本文由Markdown语法编辑器编辑完成.
写作时长: 2024.05.07 ~
文章字数: 1868
1. 前言
最近我负责的一个服务,在医院的服务器上线一段时间后,利用docker logs查看容器的运行日志时,发现会有一个"莫名其妙"的报错.报错的大致内容就是,celery的进程,在运行时需要记录日志时,提示找不到某一个日期的日志文件.在下面的截图中,是找不到: /app/logs/xxxx.log.2024-04-19的文件.
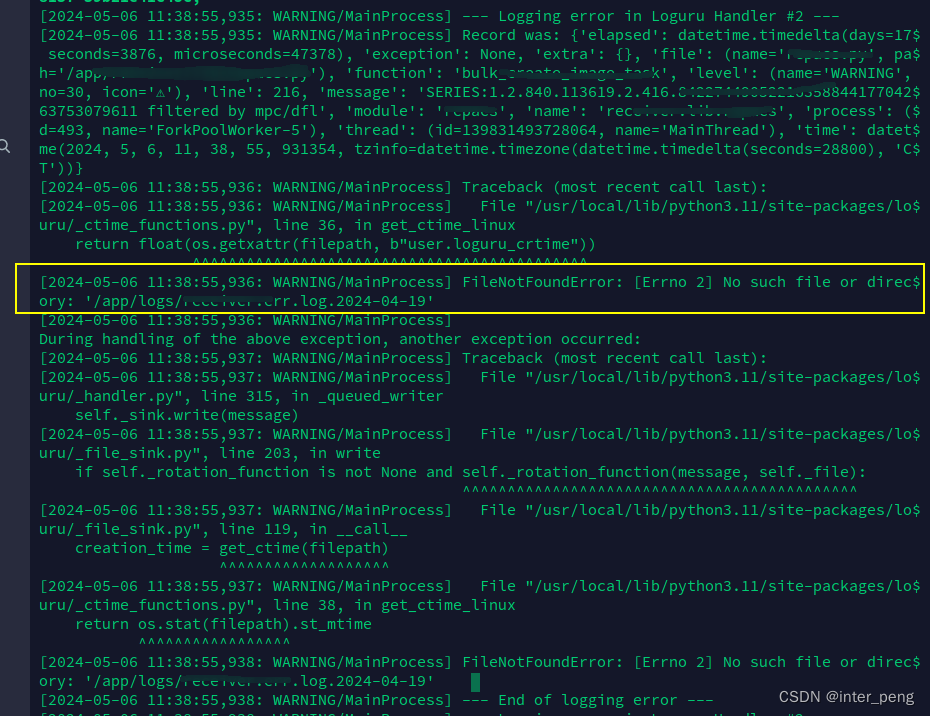
而且,这个日期,不是一个固定的数字,也看不出什么规律来.
不是loguru配置里面的,保留1 week内的7天.总之就是不知道怎么突然有这么个日期.
每家医院报错时的日期,都不同.有的甚至是,1个月, 2个月前的某一天.
虽然这个报错,并未影响程序的正常运行.但是,对于需要在线查看和定位问题时,会造成极大的干扰.因为,几乎每一个loguru.info()都会抛出这么一长串的报错.
因此,在某一天,我决定必须要解决掉这个bug.
我又开始了寻找病因的过程.
以下,我来介绍这个问题的原因和后来的解决方案.
2. 重现问题
程序员解决bug, 和医生看病有一个区别就是:程序员要解决这个bug, 最好是能够让这个bug,在某种情况下可以稳定复现.
这样,在修复代码后,可以通过重现这个场景,来验证这个问题,是否真得得到解决.
但医生给病人看病,总不能让病人,再从健康状态来一遍,看怎么再复现这个生病的状态.
2.1 场景1
遇到日志翻转的报错,最容易想到的问题是,多进程在同时记录日志时,可能一个进程在记录日志,刚才跨越零点,将日志文件翻转,生成了一个新的文件;但是,其他进程,由于那个时刻未工作,导致没有翻转日志,因此,它还是要寻找翻转前的那个日志文件.
结果由于第一个进程,已经把日志进行了翻转,比如日期是2024年5月6日,23:59:59, 刚才零点后,就会生成一个: info.log.2024-05-06的文件.
而00:00之后的日志,则会记录在新的日志文件: info.log里面.
于是,我通过修改系统时间,修改为23:59:00.然后启动容器后,同时发很多图,尽量让多进程的每个进程都在工作,以尽量复现这样的情况.
但经过多次的修改系统时间,和重新发图,仍然没有触发这个报错.
2.2 场景2
观察到的现象是,只有在docker logs -f xxx的时候,才会有这个报错,且这个报错,又不会阻塞多进程的正常工作.
为了能够看到在这个时刻,每个多进程的输出日志,我在loguru的terminal的配置中,增加了一些输出.修改如下:
from loguru import logger as loguru_logger# 日志文本文件中,每一行日志的格式.
LOG_FILE_FORMAT = ("{time:YYYY-MM-DD HH:mm:ss.SSS}/{level}/{module}.{function}:{line}|{process.name}({process.id})|{message}"
)# 容器运行时,输出到terminal中的日志格式.
LOG_STDOUT_FORMAT_WITH_COLOR = ("<green>{time:YYYY-MM-DD HH:mm:ss.SSS}</green> ""<level>{level: <8}</level> <cyan>{module}</cyan>.<cyan>{function}</cyan>:<cyan>{line}</cyan> <cyan>{process.id}</cyan> |<bold><blue>{process.name}({process.id})</blue></bold>| <level>{message}</level>"
)
相比较之前的,我在LOG_STDOUT_FORMAT_WITH_COLOR中,额外增加了两个字段:
<cyan>{process.id}</cyan> |<bold><blue>{process.name}({process.id})</blue></bold>
这样,在docker logs -f , 查看容器运行的日志时,就可以看到,当前输出日志的,进程的name, 和进程的id.
也就是我增加的这两个关键内容,帮助我找到了问题所在.
未完待续…