文章目录
- epoll
- select和poll的优缺点
- epoll的原理以及优势
- epoll
- 好的网络服务器设计
- Reactor模型
- 图解Reactor
- muduo库的Multiple Reactors模型
epoll
select和poll的优缺点
1、单个进程能够监视的文件描述符的数量存在最大限制,通常是1024,当然可以更改数量,但由于 select采用轮询的方式扫描文件描述符,文件描述符数量越多,性能越差;(在linux内核头文件中,有 这样的定义:#define __FD_SETSIZE 1024
2、内核 / 用户空间内存拷贝问题,select需要复制大量的句柄数据结构,产生巨大的开销
3、select返回的是含有整个句柄的数组,应用程序需要遍历整个数组才能发现哪些句柄发生了事件
4、select的触发方式是水平触发,应用程序如果没有完成对一个已经就绪的文件描述符进行IO操作, 那么之后每次select调用还是会将这些文件描述符通知进程
相比select模型,poll使用链表保存文件描述符,因此没有了监视文件数量的限制,但其他三个缺点依然存在。
以select模型为例,假设我们的服务器需要支持100万的并发连接,则在__FD_SETSIZE 为1024的情况 下,则我们至少需要开辟1k个进程才能实现100万的并发连接。除了进程间上下文切换的时间消耗外, 从内核/用户空间大量的句柄结构内存拷贝、数组轮询等,是系统难以承受的。因此,基于select模型的 服务器程序,要达到100万级别的并发访问,是一个很难完成的任务。
epoll的原理以及优势
epoll的实现机制与select/poll机制完全不同,它们的缺点在epoll上不复存在。
设想一下如下场景:有100万个客户端同时与一个服务器进程保持着TCP连接。而每一时刻,通常只有 几百上千个TCP连接是活跃的(事实上大部分场景都是这种情况)。如何实现这样的高并发?
- 在select/poll时代,服务器进程每次都把这100万个连接告诉操作系统(从用户态复制句柄数据结构到 内核态),让操作系统内核去查询这些套接字上是否有事件发生,轮询完成后,再将句柄数据复制到用 户态,让服务器应用程序轮询处理已发生的网络事件,这一过程资源消耗较大,因此,select/poll一般 只能处理几千的并发连接。
- epoll的设计和实现与select完全不同。epoll通过在Linux内核中申请一个简易的文件系统(文件系统一 般用什么数据结构实现?B+树,磁盘IO消耗低,效率很高)。把原先的select/poll调用分成以下3个部分:
- 调用epoll_create()建立一个epoll对象(在epoll文件系统中为这个句柄对象分配资源)
- 调用epoll_ctl向epoll对象中添加这100万个连接的套接字
- 调用epoll_wait收集发生的事件的fd资源
如此一来,要实现上面说是的场景,只需要在进程启动时建立一个epoll对象,然后在需要的时候向这 个epoll对象中添加或者删除事件。同时,epoll_wait的效率也非常高,因为调用epoll_wait时,并没有 向操作系统复制这100万个连接的句柄数据,内核也不需要去遍历全部的连接。
//epoll_create在内核上创建的eventpoll结构如下:
struct eventpoll{.... /*红黑树的根节点,这颗树中存储着所有添加到epoll中的需要监控的事件*/ struct rb_root rbr; /*双链表中则存放着将要通过epoll_wait返回给用户的满足条件的事件*/ struct list_head rdlist; ....
};
epoll
epoll重点掌握LT模式和ET模式。
关于这一节可以读以下两篇博客:
IO多路转接(复用)之epoll
epoll边沿模式的非阻塞方法
好的网络服务器设计
陈硕老师的原话:
在这个多核时代,服务端网络编程如何选择线程模型呢? 赞同libev作者的观点:one loop per thread is usually a good model,这样多线程服务端编程的问题就转换为如何设计一个高效且易于使 用的event loop,然后每个线程run一个event loop就行了(当然线程间的同步、互斥少不了,还有其 它的耗时事件需要起另外的线程来做)。event loop 是 non-blocking 网络编程的核心,在现实生活中,non-blocking 几乎总是和 IOmultiplexing 一起使用,原因有两点:
- 没有人真的会用轮询 (busy-pooling) 来检查某个 non-blocking IO 操作是否完成,这样太浪费 CPU资源了。
- IO-multiplex 一般不能和 blocking IO 用在一起,因为 blocking IO 中
read()/write()/accept()/connect()都有可能阻塞当前线程,这样线程就没办法处理其他 socket 上的 IO 事件了。
所以,当我们提到 non-blocking 的时候,实际上指的是 non-blocking + IO-multiplexing,单用其 中任何一个都没有办法很好的实现功能。
更强大的网络服务器Nginx!
采用的是epoll + fork 而不是epoll+pthread!
用多个进程程来监听新链接,不想muduo只有一个线程来监听网络连接
强大的nginx服务器采用了epoll+fork模型作为网络模块的架构设计,实现了简单好用的负载算法,使 各个fork网络进程不会忙的越忙、闲的越闲,并且通过引入一把乐观锁解决了该模型导致的服务器惊群 现象,功能十分强大。
Reactor模型
Reactor模型是一个设计一个高性能网络服务器的常用模型。
The reactor design pattern is an event handling pattern for handling service requests delivered concurrently to a service handler by one or more inputs. The service handler then demultiplexes the incoming requests and dispatches them synchronously to the associated request handlers.
反应堆设计模式是一种事件处理模式,用于处理由一个或多个输入并发传递给服务处理程序的服务请求。然后,服务处理程序对传入的请求进行多路复用,并将它们同步地分派给相关的请求处理程序。
重要组件:Event事件、Reactor反应堆、Demultiplex IO多路复用事件分发器、Evanthandler事件处理器
之后我们主要关注这四个组件的通信即可。
图解Reactor
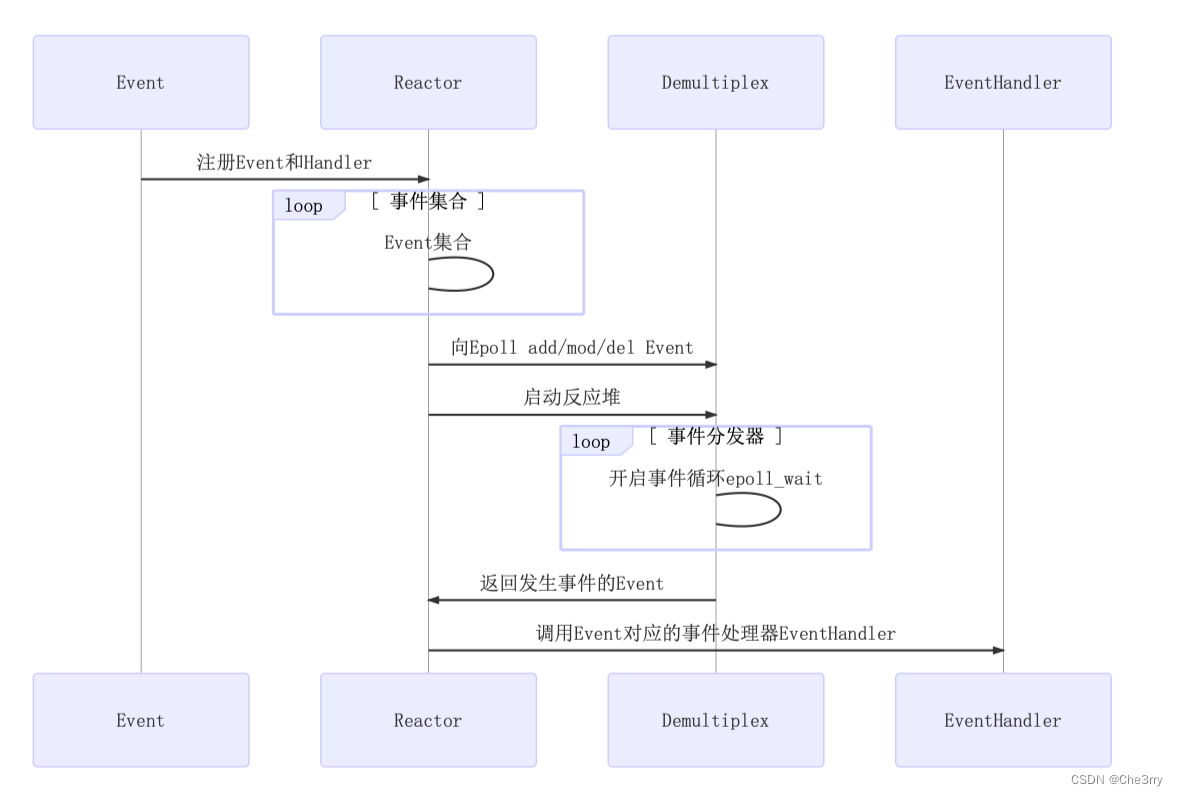
交互流程:
- 首先会把事件注册到反应堆上,所谓的注册指的是应用程序对该事件比较感兴趣,我们请求反应堆帮我来监听我所感兴趣的事件,并且在事件发生的时候调用我预置的回调函数Handler
- 反应堆可以理解为存储了一个Event事件以及事件处理的集合,我们的事件处理可以添加很多的选项,比如事件响应、事件处理等等。每一个Event都对应一个Handler,所以的反应堆就维护了这样一个集合。然后reactor会调用epoll_ctl来设置相关的方法来处理sockfd,这个过程是借助Demultiplex实现。
- 我们这里的Demultiplex用来处理epoll_ctl的相关处理,然后Reactor自己启动反应堆,反应堆的后端就能驱动事件分发器Demultiplex(其实就是开启epoll_wait)的使用,整个服务器呈现出阻塞的状态来等待新用户的链接或者是已连接用户的读写事件,epoll_wait监听到了新事件产生,Demultiplex会把事件给反应堆返回。
为什么Demultiplex会返回给Reactor呢,因为事件Event发生后,我们需要调用对应的事件处理器Handler,这是我们注册在Reactor中的
- 最后对于发生事件的Event,我们就通过一个Map表来找到该事件Event对应的那个EventHandler,最后处理该任务。
muduo库的Multiple Reactors模型

在muduo网络库中,Reactor中已经集成了Demultiplex IO多路复用事件分发器组件(图片来源见水印)
在 muduo 库中,许多 client 在 MainReactor 中得到了连接请求的响应,并与 WebServer 建⽴具体的连接。然后通过⼀个叫 Acceptor 的模块,将具体的连接分配给到⼀些叫做 SubReactor 的 模块,在 SubReactor 中对具体的连接进⾏读、编码、计算、解码和写操作(即对 client 请求的响应)。
所以改图有一点不准确,Reactor其实就是存储了事件以及事件处理器,仅此而已,所以上图应该画成事件份发器。
![[机器学习-06] | Scikit-Learn机器学习工具包进阶指南:机器学习分类模型实战与数据可视化分析](https://img-blog.csdnimg.cn/direct/0ea10246daa642aa8c6891b5a73ab067.png)





![[AIGC] 压缩列表了解吗?快速列表 quicklist 了解吗?](https://img-blog.csdnimg.cn/img_convert/7c70dfe31cd6cefffd2b2ffcd0dd652d.png)