引入
什么是神经网络?
我们今天学习的神经网络,不是人或动物的神经网络,但是又是模仿人和动物的神经网络而定制的神经系统,特别是大脑和神经中枢,定制的系统是一种数学模型或计算机模型,神经网络由大量的人工神经元连接而成,大多数时候人工神经网络能够在外界信息的基础上改变内部结构,是一种自适应的改变的过程,现代的神经网络是一种基于传统统计学的建模工具,常用来对输入和输出之间复杂的关系进行建模或者探索数据之间的模式
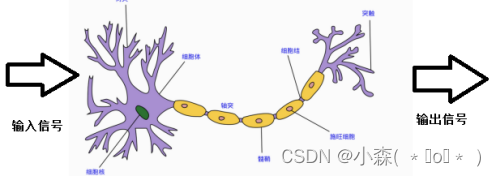
人或动物的神经元如下,当人感受到刺激的时候,信号会通过传道部传递信号,最后会作用在效应部做出相应的反应。神经网络是一种运算模型,有大量的节点,神经元节点之间构成了联系,这些神经元负责传递信息和加工信息,神经元可以被训练和强化,形成一种固定的形态,对一些特殊的信息会有更强烈的反应。

这张图片是一张古风女士的图片,因为在我们的生活中的经验已经告诉我们人的模样,椅子的样子,衣服的模样。
所以通过我们强大的成熟的视觉神经系统判定她是一个古风女孩。
计算机系统和人脑一样,也是通过不断训练,告诉计算机那些是猫,那些是狗,会通过一个数学模型来得到结果。比如:百度图片搜索就能识别图片的物体,地点以及其他信息,都归功于计算机神经系统的突破发展。
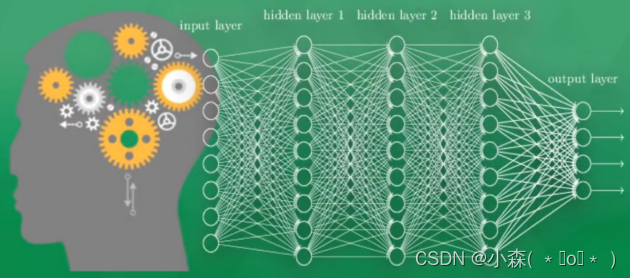
一个可视化的神经网络系统,由多层的神经元组成,为了区分不同的神经层,我们通常将输入信息的叫做输入层,中间传递信息叫做隐藏层或隐层,输出层就是将前面传递的信息形成输出的结果,通过该结果能直接看到计算机对物体的认知,隐层通常由1层或多层组成,负责输入层的加工信息的处理,类似于人类的神经系统,通过多层的神经加工才能达到最后的效果。
一个可视化的神经网络系统,由多层的神经元组成,为了区分不同的神经层,我们通常将输入信息的叫做输入层,中间传递信息叫做隐藏层或隐层,输出层就是将前面传递的信息形成输出的结果,通过该结果能直接看到计算机对物体的认知,隐层通常由1层或多层组成,负责输入层的加工信息的处理,类似于人类的神经系统,通过多层的神经加工才能达到最后的效果。
现在的深度学习就是从神经网络发展而来,当神经网络中间的隐层非常之多的时候可处理的信息也会非常之多,这也是叫深度神经网络的原因。当隐藏层只有1个时候,是神经网络中的“BP神经网络”模型,而没有隐层,只有输入输出层的是最简单的“感知机”分类模型。
- 感知机由输入层和输出层组成,没有隐藏层。它接收多个输入信号,通过加权求和后,如果超过某个阈值,则输出一个信号,这种结构使其成为一个线性分类器。
- 感知机通过错误修正算法来更新权重。当模型做出错误预测时,它会调整权重以减少未来的错误。
感知机作为神经网络的基础,虽然简单,但为理解更复杂的神经网络模型提供了重要的起点。
通常计算机能看到的和处理的和人类会有很大的不同,比如图片和声音、文字,他们在计算机中均已0或1的方式存在再神经网络中,通过对这一些0-1数字的加工和处理生成另外一些数字,而生成的数字也有了物理上的意义了。
神经网络训练的过程
首先,需要准备大量的数据集,进行上千万次的训练,但是计算机不一定能识别正确,比如一张图原来是猫的被识别成了狗,虽然识别错误了,但是这个错误是非常有价值的,我们可以从这次错误中总结和学习经验,计算机一般是根据正确的答案和预测的答案做对比产生一个差别,在将这个差别反向传递回去,每一个神经元往正确的方向上改动一点点,这样下一次识别的时候,通过已经改进的神经网络识别的正确率会提高一些,将每次一点点的提高加上上千万次的训练,最终的识别效果也就被提高了,最后到了验收结果的时候原来是猫现在也被识别为猫。
计算机中的每个神经元都有属于他的激励函数,我们可以利用这些函数给计算机一个刺激行为。
当第一次给计算机看猫的图片的时候,只有部分神经元被激励或激活,被激活的神经元会传递给下一级别的神经元,这些传递的信息也是计算机中最为重要的信息,也就是对输出结果最优价值的信息,如果预测成了狗狗,那么神经元的一些参数就会被调整,有一些神经元变得迟钝,有一些则变得敏感起来,这就说明所有神经元参数都在被改变,往识别正确的方向去改变了,被改动的参数也能逐渐的预测出正确的答案,这就是神经网络的过程。
感知机
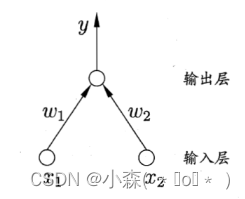
感知机只有输出层神经元进行激活函数处理,即只拥有一层功能神经元,学习能力非常有限,感知机的学习皆在求将训练数据进行线性划分的分离超平面。为此,导入基于误分类的损失函数,利用梯度下降法对损失函数进行极小化,求得感知机模型。
激励函数
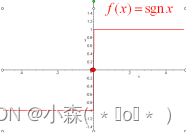

BP神经网络
BP中采用的梯度求解最优参数的方法是最常用的方法,但是如果误差函数在当前点的梯度为0,已达到了局部最小,更新量将为0,这意味着迭代将会停止,但此时如果误差函数仅仅有一个局部的最小,那么此时的局部最小将变为全局最小;如果误差函数有多个局部最小,则不能保证找到的解释全部最小,这种情形也是参数陷入局部最小的情况。
- 以不同的参数值初始化多个网络,按不同方法标准化训练后,取最小的解作为最终参数。这相当于从多个不同的初始点开始搜索,这样就可能陷入不同的局部最小,从中选择可能更接近全局最小的结果。
-
使用“模拟退火”技术在每一步都以一定的概率接受比当前更差的结果,从而有助于跳出局部最小。在每次迭代的过程中,接受“次优解”的概率要随着时间的推移而逐渐降低,从而保证算法的稳定性。
- 使用随机梯度下降。与标准的梯度下降算法精确计算梯度不同。随机梯度下降法在计算梯度的时候加入了随机因素。即便陷入了局部最小值点,它计算的梯度仍不可能为0,这样就跳出了局部最小搜索。
梯度下降法
找到一个抛物线的最低点:
首先求导,令导数为0,求值。l为学习率,为(0,1]的值,设置的小,需要很长时间才能到最低点。设置的大,可能错过最低点。一般设置的时候首先设置的大一些,等到快接近最低点步子放慢一些。
import numpy as np
def tanh(x): return np.tanh(x)def tanh_deriv(x): return 1.0 - np.tanh(x)*np.tanh(x)def logistic(x): return 1/(1 + np.exp(-x))def logistic_derivative(x): return logistic(x)*(1-logistic(x))class NeuralNetwork: def __init__(self, layers, activation='tanh'): """ :param layers: A list containing the number of units in each layer.Should be at least two values :param activation: The activation function to be used. Can be"logistic" or "tanh" """ if activation == 'logistic': self.activation = logistic self.activation_deriv = logistic_derivative elif activation == 'tanh': self.activation = tanh self.activation_deriv = tanh_derivself.weights = [] for i in range(1, len(layers) - 1): self.weights.append((2*np.random.random((layers[i - 1] + 1, layers[i] + 1))-1)*0.25) self.weights.append((2*np.random.random((layers[i] + 1, layers[i + 1]))-1)*0.25) def fit(self, X, y, learning_rate=0.2, epochs=10000): X = np.atleast_2d(X) temp = np.ones([X.shape[0], X.shape[1]+1]) temp[:, 0:-1] = X # adding the bias unit to the input layer X = temp from NeuralNetwork import NeuralNetwork
import numpy as npnn = NeuralNetwork([2,2,1], 'tanh')
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
y = np.array([0, 1, 1, 0])
nn.fit(X, y)
for i in [[0, 0], [0, 1], [1, 0], [1,1]]: print(i, nn.predict(i))




![[单机]成吉思汗3_GM工具_VM虚拟机](https://img-blog.csdnimg.cn/img_convert/ee9be78a18d7d5bc082500017469ba5b.webp?x-oss-process=image/format,png)