目录
嵌套循环算法(NLJ)
简单嵌套循环(SNLJ)
索引嵌套循环(INLJ)
块嵌套循环(BNLJ)
三种算法比较
哈希连接算法(Hash Join)
注意事项:
工作原理:
优点:
缺点:
排序合并链接(SORT MERGE JOIN)
工作流程:
优点:
缺点:
总结
我们都知道SQL的join关联表的使用方式,但是这次聊的是实现join的算法,join有三种算法,分别是Nested Loop Join,Hash join,Sort Merge Join。
嵌套循环算法(NLJ)
嵌套循环算法(Nested-Loop Join,NLJ)是通过两层循环,用第一张表做Outter Loop,第二张表做Inner Loop,Outter Loop的每一条记录跟Inner Loop的记录作比较,符合条件的就输出。而NLJ又有3种细分的算法:嵌套循环算法又可以分为简单嵌套循环、索引嵌套循环、块嵌套循环。
简单嵌套循环(SNLJ)
// 伪代码for (r in R) {for (s in S) {if (r satisfy condition s) {output <r, s>;}}}
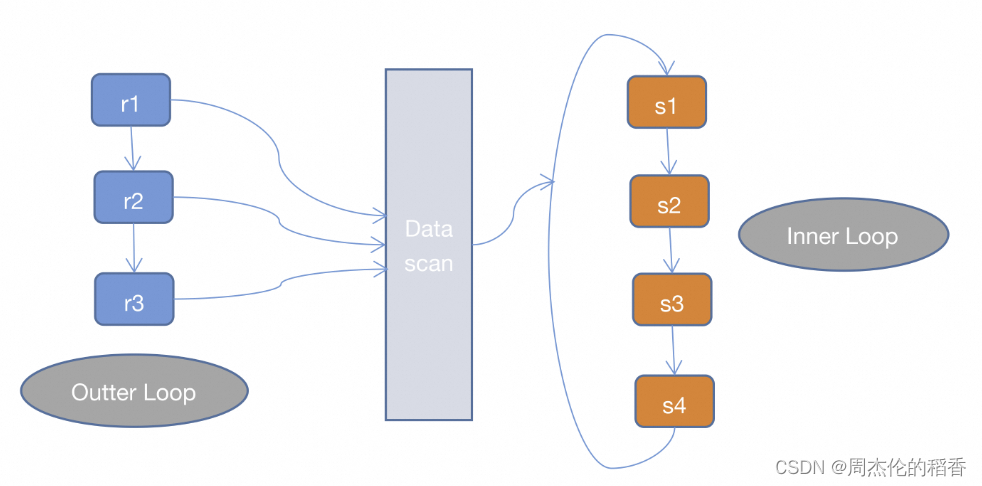
SNLJ就是两层循环全量扫描连接的两张表,得到符合条件的两条记录则输出,这也就是让两张表做笛卡尔积,比较次数是R * S,是比较暴力的算法,会比较耗时。
索引嵌套循环(INLJ)
// 伪代码for (r in R) {for (si in SIndex) {if (r satisfy condition si) {output <r, s>;}}}
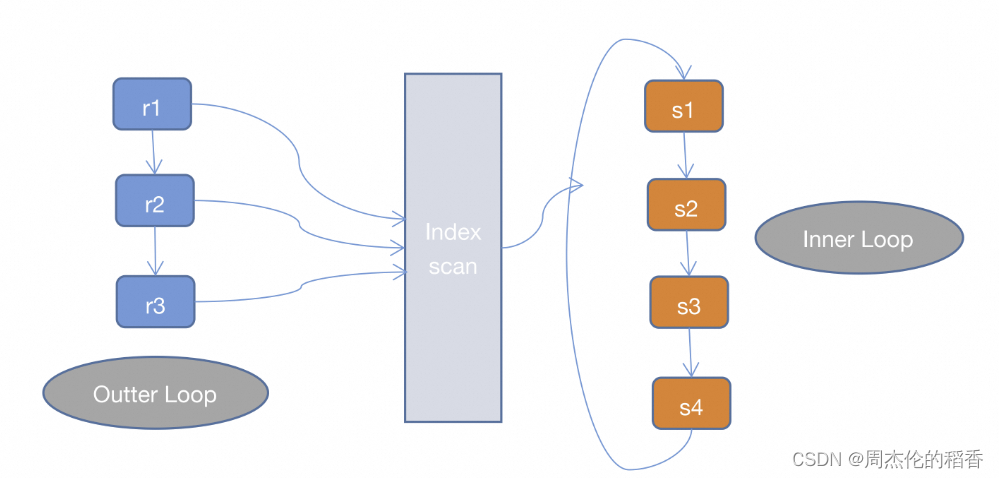
INLJ是在SNLJ的基础上做了优化,通过连接条件确定可用的索引,在Inner Loop中扫描索引而不去扫描数据本身,从而提高Inner Loop的效率。
而INLJ也有缺点,就是如果扫描的索引是非聚簇索引,并且需要访问非索引的数据,会产生一个回表读取数据的操作,这就多了一次随机的I/O操作。
块嵌套循环(BNLJ)
// 伪代码for (r in R) {for (sbu in SBuffer) {if (r satisfy condition sbu) {output <r, s>;}}}

扫描一个表的过程其实是先把这个表从磁盘上加载到内存中,然后在内存中比较匹配条件是否满足。但内存里可能并不能完全存放的下表中所有的记录。为了减少访问被驱动表的次数,我们可以首先将驱动表的数据批量加载到 Join Buffer(连接缓冲),然后当加载被驱动表的记录到内存时,就可以一次性和多条驱动表中的记录做匹配,这样可大大减少被驱动表的扫描次数,这就是 BNLJ 算法的思想。
三种算法比较
算法比较(外表大小R,内表大小S):
| \algorithm comparison\ | Simple Nested Loop Join | Block Nested Loop Join | ||||
|---|---|---|---|---|---|---|
| 外表扫描次数 | 1 | 1 | 1 | |||
| 内表扫描次数 | R | 0 |  | |||
| 读取记录次数 |
|
|
| |||
| 比较次数 |
| R * IndexHeight |
| |||
| 回表次数 | 0 |
| 0 |

整体效率比较:INLJ > BNLJ > SNLJ
哈希连接算法(Hash Join)
MySQL 8.0.18支持在optimizer_switch中设置hash_join标志,以及优化器提示HASH_JOIN和NO_HASH_JOIN。在MySQL 8.0.19和更高版本中,这些都不再有任何效果。
从MySQL 8.0.20开始,对块嵌套循环的支持被删除,并且服务器在以前使用块嵌套循环的地方使用哈希连接。

hash join的实现分为build table也就是被用来建立hash map的小表和probe table,首先依次读取小表的数据,对于每一行数据根据连接条件生成一个hash map中的一个元組,数据缓存在内存中,如果内存放不下需要dump到外存。依次扫描探测表拿到每一行数据根据join condition生成hash key映射hash map中对应的元組,元組对应的行和探测表的这一行有着同样的hash key, 这时并不能确定这两行就是满足条件的数据,需要再次过一遍join condition和filter,满足条件的数据集返回需要的投影列。
// 伪代码 // 算法复杂度:O(M + N) // 假设用户表有M条记录, 订单表有N条记录 func HashJoin(users []TradeUser, orders []TradeOrder) []*UserOrderView {var userOrderViews []*UserOrderView = make([]*UserOrderView, 0)// 将用户表以用户ID为Key,用户为Value转换为Hash表// 算法复杂度:O(M)userTable := make(map[int]TradeUser)for _, user := range users {userTable[user.Id] = user}// 遍历订单表,查找用户// 算法复杂度:O(N)for _, order := range orders {// 复杂度,接近:O(1)if user, exists := userTable[order.UserId]; exists {// 添加视图结果userOrderViews = append(userOrderViews, &UserOrderView{UserId: user.Id,UserName: user.Name,OrderId: order.Id,OrderAmount: order.Amount,})}}return userOrderViews }

注意事项:
- hash join本身的实现不要去判断哪个是小表,优化器生成执行计划时就已经确定了表的连接顺序,以左表为小表建立hash table,那对应的代价模型就会以左表作为小表来得出代价,这样根据代价生成的路径就是符合实现要求的。
- hash table的大小、需要分配多少个桶这个是需要在一开始就做好的,那分配多少是一个问题,分配太大会造成内存浪费,分配太小会导致桶数过小开链过长性能变差,一旦超过这里的内存限制,会考虑dump到外存,不同数据库有它们自身的实现方式。
- 如何对数据hash,不同数据库有着自己的方式,不同的哈希方法也会对性能造成一定的影响。
工作原理:
构建阶段(Build Phase)
- 选择构建表(Build Table):算法通常会选择数据量较小的表作为构建表,以减少哈希表的构建时间和所需内存。但这不是绝对的,实际选择会根据统计信息和成本估算来决定。
- 创建哈希表:对构建表中的每一行记录,取其连接列(即用于JOIN的列)的值,应用哈希函数计算出一个哈希码(hash code)。然后,根据这个哈希码将记录存储在一个哈希桶(hash bucket)中。如果有多个记录的连接列值经过哈希后得到相同的哈希码,这些记录会被组织成链表或其他数据结构存储在同一哈希桶内。
探测阶段(Probe Phase)
- 扫描探测表(Probe Table):对另一个较大的表(探测表)进行扫描。
- 哈希计算与匹配:对于探测表中的每一行,同样对其连接列值应用相同的哈希函数计算哈希码,然后在这个预先构建好的哈希表中查找对应的哈希桶。
- 匹配与输出:如果找到匹配的哈希桶,就进一步检查桶内的链表或数据结构,进行精确的等值比较,以确保连接列的值确实相等。一旦找到匹配项,就结合两个表的相关字段生成结果集的行并输出。
优点:
- 性能优势:在数据量大时,哈希连接可以显著减少磁盘I/O和CPU时间,因为它避免了嵌套循环的多次扫描和排序-合并连接中的排序开销。
- 并行处理友好:哈希连接天然适合并行化处理,因为哈希表可以在不同的处理器或节点上并行构建和查询。
- 内存依赖:哈希连接的效率高度依赖于可用内存,因为需要在内存中存储整个哈希表。如果内存不足,部分或全部哈希表可能需要溢写到磁盘,这会大大降低效率。
缺点:
- 内存消耗:如前所述,构建哈希表需要足够的内存空间,特别是当构建表较大时。
- 非等值连接不适用:哈希连接主要用于等值连接,对于非等值连接(如大于、小于等条件)不适用。
- 预读取与优化:为了效率,数据库系统需要有效管理内存使用,并可能实施预读取策略来优化性能。
排序合并链接(SORT MERGE JOIN)
排序合并连接是嵌套循环连接的变种。如果两个数据集还没有排序,那么数据库会先对它们进行排序,这就是所谓的sort join操作。对于数据集里的每一行,数据库会从上一次匹配到数据的位置开始探查第二个数据集,这一步就是Merge join操作。
// 伪代码 // 算法复杂度:O(M log M + N log N) // 假设用户表有M条记录, 订单表有N条记录 func SortJoin(users []TradeUser, orders []TradeOrder) []*UserOrderView {var userOrderViews []*UserOrderView = make([]*UserOrderView, 0)// 排序user表// 算法复杂度:O(M log M)sort.Slice(users, func(i, j int) bool {return users[i].Id < users[j].Id})// 排序order表// 算法复杂度:O(N log N)sort.Slice(orders, func(i, j int) bool {return orders[i].Id < orders[j].Id})// 遍历订单表,查找用户// 算法复杂度:O(M)userIdx := 0for _, order := range orders {// 在user.id为主键的情况下,这里还可以执行二分查找for idx < len(users) && users[userIdx].Id < order.UserId {userIdx++}// 如果找到用户,添加到结果集合if userIdx < len(users) && users[userIdx].id == order.UserId {// Join条件满足添加视图结果userOrderViews = append(userOrderViews, &UserOrderView{UserId: user.Id,UserName: user.Name,OrderId: order.Id,OrderAmount: order.Amount,})}}return userOrderViews }
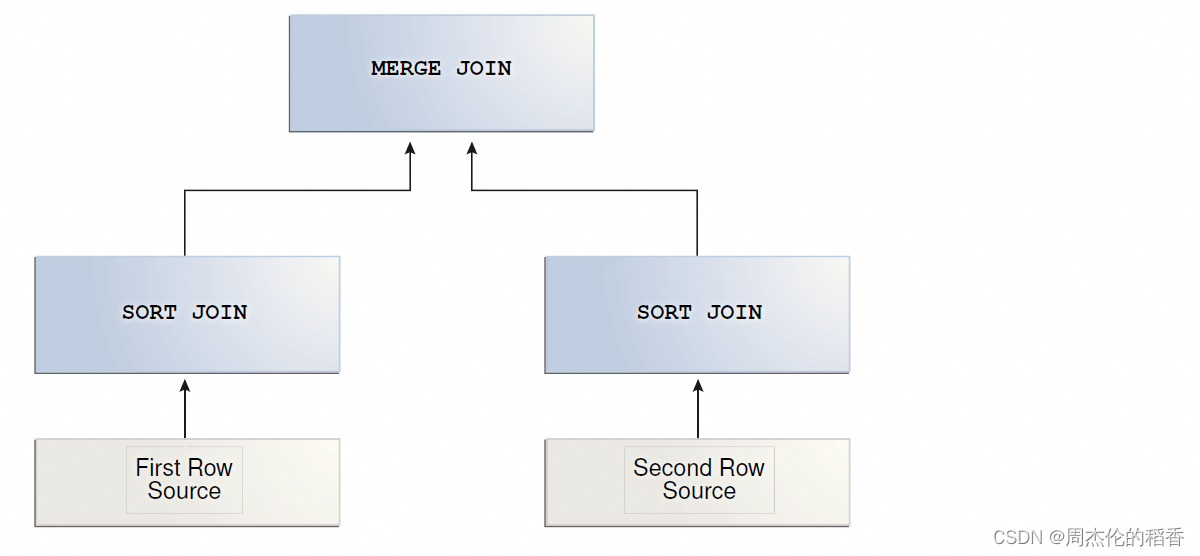
工作流程:
-
排序阶段:
- 数据排序:首先,算法会对参与连接的两个表根据连接键进行排序。这一步骤是关键,因为只有排序后的数据才能有效地进行归并操作。如果表已经按照连接键排序,这一步可以省略。
- 索引利用:如果表上有适合的索引(如聚集索引或覆盖索引),数据库引擎可能会直接利用这些索引来避免全表排序。
-
合并阶段:
- 双指针扫描:一旦两个表的数据都按连接键排序好了,算法会使用两个指针(或游标)分别指向两个表的开始。每个指针逐步向后移动,比较两个指针所指记录的连接键值。
- 匹配与输出:当两个指针指向的记录的连接键相等时,说明这两个记录应该被连接起来,此时就会输出(或累积到结果集中)这对匹配的记录。如果一个表的指针达到末尾,而另一个表还有剩余记录,则剩余的记录被视为不匹配,如果有外连接的情况,则可能作为NULL扩展输出。
- 推进指针:匹配后,指针会根据排序顺序向后移动,继续寻找下一个匹配的记录。
优点:
- 效率:对于大表连接,特别是当连接键分布均匀,且数据已经排序或可以低成本排序时,SMJ比Nested-Loop Join更高效,因为它减少了不必要的比较次数。
- 稳定性:由于是基于排序的,Sort Merge Join保证了输出结果的稳定性,即具有相同键值的记录保持原有的相对顺序。
- 可预测性能:时间复杂度主要取决于排序操作,通常是O(n log n),对于大规模数据集来说,性能较为可预测。
缺点:
- 内存和I/O开销:排序操作可能需要额外的内存空间,并且如果数据不能完全放入内存,还需要磁盘I/O操作,这可能会成为性能瓶颈。
- 预处理时间:排序是预处理步骤,可能增加整体处理时间,尤其是在数据已经接近有序或只需要执行一次连接操作的情况下。
总结
| 算法名称 | 时间复杂度 | 描述 |
| Nested Loop Join | O(M*N) | 适合小数据集,大数据集很慢 |
| Sort Merge Join | O(M log M + N log N + M + N) | 适合于当内存不足以存放整个数据集,需要小的分区上进行排序和合并 |
| Hash Join | O(M+N) | 适用于大数据集 |