在目前流行的互联网架构中,Tomcat在目前的网络编程中是举足轻重的,由于Tomcat的运行依赖于JVM,从虚拟机的角度把Tomcat的调整分为外部环境调优 JVM 和 Tomcat 自身调优两部分。
一、JVM组成
1. JVM 组成
JVM组成部分
-
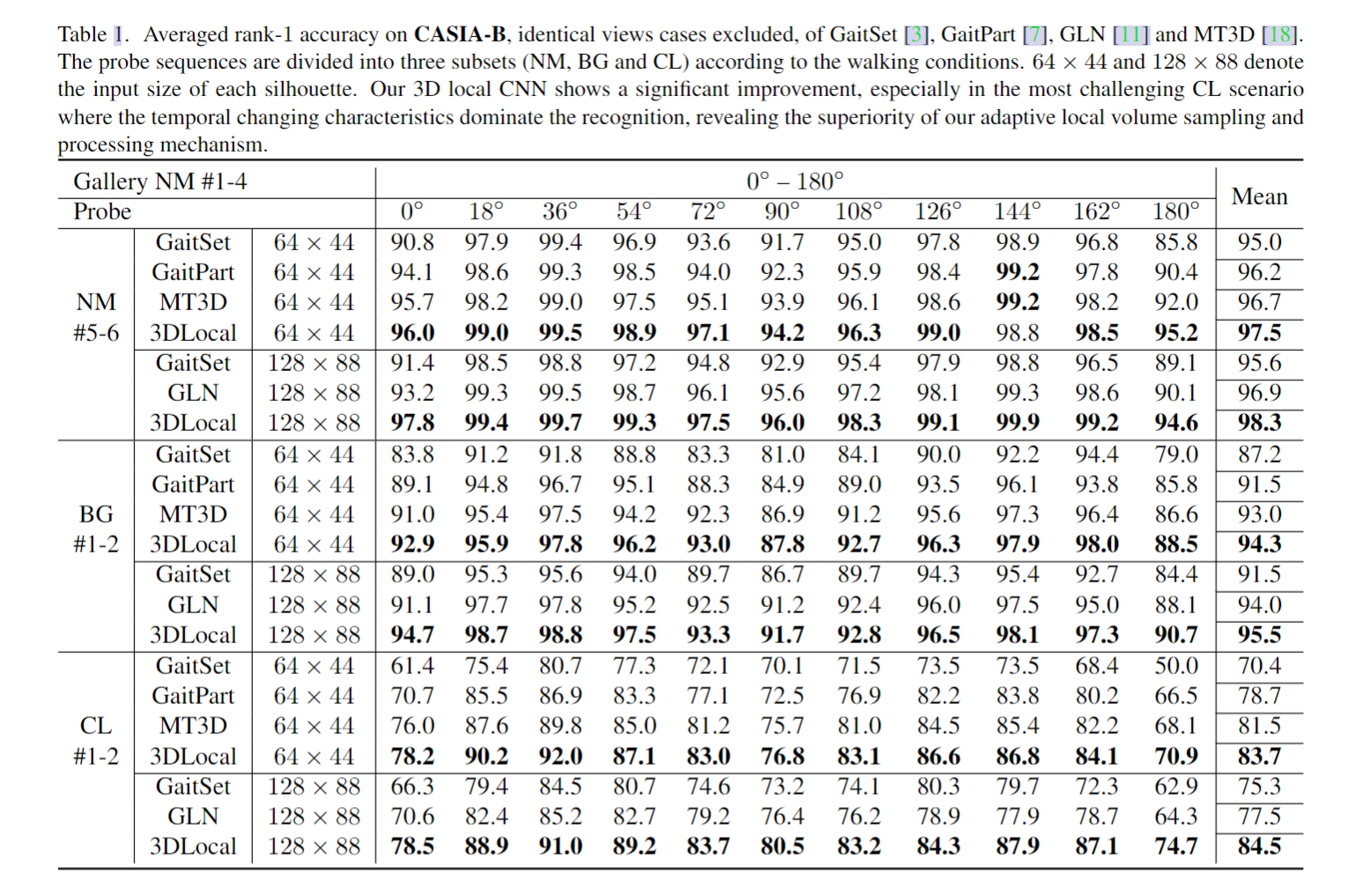
类加载子系统: 使用Java语言编写.java Source Code文件,通过javac编译成.class Byte Code文件。class loader类加载器将所需所有类加载到内存,必要时将类实例化成实例
-
运行时数据区: 最消耗内存的空间,需要优化
-
执行引擎: 包括JIT (JustInTimeCompiler)即时编译器, GC垃圾回收器
-
本地方法接口: 将本地方法栈通过JNI(Java Native Interface)调用Native Method Libraries, 比如:C,C++库等,扩展Java功能,融合不同的编程语言为Java所用
JVM运行时数据区域由下面部分构成:
-
Method Area (线程共享):方法区是所有线程共享的内存空间,存放已加载的类信息(构造方法,接口定义),常量(final),静态变量(static), 运行时常量池等。但实例变量存放在堆内存中. 从JDK8开始此空间由永久代改名为元空间
-
heap (线程共享):堆在虚拟机启动时创建,存放创建的所有对象信息。如果对象无法申请到可用内存将抛出OOM异常.堆是靠GC垃圾回收器管理的,通过-Xmx -Xms 指定最大堆和最小堆空间大小
-
Java stack (线程私有):Java栈是每个线程会分配一个栈,存放java中8大基本数据类型,对象引用,实例的本地变量,方法参数和返回值等,基于FILO()(First In Last Out),每个方法为一个栈帧 1 50 %
-
Program Counter Register (线程私有):PC寄存器就是一个指针,指向方法区中的方法字节码,每一个线程用于记录当前线程正在执行的字节码指令地址。由执行引擎读取下一条指令.因为线程需要切换,当一个线程被切换回来需要执行的时候,知道执行到哪里了
-
Native Method stack (线程私有):本地方法栈为本地方法执行构建的内存空间,存放本地方法执行时的局部变量、操作数等。
2. 虚拟机
目前Oracle官方使用的是HotSpot, 它最早由一家名为"Longview Technologies"公司设计,使用了很多优秀的设计理念和出色的性能,1997年该公司被SUN公司收购。后来随着JDK一起发布了HotSpot VM。目前HotSpot是最主要的 JVM。
安卓程序需要运行在JVM上,而安卓平台使用了Google自研的Java虚拟机——Dalvid,适合于内存、处理器能力有限系统。

在堆内存中如果创建的对象不再使用,仍占用着内存,此时即为垃圾.需要即使进行垃圾回收,从而释放内存空间给其它对象使用
其实不同的开发语言都有垃圾回收问题,C,C++需要程序员人为回收,造成开发难度大,容易出错等问题,但执行效率高,而JAVA和Python中不需要程序员进行人为的回收垃圾,而由JVM或相关程序自动回收垃圾,减轻程序员的开发难度,但可能会造成执行效率低下
堆内存里面经常创建、销毁对象,内存也是经常被使用、被释放。如果不妥善处理,一个使用频繁的进程,可能会出现虽然有足够的内存容量,但是无法分配出可用内存空间,因为没有连续成片的内存了,内存全是碎片化的空间。
所以需要有合适的垃圾回收机制,确保正常释放不再使用的内存空间,还需要保证内存空间尽可能的保持一定的连续
java 什么是垃圾 没有被使用的进程 线程
对于垃圾回收,需要解决三个问题
-
哪些是垃圾要回收 A计数法(计数为0 就是垃圾) B根搜索法(具体是谁在用 这个进程)
-
怎么回收垃圾
-
什么时候回收垃圾
3. Garbage 垃圾确定方法
-
引用计数: 每一个堆内对象上都与一个私有引用计数器,记录着被引用的次数,引用计数清零,该对象所占用堆内存就可以被回收。循环引用的对象都无法将引用计数归零,就无法清除。Python中即使用此种方式。 简单来说就是有个笔记本,记录有没有人在用,缺陷,AB 资源互相调用
-
根搜索(可达)算法 Root Searching
二、垃圾回收基本算法
1. 标记-清除 Mark-Sweep
分垃圾标记阶段和内存释放阶段。标记阶段,找到所有可访问对象打个标记。清理阶段,遍历整个堆,对未标记对象(即不再使用的对象)逐一进行清理。

标记-清除最大的问题会造成内存碎片,但是不浪费空间,效率较高(如果对象较多,逐一删除效率也会影响)
2. 标记压缩 (压实)Mark-Compact
分垃圾标记阶段和内存整理阶段。标记阶段,找到所有可访问对象打个标记。内存清理阶段时,整理时将对象向内存一端移动,整理后存活对象连续的集中在内存一端。

标记-压缩算法好处是整理后内存空间连续分配,有大段的连续内存可分配,没有内存碎片。缺点是内存整理过程有消耗,效率相对低下
3. 复制 Copying
先将可用内存分为大小相同两块区域A和B,每次只用其中一块,比如A。当A用完后,则将A中存活的对象复制到B。复制到B的时候连续的使用内存,最后将A一次性清除干净。缺点是比较浪费内存,只能使用原来一半内存,因为内存对半划分了,复制过程毕竟也是有代价。好处是没有碎片,复制过程中保证对象使用连续空间,且一次性清除所有垃圾,所以效率很高。
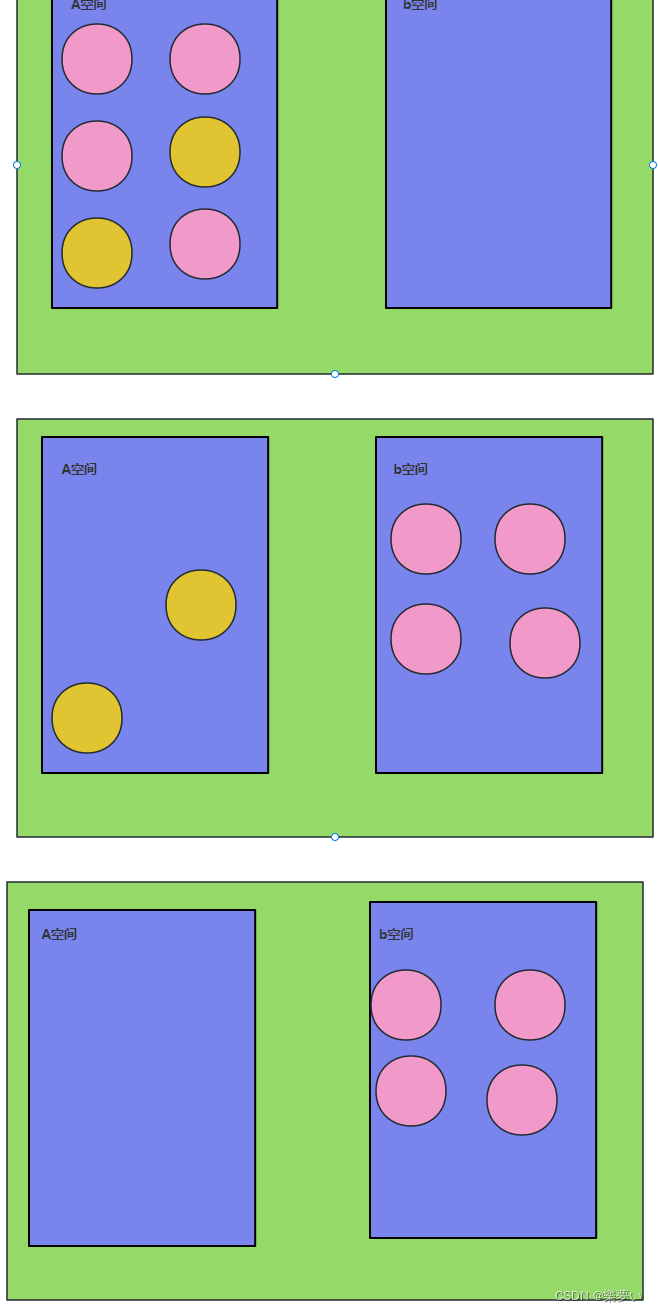
4. 多种算法总结
没有最好的算法,在不同场景选择最合适的算法
-
效率: 复制算法>标记清除算法> 标记压缩算法
-
内存整齐度: 复制算法=标记压缩算法> 标记清除算法
-
内存利用率: 标记压缩算法=标记清除算法>复制算法
5. STW
对于大多数垃圾回收算法而言,GC线程工作时,停止所有工作的线程,称为Stop The World。GC 完成时,恢复其他工作线程运行。这也是JVM运行中最头疼的问题。
三、分代堆内存GC策略
1. 堆内存分代
上述垃圾回收算法都有优缺点,能不能对不同数据进行区分管理,不同分区对数据实施不同回收策略,分而治之
将heap内存空间分为三个不同类别: 年轻代、老年代、持久代


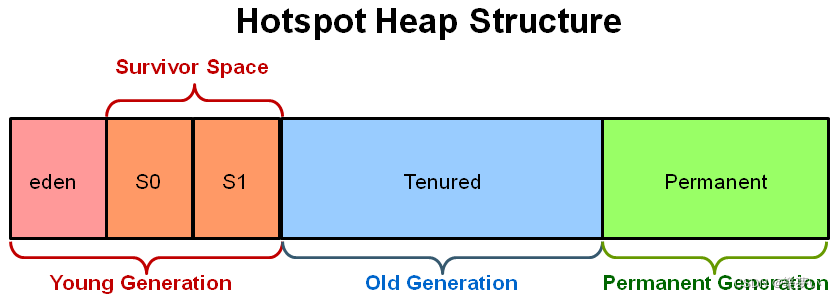
Heap堆内存分为
- 年轻代Young:Young Generation
伊甸园区eden: 只有一个,刚刚创建的对象
幸存(存活)区Servivor Space:有2个幸存区,一个是from区,一个是to区。大小相等、地位相同、可互换。from 指的是本次复制数据的源区
to 指的是本次复制数据的目标区- 老年代Tenured:Old Generation, 长时间存活的对象
默认空间大小比例:

2. 年轻代回收Minor GC
-
起始时,所有新建对象(特大对象直接进入老年代)都出生在eden,当eden满了,启动**GC。这个称为Young GC 或者 Minor GC。
-
先标记eden存活对象,然后将存活对象复制到s0(假设本次是s0,也可以是s1,它们可以调换),eden剩余所有空间都清空。GC完成。
-
继续新建对象,当eden再次满了,启动GC。
-
先同时标记eden和s0中存活对象,然后将存活对象复制到s1。将eden和s0清空,此次GC完成
-
继续新建对象,当eden满了,启动GC。
-
先标记eden和s1中存活对象,然后将存活对象复制到s0。将eden和s1清空,此次GC完成以后就重复上面的步骤。
通常场景下,大多数对象都不会存活很久,而且创建活动非常多,新生代就需要频繁垃圾回收。但是,如果一个对象一直存活,它最后就在from、to来回复制,如果from区中对象复制次数达到阈值(默认15次,CMS为6次,可通过java的选项 -XX:MaxTenuringThreshold=N 指定),就直接复制到老年
代。
3. 老年代回收 Major GC
进入老年代的数据较少,所以老年代区被占满的速度较慢,所以垃圾回收也不频繁。如果老年代也满了,会触发老年代GC,称为Old GC或者 Major GC。
由于老年代对象一般来说存活次数较长,所以较常采用标记-压缩算法。
当老年代满时,会触发 Full GC,即对所有"代"的内存进行垃圾回收
Minor GC比较频繁,Major GC较少。但一般Major GC时,由于老年代对象也可以引用新生代对象,所以先进行一次Minor GC,然后在Major GC会提高效率。可以认为回收老年代的时候完成了一次Full GC。所以可以认为 MajorGC = FullGC
四、java 内存调整相关参数
1. JVM 内存常用相关参数
Java 命令行参考文档: https://docs.oracle.com/javase/8/docs/technotes/tools/unix/java.html

选项分类
-
-选项名称 此为标准选项,所有HotSpot都支持
-
-X选项名称 为稳定的非标准选项
-
-XX:选项名称 非标准的不稳定选项,下一个版本可能会取消
| 参数 | 说明 | 举例 |
|---|---|---|
| -Xms | 设置应用程序初始使用的堆内存大小(年轻代+老年代) | -Xms2g |
| -Xmx | 设置应用程序能获得的最大堆内存早期JVM不建议超过32G,内存管理效率下降 | -Xms4g |
| -XX:NewSize | 设置初始新生代大小 | -XX:NewSize=128m |
| -XX:MaxNewSize | 设置最大新生代内存空间 | -XX:MaxNewSize=256m |
| -Xmnsize | 同时设置-XX:NewSize 和 -XX:MaxNewSize,代 | -Xmn1g |
| -XX:NewRatio | 以比例方式设置新生代和老年代 | -XX:NewRatio=2new/old=1/2 |
| -XX:SurvivorRatio | 以比例方式设置eden和survivor(S0或S1) | -XX:SurvivorRatio=6eden/survivor=6/1new/survivor=8/1 |
| -Xss | 设置每个线程私有的栈空间大小,依据具体线程 | -Xss256k |
标准选项:
[root@localhost ~]#java
用法: java [-options] class [args...](执行类)或 java [-options] -jar jarfile [args...](执行 jar 文件)
其中选项包括:-d32 使用 32 位数据模型 (如果可用)-d64 使用 64 位数据模型 (如果可用)-server 选择 "server" VM默认 VM 是 server,因为您是在服务器类计算机上运行。-cp <目录和 zip/jar 文件的类搜索路径>-classpath <目录和 zip/jar 文件的类搜索路径>用 : 分隔的目录, JAR 档案和 ZIP 档案列表, 用于搜索类文件。-D<名称>=<值>设置系统属性-verbose:[class|gc|jni]启用详细输出-version 输出产品版本并退出-version:<值>警告: 此功能已过时, 将在未来发行版中删除。需要指定的版本才能运行-showversion 输出产品版本并继续-jre-restrict-search | -no-jre-restrict-search警告: 此功能已过时, 将在未来发行版中删除。在版本搜索中包括/排除用户专用 JRE-? -help 输出此帮助消息-X 输出非标准选项的帮助-ea[:<packagename>...|:<classname>]-enableassertions[:<packagename>...|:<classname>]按指定的粒度启用断言-da[:<packagename>...|:<classname>]-disableassertions[:<packagename>...|:<classname>]禁用具有指定粒度的断言-esa | -enablesystemassertions启用系统断言-dsa | -disablesystemassertions禁用系统断言-agentlib:<libname>[=<选项>]加载本机代理库 <libname>, 例如 -agentlib:hprof另请参阅 -agentlib:jdwp=help 和 -agentlib:hprof=help-agentpath:<pathname>[=<选项>]按完整路径名加载本机代理库-javaagent:<jarpath>[=<选项>]加载 Java 编程语言代理, 请参阅 java.lang.instrument-splash:<imagepath>使用指定的图像显示启动屏幕
有关详细信息, 请参阅 http://www.oracle.com/technetwork/java/javase/documentation/index.html。
非标准的稳定选项:
[root@localhost ~]#java -X-Xmixed 混合模式执行 (默认)-Xint 仅解释模式执行-Xbootclasspath:<用 : 分隔的目录和 zip/jar 文件>设置搜索路径以引导类和资源-Xbootclasspath/a:<用 : 分隔的目录和 zip/jar 文件>附加在引导类路径末尾-Xbootclasspath/p:<用 : 分隔的目录和 zip/jar 文件>置于引导类路径之前-Xdiag 显示附加诊断消息-Xnoclassgc 禁用类垃圾收集-Xincgc 启用增量垃圾收集-Xloggc:<file> 将 GC 状态记录在文件中 (带时间戳)-Xbatch 禁用后台编译-Xms<size> 设置初始 Java 堆大小-Xmx<size> 设置最大 Java 堆大小-Xss<size> 设置 Java 线程堆栈大小-Xprof 输出 cpu 配置文件数据-Xfuture 启用最严格的检查, 预期将来的默认值-Xrs 减少 Java/VM 对操作系统信号的使用 (请参阅文档)-Xcheck:jni 对 JNI 函数执行其他检查-Xshare:off 不尝试使用共享类数据-Xshare:auto 在可能的情况下使用共享类数据 (默认)-Xshare:on 要求使用共享类数据, 否则将失败。-XshowSettings 显示所有设置并继续-XshowSettings:all显示所有设置并继续-XshowSettings:vm 显示所有与 vm 相关的设置并继续-XshowSettings:properties显示所有属性设置并继续-XshowSettings:locale显示所有与区域设置相关的设置并继续-X 选项是非标准选项, 如有更改, 恕不另行通知。
有不稳定选项的当前生效值
[root@centos7 ~]#java -XX:+PrintFlagsFinal查看所有不稳定选项的默认值
[root@centos7 ~]#java -XX:+PrintFlagsInitial实例:指定内存空间
#指定内存空间
[root@centos8 ~]#java -Xms1024m -Xmx1024m -XX:+PrintGCDetails -cp . Heap范例: 查看OOM
java -cp . HeapOom22. JDK工具监控使用情况
2.1 jvisualvm
[root@localhost mnt]#vim Helloworld.java
public class Helloworld extends Thread {
public static void main(String[] args) {
try {
while (true) {
Thread.sleep(2000);
System.out.println("hello zjl");
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}[root@localhost mnt]#javac Helloworld.java #将Linux的图形工具显示到windows桌面
#方法1
#注意:先在windows上开启Xwindows Server,如Xmanager
[root@tomcat ~]#export DISPLAY=192.168.91.1:0.0
#方法2:使用 MobaXterm 连接
[root@tomcat ~]#yum -y install xorg-x11-xauth xorg-x11-fonts-* xorg-x11-font-utils xorg-x11-fonts-Type1
[root@tomcat ~]#exit
#运行图形工具
[roottomcat ~]#which jvisualvm
/usr/local/jdk/bin/jvisualvm
[root@tomcat ~]#jvisualvmjava -cp . -Xms5m -Xmx10m -XX:+HeapDumpOnOutOfMemoryError HeapOom3. Tomcat 配置文件参数优化
常用的优化相关参数如下:
【redirectPort】如果某连接器支持的协议是HTTP,当接收客户端发来的HTTPS 443 请求时,则转发至此属性定义的 8443 端口。【maxThreads】Tomcat使用线程来处理接收的每个请求,这个值表示Tomcat可创建的最大的线程数,即支持的最大并发连接数,默认值是 200。【minSpareThreads】最小空闲线程数,Tomcat 启动时的初始化的线程数,表示即使没有人使用也开这么多空线程等待,默认值是 10。【maxSpareThreads】最大备用线程数,一旦创建的线程超过这个值,Tomcat就会关闭不再需要的socket线程。默认值是-1(无限制)。一般不需要指定。【processorCache】进程缓冲器,可以提升并发请求。默认值是200,如果不做限制的话可以设置为-1,一般采用maxThreads的值或者-1。【URIEncoding】指定 Tomcat 容器的 URL 编码格式,网站一般采用UTF-8作为默认编码。【connnectionTimeout】网络连接超时,单位:毫秒,设置为 0 表示永不超时,这样设置有隐患的。通常默认 20000 毫秒就可以。【enableLookups】是否反查域名,以返回远程主机的主机名,取值为:true 或 false,如果设置为 false,则直接返回 IP 地址,为了提高处理能力,应设置为 false。【disableUploadTimeout】上传时是否使用超时机制。应设置为 true。【connectionUploadTimeout】上传超时时间,毕竟文件上传可能需要消耗更多的时间,这个根据你自己的业务需要自己调,以使Servlet有较长的时间来完成它的执行,需要与上一个参数一起配合使用才会生效。【acceptCount】指定当所有可以使用的处理请求的线程数都被使用时,可传入连接请求的最大队列长度,超过这个数的请求将不予处理,默认为 100 个。【maxKeepAliveRequests】指定一个长连接的最大请求数。默认长连接是打开的,设置为1时,代表关闭长连接;为-1时,代表请求数无限制【compression】是否对响应的数据进行GZIP压缩,off:表示禁止压缩;on:表示允许压缩(文本将被压缩)、force:表示所有情况下都进行压缩,默认值为 off,压缩数据后可以有效的减少页面的大小,一般可以减小 1/3 左右,节省带宽。【compressionMinSize】表示压缩响应的最小值,只有当响应报文大小大于这个值的时候才会对报文进行压缩,如果开启了压缩功能,默认值就是 2048。【compressableMimeType】压缩类型,指定对哪些类型的文件进行数据压缩。【noCompressionUserAgents="gozilla, traviata"】对于以下的浏览器,不启用压缩
#如果已经进行了动静分离处理,静态页面和图片等数据就不需做 Tomcat 处理,也就不要在 Tomcat 中配置压缩了。
![[C++]哈希应用-布隆过滤器快速入门](https://img-blog.csdnimg.cn/direct/5368f3ff867f40d19a4766f05b5c287e.png#pic_center)