Java的关键字volatile保证了有序性和可见性,这里我试着从底层开始讲一下有序性和可见性。
一,一致性
数据如果同时被两个cpu读取了,如何保证数据的一致性?或者换句话说,cpu1改了数据,cpu2的数据就成了无效的数据,如何保证cpu读取的数据是有效的呢?
在计算机技术比较古老的时候,采用的解决办法就是总线锁,即锁住cpu到内存的cpu总线[3],如此,同时最多仅能有一个cpu访问数据,但是这样带来的坏处是显而易见的,就是并发能力很低。

另外一种比较现代的解决方式就是CPU缓存一致性协议,也可以叫缓存锁。最常见的是Intel实现的是MESI协议,MESI(Modified Exclusive Shared Or Invalid)(也称为伊利诺斯协议,是因为该协议由伊利诺斯州立大学提出)是一种广泛使用的支持写回策略的缓存一致性协议。CPU中每个缓存行(caceh line)使用4种状态进行标记(使用额外的两位(bit)表示),分别是[4]:
M: 被修改(Modified)
该缓存行只被缓存在该CPU的缓存中,并且是被修改过的(dirty),即与主存中的数据不一致,该缓存行中的内存需要在未来的某个时间点(允许其它CPU读取请主存中相应内存之前)写回(write back)主存。
当被写回主存之后,该缓存行的状态会变成独享(exclusive)状态。
E: 独享的(Exclusive)
该缓存行只被缓存在该CPU的缓存中,它是未被修改过的(clean),与主存中数据一致。该状态可以在任何时刻当有其它CPU读取该内存时变成共享状态(shared)。
同样地,当CPU修改该缓存行中内容时,该状态可以变成Modified状态。
S: 共享的(Shared)
该状态意味着该缓存行可能被多个CPU缓存,并且各个缓存中的数据与主存数据一致(clean),当有一个CPU修改该缓存行中,其它CPU中该缓存行可以被作废(变成无效状态(Invalid))。
I: 无效的(Invalid)
该缓存是无效的(可能有其它CPU修改了该缓存行)。
需要注意的是,这些标识了状态位的缓存行是存储在cpu私有的cpu高速缓存中(L1、L2)。可以看到,cpu根据缓存行的状态位进行判断,进而读取、或者重新从共享主存中读取、或者在别的cpu读取共享主存数据之前写入。
这样,我们通过缓存锁(实质上这里举例的是MESI协议),在某些情况下达到了确保一致性。
为什么是“有些情况”呢?因为在数据无法被缓存的情况下、或者数据跨越多个缓存行的情况下,依然需要使用总线锁来解决一致性问题。
二,有序性
说起保证有序性,在此之前,我想我们需要先看一下,如何证明,代码会被cpu乱序执行。网上有这样一段代码,可以证明。
private static int x = 0, y = 0;private static int a = 0, b =0;public static void main(String[] args) throws InterruptedException {int i = 0;for(;;) {i++;x = 0; y = 0;a = 0; b = 0;Thread one = new Thread(new Runnable() {public void run() {//由于线程one先启动,下面这句话让它等一等线程two. 读着可根据自己电脑的实际性能适当调整等待时间.//shortWait(100000);a = 1;x = b;}});Thread other = new Thread(new Runnable() {public void run() {b = 1;y = a;}});one.start();other.start();one.join();other.join();String result = "第" + i + "次 (" + x + "," + y + ")";if(x == 0 && y == 0) {System.err.println(result);break;} else {//System.out.println(result);}}}
如果一切都是顺序执行,那么当一个变量为0时,另外一个不可能为0 。而执行结果是时间够长,你就会发现确实出现了x和y都为0的情况。这就证明了cpu的乱序执行,即
线程one中执行如下: x = b; a = 1;
线程other中执行如下:y = a; b = 1;
导致x和y的值都为0.

cpu会首先访问寄存器,寄存器没有去访问L1,L1没有去访问L2,直到访问主存,主存没有去访问硬盘,从硬盘中load数据到内存,再挨个返回到给cpu为止。
之所以会出现cpu乱序执行[1],是因为cpu的速度要比内存快很多个数量级,如果cpu要访问的数据在内存中没有,从下图中来看,假设cpu执行了一个时钟周期,发出了要读取数据的命令,而内存要返回要读取的数据,要至少两百多时钟周期,这期间cpu都在等待内存返回数据。这无疑是对计算资源的浪费,因此cpu会在等待期间做别的事。什么事呢?
读指令的同时可以同时执行不影响读指令的其他指令
写的同时可以可以进行合并写(WCBuffer)[注1]
这就是cpu乱序执行的根源。
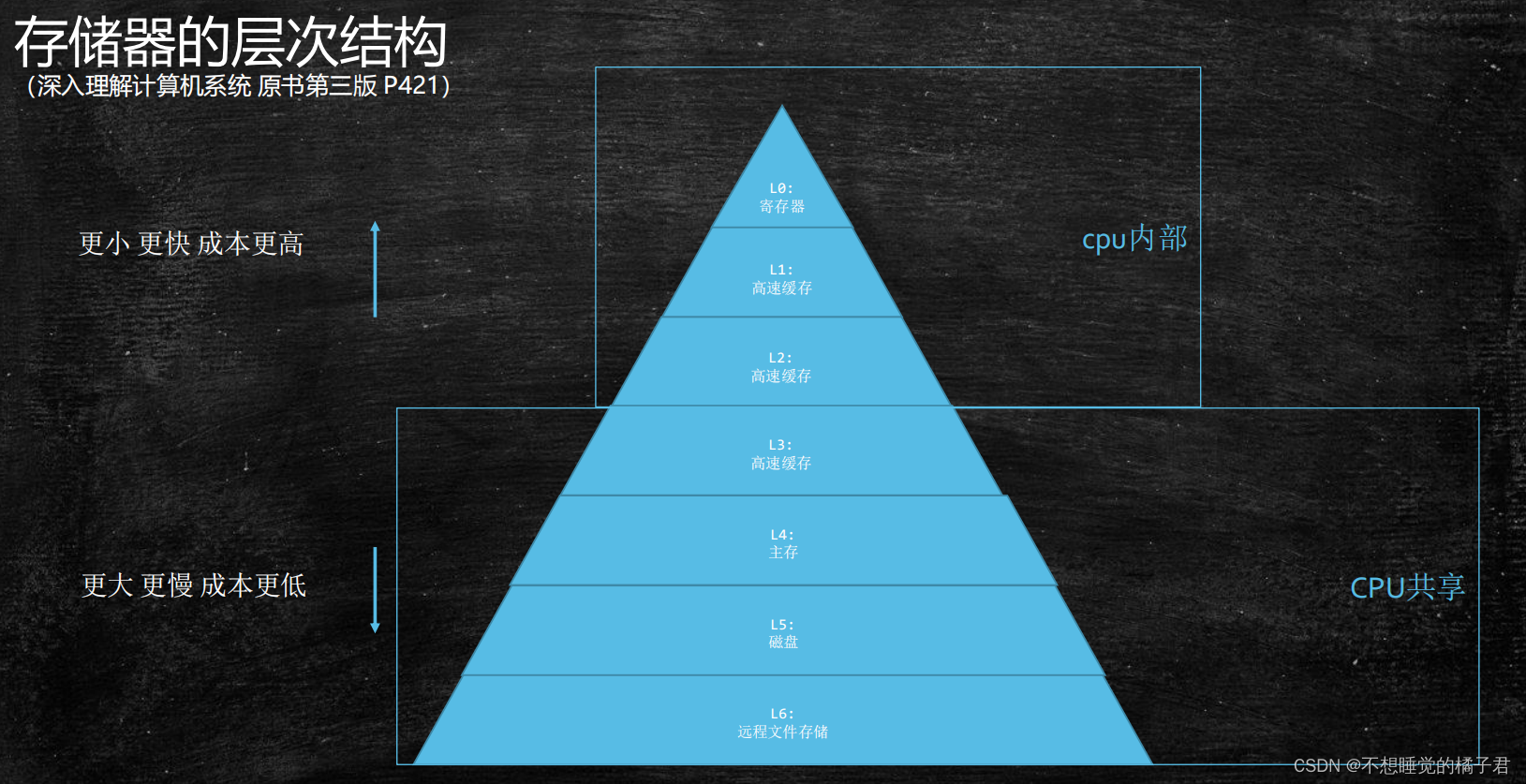
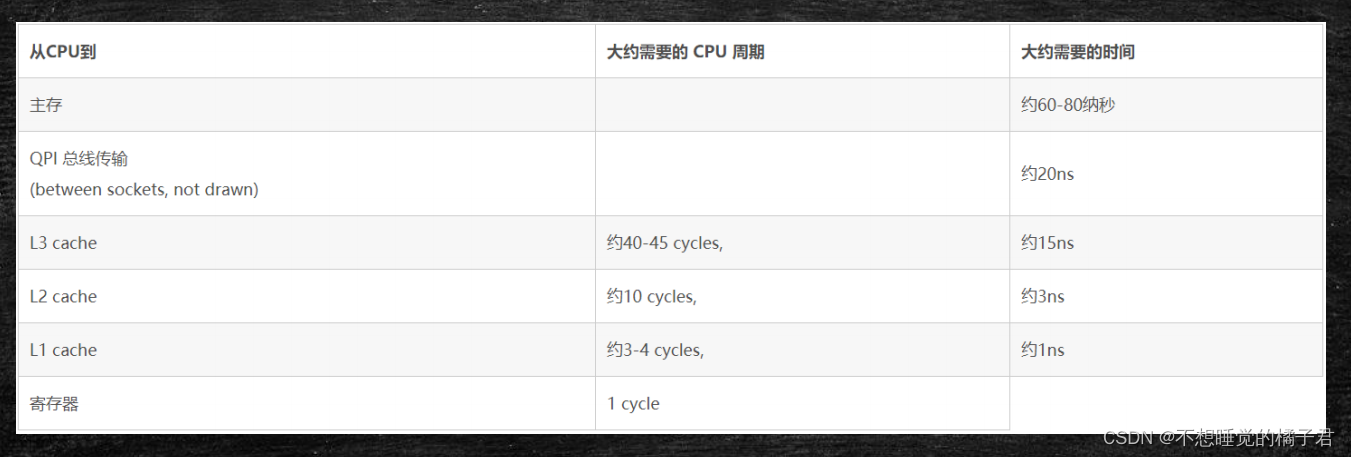
显然cpu乱序执行在多线程时会带来一些有序性上的问题,那么如何解决的呢?在不同层级有不同层级的解决办法,下面依次来说一下。
1.硬件层面
下面的内存屏障和lock锁都以intel的cpu来举例,不同的cpu有不同的内存屏障的实现,对于保障有序性的方式也不尽相同。
1.1 硬件级别内存屏障 sfence、lfence、mfence
如intel的cpu,有如下的cpu内存屏障可以实现有序性。
X86 intel CPU内存屏障
sfence:在sfence指令前的写操作当必须在sfence指令后的写操作前完成。
lfence:在lfence指令前的读操作当必须在lfence指令后的读操作前完成。
mfence:在mfence指令前的读写操作当必须在mfence指令后的读写操
作前完成。
举例解释一下sfence,假设有如下两个"独立"的写操作,
写操作A
写操作B
在没有添加cpu内存屏障指令前,是可以cpu乱序执行的,如乱序为B->A。但是在添加了cpu内存屏障sfence后,写操作A不允许重排序到内存屏障sfence之后,写操作B不允许重排序到内存屏障sfence之前。
写操作A
sfence
写操作B
类似的,读操作有读内存屏障,读操作无法重排序越过读内存屏障lfence。而mfence则可以阻挡住读操作和写操作。
1.2 lock
此外intel的cpu也可以通过lock锁指令来实现有序性。
intel lock汇编指令
原子指令,如x86上的”lock …” 指令是一个Full
Barrier,执行时会锁住内存子系统来确保执行顺
序,甚至跨多个CPU。Software Locks通常使用
了内存屏障或原子指令来实现变量可见性和保持
程序顺序
2.应用层面
在应用层面,JVM规定的内存屏障,如下共4种。
JSR内存屏障(Java Specification Request,JSR,Java规范请求)
LoadLoad屏障:
对于这样的语句Load1; LoadLoad; Load2,
在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
StoreStore屏障:
对于这样的语句Store1; StoreStore; Store2,
在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。
LoadStore屏障:
对于这样的语句Load1; LoadStore; Store2,
在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。
StoreLoad屏障:对于这样的语句Store1; StoreLoad; Load2,
在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。
这4种内存屏障的功能,比之intel cpu级别的内存屏障要复杂一些,但是核心的功能没有改变,依然是阻止不同读写操作越过内存屏障重排序,其实现依赖于硬件层面的内存屏障或者锁。如这篇文章[5]中测试用的windows系统的机器使用的是lock指令实现的JVM级别的内存屏障。
三,volatile和synchronized
前文讲述了硬件级别如何保证有序性和可见性(此外还有应用级别如JVM保证有序性),下面就聊一下volatile和synchronized
1,volatile
1.1 volatile在编译器层面
依然可以看到其字节码是volatile没有变,编译器没有对volatile做特殊的处理。
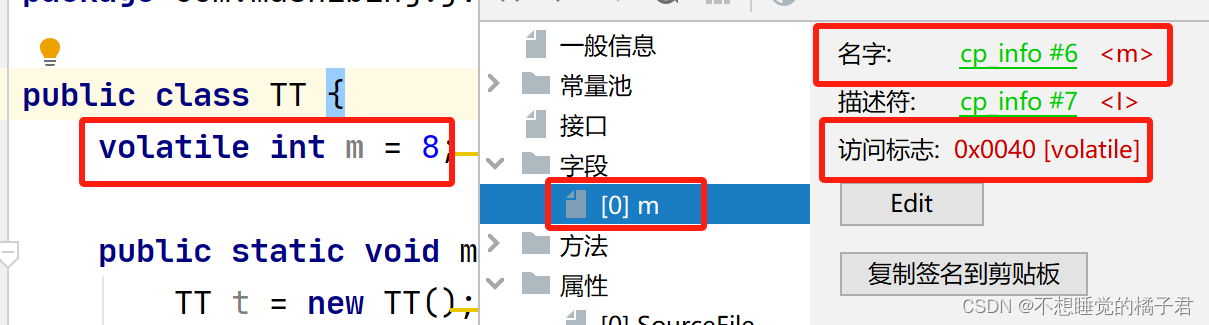
1.2 volatile在JVM层面
实现有序性的方式如下:
StoreStoreBarrier
volatile 写操作
StoreLoadBarrier
或者
LoadLoadBarrier
volatile 读操作
LoadStoreBarrier
1.3 volatile在cpu硬件层面
我们在前面已经举例了文章[5],通过反汇编器hsdis,可以看到举例的机器是通过lock指令来保证有序性,但是注意不同的机器,其实现有序性的方式可能不同。

2,synchronized
2.1 synchronized在编译器层面
举例如下
synchronized方法,在字节码中仅仅是accedss flags中加了一个synchronized。
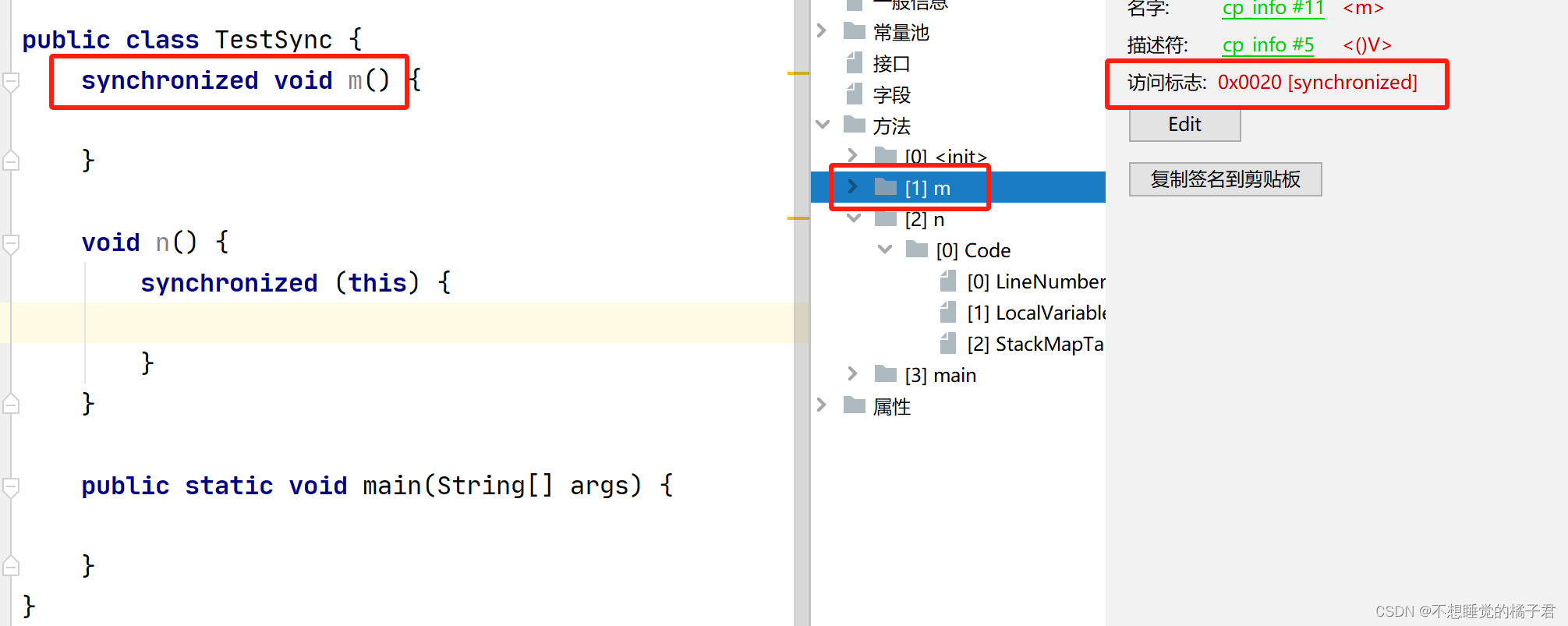
在方法中添加synchronized代码块,会在字节码中添加monitor enter和monitoer exit,即监视器的进入和监视器的退出。(有2个monitorexit是因为一个是正常的退出synchronized代码块,一个是类似于try catch在抛异常的时候退出监视器)
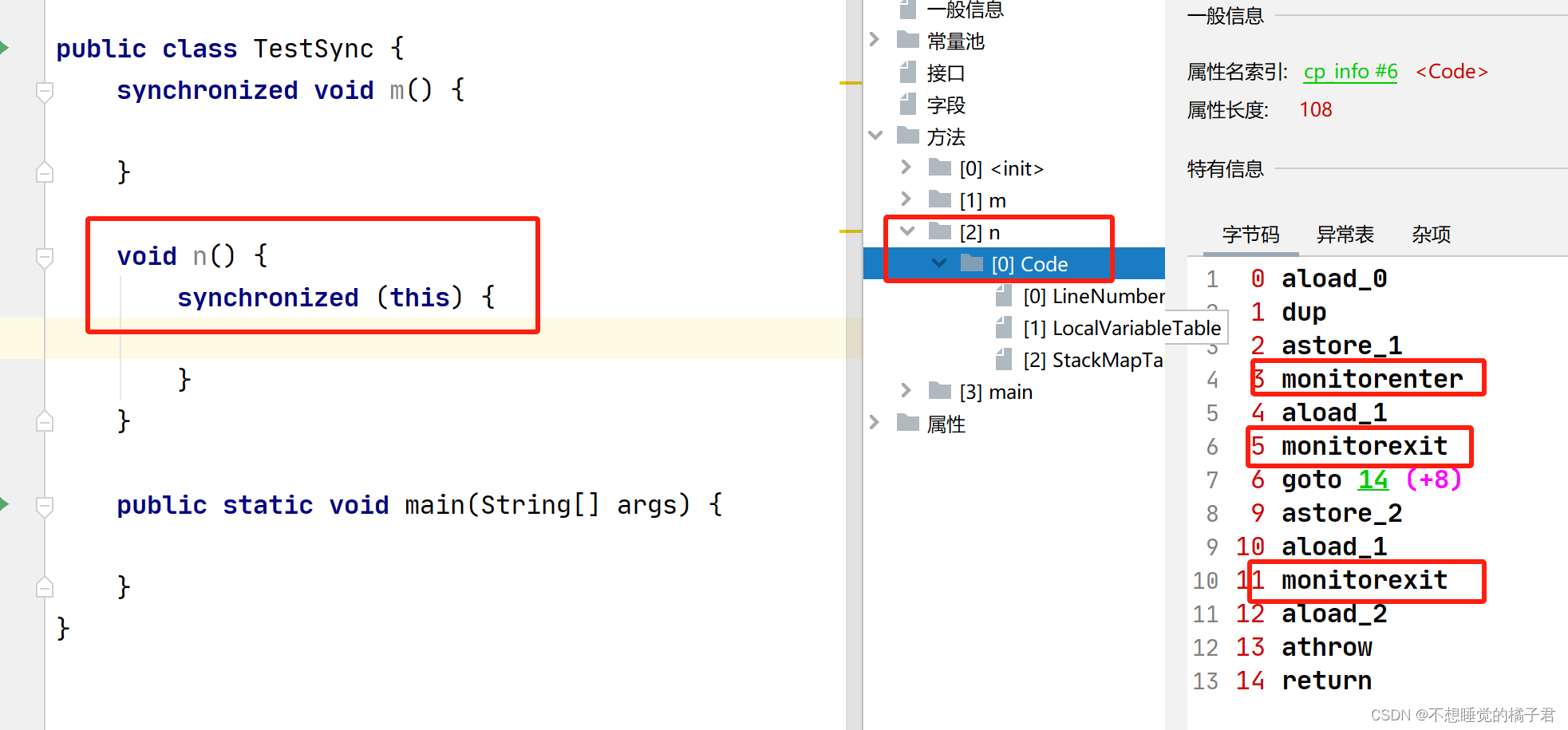
2.2 synchronized在JVM层面
靠的是一些C和C++调用了系统提供的同步机制。
2.3 synchronized在cpu硬件层面
在这篇文章[6]中可以看到是依靠的lock cmpxchg
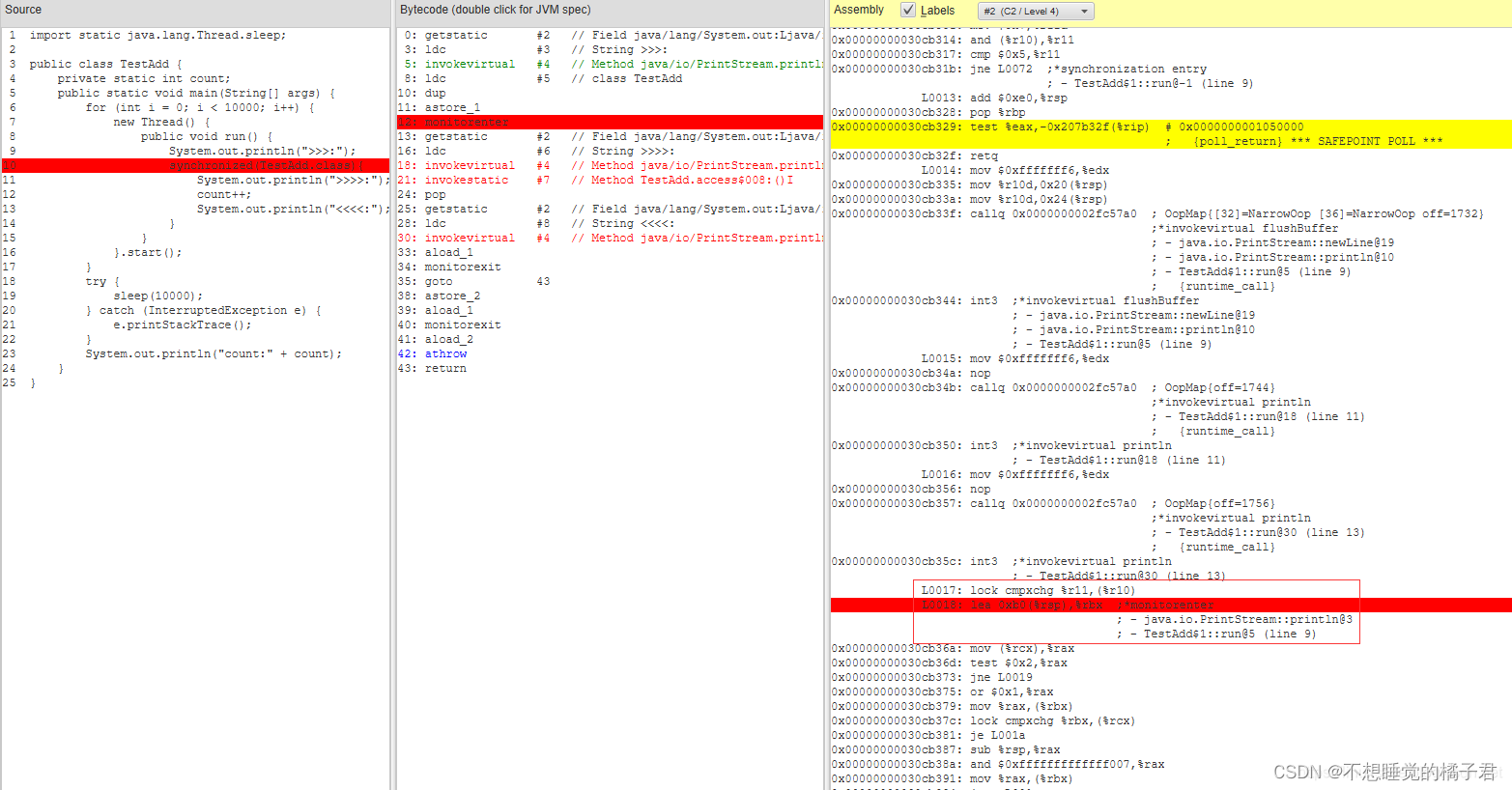
四,其他
此外,还有一些面试时会考到的其他知识点,
如happens-before原则,(JVM规定重排序必须遵守的规则)
JLS17.4.5
•程序次序规则:同一个线程内,按照代码出现的顺序,前面的代码先行于后面的代码,准
确的说是控制流顺序,因为要考虑到分支和循环结构。
•管程锁定规则:一个unlock操作先行发生于后面(时间上)对同一个锁的lock操作。
•volatile变量规则:对一个volatile变量的写操作先行发生于后面(时间上)对这个变
量的读操作。
•线程启动规则:Thread的start( )方法先行发生于这个线程的每一个操作。
•线程终止规则:线程的所有操作都先行于此线程的终止检测。可以通过Thread.join( )
方法结束、Thread.isAlive( )的返回值等手段检测线程的终止。
•线程中断规则:对线程interrupt( )方法的调用先行发生于被中断线程的代码检测到中
断事件的发生,可以通过Thread.interrupt( )方法检测线程是否中断
•对象终结规则:一个对象的初始化完成先行于发生它的finalize()方法的开始。
•传递性:如果操作A先行于操作B,操作B先行于操作C,那么操作A先行于操作C
比如,as if serial
不管如何重排序,单线程执行结果不会改变
比如,java8大原子操作(虚拟机规范)(已弃用,了解即可)
最新的JSR-133已经放弃这种描述,但JMM没有变化
《深入理解Java虚拟机》P364
lock:主内存,标识变量为线程独占
unlock:主内存,解锁线程独占变量
read:主内存,读取内容到工作内存
load:工作内存,read后的值放入线程本地变量副本
use:工作内存,传值给执行引擎
assign:工作内存,执行引擎结果赋值给线程本地变量
store:工作内存,存值到主内存给write备用
write:主内存,写变量值
注[1]:
当cpu执行存储指令(写入数据)时,它会首先试图将数据写到离cpu最近的L1_cache, 如果此时cpu出现L1未命中,则会访问下一级缓存。速度上L1_cache基本能和cpu持平,其他的均明显低于cpu,L2_cache的速度大约比cpu慢20-30倍,而且还存在L2_cache不命中的情况,又需要更多的周期去主存读取。其实在L1_cache未命中以后,cpu就会使用一个另外的缓冲区,叫做合并写存储缓冲区。这一技术称为合并写入技术。在请求L2_cache缓存行的所有权尚未完成时,cpu会把待写入的数据写入到合并写存储缓冲区,该缓冲区大小和一个cache line[注2]大小,一般都是64字节。这个缓冲区允许cpu在写入或者读取该缓冲区数据的同时继续执行其他指令,这就缓解了cpu写数据时cache miss时的性能影响[2]。
注[2]:
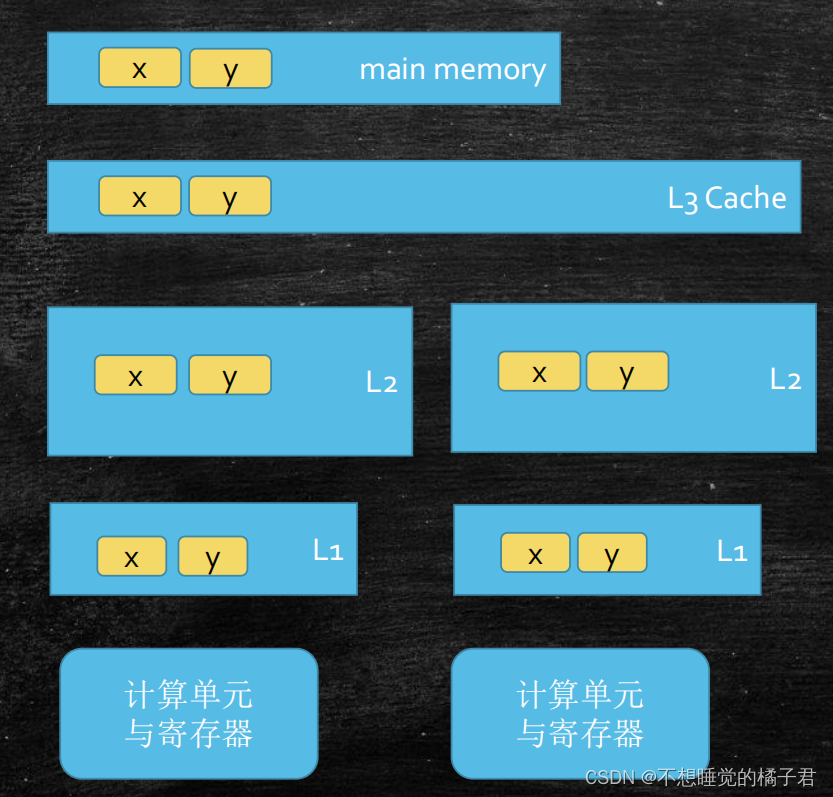
cpu读取数据时,比如要读取一个int类型4个字节,不会仅仅将这4个字节的int类型数据读进来,而是会把64个字节(一般为64字节)一整块读取进来,这一整块读取的单位叫缓存行(cache line)。如下图中,x和y处于一个缓存行中,被不同的两个cpu读取。cpu1要读取的是x,cpu2要读取的是y。当cpu1修改数据时,缓存锁的状态改为modified,cpu2对应的状态就会改为invalied。那么cpu2就会重新去读取数据,如果此时cpu2也修改了数据,那么cpu1的缓存锁状态就会为invalied,cpu1就需要重新读取数据。这种由于位于同一个缓存行的不同数据,被不同cpu读取,进而导致的一致性冲突的问题,称之为伪共享。
参考文章: [1],现代cpu的合并写技术对程序的影响
[2],现代cpu的合并写技术对程序的影响
[3],总线锁、缓存锁、MESI
[4],【并发编程】MESI–CPU缓存一致性协议
[5],volatile与lock前缀指令
[6],Java使用字节码和汇编语言同步分析volatile,synchronized的底层实现



![数据结构05:树与二叉树 习题01[C++]](https://img-blog.csdnimg.cn/direct/e523d095fbd34f8f92541e0573c72475.png)