motivation :现有方法方法无法准确定位身体部位,不同的身体部位可以出现在同一个条纹(如手臂和躯干),一个部分可以出现在不同帧(如手)的不同条纹上。其次,不同的身体部位具有不同的尺度,即使是不同帧中的同一部分也可以出现在不同的位置和尺度上。第三,不同的部分也表现出不同的运动模式
核心思想:
意义作用与优势:可以作为作为 3D 步态识别主干的通用家族构建块,在实践中,现有 3D 主干 CNN 的任何构建块都可以被视为全局路径,并且所提出的局部路径可以很容易地插入到这些块中,而不会改变训练方案。此外,局部操作中每个组件的架构对于不同的配置非常灵活。
代码
https://github。com/Huangtownhz/3DLocalCNN
摘要
步态识别的目标是从人体形状的时间变化特征中学习独特的时空模式。由于不同的身体部位在行走过程中表现不同,因此分别对每个部分的时空模式进行建模是直观的。然而,现有的基于部分的方法将每一帧的特征图平均划分为固定的水平条纹stripes(HP操作),得到局部部分。很明显,这些基于条纹分区的方法无法准确定位身体部位。首先,不同的身体部位可以出现在同一个条纹(如手臂和躯干),一个部分可以出现在不同帧(如手)的不同条纹上。其次,不同的身体部位具有不同的尺度,即使是不同帧中的同一部分也可以出现在不同的位置和尺度上。第三,不同的部分也表现出不同的运动模式(例如,运动开始的帧、位置变化频率、持续时间)。为了克服这些问题,我们提出了一种新的 3D 局部操作作为 3D 步态识别主干的通用家族构建块。所提出的 3D 局部操作支持在具有自适应空间和时间尺度、位置和长度的序列中提取身体部位的局部 3D 体积。通过这种方式,身体部位的时空模式是从特定部分尺度、位置、频率和长度的 3D 局部邻域中很好地学习的。实验表明,我们的 3D 局部卷积神经网络在流行的步态数据集上实现了最先进的性能。、
1. Introduction
Gait是最重要和有效的生物特征模式之一,因为它可以在一定距离的距离上进行身份验证而无需受试者配合,步态识别在预防犯罪、法医鉴定和社会安全保险方面有着广泛的应用[2,14]。在现实世界的场景中,除了行走运动引起的体型变化外,携带袋、外衣和相机视点切换等变化也会导致身体外观的巨大变化,导致步态识别面临重大挑战。步态识别的基本目标是从人体形状的时间变化特征中学习独特且不变的表示。步态识别的早期工作集中于使用卷积神经网络(CNNs)提取全局特征[35,20,29,19]。GaitNet[41,40]提出了一种自动编码器框架,从原始RGB图像中提取步态相关特征,然后使用LSTMs对步态序列的时间变化进行建模。Thomas等人[33]直接应用3DCNN使用在自然图像分类任务上预训练的模型提取顺序信息。然而,全局特征没有考虑空间结构和局部细节,因此,在面对视点变化时没有足够的辨别力。一个自然的选择是学习与全局特征互补的详细的基于部分的局部特征,或者学习两者的特征嵌入。
由于人体由定义明确的部位组成,即头部、手臂、腿和躯干,因此基于部位的模型有可能解决步态识别中的变化。以前的基于零件的模型通过将特征映射均匀地划分为固定的水平条纹来提取零件特征。在GaitPart[7]中,首先对每个输入帧的输出CNN特征图进行预定义的水平分割,提取二维外观特征。然后,通过局部近程二维部分特征的时序拼接,聚合所有帧中同一条纹对应的特征;在GaitSet[3]和GLN[11]中,首先将最后一个二维卷积的帧级特征映射分割成均匀的条纹,然后沿集合维数对其进行max-pooling,提取集合级部分特征。在MT3D[18]中,使用多个时间尺度的3D cnn来探索序列中的时间关系。然后,将输出的特征映射也划分为多个条纹。然而,这些基于分割的步态识别方法忽略了两个问题。首先,人体的不同部位出现在不同的尺度上,甚至同一部位在不同的帧中出现在不同的位置和尺度上[3]。其次,不同的部分表现出不同的运动模式,例如,运动从哪一帧开始,位置变化的频率,以及持续的时间。因此,在步态周期中,视觉外观和时间运动变化是相互依赖的,并且人体不同自然部位的特征是彼此不同的。这表明步态识别模型应该支持对人体各个特定部位的自适应三维局部体积的提取和处理
为了克服上述步态识别问题,我们提出了一种新的 3D 局部操作作为 3D 步态识别主干的通用构建块家族。我们的 3D 局部操作支持在具有自适应空间和时间尺度、位置和长度的序列中提取局部 3D 体积。这样,不同身体部位的三维局部邻域在特定的部位尺度、位置和运动位置、频率、长度进行处理,如图1所示。二维局部操作已被证明在图像识别中是有效的[10,36],Local Convolutional Neural Networks for Person Re-Identification其中利用可微二维注意机制生成平滑变化位置和尺度的二维图像/特征块。然而,由于时间注视[21]的机制不同,将这一思想应用于3D局部操作是非常具有挑战性的。原因有两个。1)像素的空间采样遵循人眼的焦点,而帧的时间采样在光流分布。2)空间采样处理二维patch,时间采样处理一维序列,时空采样处理3D视频卷积。因此,需要一种新的 2D 和 1D 联合采样策略。
我们的本地操作由四个模块组成:定位、采样、特征提取和融合。
定位模块旨在学习六个身体部位(头部、躯干、左臂、右臂、左腿和右腿)的自适应空间和时间尺度、位置和时间长度。
采样模块对平滑变化的位置、尺度和时间长度的局部体积进行采样。
特征提取模块由几个卷积和 ReLU [22] 层组成,就像在一般卷积块中一样。
融合模块形成全局和局部输出的连接层,然后是1×1卷积层。
在实践中,现有 3D 主干 CNN 的任何构建块都可以被视为全局路径,并且所提出的局部路径可以很容易地插入到这些块中,而不会改变训练方案。此外,局部操作中每个组件的架构对于不同的配置非常灵活。
这项工作的主要贡献总结如下:
• 与 C3D [30]、P3D [24] 和非本地网络 [31] 相比,我们为主干 3D CNN 设计了一个新的构建块,它结合了特定于部分的顺序信息,称为 3D 局部卷积神经网络。
• 我们实现了一种简单而有效的 3D 局部 CNN 形式用于步态识别。该模型在CASIA-B和OU-MVLP两个最流行的数据集CASIA-B和OU-MVLP上优于最先进的步态识别方法。
•据我们所知,我们是第一个提出一个框架,该框架能够在3D cnn的任何层中交互/增强全局和局部3D体积信息。
2. Related Works
Local-based模型
基于部分的模型已在许多视觉任务中得到利用。在细粒度图像分类中,许多作品 [37, 26, 5, 42, 8, 32] 自动定位信息区域以捕获微妙的判别细节,使从属类彼此不同。Sun等人[26]利用多通道注意来学习几个相关区域。Wang等人[32]使用一组卷积滤波器来捕获特征图中的判别区域。Zheng等人[42]提出了三线性注意采样网络,从不同细节学习特征。在Person Reid中,Li等人。[15]将第一卷积层的输出特征映射水平平均划分为m个局部区域,并分别学习局部/全局。程等人。 [6] 将低级特征图水平分为四个相等的部分,并在最后一个全连接层之前将它们与全局流连接。Yang等人[36]提出了一组操作来定位静态图像中人体的关键位置。所有这些以前的基于局部的模型都旨在提取静态图像中空间局部区域的模式。对于步态识别,很自然地将这种见解扩展到步态序列的时空维度,并在提取特定时间间隔内特定人体部位的时空运动模式。
骨干cnn。通常使用的主干 CNN [13, 30, 24, 31] 表明,从局部邻域中提取局部特征有助于提高视觉模型。如图1所示,C2D[13]和C3D[30]捕获局部邻域内的短程依赖关系。它们的局部邻域是一个固定的2D补丁(k × k)或3D体积(k × k × k)。P3D[24]在空间域上将3 × 3 × 3卷积分割成1×3×3卷积滤波器,在时域上分割3×1×1卷积。在非局部神经网络[31]中,其中整个输入可以看作是一个固定的全局邻域。我们的3D局部CNN针对不同的局部路径定位一个自适应的3D局部体积,而不是固定的局部邻域。
3. Method
三维局部卷积可以看作是神经网络中一般卷积运算的一种特殊形式。
考虑一个三维输入x∈R H×W ×T,对应输出y的卷积块,其三维局部卷积定义为:
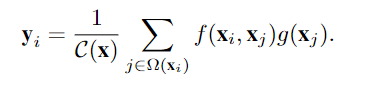
这个公式和non_local 神经网络类似 只是j 的取值范围不同
这里i是要计算响应的输出位置(在RH×W ×T中)的索引,j是x附近一个可能位置Ω(x)的索引。f 是计算xi和xj之间的相关系数。g计算输入信号在位置j的表示形式。响应通过因子C归一化。
神经网络中不同形式的卷积运算在于邻域Ω ( x )的定义。如图 1 所示,2D 卷积和 3D 卷积聚合来自固定局部邻域切片或体积的特征。在非局部神经网络中,邻域被定义为所有的特征图。与这些操作不同的是,3D 局部卷积将邻域定义为具有自适应空间和时间尺度、位置和时间长度的 3D 局部体积
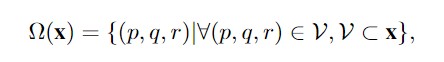
论文分享[cvpr2018]Non-local Neural Networks非局部神经网络-CSDN博客其中V为特定局部部件的自适应3D局部体积。我们的3D局部卷积操作的基本目标是从给定的输入x中采样自适应3D体积V,并从这些体积中提取相应的局部特征。论文分享[cvpr2018]Non-local Neural Networks非局部神经网络-CSDN博客

3.2. 实例化
如图2展示了3D Local cnn中的构建块实例。
该块由一个全局路径(与其他3D骨干构建块一样)和几个局部路径组成。我们的局部操作有四个组成部分:定位模块(L)、采样模块(S)、特征提取模块(FE)和融合模块(FS)。定位模块根据全局特征生成对应局部部件的局部体的位置/尺度。然后,采样模块对给定位置/尺度的特定局部3D体进行采样。特征提取模块用于从采样的局部体中提取特征。特征融合模块用于合成生成的全局特征和局部特征
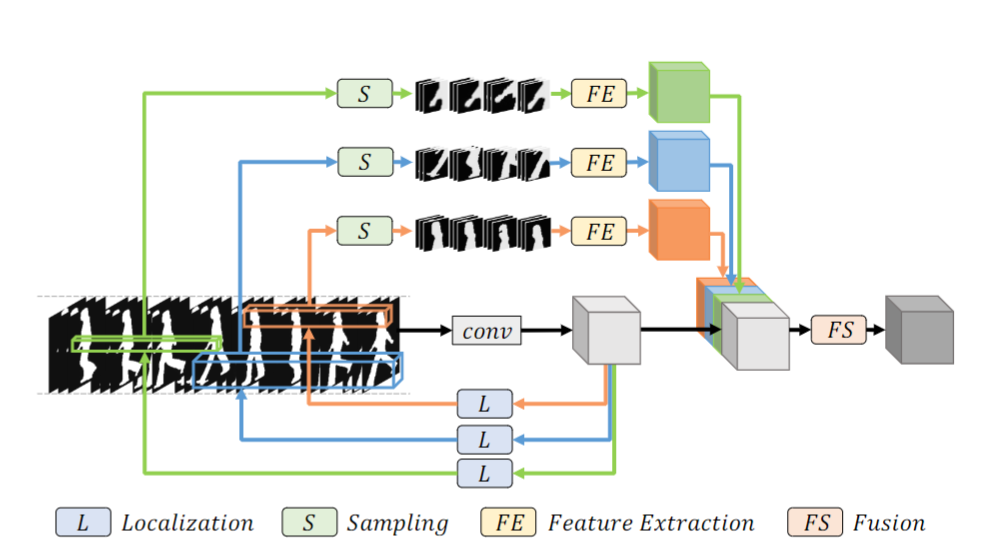
图 2.3D局部CNN的构建块。有四个组成部分:定位模块、采样模块、特征提取模块和融合模块。定位模块旨在定位每个身体部位的位置。采样模块被公式化为应用于输入的特定滤波器(高斯或三线性或混合)。特征提取模块由几个卷积层和ReLU层组成。融合模块由全局和局部输出的级联层形成,后跟1 × 1 × 1 卷积层。为简单起见,这里仅说明三个局部路径(头部、左手和右腿)
3.2.1定位
受可微分注意机制的启发,我们通过七个独立参数(∆x,∆y,∆t, δx, δy, δt, σ2, γ)来指定我们的定位模块。它们是为每一帧动态确定的。(∆x,∆y)为采样网格中心到每帧对应部分的预定义中心的实值高度和宽度偏移量,∆t为整个序列的帧偏移量。(δx, δy)为采样网格的实值空间步幅,δt为时间步幅。σ2为高斯滤波器的各向同性方差。δ和σ2的组合控制了局部的“变焦”。γ作为与滤波器响应相乘的置信度分数。理想情况下,γ表示聚焦部分的存在,即当面对遮挡时,它应该接近于0。给定H ×W ×T输出全局路径的特征映射,我们利用卷积块,ReLU,批处理归一化,最大池化和全连接层来推断以下参数:
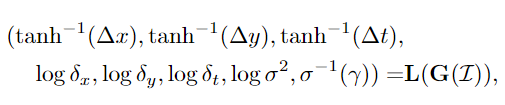
其中G为全局模块,I为输入模块,L为局部模块,σ(γ) = 11 +exp(−γ)。(∆x,∆y,∆t)归一化并缩放为(- 1,1),以确保网格中心在采样输入内。方差和步幅以对数尺度发出,以确保正性。置信度分数γ被缩放到(0,1)。我们的定位模块的架构在补充细节的表1中详细说明。在输入和每个卷积层后采用批处理归一化和ReLU非线性。值得注意的是,为了确保全局路径只关注表示,该模块的梯度不会传播到全局路径。
3.2.2采样
为了从给定的输入中采样局部三维体积,我们考虑一个明确的三维形式的注意力。一组3D滤波器应用于输入序列,产生一系列具有平滑变化位置和缩放的局部补丁。给定期望的局部输出大小M ×N ×L,根据网格中心的坐标和相邻滤波器之间的步距,对输入应用采样滤波器的M ×N ×L网格。步幅越大,注意体积中可见的输入区域越大,但注意体积的有效分辨率越低。各向同性方差越大,输出的体积越平滑,但局部体积的细节越不清晰。根据定位模块提供的归一化先验体中心位置(cx, cy, ct)、体中心偏移量(∆x,∆y,∆t)和步长(δx, δy, δt)(均为实值),得到体在第i行,第j列,第k帧处的网格位置(μX, μY, μT)为:
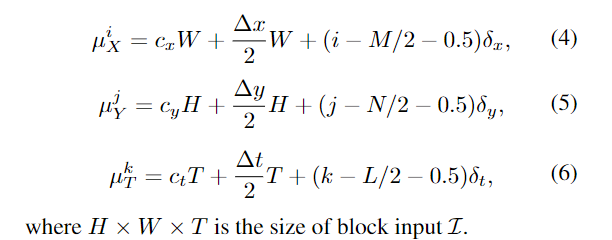
空间滤波。受[36,10,9]中模仿人眼注视焦点的可微分注意技术[10]的启发,我们采用高斯滤波器进行空间滤波。对于高斯滤波器,采样网格的坐标也是滤波器的平均位置。给定定位模块输出的各向同性方差σ2,水平和垂直滤波器组权重矩阵GX和gy(维度分别为M × W和N × H)定义如下:

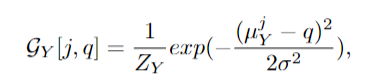
式中(i, j)为注意三维体中某点的空间索引,(p, q)为输入中某点的空间索引。ZX和ZY是保证∑p GX [i, p] = 1和∑k GY [j, k] = 1的归一化常数。
时间过滤。受cnn[12]和视频插值[21]中的可微运动层技术的启发,对体积进行时间采样的自然选择是三线插值。与高斯滤波器类似,这里我们将时间三线性插值函数表述为权重矩阵TT(维度L×T)。目标位置的插值值被计算为天花板和地板整数位置值的线性组合:
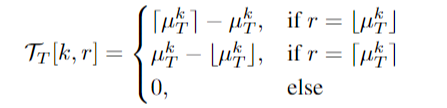
其中b·c是底函数,d·e是顶函数。k为注意三维体积中的帧索引,r为输入中的帧索引。最后,将整体混合采样操作表述为三个一维采样,其中结合了模拟人眼注视点的空间高斯滤波器[10]和假设连续帧之间的光流局部线性的时间线性滤波器。基于(GX, GY, TT)和定位模块提供的置信度分数γ,从输入I输出的3D局部体积V被采样为:
![]()
)有趣的是,我们将通过实验(表4)表明,我们的3D局部模型对采样滤波器的选择并不敏感。只有使用高斯滤波器或线性滤波器才能显示与上述组合滤波器相当的性能。这一结果表明,一般的局部行为是观察到的改进的主要原因。
3.2.3特征提取
如图2所示,特征提取模块用于提取局部路径的特征。所有类型的卷积块,如C3D[30], P3D[24]和MT3D[18],都是候选的。本文的特征提取模块目前的体现仅限于过滤器大小3×3×3的一个卷积层,然后是ReLU,并且这种设计更多地是基于方便而不是必要性。特征提取模块中更复杂的架构可能会带来更大的性能提升,但这不是本文的重点。该模块的输出特征映射的数量被设置为全局路径的一半。特征提取模块的输出和输入具有相同的高度、宽度和长度。3.2.4特征融合特征融合模块旨在通过综合给定的全局和局部输出来产生更鲁棒和有区别的表示。在本文中,特征融合模块形成了一个沿通道维度的全局和局部输出的拼接层,然后是一个带有ReLU的a1 × 1 × 1卷积层,基于局部和全局信息的综合对表示进行细化,并保证基数不变。像注意力这样更复杂的机制可能会带来更多的性能提升,但这不是本文的重点。将该模块的输出特征映射的数量设置为与全局路径相同
3.3.3D Local CNN for Gait Recognition
为了将我们的3D局部CNN块插入骨干CNN,我们需要基于先验知识定义以下设置:1)局部路径的数量,2)每条路径的采样网格中心的先验位置(cx, cy, ct),以及3)每条路径的局部采样输出的期望维数(M, N, L)。对于步态识别的特征学习,定义头部、左臂、右臂、躯干、左腿和右腿对应的6条局部路径是很自然的。(如图3所示)。根据[1]和常识,人体的头部、左臂、右臂、躯干、左腿、右腿的一般比例(身高、宽度、长度)(pH、pW、pL)汇总在附录的表3中
为了验证三维局部cnn的有效性,我们在骨干网络的每两层之后插入提出的局部操作。如[7,3,11]所示,骨干网由三个构建块组成。每个块由两个卷积层组成,然后是ReLU层。我们采用了来自GaitPart[7]的空间池化和时间池化,以及来自GLN[11]的紧凑块和线性模块。
实验结果
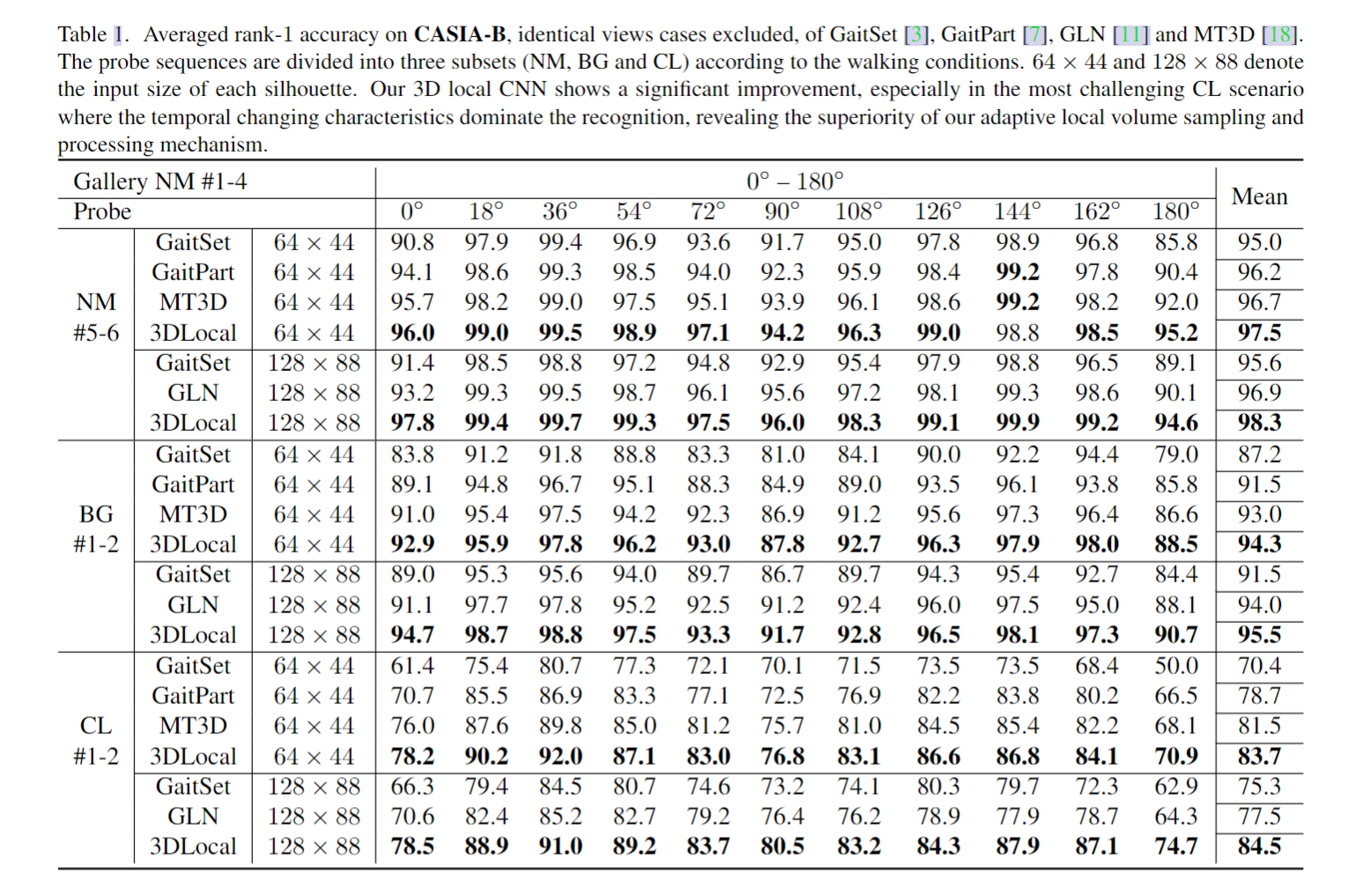
(ICCV-2021)用于步态识别的3D局部卷积神经网络(一)_3d卷积网络,用于ct分类-CSDN博客