较。
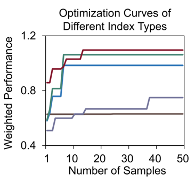
图4 不同索引系数类型的性能随样本数量的变化
3. VDTuner框架设计
到目前为止,研究人员已经提出了许多自动调优解决方案来寻找数据库的高性能配置。然而,由于上述挑战,现有的解决方案都不能很好地解决向量数据库调优问题。在本章中,我们提出了VDTuner,一个采用多目标贝叶斯优化来自动配置向量数据库的框架,以最大限度地提高召回率和搜索速度。
3.1. 多目标贝叶斯优化
在本节中,我们介绍多目标贝叶斯优化的工作原理,并总结设计基于多目标贝叶斯优化的高效自动调节器的优点和挑战。
贝叶斯优化(Bayesian Optimization,BO)是一种强大的基于顺序模型的优化技术,旨在找到黑盒函数的全局最优值。 BO背后的核心思想是构建一个概率代理模型,通常使用高斯过程来逼近未知的目标函数。随着获得新函数评估,该代理模型会迭代更新,从而能够纳入新信息并完善模型的预测。在每次迭代中,BO 使用获取函数(例如预期改进或改进概率)来确定下一个要评估的点。这种获取函数平衡了对未探索区域的探索和对有前景区域的开发,使算法能够通过有限的函数评估有效地搜索全局最优值。
多目标贝叶斯优化(Multi-Objective Bayesian Optimization,MOBO)是 BO 的扩展,它解决了多个目标相互冲突的问题。它的目的是找到一组代表帕累托前沿的解决方案,代表不同目标之间的最佳权衡。在 MOBO 中,代理模型被扩展以处理多个目标。这可以通过单独建模和预测每个目标做到。该模型捕获输入变量和多个目标函数之间的关系,从而可以预测未观察点的目标值。在 MOBO 中,获取功能被扩展为选择有前途的解决方案,在相互冲突的目标之间取得平衡。一种流行的方法是使用预期超容量改进(Expected Hypervolume Improvement,EHVI)指标。该指标使用候选方案添加到现有解决方案集所贡献的超容量增益来评估新解决方案的质量。
为了计算 EHVI,我们首先需要构造一个超体积指标,它量化当前解集的超体积。然后,通过对目标空间的不确定区域进行积分并考虑新解的概率分布来计算超体积的预期改进。在所有候选解决方案中,获取函数优先选择 EHVI 最高的解决方案。图5显示了计算 EHVI 的示例。在(a)中,蓝色区域代表三个帕累托前沿解的超体积; 在(b)中,红色区域代表新增解 x1 的EHVI,绿色区域代表新增解 x2 的EHVI;x2 的 EHVI 高于 x1,这将被认为是更好的解决方案。 EHVI指标不仅考虑单个目标的改进,还考虑帕累托前沿的整体覆盖范围,代表最优的权衡解决方案。通过优化 EHVI,我们可以引导搜索提高 Pareto 前沿质量和多样性的解决方案。
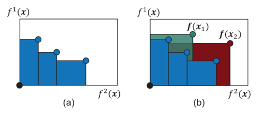
图5 EHVI示例
为什么MOBO适合于向量数据库的性能调优?VDTuner采用MOBO作为其核心优化引擎,主要原因如下。首先,MOBO不需要任何有关向量数据库的先验知识,这减轻了管理员了解复杂且快速变化的向量数据库版本的压力。其次,向量数据库配置的评估成本高昂,通常需要几分钟甚至几小时,尤其是在索引类型更改后重新构建向量索引时。 MOBO可以通过高效、智能地探索复杂的多维参数空间来避免过多的配置评估。第三,MOBO最初是为了优化多个目标而设计的,这与我们优化两个目标(搜索速度和召回率)的需求完美契合。
将MOBO应用于向量数据库性能调优的挑战。尽管 MOBO 有许多吸引人的优点,但将其应用于 向量数据库 调优仍然具有挑战性,原因如下。首先,原始BO模型通常需要一组固定的调优参数,而向量数据库中不同索引类型的调优参数并不固定。因此,为了将BO应用于向量数据库,需要专门的设计。其次,我们的初步研究(图4)表明不同的索引类型具有明显的性能差异。因此,将调优预算平均分配给所有索引类型是低效的,需要更高效的预算分配方式。第三,向量数据库中的所有索引类型共享一些全局调整参数(例如系统参数),这意味着从一种索引类型学到的知识也可能对其他索引类型有启发。因此,如何充分利用从不同指数类型中学到的知识值得探索。
3.2. VDTuner的调优方案
VDTuner 的整体工作流程。如图6所示,VDTuner 对向量数据库的配置进行迭代采样,以学习包含所有索引类型的所有可调参数的整体 BO 模型。在每次迭代中,VDTuner指定索引类型,并且BO模型的获取函数推荐针对指定索引类型进行采样的配置。采用轮询的方式指定索引类型,但VDTuner会陆续放弃性能较差的索引类型,以确保更重要的索引类型获得更大的预算分配。然后使用新采样的配置来更新代理模型。直到找到足够好的配置,调优过程将终止。
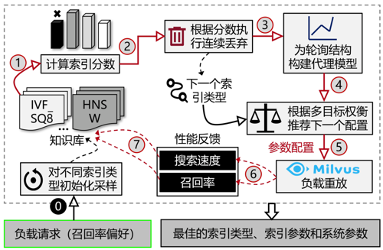
图6 VDTuner自动寻优框架
整体BO优化结构。由于很多参数(例如系统参数)在不同的索引类型里是共享的,简单的为每个索引类型单独构建BO模型并选择最优的索引类型是低效的。因此,采用统一的全局BO模型轮询学习不同的参数类型。整体BO轮询学习方式具有以下几个优势:首先共享的参数不会被重复的调优;其次,相同参数在不同索引类型的BO模型里学到的知识可以共享。



算法伪代码。总体而言,我们在以下算法中报告了 VDTuner 轮询贝叶斯优化的伪代码。对于给定的工作负载(例如,一批相似性搜索请求),VDTuner 首先对所有索引类型执行初始采样(第 1-5 行),采样的配置作为 VDTuner 的初步训练数据。在每次调整迭代中(第6-23行),如果剩余索引类型超过一种,VDTuner首先对索引类型进行评分,并据此决定是否放弃最差的索引类型(第7-14行);然后,VDTuner 使用所有索引类型的数据构建专门的 GP 代理模型(第 15-18 行);之后,对于当前的轮询索引类型,VDTuner推荐了一种有前途的配置(第19-21行),该配置可以最大化采集功能;最后,评估推荐的配置,VDTuner 根据反馈更新其知识库(第 22 行)。 VDTuner 的终止条件不是固定的,可以灵活指定,例如最大样本数或性能持续一段时间没有提升。
处理用户偏好。到目前为止,我们假设用户对 向量数据库 调整的任一目标没有偏好。然而,在某些场景下,用户可能会要求优化搜索速度,同时保持召回率高于定义的阈值,而这是EHVI采集功能无法捕获的。因此,VDTuner 结合了约束模型来指导召回率约束区域内的搜索。约束模型量化候选配置满足约束的概率。具体来说,当出现用户定义的召回率约束(例如,rlim > 0.85)时,我们将获取函数替换为约束获取函数。约束获取函数是EI取函数(衡量预期搜索速度改进)和概率函数(衡量实现高于 rlim 的召回率的可能性)的乘积。这表明VDTuner放宽了同时实现高搜索速度和召回率的目标,而是专注于在约束区域内最大化搜索速度。
对于更一般的情况,用户可能有波动的召回率偏好。直观上,从头开始学习每个新的召回率约束并不高效,因为之前的采样数据可能包含可以共享的有用信息。特别是,旧召回率约束的初始采样可能反映配置空间的粗略性能分布,即使 VDTuner 之后逐渐专注于约束区域内的优化。因此,VDTuner 通过使用不同召回率约束的先前采样数据(如果可用)预热代理模型来引导自动调优。
4. 实验评估
实验平台和数据集如下表。
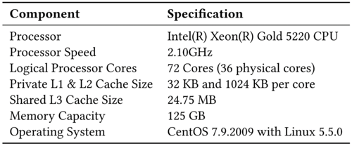

表2实验平台与数据集信息
自动性能调优的优势。默认的VDMS配置有相当大的改进空间,VDTuner可以显着提高性能。表3是不同数据集下VDTuner相较于默认配置带来的性能提升(两个目标的性能提升被定义为:相对于默认性能在不牺牲召回率(或搜索速度)的情况下,搜索速度(或召回率)的最大提升)。

表3自动调优算法在不同数据集的性能提升对比
调优效率。图7显示VDTuner 在两个目标之间取得了平衡,在 VDMS 性能方面超越了基线(高达 59.54%)。图8显示与竞争的基线相比,VDTuner 识别更好的配置的速度明显更快(速度提高了 3.57 倍)。下图是不同策略实现的最终性能、不同策略随迭代次数找到的最优配置性能。
图7 VDTuner在不同召回率下相对基线保持最优的搜索速度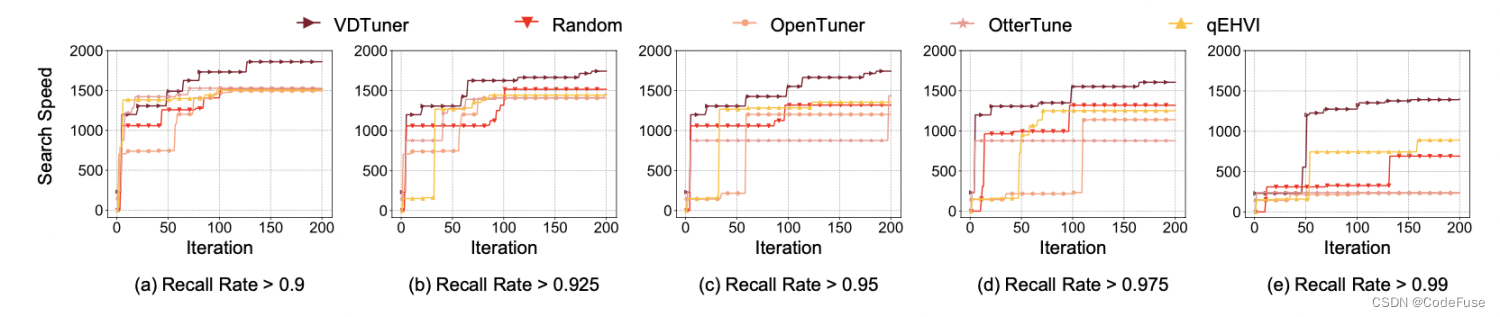
图8 VDTuner与基线对比识别最优配置需要更少的样本
预算分配的有效性。VDTuner的逐次放弃策略带来了不同召回率牺牲下的搜索速度提升(高达34%)。图9是VDTuner对不同索引类型的动态评分、VDTuner预算分配策略的消融性能对比。
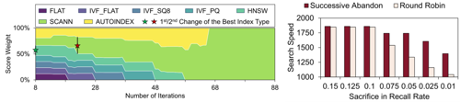
图9 不同索引类型评分以及不同预算分配算法对性能的影响
代理模型的有效性。VDTuner 的轮询代理在不同的召回率牺牲下带来了明显更好的搜索速度(高达 26%)。图10是两种代理模型的采样配置集合、两种代理模型的最终性能。
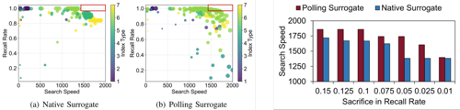
图10 不同代理模型采样配置以及最终性能对比
可扩展性。(1)更大的数据集:对于 10 倍更大的数据集,VDTuner 实现了搜索速度 159% 的性能提升,在达到相同性能水平的情况下,调优速度提高了 8.1 倍。(2)处理用户偏好(我们的设计分别节省了 25% 和 34% 的成本。图11是VDTuner的用户偏好设计带来的相对性能提升。
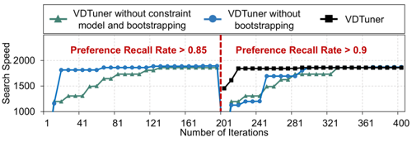
图11 VDTUner灵活处理在不同召回率下的用户偏好
时间开销。VDTuner 的开销仅占总调谐时间的一小部分(1.44%),考虑到 VDTuner 的卓越性能,这是可以接受的。表4是不同策略在一个数据集上的开销细分。
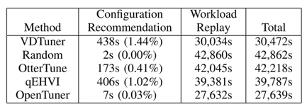
表4不同调优算法运行时间分解
5. 总结
在本文中,我们提出了 VDTuner,这是一种基于学习的性能调优框架,可优化向量数据库索引和系统配置。 VDTuner积极地在搜索速度和召回率之间取得平衡,并通过轮询结构、专门的代理模型和自动预算分配策略提供更好的性能。广泛的评估证明 VDTuner 是有效的,在调整效率方面显著优于基准,并且可针对不断变化的用户偏好和成本意识目标进行扩展。未来,我们希望将 VDTuner 扩展到在线版本,以主动捕获不同的工作负载。此外,我们还希望对其进行扩展以优化向量数据库的更多级别(例如数据分区),以进一步提高性能和资源利用率。同时,我们将探索VDTuner在不同向量数据库引擎以及CodeFuse更多相似检索(超长上下文代码生成、代码问答、代码补全等)场景的落地效果。
6. 致谢
本文是蚂蚁集团与南开大学在CodeFuse推理部署领域的阶段性技术创新成果,后续将持续深挖推理优化空间。想了解更多蚂蚁代码大模型,欢迎查看:蚂蚁代码大模型推理部署探索与实践
ModelCache 开源地址:
https://github.com/codefuse-ai/CodeFuse-ModelCache
Reference
VDTuner的预印版本:http://arxiv.org/abs/2404.10413,论文所参考到的文献信息如下:
- OpenAI, “Gpt-4 technical report,” 2023.
- W.X.Zhao,K.Zhou,J.Li,T.Tang,X.Wang,Y.Hou,Y.Min,B.Zhang, J. Zhang, Z. Dong et al., “A survey of large language models,” arXiv preprint arXiv:2303.18223, 2023.
- L. Huang, W. Yu, W. Ma, W. Zhong, Z. Feng, H. Wang, Q. Chen, W. Peng, X. Feng, B. Qin et al., “A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions,” arXiv preprint arXiv:2311.05232, 2023.
- J. Cui, Z. Li, Y. Yan, B. Chen, and L. Yuan, “Chatlaw: Open-source legal large language model with integrated external knowledge bases,” arXiv preprint arXiv:2306.16092, 2023.
- Y. Han, C. Liu, and P. Wang, “A comprehensive survey on vector database: Storage and retrieval technique, challenge,” arXiv preprint arXiv:2310.11703, 2023.
- Y. Bang, S. Cahyawijaya, N. Lee, W. Dai, D. Su, B. Wilie, H. Lovenia, Z. Ji, T. Yu, W. Chung et al., “A multitask, multilingual, multimodal evaluation of chatgpt on reasoning, hallucination, and interactivity,” arXiv preprint arXiv:2302.04023, 2023.
- J. Wang, X. Yi, R. Guo, H. Jin, P. Xu, S. Li, X. Wang, X. Guo, C. Li, X. Xu et al., “Milvus: A purpose-built vector data management system,” in Proceedings of the 2021 International Conference on Management of Data, 2021, pp. 2614–2627.
- R. Guo, X. Luan, L. Xiang, X. Yan, X. Yi, J. Luo, Q. Cheng, W. Xu, J. Luo, F. Liu et al., “Manu: a cloud native vector database management system,” Proceedings of the VLDB Endowment, vol. 15, no. 12, pp. 3548–3561, 2022.
- “Qdrant: Powering the next generation of ai applications with advanced and high-performant vector similarity search technology,” 2023. [Online]. Available: https://qdrant.tech/
- “Chroma: the ai-native open-source embedding database,” 2023. [Online]. Available: https://www.trychroma.com/
- D. Van Aken, A. Pavlo, G. J. Gordon, and B. Zhang, “Automatic database management system tuning through large-scale machine learn- ing,” in Proceedings of the 2017 ACM International Conference on Management of Data, 2017, pp. 1009–1024.
- J. Zhang, Y. Liu, K. Zhou, G. Li, Z. Xiao, B. Cheng, J. Xing, Y. Wang, T. Cheng, L. Liu et al., “An end-to-end automatic cloud database tuning system using deep reinforcement learning,” in Proceedings of the 2019 International Conference on Management of Data, 2019, pp. 415–432.
- I. Trummer, “Db-bert: a database tuning tool that” reads the manual”,” in Proceedings of the 2022 International Conference on Management of Data, 2022, pp. 190–203.
- X. Zhang, Z. Chang, H. Wu, Y. Li, J. Chen, J. Tan, F. Li, and B. Cui, “A unified and efficient coordinating framework for autonomous dbms tuning,” Proceedings of the ACM on Management of Data, vol. 1, no. 2, pp. 1–26, 2023.
- “Pgtune,” 2023. [Online]. Available: https://pgtune.leopard.in.ua/
- G. Li, X. Zhou, S. Li, and B. Gao, “Qtune: A query-aware database tuning system with deep reinforcement learning,” Proceedings of the VLDB Endowment, vol. 12, no. 12, pp. 2118–2130, 2019.
- S. Cereda, S. Valladares, P. Cremonesi, and S. Doni, “Cgptuner: a contextual gaussian process bandit approach for the automatic tuning of it configurations under varying workload conditions,” Proceedings of the VLDB Endowment, vol. 14, no. 8, pp. 1401–1413, 2021.
- C. Zhao, T. Chugh, J. Min, M. Liu, and A. Krishnamurthy, “Dremel: Adaptive configuration tuning of rocksdb kv-store,” Proceedings of the ACM on Measurement and Analysis of Computing Systems, vol. 6, no. 2, pp. 1–30, 2022.
- X. Zhao, X. Zhou, and G. Li, “Automatic database knob tuning: A survey,” IEEE Transactions on Knowledge and Data Engineering, 2023.
- J. Ansel, S. Kamil, K. Veeramachaneni, J. Ragan-Kelley, J. Bosboom, U.-M. O’Reilly, and S. Amarasinghe, “Opentuner: An extensible frame- work for program autotuning,” in Proceedings of the 23rd International Conference on Parallel Architectures and Compilation, 2014, pp. 303– 316.
- Y. Zhu, J. Liu, M. Guo, Y. Bao, W. Ma, Z. Liu, K. Song, and Y. Yang, “Bestconfig: tapping the performance potential of systems via automatic configuration tuning,” in Proceedings of the 2017 Symposium on Cloud Computing, 2017, pp. 338–350.
- X. Zhang, H. Wu, Z. Chang, S. Jin, J. Tan, F. Li, T. Zhang, and B. Cui, “Restune: Resource oriented tuning boosted by meta-learning for cloud databases,” in Proceedings of the 2021 International Conference on Management of Data, 2021, pp. 2102–2114.
- K. Yang, M. Emmerich, A. Deutz, and T. Ba ̈ck, “Multi-objective bayesian global optimization using expected hypervolume improvement gradient,” Swarm and Evolutionary Computation, vol. 44, pp. 945–956, 2019.
- S.Daulton,M.Balandat,andE.Bakshy,“Differentiableexpectedhyper- volume improvement for parallel multi-objective bayesian optimization,” Advances in Neural Information Processing Systems, vol. 33, pp. 9851– 9864, 2020.
- “Milvus,”2023.[Online].Available:https://github.com/milvus-io/milvus
- W. Li, Y. Zhang, Y. Sun, W. Wang, M. Li, W. Zhang, and X. Lin, “Approximate nearest neighbor search on high dimensional data—experiments, analyses, and improvement,” IEEE Transactions on Knowledge and Data Engineering, vol. 32, no. 8, pp. 1475–1488, 2019.
- V. Dalibard, M. Schaarschmidt, and E. Yoneki, “Boat: Building auto- tuners with structured bayesian optimization,” in Proceedings of the 26th International Conference on World Wide Web, 2017, pp. 479–488.
- J. Wang, I. Trummer, and D. Basu, “Udo: universal database op- timization using reinforcement learning,” Proceedings of the VLDB Endowment, vol. 14, no. 13, pp. 3402–3414, 2021.
- J.-K.Ge,Y.-F.Chai,andY.-P.Chai,“Watuning:aworkload-awaretuning system with attention-based deep reinforcement learning,” Journal of Computer Science and Technology, vol. 36, no. 4, pp. 741–761, 2021.
- R. Garnett, Bayesian optimization. Cambridge University Press, 2023. [31] B. Shahriari, K. Swersky, Z. Wang, R. P. Adams, and N. De Freitas, “Taking the human out of the loop: A review of bayesian optimization,” Proceedings of the IEEE, vol. 104, no. 1, pp. 148–175, 2015.
- “Vector-db-benchmark: Framework for benchmarking vector search engines,” 2023. [Online]. Available: https://github.com/qdrant/vector-db-benchmark
- J. Bergstra and Y. Bengio, “Random search for hyper-parameter optimization.” Journal of Machine Learning Research, vol. 13, no. 2, 2012. [34] W.-L. Loh, “On latin hypercube sampling,” The Annals of Statistics, vol. 24, no. 5, pp. 2058–2080, 1996.
- D. Van Aken, D. Yang, S. Brillard, A. Fiorino, B. Zhang, C. Bilien, and A. Pavlo, “An inquiry into machine learning-based automatic con- figuration tuning services on real-world database management systems,” Proceedings of the VLDB Endowment, vol. 14, no. 7, pp. 1241–1253, 2021.
- X.Zhang,Z.Chang,Y.Li,H.Wu,J.Tan,F.Li,andB.Cui,“Facilitating database tuning with hyper-parameter optimization: a comprehensive experimental evaluation,” Proceedings of the VLDB Endowment, vol. 15, no. 9, pp. 1808–1821, 2022.
- S. M. Lundberg and S.-I. Lee, “A unified approach to interpreting model predictions,” Advances in Neural Information Processing Systems, vol. 30, 2017.
- J.Johnson,M.Douze,andH.Je ́gou,“Billion-scalesimilaritysearch with gpus,” IEEE Transactions on Big Data, vol. 7, no. 3, pp. 535–547, 2019.
- Y. A. Malkov and D. A. Yashunin, “Efficient and robust approxi- mate nearest neighbor search using hierarchical navigable small world graphs,” IEEE Transactions on Pattern Analysis and Machine Iintelli- gence, vol. 42, no. 4, pp. 824–836, 2018.
- “Annoy: Approximate nearest neighbors oh yeah,” 2023. [Online]. Available: https://github.com/spotify/annoy
- J. Xin, K. Hwang, and Z. Yu, “Locat: Low-overhead online configuration auto-tuning of spark sql applications,” in Proceedings of the 2022 International Conference on Management of Data, 2022, pp. 674–684.
- C. Lin, J. Zhuang, J. Feng, H. Li, X. Zhou, and G. Li, “Adaptive code learning for spark configuration tuning,” in 2022 IEEE 38th International Conference on Data Engineering (ICDE). IEEE, 2022, pp. 1995–2007.
- H.Herodotou,L.Odysseos,Y.Chen,andJ.Lu,“Automaticperformance tuning for distributed data stream processing systems,” in 2022 IEEE 38th International Conference on Data Engineering (ICDE). 2022, pp. 3194–3197.