1. 任务目标
利用循环冗余校验(CRC)检测错误。
循环冗余校验(英语:Cyclic redundancy check,通称 CRC)是一种根据网上数据包或计算机文件等数据产生简短固定位数校验码的一种散列函数,主要用来检测或校验数据传输或者保存后可能出现的错误。生成的数字在传输或者存储之前计算出来并且附加到数据后面,然后接收方进行检验确定数据是否发生变化。一般来说,循环冗余校验的值都是32位的整数。由于本函数易于用二进制的计算机硬件使用、容易进行数学分析并且尤其善于检测传输通道干扰引起的错误,因此获得广泛应用。此方法是由W. Wesley Peterson于1961年发表。
2. 需要编写的程序
crc_encoder:利用 CRC 将数据字转换为码字。
crc_decoder:在恢复数据字的同时,检测是否存在错误。
3. 详细说明(请仔细阅读并按照指示实现)
3.1. crc_encoder
(1) crc_encoder 应按以下方式运行
./crc_encoder input_file output_file generator dataword_size要传递给程序的参数有4个,如下所示:
- input_file:要传输的文件
- output_file:用CRC编码的要传输的文件
- generator:CRC的生成多项式
- dataword_size:数据字的大小。在 crc_encoder 中,应将文件划分为数据字的大小,并将每个数据字转换为码字,单位为 bit。
如果参数数量不匹配,则输出以下消息并退出,usage:
./crc_encoder input_file output_file generator dataword_size(2) 如果无法打开 input_file,则输出以下消息并退出:
input file open error.(3) 如果无法打开 output_file,则输出以下消息并退出:
output file open error.dataword_size 只支持 4 或 8。如果不是 4 或 8,则输出以下消息并退出。
dataword size must be 4 or 8.(5) crc_encoder 将从输入文件中读取的数据分割为 dataword 大小。
- 举个例子,假设输入文件中只有一个字符 'A'。'A' 的 ASCII 码为 65,在二进制中表示为 01000001。因此,第一个 dataword 是 '0100',第二个 dataword 是 '0001'。
(6) 将每个 dataword 转换为 codeword。为此,执行如下的模二除法以获得余数。
- 假设程序的参数中给定的 generator 是 '1101'。
- 第一个 dataword 是 '0100'。
- 由于 generator 是四位数,所以在 dataword 后面添加 '000'。
- 使用模二除法将 '0100000' 除以 '1101'。
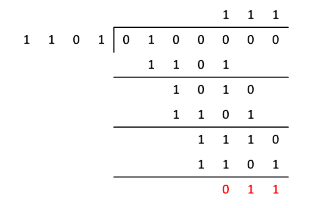
- 余数为 '011',因此将其附加在 dataword 后面以生成 codeword。
- dataword '0100' 的 codeword 是 '0100011'。
- 其余的 dataword 也以相同的方式转换为 codeword。
(7) 使用 CRC 转换后的 codeword 必须写入输出文件。然而,一个问题是,由于 codeword 不是 8 的倍数,所以文件大小可能不会以字节为单位对齐。
- 例如,一个由一个字符 'A' 组成的文件的内容是 8 位,但是使用 4 位的生成器将其转换为 codeword 后,总共有 14 位。由于文件是按字节写入的,因此需要将其转换为 16 位(2 字节),为此使用零填充。
填充可以放在前面或后面,这里选择放在前面。
- 将 'A' 按照 4 位一组转换为 codeword 后得到 '01000110001101'。因此,需要添加两位填充,以使其达到 16 位,因此在前面添加两个零。结果是 '0001000110001101'。前两位不是 codeword 的位,而是填充位。
接收者需要对编码文件进行解码,为此需要知道填充位的数量。因此,将输出文件的第一个字节设置为表示填充位数量的字节。
在上述示例中,由于填充位数量为 2,因此输出文件的第一个字节为 '00000010'。
因此,一个由一个字符 'A' 组成的输入文件经过 crc_encoder 程序处理后,输出文件的内容如下。这里使用二进制表示值。
00000010 00010001 10001101 3.2 cre_decoder
(1) crc_decoder 应按以下方式运行:
./crc_decoder input_file output_file result_file generator dataword_size 程序的参数总共有 5 个,如下所示:
- input_file:经过 CRC 编码的文件
- output_file:删除 CRC 并恢复原始数据的文件
- result_file:显示总帧数和出错帧数的文件
- generator:CRC 的生成器
- dataword_size:dataword 的大小,单位是 bit。
如果参数数量不匹配,则输出以下消息并退出:
usage: ./crc_decoder input_file output_file result_file generator dataword_size(2) 如果无法打开 input_file,则输出以下消息并退出:
input file open error.(3) 如果无法打开 output_file,则输出以下消息并退出:
output file open error.(4) 如果无法打开 result_file,则输出以下消息并退出:
result file open error.(5) 如果 dataword_size 不是 4 或 8,则输出以下消息并退出:
dataword size must be 4 or 8.(6) 首先,crc_decoder 读取输入文件的第一个字节以确定填充的大小。
(7) 然后,crc_decoder 从第二个字节中移除填充。
(8) 接下来,将剩余的位数按照 codeword 的大小进行划分。
- 例如,如果输入文件是 '00000010 00010001 10001101',则从第一个字节得知填充大小为 2 位。然后,忽略第二个字节的前两位 '00',然后将剩余位数划分为 codeword。这样就得到了两个 codeword,'0100011' 和 '0001101'。
(9) 对于每个 codeword,使用生成器进行模二除法,以确定是否存在错误。记录总的 codeword 数量和出现错误的 codeword 数量。
(10) 无论 codeword 是否存在错误,都将其恢复为 dataword 并写入输出文件。
(11) 在结果文件中记录总的 codeword 数量和出现错误的 codeword 数量。例如,如果总的 codeword 数量为 23 个,其中有 5 个出现错误,则结果文件应该写入一行,如下所示:
23 5- 首个填充字节和填充位不包含在总的 codeword 数量或有错误的 codeword 数量中。
3.3. linksim
linksim 是以二进制格式提供的程序,而不是作为作业要求实现的程序。
要运行 linksim,执行以下操作:
./linksim inputfile outputfile error_ratio(0-1) seed_numinput file 是经过介质传输之前的文件,而 output file 是经过介质传输后的文件。
error_ratio 表示每个比特的错误率。例如,如果 error_ratio 为 0.1,则表示每个比特出现错误的概率为 10%。error_ratio 的取值范围应为 0 到 1 之间。
seed_num 是随机数生成器的种子值。如果将其设置为相同的值,则随机数的序列相同;如果设置为不同的值,则序列不同。
3.4 运行顺序
已经完成了 crc_encoder 和 crc_decoder 的实现后,接下来可以这样测试。
假设数据存储在名为 datastream.tx 的文件中。
>> ./crc_encoder datastream.tx codedstream.tx 1101 4
>> ./linksim codedstream.tx codedstream.rx 0.0 1001
>> ./crc_decoder codedstream.rx datastream.rx result.txt 1101 4 由于在此处将 linksim 的错误率设为 0,因此如果程序没有错误,datastream.tx 和 datastream.rx 应完全匹配。
对于 result.txt,由于没有错误,第二个数字应为 0,而第一个数字在 dataword 大小为 4 时应为初始输入文件大小的两倍,在 dataword 大小为 8 时应为初始输入文件大小。
在上述示例中,如果 datastream.tx 为 42 字节,则 result.txt 应如下所示:
84 23表达的意思是:共发送了 84 个码字,其中 23 个被检测出错误。
💬 crc_encoder:
#include <iostream>
#include <vector>
#include <string>
#include <bitset>
#include <cmath>
#include <list>
#include <fstream>
#include <stdlib.h>
#include <cstring>
using namespace std;
#define ARGC_5 5// Most Significant Bit
int GetMSB(int nums) {if (0 == nums) { // 检查x是否为0,避免对0取对数return 0;}// MSB = ⌈ log_2(x) ⌉int ret = static_cast<int> (ceil(log2(nums)));return ret;
}int main(int argc, char *argv[]) {int gen_sz = 0;string init_gen;int generator = 0;int data_word_sz = 0;int len = 0;int i = 0;int j = 0;int sz = 0;if (ARGC_5 != argc) {printf("usage: ./crc_encoder input_file output_file generator data_word_sz");exit(0);}ifstream readFile;readFile.open(argv[1]);string input_file = "";string line;// input_file 打开失败if (!readFile.is_open()) { cerr << "input file open error." << endl;exit(0);}else {for (std::string line; getline(readFile, line); input_file += line, input_file += "\n");input_file = input_file.substr(0, input_file.length() - 1);readFile.close();}// output_file 打开失败ofstream outfile(argv[2], ios::out | ios::binary);if (!outfile) {cerr << "output file open error." << endl;exit(0);}// data_word_sz大小不是4也不是8的情况string ds = argv[4];if (ds != "4" && ds != "8") {cerr << "dataword size must be 4 or 8." << endl;exit(0);}gen_sz = strlen(argv[3]);init_gen = argv[3];generator = (bitset<32>(init_gen)).to_ulong();data_word_sz = atoi(argv[4]);len = input_file.length();vector<string> bits_in_str; string plus_for_divide = "";i = 0;while (i < GetMSB(generator) - 1) {plus_for_divide += '0';i++;}i = 0;while (i < len) {bitset<8> bit(input_file[i]);string bit_string = bit.to_string();int j = 0;while (j < 8) {bits_in_str.push_back(bit_string.substr(j, data_word_sz) + plus_for_divide);j += data_word_sz;}i++;}string all_generator = (bitset<8>(generator)).to_string();string real_generator;i = 0;int gen_sz = all_generator.size();while (i <= gen_sz) {if ('1' != all_generator[i]) {i++;}else {real_generator = all_generator.substr(i, all_generator.size() - i);break;}}vector<string> fc;i = 0;int bitsz = bits_in_str.size();while (i < bitsz) {string a = bits_in_str[i];bitset<16> data = bitset<16>(a);bitset<16> __div = bitset<16>(generator);string baoliu = "";__div = __div << (16 - GetMSB(generator));data = data << (16 - (data_word_sz + GetMSB(generator) - 1));string strdata = data.to_string();j = 0;while (j < data_word_sz) {if (strdata[j] != '1') {__div = __div >> 1;j++;}else {data = data ^ __div;strdata = data.to_string();}}baoliu = data.to_string();baoliu = baoliu.substr(data_word_sz, GetMSB(generator) - 1);a = a.substr(0, data_word_sz) + baoliu;fc.push_back(a);i++;}int padding_size = 0;int sum = (data_word_sz + GetMSB(generator) - 1) * fc.size();padding_size = 16 - (sum % 16);string zero_padding;i = 0;while (i < padding_size) {zero_padding += '0';i++;}bitset<8> bit_padding_size(padding_size);bitset<8> bit_zero_padding(zero_padding);string fc_string = "";i = 0;int fc_sz = fc.size();while (i < fc_sz) {string a = fc[i];fc_string += a;i++;}string final_output = bit_padding_size.to_string() + zero_padding + fc_string;size_t ui = 0;int fo = final_output.length();while (ui < fo) {string byte_str = final_output.substr(ui, 8);bitset<8> byte(byte_str);unsigned char c = static_cast<unsigned char>(byte.to_ulong());outfile.write(reinterpret_cast<const char*>(&c), sizeof(c));ui += 8;}outfile.close();return (0);
}
💬 crc_decoder:
#include <iostream>
#include <vector>
#include <cmath>
#include <list>
#include <fstream>
#include <stdlib.h>
#include <cstring>
#include <string>
#include <bitset>
#define ARGC_6 6
using namespace std;// time 21:33
int GetMSB(int nums);
int main(int argc, char*argv[]) {char byte = 0;int gen_sz = 0;string init_gen;int generator = 0;int dataword_size = 0;int all_num = 0;int fail_num = 0;int i = 0;int j = 0;int k = 0;int zero_sz = 0;int sz = 0;// processCRC(argv[1], argv[2], argv[3], argv[4], argv[5]);if (ARGC_6 != argc) {printf("usage: ./crc_decoder input_file output_file result_file generator dataword_size");exit(0);}string input_string;byte = 0;ifstream input_file;input_file.open(argv[1], ios::binary);string line;if (!input_file.is_open() ) {cerr << "input file open error." << endl;exit(0);}else {for (char byte; input_file.get(byte);) {bitset<8> bits(byte);input_string += bits.to_string();}input_file.close();}ofstream outfile;outfile.open(argv[2]);if (!outfile) {cerr << "output file open error." << endl;exit(0);}ofstream resultfile;resultfile.open(argv[3]);if (!resultfile) {cerr << "result file open error." << endl;exit(0);}string a4 = argv[5];if (a4 != "4" && a4 != "8") {cerr << "dataword size must be 4 or 8." << endl;exit(0);}gen_sz = strlen(argv[4]);init_gen = argv[4];generator = (bitset<32>(init_gen)).to_ulong();dataword_size = atoi(argv[5]);all_num = 0;fail_num = 0;bitset<8> bit_zero_sz(input_string.substr(0, 8));zero_sz = (bitset<8> (input_string.substr(0, 8)) ).to_ulong();k = dataword_size + GetMSB(generator) - 1;vector<string> re_word;all_num = (input_string.length() - 8 - zero_sz) / 7;i = 0;int max_it = (input_string.length() - 8 - zero_sz) / (dataword_size + GetMSB(generator) - 1);while (i < max_it) {string substr = input_string.substr(8 + zero_sz + i * k, dataword_size);re_word.push_back(substr);string x = input_string.substr(8 + zero_sz + i * k, k);bitset<16> bit_str(x);bitset<16> div(generator);bit_str = bit_str << 16 - k;div = div << 16 - GetMSB(generator);string strdata = bit_str.to_string();j = 0;while (j < dataword_size) {if (strdata[j] != '1') {div = div >> 1;++j;}else {bit_str = bit_str ^ div;strdata = bit_str.to_string();}}if (0 == bit_str.to_ulong()) {i += 1;}else {fail_num++;}}string reborn = "";i = 0;sz = re_word.size();while (i < sz) {string a = re_word[i];reborn += a;i++;}string end_str = "";j = 0;sz = reborn.length();while (j < sz) {bitset<8> y(reborn.substr(j, 8));char z = char(y.to_ulong());end_str += char((bitset<8>(reborn.substr(j, 8)).to_ulong()));j += 8;}outfile << end_str << endl;resultfile << all_num << " " << fail_num << endl;return( 0);
}int GetMSB(int nums) {if (0 == nums) {return 0;}// MSB = ⌈ log_2(x) ⌉int ret = static_cast<int> (ceil(log2(nums)));return ret;
}