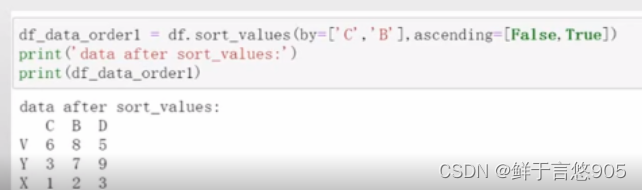
文章目录
- 简介
- 方法
- 总体框架 (Language-Guided Dense Prediction)
- 上下文感知提示 (Context-Aware Prompting)
- 应用实例
论文:DenseCLIP: Language-Guided Dense Prediction with Context-Aware Prompting
代码:https://github.com/raoyongming/DenseCLIP
简介
- 提出背景:
现有的方法大多数用CLIP预训练模型来解决分类任务,但是很少应用在密集预测的任务上。本文就主要研究如何微调预训练的CLIP模型,使其可以应用于密集预测任务 - 困难挑战:
与传统的ImageNet预训练模型相比,最大的挑战是上游对比预训练任务和下游逐像素预测任务之间的gap,前者涉及图像和文本的实例级表示,而后者仅基于像素级的视觉信息。 - 解决思路:
为了解决上述问题,通过隐式和显式地利用来自CLIP的预训练知识,提出了一个语言引导的密集预测框架: DenseCLIP。 该框架是模型不可知(model-agnostic)且即插即用(plug-and-play),可以应用于任意密集预测系统和各种预训练的视觉主干。
(1)隐式方法:直接对下游数据集上的模型进行微调。但是这种直接的方法不能充分利用CLIP模型的潜力。
(2)显示的方法:受CLIP中原始对比学习框架的启发,将CLIP中的原始图像-文本匹配问题转换为像素-文本匹配问题,并使用像素-文本得分映射来指导密集预测模型的学习。通过进一步使用图像中的上下文信息来提示语言模型,能够促进模型更好地利用预训练的知识。

- 传统的预训练+微调模式:如上图所示,通常通过在ImageNet等大规模数据集上对骨干模型进行监督分类或自监督学习来完成,然后在骨干模型上添加特定任务的模块,如检测器或分割解码器,然后在训练数据较少的目标数据集上对整个模型进行微调。

- DenseCLIP的预训练步骤:CLIP预训练模型+语言引导的微调
DenseCLIP通过引入新的像素-文本匹配任务,将图像-文本对比学习的知识转移到密集预测模型中,并进一步使用图像中的上下文信息提示预训练的语言模型。
方法
总体框架 (Language-Guided Dense Prediction)
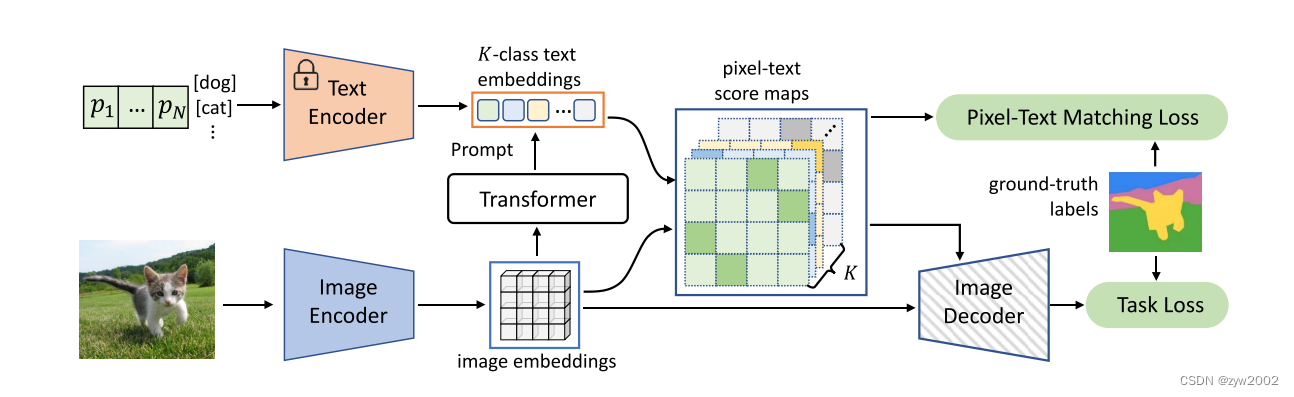
如上图所示,DenseCLIP的步骤如下:
- DenseCLIP首先提取图像嵌入(
image embeddings)和 K类文本嵌入(k-class text embeddings) - 然后计算像素-文本得分映射(
pixel-text score maps),将CLIP中原始的图像-文本匹配问题转化为像素-文本匹配进行密集预测。 - 这些分数图被输入到解码器中,并使用真值标签进行监督。
- 为了更好地利用预先训练的知识,DenseCLIP使用图像中的上下文信息来用Transformer模块提示语言模型。
除了全局图像特征,我们还可以从CLIP图像编码器的最后一层提取语言兼容的特征映射。
以ResNet编码器为例,总共有4个阶段,我们将特征映射表示为 { x i } i − 1 4 \{x_i\}^4_{i-1} {xi}i−14。与原来的ResNet不同,CLIP增加了一个注意力池化层(attention pooling layer)。
CLIP首先对 x 4 ∈ R H 4 W 4 × C x_4\in R^{H_4W_4\times C} x4∈RH4W4×C进行全局平均池化,得到一个全局特征 x ˉ 4 ∈ R 1 × C \bar x_4\in R^{1\times C} xˉ4∈R1×C, 其中 H 4 H_4 H4、 W 4 W_4 W4、 C C C分别为骨干网第4段特征图的高度、宽度和通道数。
然后将连接的特征 [ x ˉ 4 , x 4 ] [\bar x_4, x_4] [xˉ4,x4]馈送到多头自关注层 (MHSA)。
⌈ z ‾ , z ] = MHSA ( [ x ‾ 4 , x 4 ] ) . \lceil\overline{\mathbf{z}}, \mathbf{z}]=\operatorname{MHSA}\left(\left[\overline{\mathbf{x}}_4, \mathbf{x}_4\right]\right) . ⌈z,z]=MHSA([x4,x4]).
在CLIP的标准训练过程中,使用全局特征 z ‾ \overline{\mathbf{z}} z作为图像编码器的输出,而其他输出 z \mathbf{z} z通常被忽略。
然而,作者发现z有两个有趣的性质: (1) z \mathbf{z} z仍然保留了足够的空间信息,因此可以作为特征映射。(2)由于MHSA对每个输入元素都是对称的,所以 z \mathbf{z} z的行为可能类似于 z ‾ \overline{\mathbf{z}} z,这与语言特征很好地一致。
为了获得文本特征,我们可以从模板“a photo of a [CLS]”中构造文本提示。,用K个类名,使用CLIP文本编码器提取特征 t ∈ R K × C t\in R^{K×C} t∈RK×C。
然后,使用语言兼容的特征图 z \mathbf{z} z和文本特征 t t t来计算像素-文本分数图 (pixel-text score maps):
s = z ^ t ^ ⊤ , s ∈ R H 4 W 4 × K \mathbf{s}=\hat{\mathbf{z}} \hat{\mathbf{t}}^{\top}, \quad \mathbf{s} \in \mathbb{R}^{H_4 W_4 \times K} s=z^t^⊤,s∈RH4W4×K
其中 z ^ \hat{\mathbf{z}} z^和 t ^ \hat{\mathbf{t}}^{} t^ 是 z \mathbf{z} z和 t \mathbf{t} t沿着通道维度的L2 normalization。
score maps描述了像素-文本匹配的结果。首先,score maps可以看作是分辨率较低的分割结果,因此我们可以使用它们来计算辅助分割损失。其次,我们可以将score maps连接到最后一个特征映射,以显式地合并语言先验,例如:
x 4 ′ = [ x 4 , s ] ∈ R H 4 W 4 × ( C + K ) \mathbf{x}_4^{\prime}=\left[\mathbf{x}_4, \mathbf{s}\right] \in \mathbb{R}^{H_4 W_4 \times(C+K)} x4′=[x4,s]∈RH4W4×(C+K)
上下文感知提示 (Context-Aware Prompting)
在DenseCLIP中并没有使用人工预定义模板,而是寻求其他方法来改进文本特征。
- Language-domain prompting
受到CoOP的启发,在DenseCLIP框架中使用可学习的文本上下文(learnable textual contexts)作为基线,它只包括语言域提示 (language-domain prompting)。然后文本编码器的输入变成:
[ p , e k ] , 1 ≤ k ≤ K \left[\mathbf{p}, \mathbf{e}_k\right], \quad 1 \leq k \leq K [p,ek],1≤k≤K
其中 p ∈ R N × C \mathbf{p} \in \mathbb{R}^{N \times C} p∈RN×C是 learnable textual contexts, e k ∈ R C \mathbf{e}_k \in \mathbb{R}^C ek∈RC k k k-th 个类别的名称嵌入. - Vision-to-language prompting
包括视觉上下文的描述可以使文本更准确。例如,“一张猫在草地上的照片。比“一张猫的照片”更准确。
因此,我们研究了如何使用视觉上下文来优化文本特征。一般来说,我们可以使用Transformer解码器中的交叉注意机制(cross-attention mechanism)来模拟视觉和语言之间的交互。
作者提出了两种不同的上下文感知提示策略:

- 第一个策略是模型前提示(
pre-model prompting)。
我们将特征 [ z ‾ , z ] [\overline{\mathbf{z}}, \mathbf{z}] [z,z]传递给Transformer解码器来编码视觉上下文:
v pre = TransDecoder ( q , [ z ‾ , z ] ) \mathbf{v}_{\text {pre }}=\operatorname{TransDecoder}(\mathbf{q},[\overline{\mathbf{z}}, \mathbf{z}]) vpre =TransDecoder(q,[z,z])
其中 q ∈ R N × C \mathbf{q} \in \mathbb{R}^{N \times C} q∈RN×C 是一组learnable queries, v pre ∈ \mathbf{v}_{\text {pre }} \in vpre ∈ R N × C \mathbb{R}^{N \times C} RN×C 是提取的visual contexts. (其实就是将Language-domain prompting中的 p \mathbf{p} p替换为 visual context v pre \mathbf{v}_{\text {pre }} vpre )
由于修改了文本编码器的输入,我们将此版本称为pre-model prompting。

- 第二种策略是模型后提示(
post-model prompting),是在文本编码器之后细化文本特征。在这个变体中,我们使用CoOp来生成文本特征,并直接将它们用作Transformer解码器的查询:
v post = TransDecoder ( t , [ z ‾ , z ] ) \mathbf{v}_{\text {post }}=\operatorname{TransDecoder}(\mathbf{t},[\overline{\mathbf{z}}, \mathbf{z}]) vpost =TransDecoder(t,[z,z])
这种策略促使文本特征找到最相关的视觉线索。
然后,我们通过残差连接更新文本特征:
t ← t + γ v post \mathbf{t} \leftarrow \mathbf{t}+\gamma \mathbf{v}_{\text {post }} t←t+γvpost
其中 γ ∈ R C \gamma \in \mathbb{R}^C γ∈RC 是控制残差缩放的可学习参数, γ \gamma γ 初始化为非常小的值(例如, 1 0 − 4 10^{-4} 10−4 ),以最大限度地保留文本特征中的语言先验。
虽然这两种策略的目标相同,但我们更倾向于模型后提示 post-model prompting,主要有两个原因:
(1)模型后提示更高效的。模型前提示需要文本编码器在推理期间进行额外的前向传递,因为它的输入依赖于图像。在模型后提示的情况下,我们可以在训练后存储提取的文本特征,从而减少文本编码器在推理过程中带来的开销。
(2)实证结果表明,模型后提示比模型前提示效果更好。
应用实例
- 语义分割
DenseCLIP框架是模型不可知(model-agnostic)的,可以应用于任何密集的预测管道。
此外,作者提出使用一个辅助目标函数来更好地在分割任务重利用像素文本分数图。
由于分数映射 s ∈ R H 4 W 4 × K \mathbf{s} \in \mathbb{R}^{H_4 W_4 \times K} s∈RH4W4×K可以看作是较小的分割结果,因此我们计算其分割损失:
L aux seg = CrossEntropy ( Softmax ( s / τ ) , y ) \mathcal{L}_{\text {aux }}^{\text {seg }}=\operatorname{CrossEntropy}(\operatorname{Softmax}(\mathbf{s} / \tau), \mathbf{y}) Laux seg =CrossEntropy(Softmax(s/τ),y)
式中 τ = 0.07 \tau=0.07 τ=0.07 是 temperature coefficient , y ∈ { 1 , … , K } H 4 W 4 \mathbf{y} \in\{1, \ldots, K\}^{H_4 W_4} y∈{1,…,K}H4W4 是ground truth label。
辅助分割损失可以帮助特征映射更快地恢复其局部,有利于分割和检测的密集预测任务。 - 目标检测 & 实例分割
在这种情况下,我们没有ground truth label。为了构建与分割中类似的辅助损失,我们使用边界框和标签来构建一个二元目标 y ~ ∈ { 0 , 1 } H 4 W 4 × K \tilde{\mathbf{y}} \in\{0,1\}^{H_4 W_4 \times K} y~∈{0,1}H4W4×K。辅助目标可以定义为二值交叉熵损失:
L aux det = BinaryCrossEntropy ( Sigmoid ( s / τ ) , y ~ ) \mathcal{L}_{\text {aux }}^{\text {det }}=\operatorname{BinaryCrossEntropy}(\operatorname{Sigmoid}(\mathbf{s} / \tau), \tilde{\mathbf{y}}) Laux det =BinaryCrossEntropy(Sigmoid(s/τ),y~) - 应用到任何骨干模型
我们可以用任何骨干(例如,ImageNet预训练模型和自监督模型)替换CLIP的图像编码器。虽然视觉主干的输出与文本编码器之间可能没有很强的关系,但在语言指导下主干可以更好更快地学习。换句话说,我们可以利用预训练文本编码器的语言先验来提高任何预训练图像主干的性能,这使得DenseCLIP成为一个更通用的框架,可以利用从大规模预训练中学习到的自然语言先验来改进密集预测的性能。