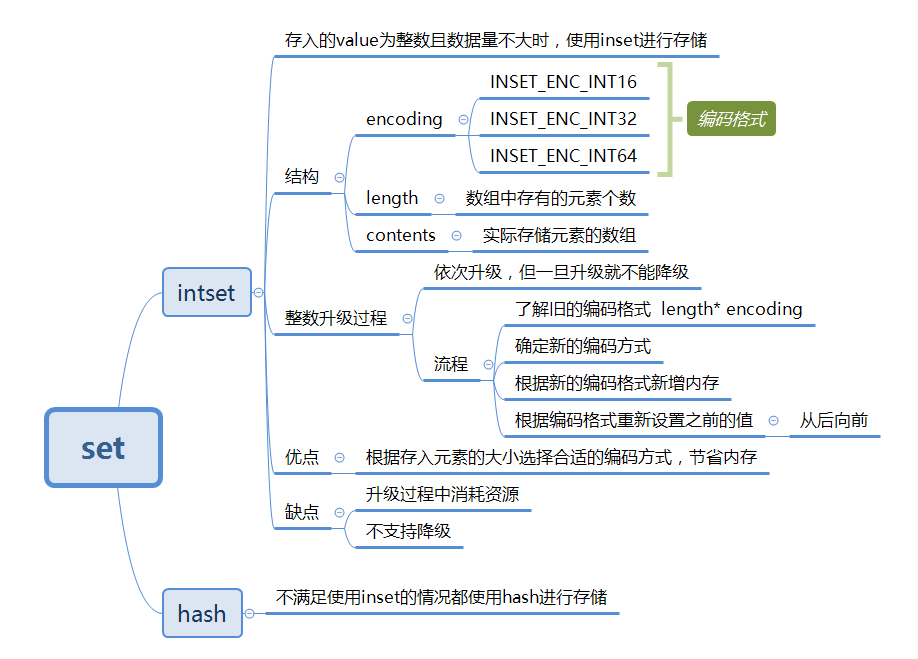
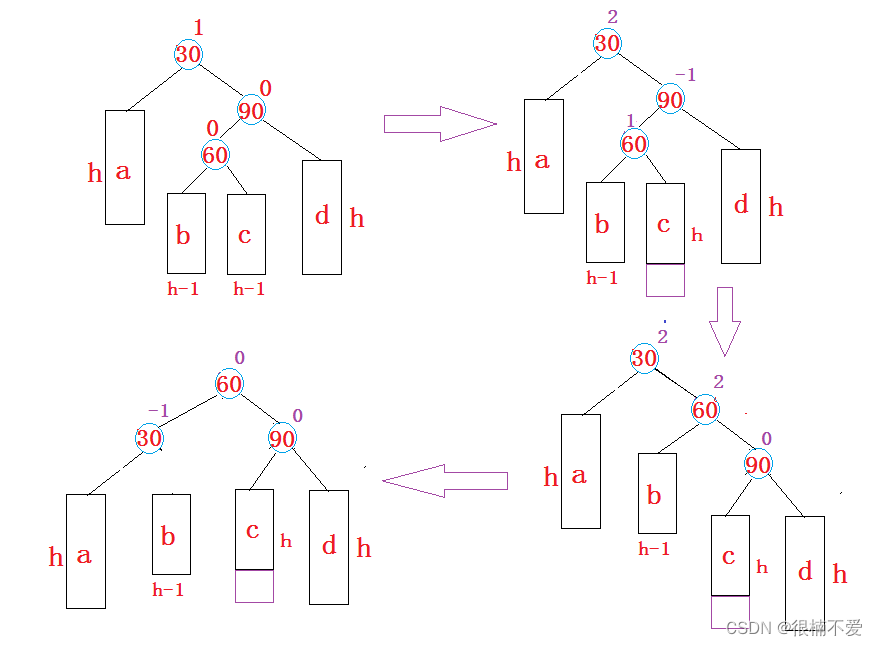
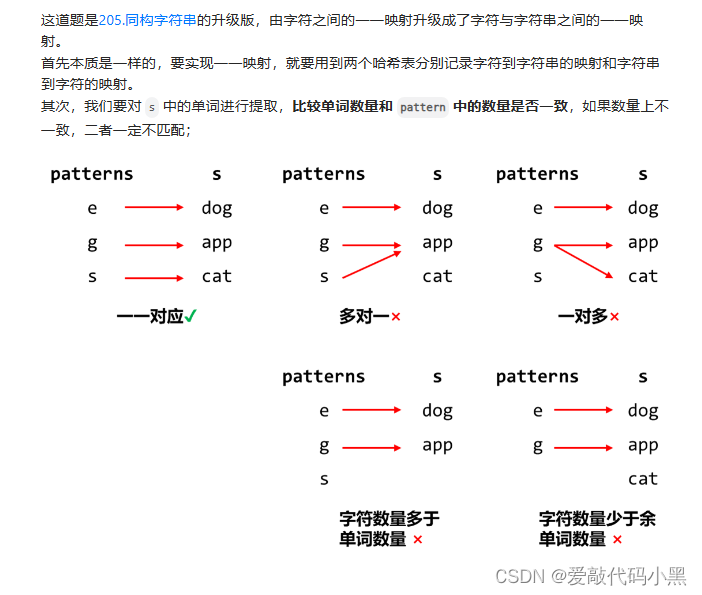
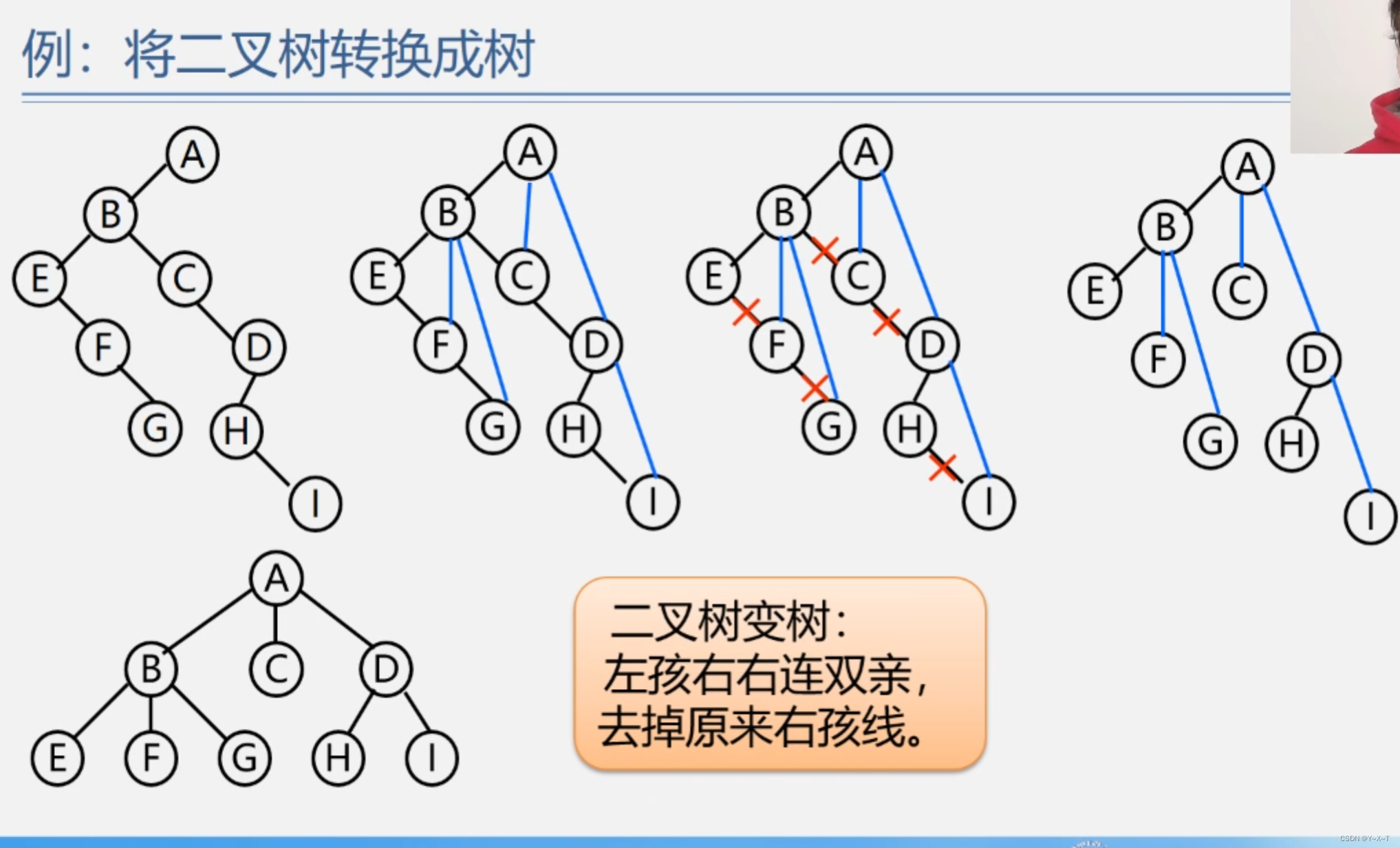
一、研究背景
“绿水青山就是金山银山,要让绿水青山变成金山银山”让人们深刻的意识到环境的重要性。与此同时,由于现代生活水平的不断提高,所带来的环境污染也不断增多,空气以及环境的污染带来了越来越多的疾病,深刻的影响着人们的身体健康。
成都作为四川的省会城市,宜居性是外来人口及本地人口决定是否留下的最重要的因素之一。宜居性除了物价、房价等经济影响因素之外,还有十分重要的一项就是环境,即空气质量的好坏。但是由于给定的数据集中,针对2000-2004年该城市每日的评价空气质量的评价指标只有API(空气污染指数Air Pollution Index,2012年上半年出台规定,将用空气质量指数(AQI)替代原有的空气污染指数(API))。
故本文根据成都市2000-2004年的成都市空气质量指数API构建了相应的ARIMA模型对成都市API进行预测,一方面能够给人们提供宜居性的参考,另一方面也能够对于政府治理环境提供一定依据与环境治理方向。
二、实证分析
本次数据分析的数据来源于全球暖化数据集中的中国城市空气质量日报表(日)的数据,得到数据后,对数据进行了相应的筛选,其数据展示如下:
表1 成都市2000-2004年的API历史数据
| Data | AirQualityLevel | AQI |
| 2000-6-5 | 良 | 83 |
| 2000-6-6 | 良 | 56 |
| 2000-6-7 | 良 | 72 |
| …… | …… | …… |
| 2004-1-9 | 良 | 90 |
API的描述性统计分析
表3 API的描述性统计
| Min. | 1stQu. | Median | Mean | 3rdQu. | Max. |
| 22.00 | 71.00 | 84.00 | 83.36 | 94.00 | 198.00 |
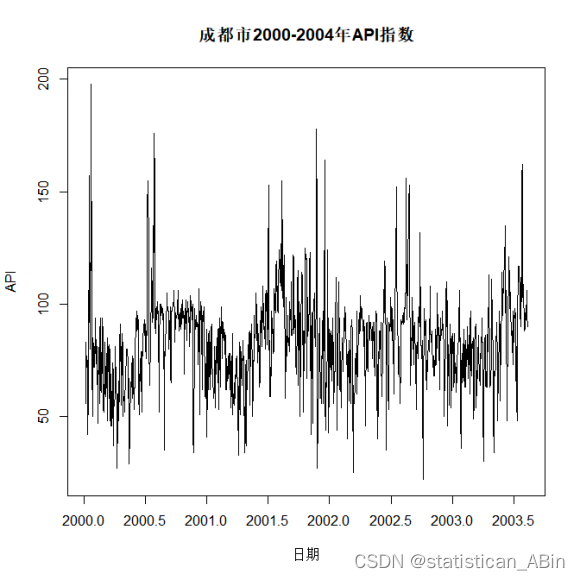
从表3可以看出,对成都市API进行了描述性统计,得到了最大最小值,均值以及1/4分位数和3/4分位数。且下图1画出了四川省成都市2000-6-5至2004-1-9的API的时序图。
library(aTSA)
library(forecast)
library(openxlsx)
library(lmtest)
library(zoo)data<- read.xlsx("成都市API .xlsx", sheet = 1)
datasummary(API)
plot(API,main = "成都市2000-2004年API指数",xlab = "日期",ylab="API")
ARIMA模型的构建
进行ARIMA模型构建之前,要对时间序列数据纯随机性和平稳性检验。可以判断数据是否具有建模的价值以及是否适合ARIMA模型。下面对天气质量指数AQI进行纯随机性检验和平稳性检验结果如下表2和表3:
表4 纯随机检验
| 滞后期数 | 卡方统计量 | P值 |
| 滞后6期P值 | 1158.9 | 0.000 |
| 滞后12期P值 | 1526.3 | 0.000 |
表5 平稳性检验
| 检验形式 | no drift no trend | with drift no trend | with drift and trend |
| ADF统计量 | -2.26 | -6.28 | -6.65 |
| 对应P值 | 0.02 | 0.01 | 0.01 |
#白噪声检验
for(i in 1:2) print(Box.test(API,type = "Ljung-Box",lag=6*i))#绘制自相关图和偏自相关图
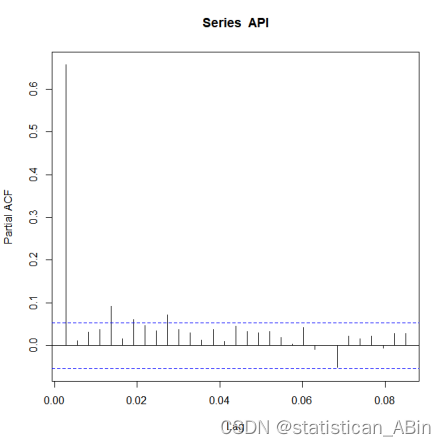
acf(API)
pacf(API)adf.test(API,3)画出API的自相关图和偏自相关图:

下面进行自动定阶的函数,计算得到模型应该采用ARIMA(2,0,0),拟合得到模型系数:
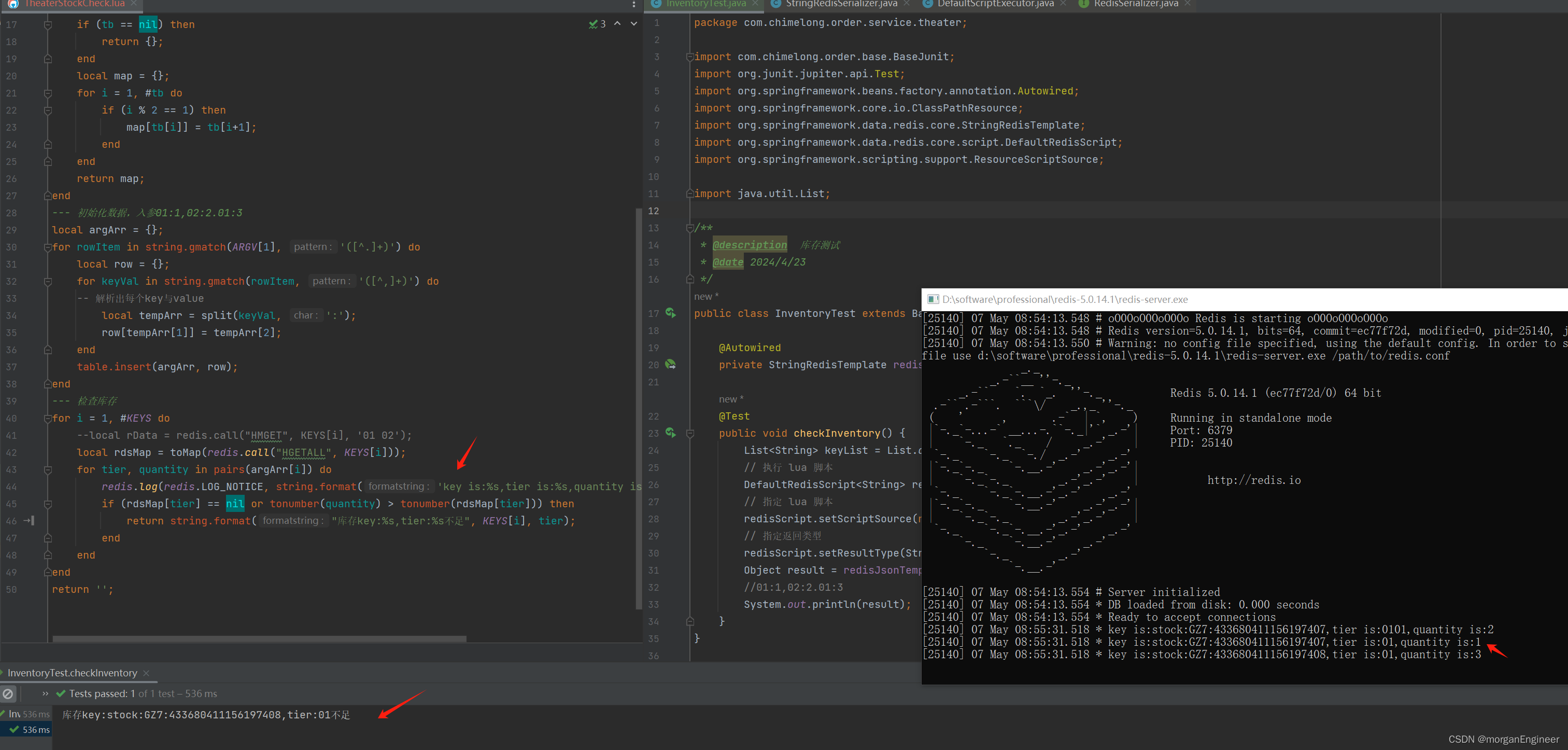
表 模型拟合系数
| Coefficients: | |||
| ar1 | ar2 | intercept | |
| 0.7613 | -0.1172 | 93.5098 | |
| s.e. | 0.1041 | 0.1236 | 6.6908 |
| sigma^2 estimated as 527.9:log likelihood=--423.79 , aic=855.59 | |||
对模型的系数进行检验:
表7 模型系数检验
| 系数 | ar1 | ar2 |
| p值 | 0.00 | 0.00 |
在0.01 的显著性水平下,所有系数都通过了检验,下面进行残差检验:
表8 残差纯随机检验
| 滞后期数 | 卡方统计量 | P值 |
| 滞后6期P值 | 7.8853 | 0.2466 |
| 滞后12期P值 | 26.286 | 0.0098 |
在0.05的显著性水平下,可以看出滞后6期的残差均是白噪音,说明模型拟合的效果良好。
最后进行预测,预测30期,即未来一个月的空气质量数据,得到的整体拟合和预测图如下:
#个性化输出预测图
L1<-x.fore$fitted-1.96*sqrt(x.fit$sigma2)
U1<-x.fore$fitted+1.96*sqrt(x.fit$sigma2)
L2<-ts(x.fore$lower[,2])
U2<-ts(x.fore$upper[,2])
c1<-min(API,L1,L2)
c2<-max(API,L2,U2)
plot(API,type = "p",pch=8,ylim = c(c1,c2))
lines(x.fore$fitted,col=2,lwd=2)
lines(x.fore$mean,col=2,lwd=2)
lines(L1,col=4,lty=2)
lines(L2,col=4,lty=2)
lines(U1,col=4,lty=2)
lines(U2,col=4,lty=2)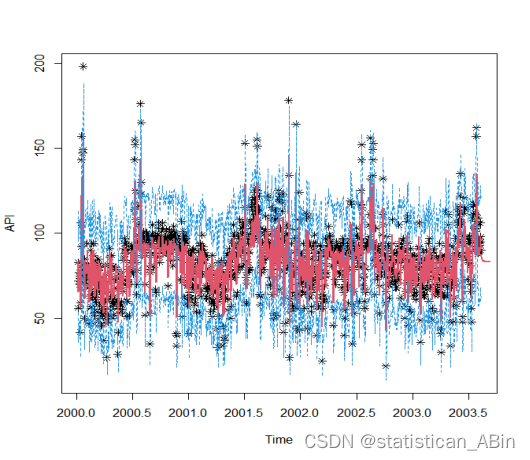
三、结论
就我国随着经济发展与工业化发展所带来的空气质量污染问题,本文通过ARIMA预测模型对空气质量指数进行分析和预测研究。在进行空气质量指数预测时,我们发现通过ARIMA模型可以对其进行较为良好的预测。