python 中如何匹配字符串?
1. re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
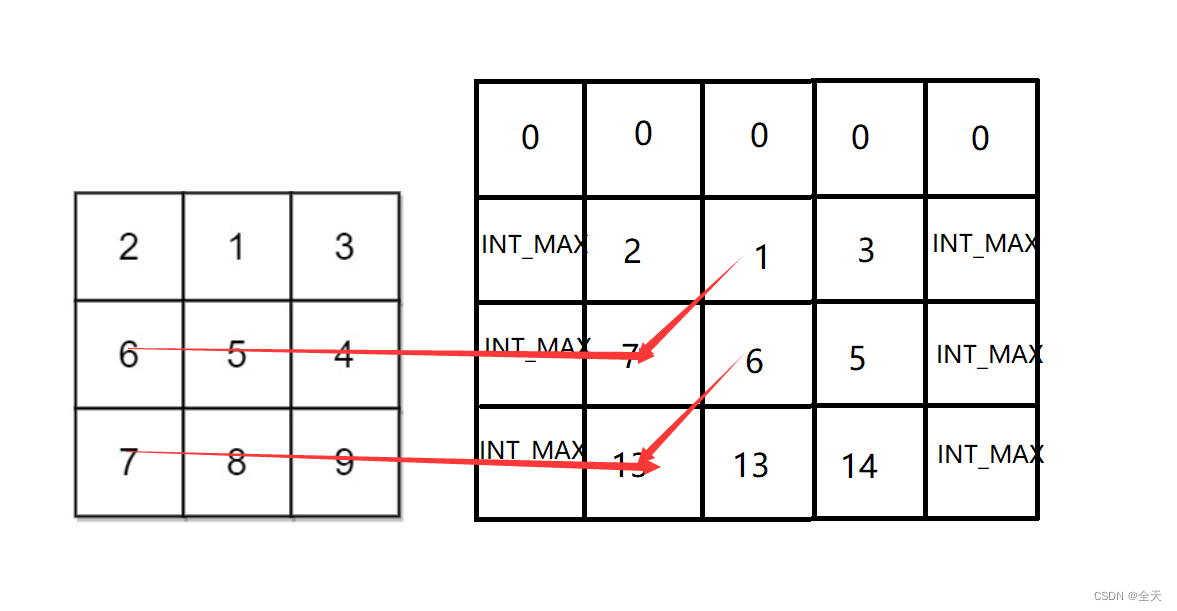
import re line="this hdr-biz 123 model server 456" pattern=r"123" matchObj = re.match( pattern, line)
2. re.search 扫描整个字符串并返回第一个成功的匹配。
import re line="this hdr-biz model server" pattern=r"hdr-biz" m = re.search(pattern, line)
3. Python 的re模块提供了re.sub用于替换字符串中的匹配项。
import re line="this hdr-biz model args= server" patt=r'args=' name = re.sub(patt, "", line)
4. compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
import re pattern = re.compile(r'\d+')
5. re.findall 在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。
import re line="this hdr-biz model args= server" patt=r'server' pattern = re.compile(patt) result = pattern.findall(line)
6. re.finditer 和 findall 类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。
import re it = re.finditer(r"\d+","12a32bc43jf3") for match in it:print (match.group() )
PS:Python字符串匹配及正则表达式说明
解析url地址正则表达式:
regexp = (r'^(?P<scheme>[a-z][\w\.\-\+]+)?:(//)?'r'(?:(?P<username>\w+):(?P<password>[\w\W]+)@|)'r'(?P<domain>[\w-]+(?:\.[\w-]+)*)(?::(?P<port>\d+))?/?'r'(?P<path>\/[\w\.\/-]+)?(?P<query>\?[\w\.*!=&@%;:/+-]+)?'r'(?P<fragment>#[\w-]+)?$')
match = re.search(regexp, url.strip(), re.U)
if match is None:raise ValueError('Incorrent url: {0}'.format(url))
url_parts = match.groupdict()
url='https://blog.csdn.net/weixin_40907382/article/明细/79654372'
print(url_parts):{'scheme': 'https', 'username': None, 'password': None, 'domain': 'blog.csdn.net', 'port': None,
'path': '/weixin_40907382/article/明细/79654372', 'query': None, 'fragment': None}