目录
5 系统详细实现
5.1实现环境配置
5.2功能实现
5.2.1 建立索引
5.2.2 文件搜索实现
5.2.3 数据库的连接配置
5.2.4 数据库搜索实现
5.2.5 后台数据编辑实现
前面内容请移步
搜索引擎的设计与实现(二)
免费源代码&毕业设计论文
搜索引擎的设计与实现
5 系统详细实现
5.1实现环境配置
因为我所选择的搜索引擎是基于Lucene的,所以需要利用Lucene的一些jar包,这样才能借助Lucene完成我们自己想要的搜索功能,并且为了实现分词,我们还需要引用分词组件的相关类库,具体的引用类库如图5-1所示:
图 5-1 Lucene配置
5.2功能实现
5.2.1 建立索引
Lucene对数据的检索是在索引文件中查找的,可能会有人问为什么不直接在数据中检索呢?一个是数据库检索要实现全文检索,实现分词是相当困难的,而且,如果数据量小只有几百几千倒是可以考虑用数据库检索。把数据从数据库里读取出来,写入索引文件的时候是一条一条记录的写入的。
由于Lucene只能替文本这一类型的数据组建索引,所以为了进行其他类型的数据进行检索,只能把其他的格式的数据用文本类型的替换,这样就可以进行索引、搜索了。如果需要对HTML文档进行索引的话,你就首先需要利用文本格式把 HTML文档替换,随后才可以将转化的结果输入 Lucene进行索引与检索,接着就会创建一份索引文件,我们需要把它保存到存储器里面,最终通过判断用户在UI界面输入的查询请求,从建立好的索引文件中查找。
实现代码:
/**
* 为数据库检索数据创建索引
* @param rs
* @throws Exception
*/ private void createIndex(ResultSet rs) throws Exception { Directory directory = null; IndexWriter indexWriter = null; try { indexFile = new File(searchDir); if(!indexFile.exists()) { indexFile.mkdir(); } directory = FSDirectory.open(indexFile); analyzer = new IKAnalyzer(); indexWriter = new IndexWriter(directory, analyzer, true, IndexWriter.MaxFieldLength.UNLIMITED); indexWriter.setMaxBufferedDocs(maxBufferedDocs); Document doc = null; while(rs.next()) { doc = new Document(); Field id = new Field("id", String.valueOf(rs.getInt("id")), Field.Store.YES, Field.Index.NOT_ANALYZED, TermVector.NO); // Field title = new Field("title", rs.getString("title") == null ? "" : rs.getString("title"), Field.Store.YES,Field.Index.ANALYZED, TermVector.NO); Field content = new Field("content", rs.getString("content") == null ? "" : rs.getString("content"), Field.Store.YES,Field.Index.ANALYZED, TermVector.NO); doc.add(id); doc.add(content); indexWriter.addDocument(doc); } indexWriter.optimize(); indexWriter.close(); } catch(Exception e) { e.printStackTrace(); } } 5.2.2 文件搜索实现
文件搜索首先需在设置系统一个搜索文件夹,然后把待搜索的文件放到该文件夹下面,接着输入关键字即可搜索,本系统目前支持搜索的文件格式包括.txt、.doc、.xls和.ppt.
在文件搜索之前需要建立索引,在建立索引的时候对性能影响最大的地方就是在将索引写入文件的时候, 所以在具体应用的时候就需要对此加以控制[4].
在读取文件夹下的文件时,我们是通过FileInputStream对象来完成这一操作的,该对象只需要有一个参数就可以啦,这个参数就是文件的存储路径,如果我们使用FileInputStream来读取文件的话,我们还需要通过利用BufferedReader对象,把文件转换成Buffered的形式存放,最后我们通过IndexSearcher对象来实现文件的搜索:
实现代码:
IndexWriter iwriter = new IndexWriter(directory, analyzer, true,IndexWriter.MaxFieldLength.LIMITED);iwriter.setMaxFieldLength(25000);// Lucene是不可以对除Document文件以外的文件建立索引的,Document只是一个假设文件while ((a = br.readLine()) != null) {Document doc = new Document();doc.add(new Field(fieldName, a, Field.Store.YES,Field.Index.ANALYZED));iwriter.addDocument(doc);}// Field.Store.YES:为该Field值创建索引// Field.Index.TOKENIZED:索引Field的值,使它能够被查到// Field 对象是用来描述一个文档的某个属性的iwriter.close();// 索引对象IndexSearcher isearcher = new IndexSearcher(directory, true);QueryParser parser = new QueryParser(Version.LUCENE_29, fieldName,analyzer);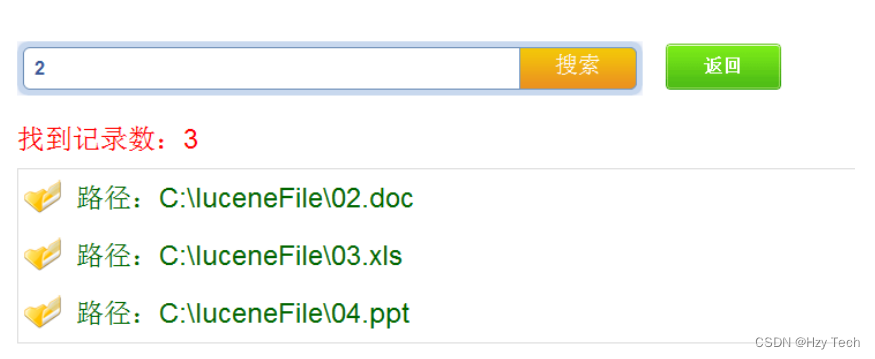
图5-2 文件搜索效果图
5.2.3 数据库的连接配置
相关代码:
Class.forName("com.microsoft.sqlserver.jdbc.SQLServerDriver");String url= "jdbc:sqlserver://localhost:1433; DatabaseName=LuceneDB2";String username = "qian";String password = "wqian";con = DriverManager.getConnection(url, username, password);5.2.4 数据库搜索实现
本模块解决了数据库快速搜索的问题,这个问题其实与文件搜索的原理一样,第一步都是需要创建索引的,当文档的索引创建好之后,就能够进行搜索的任务了。
相关代码:
// 执行sql语句增删改public int updateExecute(String sql) {int result = 0;try {Connection con = getConnection();Statement sta = con.createStatement();result = sta.executeUpdate(sql);} catch (SQLException e) {e.printStackTrace();}return result;}// 执行sql查询语句 返回一个ResultSetpublic ResultSet queryExectue(String sql) {ResultSet rs = null;try {Connection con = getConnection();Statement sta = con.createStatement();rs = sta.executeQuery(sql);} catch (SQLException e) {e.printStackTrace();}return rs;}public String executeScalar(String sql) {ResultSet rs = queryExectue(sql);String s = "";try {while (rs.next()) {s = rs.getString(1);}} catch (SQLException e) {e.printStackTrace();}return s;}这个时候,在前端页面上的用户提交一个关键字的查询请求,而后这个请求将会被自动进行分析处理。最终,系统会将用户的查询指令传输到后台中,并且把检索到的信息资源进行返回,前台一般为显示器,会将检索到的信息进行显示:
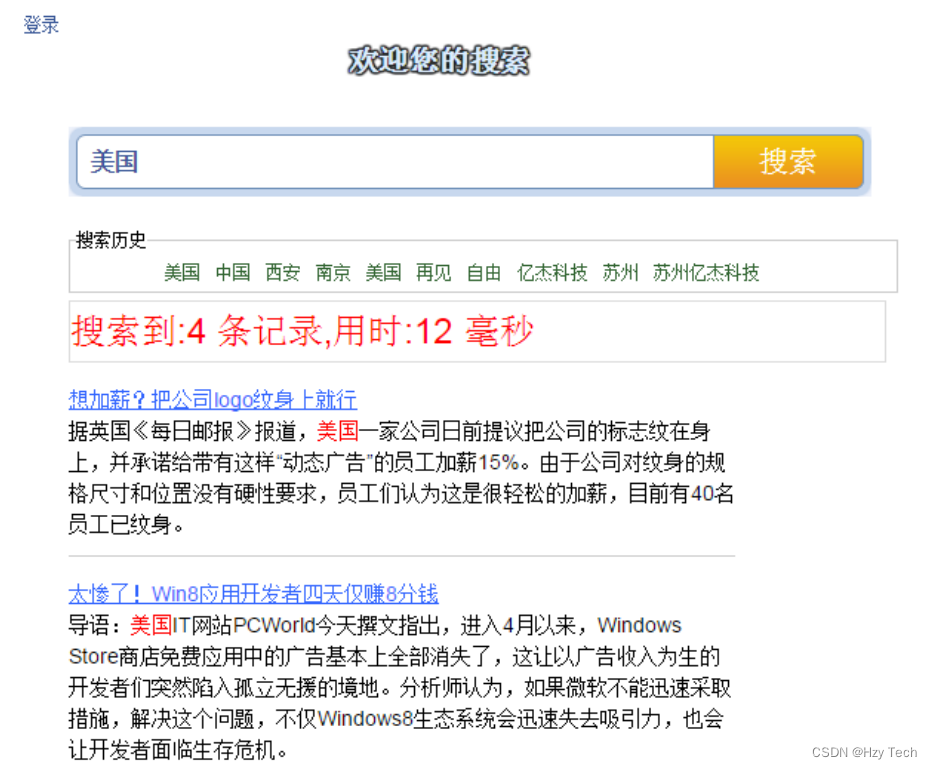
图5-3 检索结果显示图
5.2.5 后台数据编辑实现
管理员可以点击页面的“登录”链接到管理员登录页面,用户在登录页面输入账号和密码即可登录系统,登录后用户可以看到目前系统所有数据,同时也可以修改或者删除任何一条数据可以通过标题来搜索自己想看的数据,也可以通过添加按钮来添加新的数据:

图5-4 后台登录界面