一、背景介绍
1.1 爬取目标
用Python独立开发的爬虫工具,作用是:通过搜索关键词采集油管的搜索结果,包含14个关键字段:关键词,页码,视频标题,视频id,视频链接,发布时间,视频时长,频道名称,频道id,频道链接,播放数,点赞数,评论数,视频简介。
软件是通过调用ytb的谷歌官方API实现,并非通过网页爬虫,所以稳定性较高!
开通YouTube的API:【详细教程】手把手教你开通YouTube官方API接口(youtube data api v3)
开发成界面软件的目的:方便不懂编程代码的小白用户使用,无需安装python,无需改代码,双击打开即用!
软件界面截图:
爬取结果截图:
结果截图1:
结果截图2: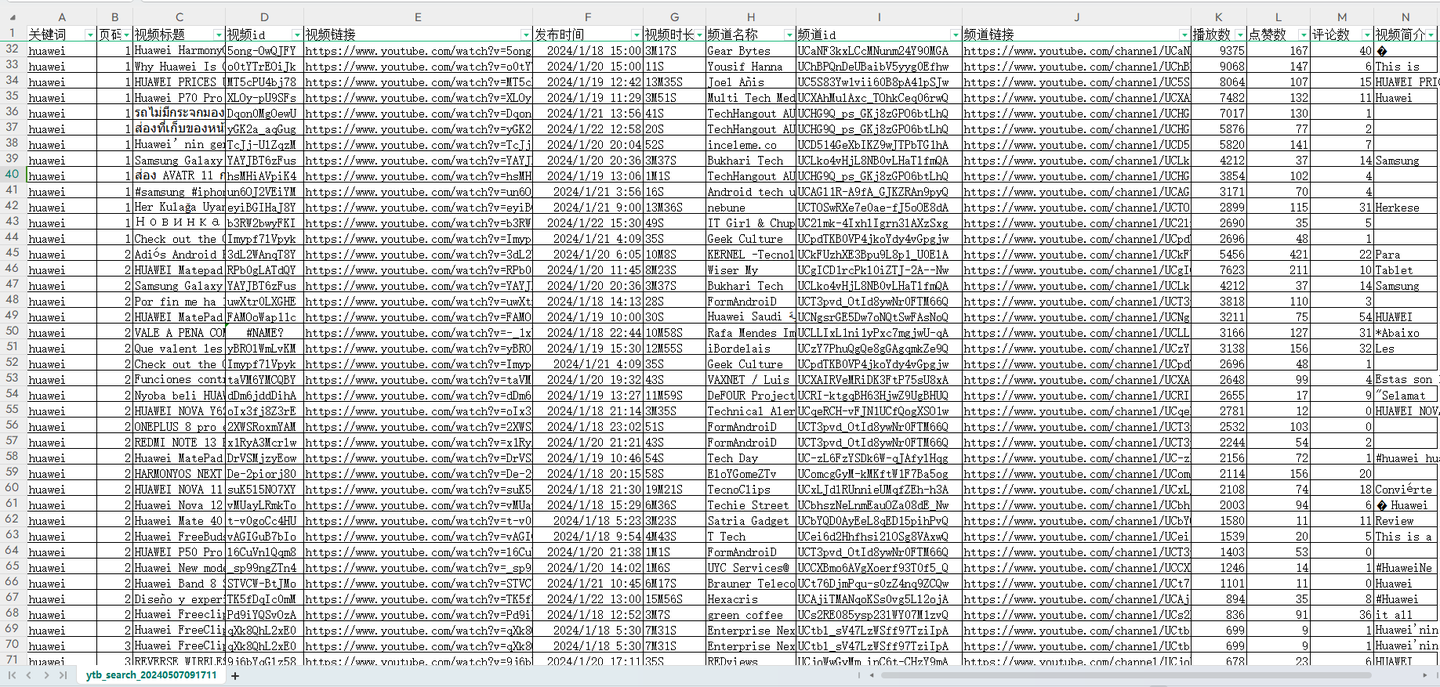
结果截图3: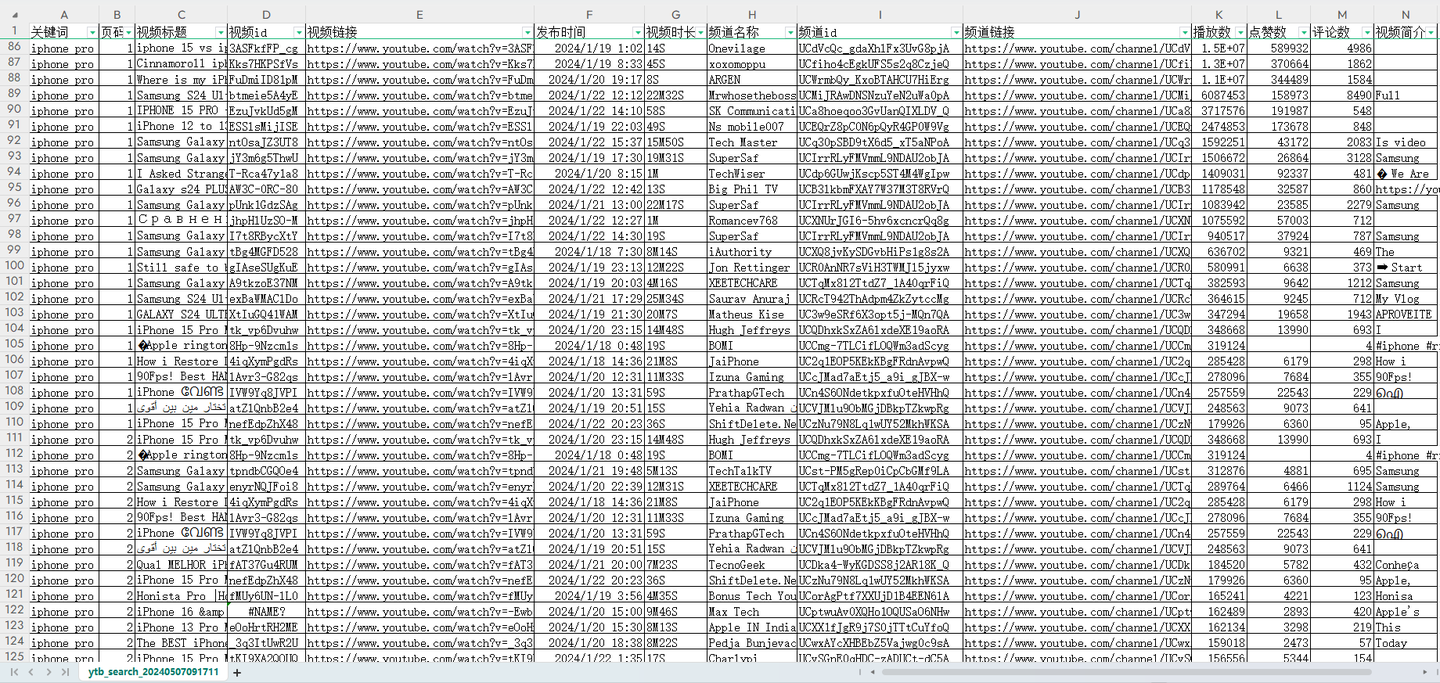
以上。
1.2 演示视频
软件使用演示:(不懂编程的小白直接看视频,了解软件作用即可,无需看代码)
【软件演示】youtube采集工具,根据关键词爬搜索结果
1.3 软件说明
几点重要说明:
以上。
二、代码讲解
2.1 调用API-搜索接口
先给大家看看搜索接口的返回json数据:
首先,定义接口地址作为请求地址:
# 请求地址
url = 'https://youtube.googleapis.com/youtube/v3/search'
定义一个请求头,用于伪造浏览器:
# 请求头
self.headers = {"Accept": "*/*","User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
加上请求参数,告诉程序你的爬取条件是什么:
# 请求参数
params = {'part': 'snippet','maxResults': '25','q': search_keyword,'key': self.API_KEY,'pageToken': pageToken,'order': self.sort_by,'publishedBefore': str(self.end_date) + 'T00:00:00Z','publishedAfter': str(self.start_date) + 'T00:00:00Z',
}
2.2 调用API-详情接口
同样,先给大家看看详情接口的返回json数据:
首先,定义接口地址作为请求地址:
# 请求地址
url = 'https://youtube.googleapis.com/youtube/v3/videos?part=snippet%2CcontentDetails%2Cstatistics&id={}&key={}'.format(video_id, self.API_KEY)
定义一个请求头,用于伪造浏览器:
# 请求头
self.headers = {"Accept": "*/*","User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
下面就是发送请求和接收数据:
# 发送请求
r = requests.post(url, headers=self.headers)
# 接收数据
json_data = r.json()
逐个解析字段数据,以"播放数"为例:
# 播放数
try:viewCount = json_data['items'][0]['statistics']['viewCount']
except:viewCount = ''
其他字段同理,不再赘述。
最后,是把数据保存到csv文件:
# 保存csv文件
with open(self.result_file, 'a+', encoding='utf_8_sig', newline='') as f:writer = csv.writer(f)writer.writerow([search_keyword, page, title, videoId, video_url, create_time, duration, channelTitle,channelId, channel_url, viewCount, likeCount, commentCount, desc])
self.tk_show('csv保存成功:' + self.result_file)
我采用csv库保存结果,实现每爬一条存一次,防止中途异常停止丢失前面的数据。
完整代码中,还含有:读取API_KEY判断、循环结束条件判断、拼接频道URL、try异常保护、日志记录等关键实现逻辑。
2.3 API_KEY说明
API_KEY是访问YouTube官方接口的密钥,只有拿到密钥,并配置到代码里,才能正常调用API接口。
API开通的教程:【详细教程】手把手教你开通YouTube官方API接口(youtube data api v3)
拿到密钥之后,配置到当前文件的config.json里面即可,如下: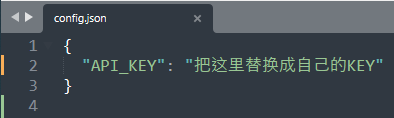
另外,魔法是一切的前提,此处不便多说!
2.4 软件界面模块
主窗口部分:
# 创建主窗口
root = tk.Tk()
root.title('爬YouTube搜索软件v1.0 | 马哥python说 | 定制+v:493882434')
# 设置窗口大小
root.minsize(width=850, height=650)
# 左上角图标
root.iconbitmap('mage.ico')
输入控件部分:
# keyword
tk.Label(root, justify='left', text='搜索关键词:').place(x=30, y=90)
entry_kw = tk.Text(root, bg='#ffffff', width=70, height=2, )
entry_kw.place(x=125, y=90, anchor='nw') # 摆放位置
tk.Label(root, justify='left', text='多关键词以|分隔', fg='red', ).place(x=630, y=90)
运行日志部分:
# 运行日志
tk.Label(root, justify='left', text='运行日志:').place(x=30, y=280)
show_list_Frame = tk.Frame(width=780, height=260) # 创建<消息列表分区>
show_list_Frame.pack_propagate(0)
show_list_Frame.place(x=30, y=310, anchor='nw') # 摆放位置
底部版权部分:
# 版权信息
copyright = tk.Label(root, text='@马哥python说 All rights reserved.', font=('仿宋', 10), fg='grey')
copyright.place(x=290, y=625)
以上。
2.5 日志模块
好的日志功能,方便软件运行出问题后快速定位原因,修复bug。
核心代码:
def get_logger(self):self.logger = logging.getLogger(__name__)# 日志格式formatter = '[%(asctime)s-%(filename)s][%(funcName)s-%(lineno)d]--%(message)s'# 日志级别self.logger.setLevel(logging.DEBUG)# 控制台日志sh = logging.StreamHandler()log_formatter = logging.Formatter(formatter, datefmt='%Y-%m-%d %H:%M:%S')# info日志文件名info_file_name = time.strftime("%Y-%m-%d") + '.log'# 将其保存到特定目录,ap方法就是寻找项目根目录,该方法博主前期已经写好。case_dir = r'./logs/'info_handler = TimedRotatingFileHandler(filename=case_dir + info_file_name,when='MIDNIGHT',interval=1,backupCount=7,encoding='utf-8')
日志文件截图:
以上。
三、获取源码及软件
完整python源码及exe软件,微信公众号"老男孩的平凡之路“后台回复”爬油管搜索软件"即可获取。点击直达