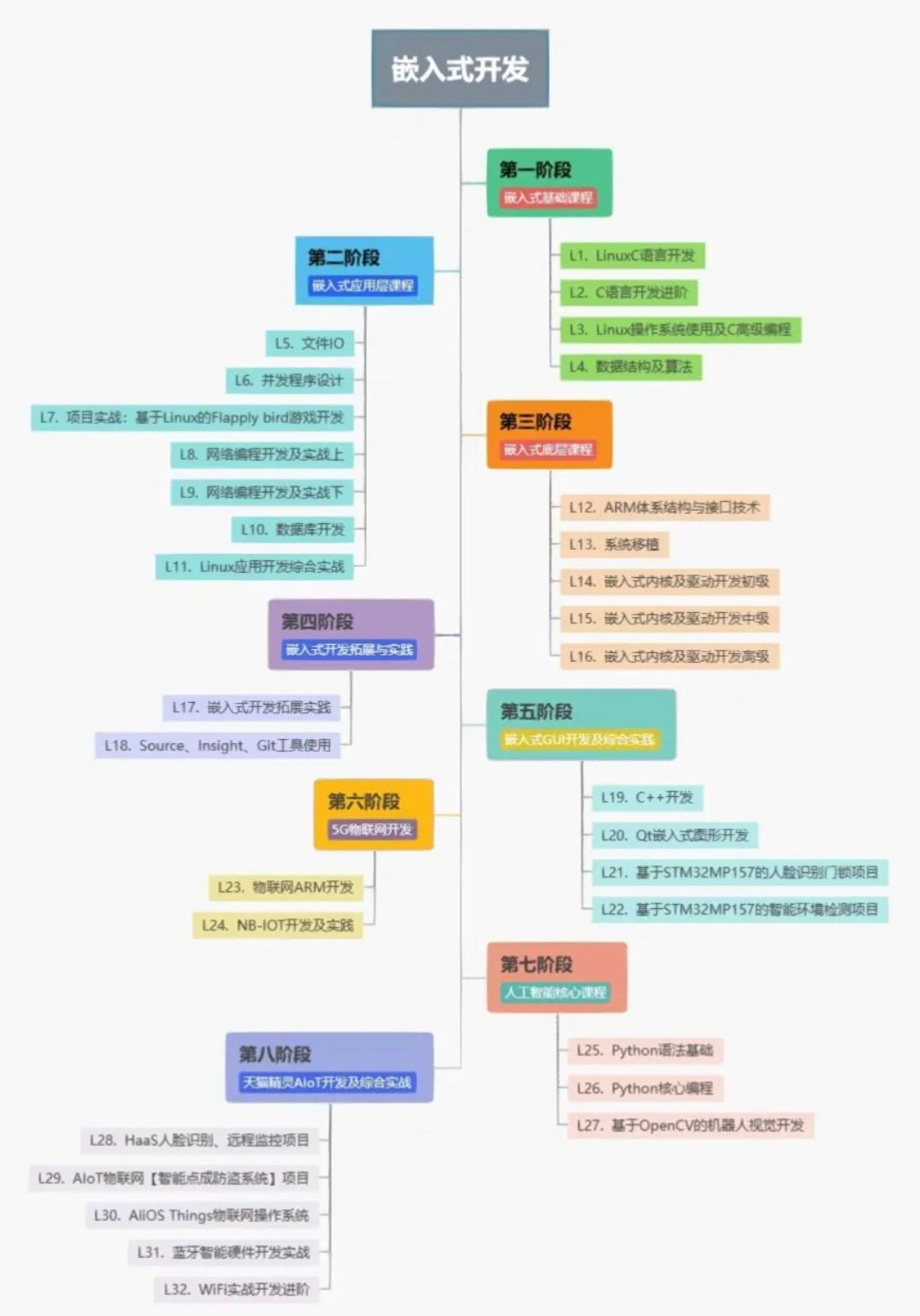
1.明确意义
通过训练集建立模型的意义是对新的数据进行准确的预测(测试集的准度高才代表good fit);
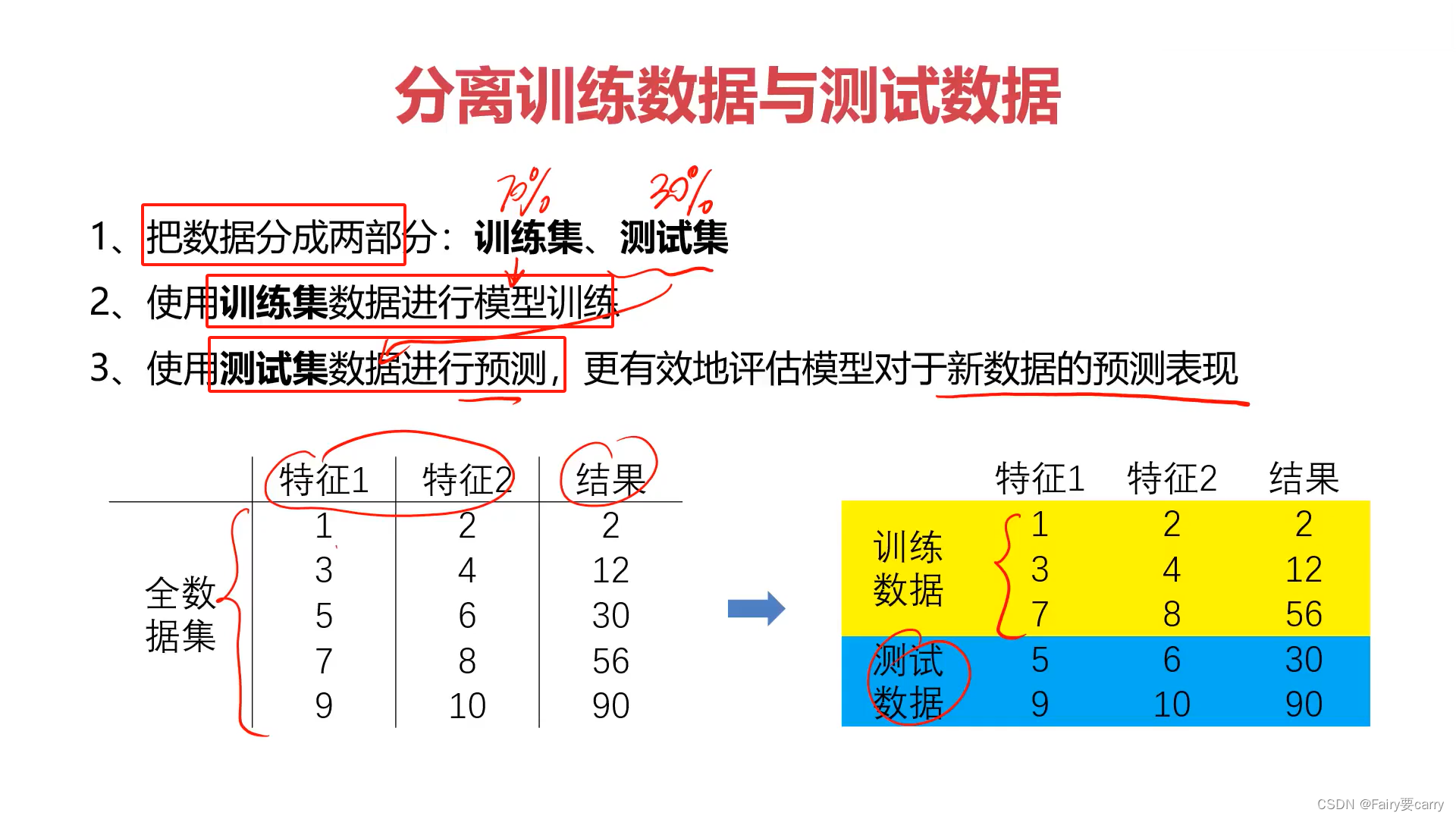
2.评估流程
3.单单利用准确率accuracy进行模型评估的局限性
模型一:一共1000个数据(分别为900个1和100个0),850个1和50个0预测准确(一共两类),所以准确率为(850+50)/1000=90%,而对于每一类:1的类为850/900的准确率;而对于0的类:50/100的准确率;
模型二:一共1000条数据,预测为900个1正确,准确率为900/1000=90%。而对于值为1的类:900/900=1,所以以后的每条数据预测都会为1,这样就会出现空准确率的情况;
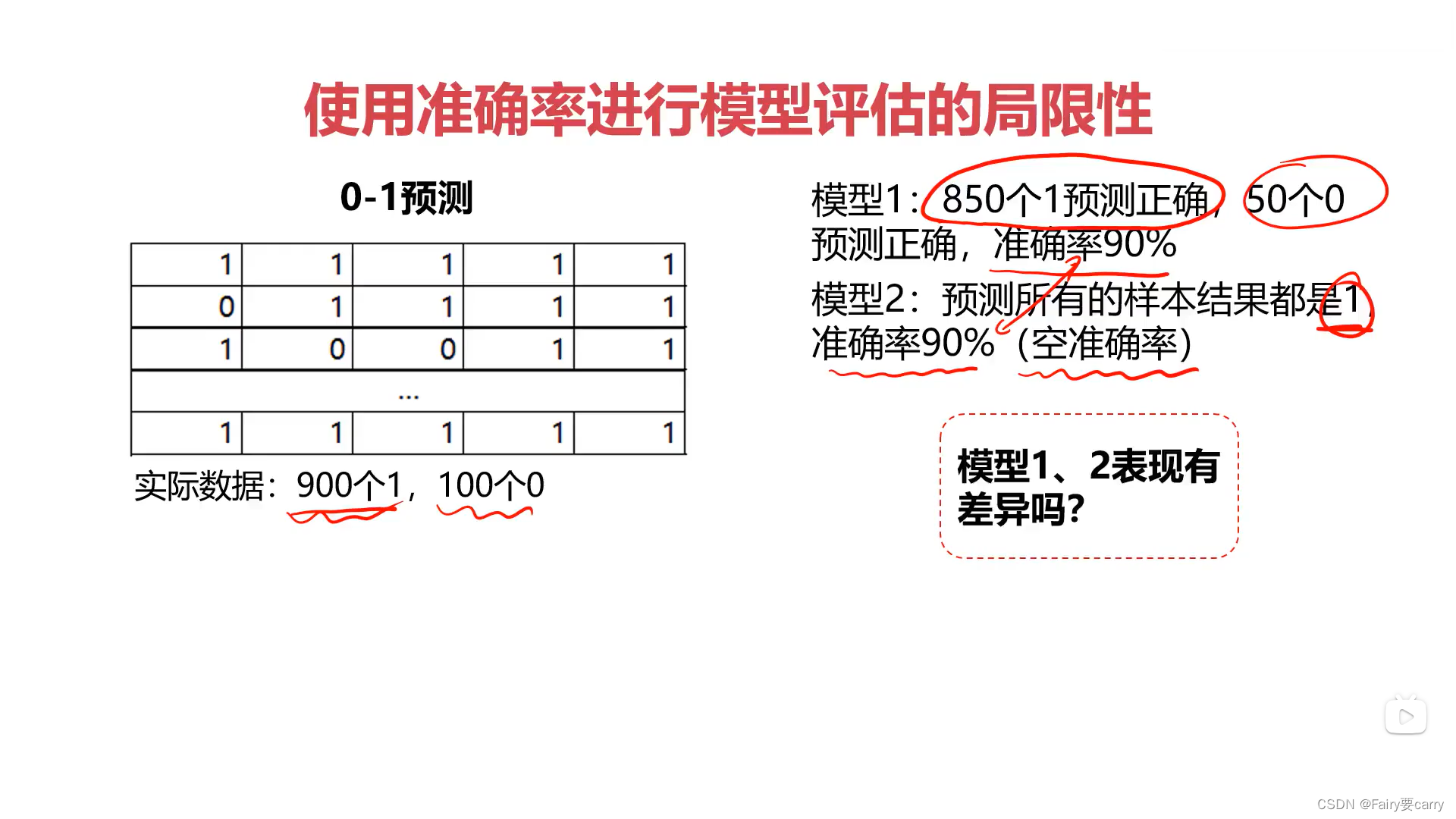
总结:需要考虑每一类本身的分布比例(比如1:0=9:1)

4.解决方案(混淆矩阵)
前一个为T:代表预测正确;
后一个为Postives:代表模型预测正确;
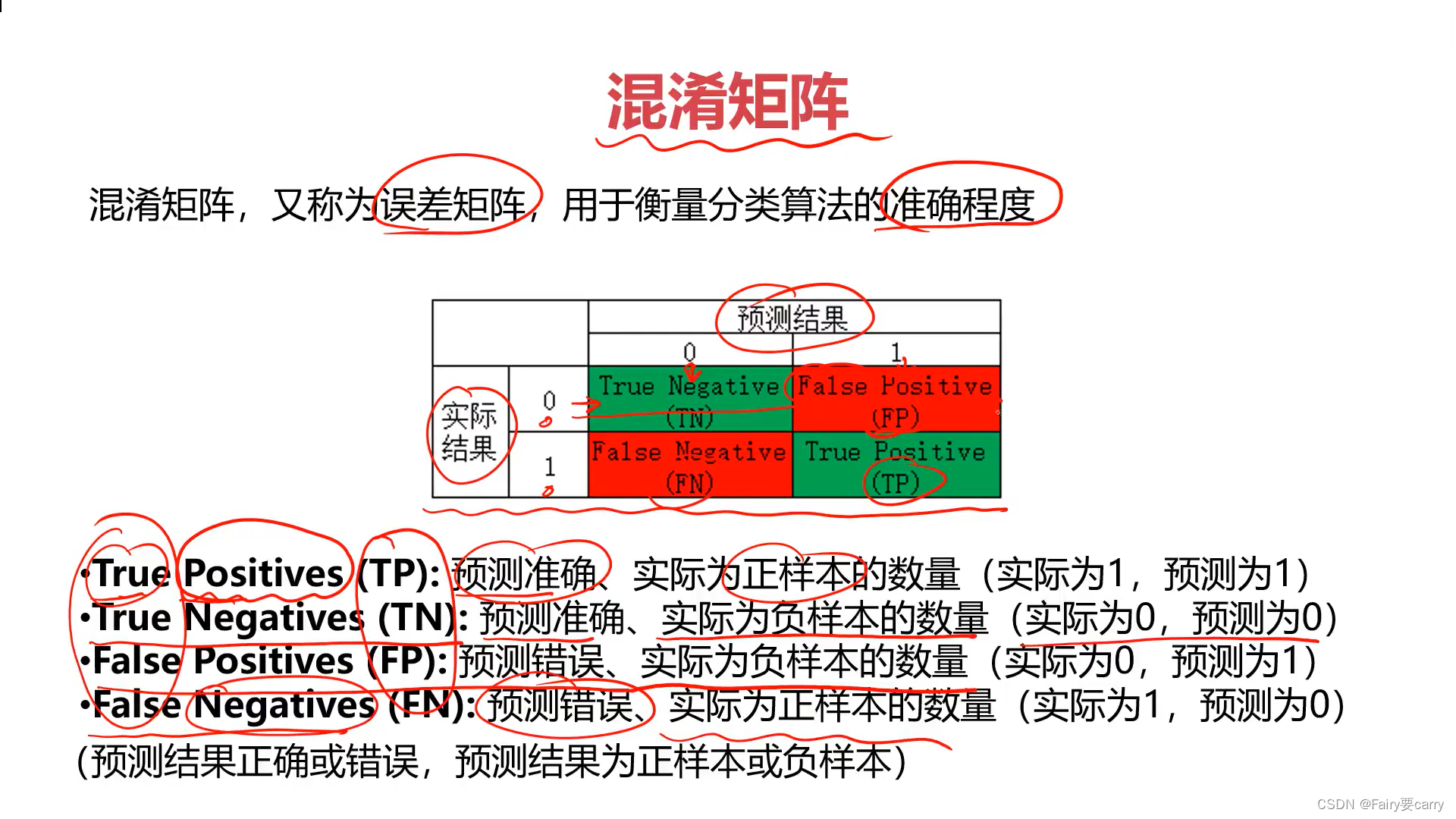
1.如何利用TP,TN,FP,FN进行模型的评估
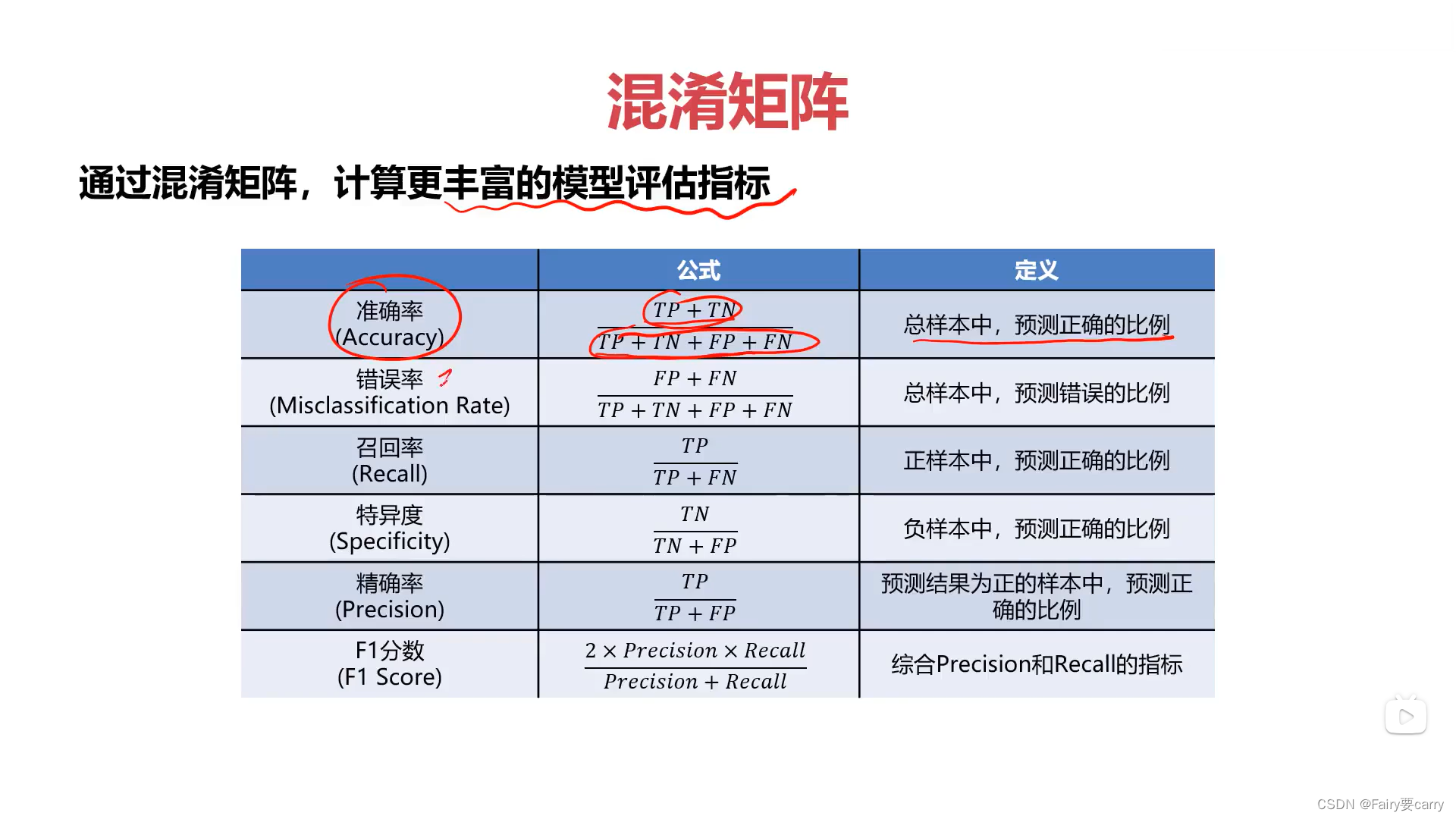
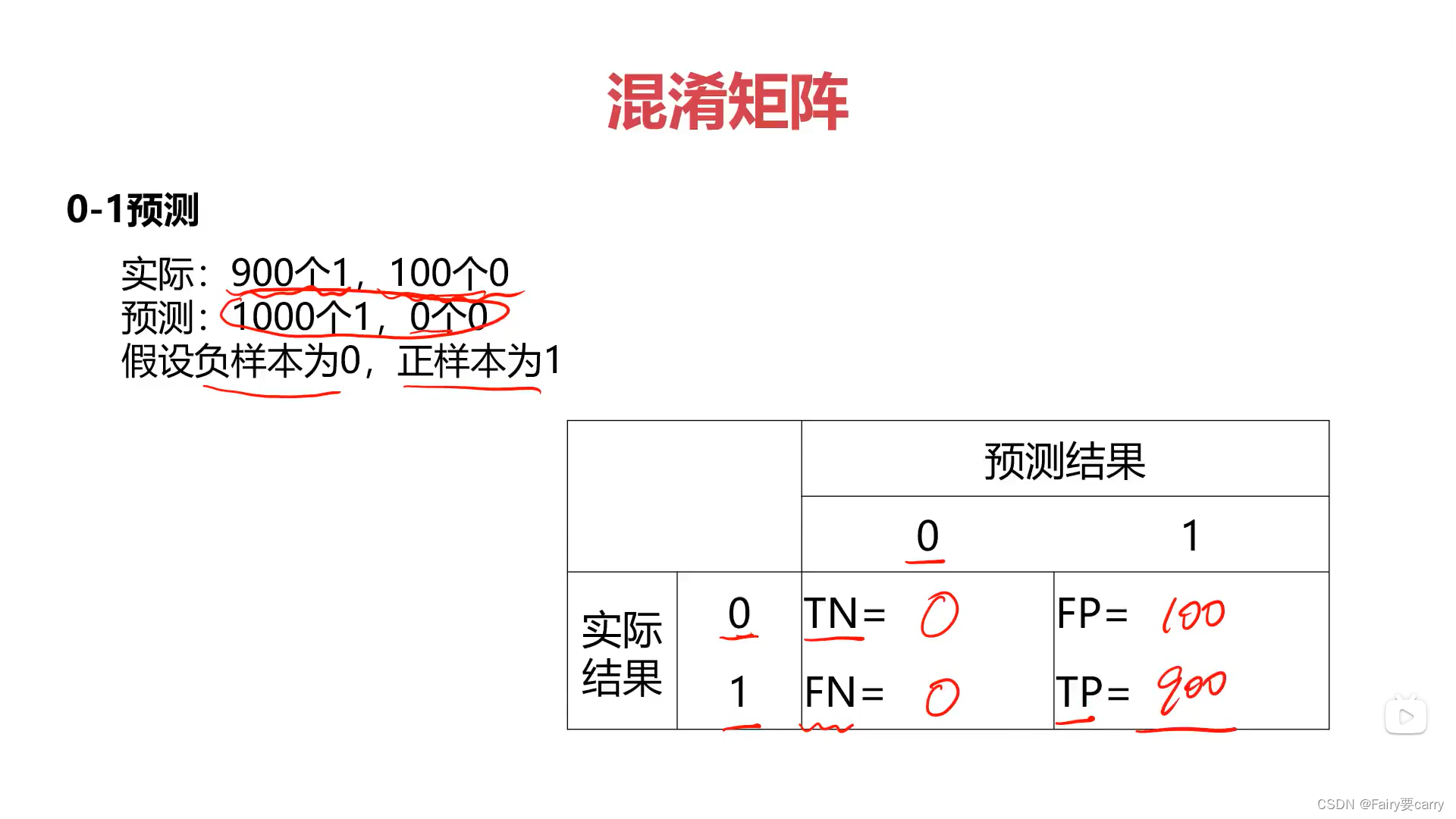
计算指标:
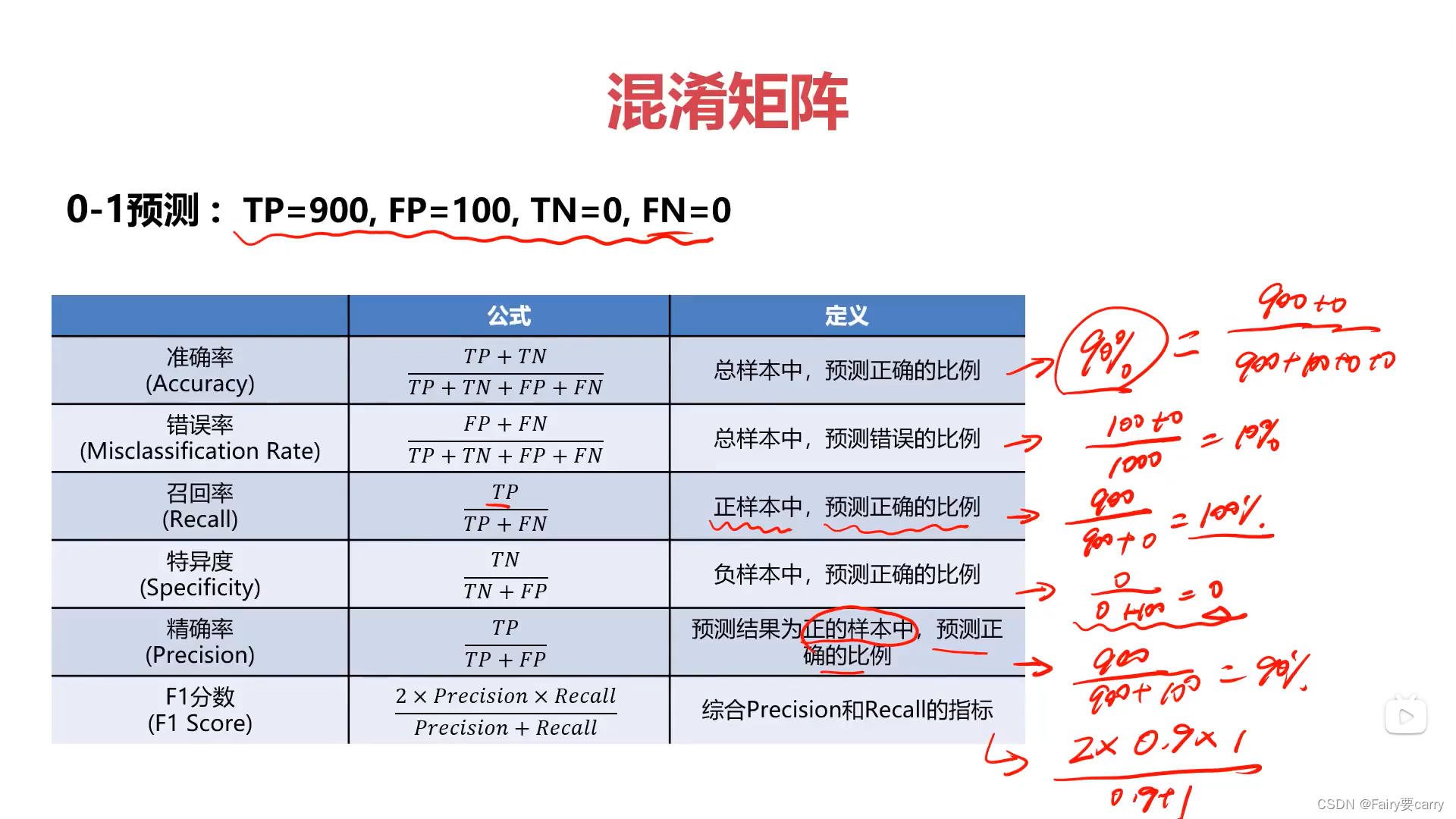
2.混淆矩阵的特点:

5.模型优化
1.用什么模型:
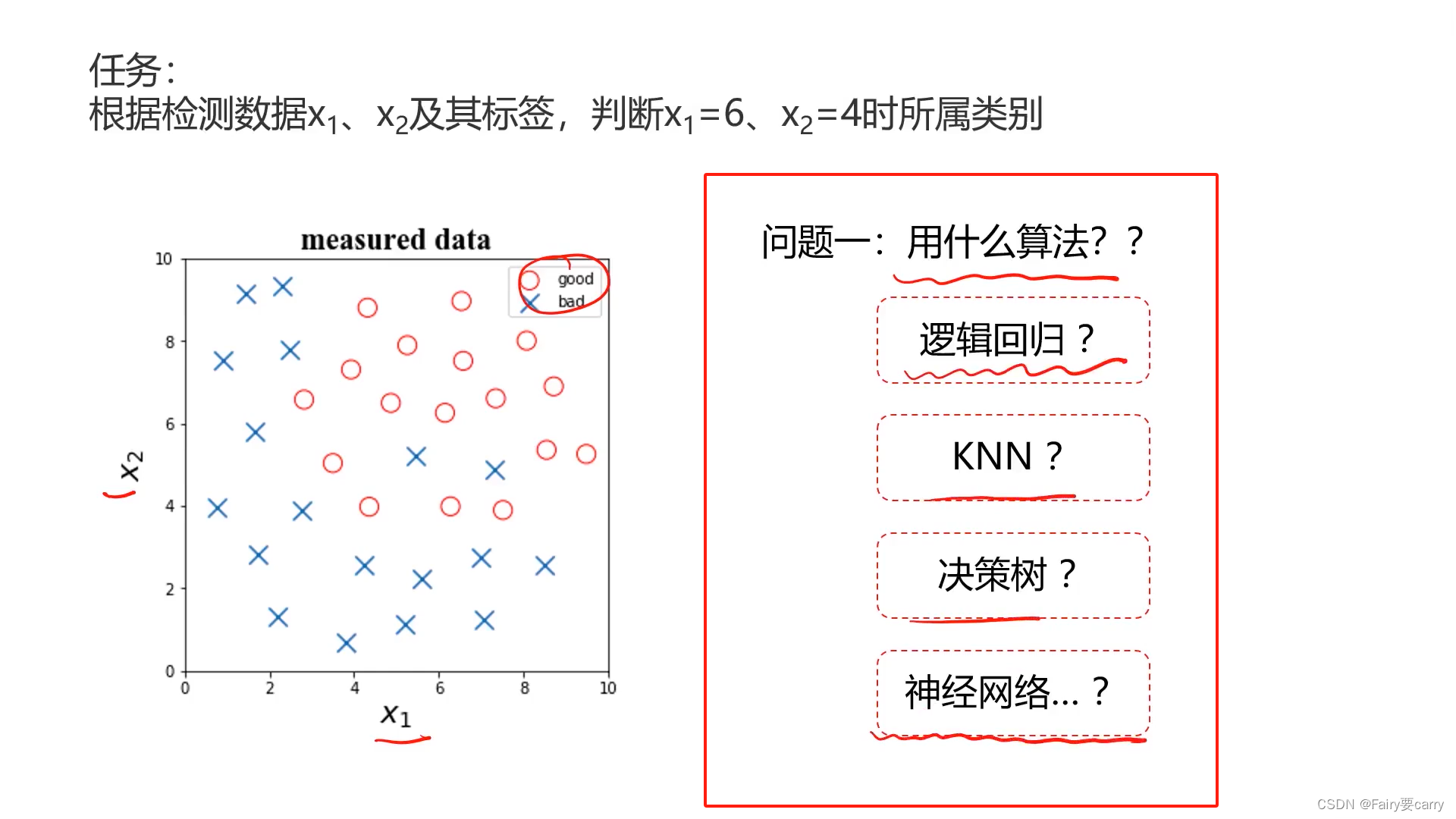
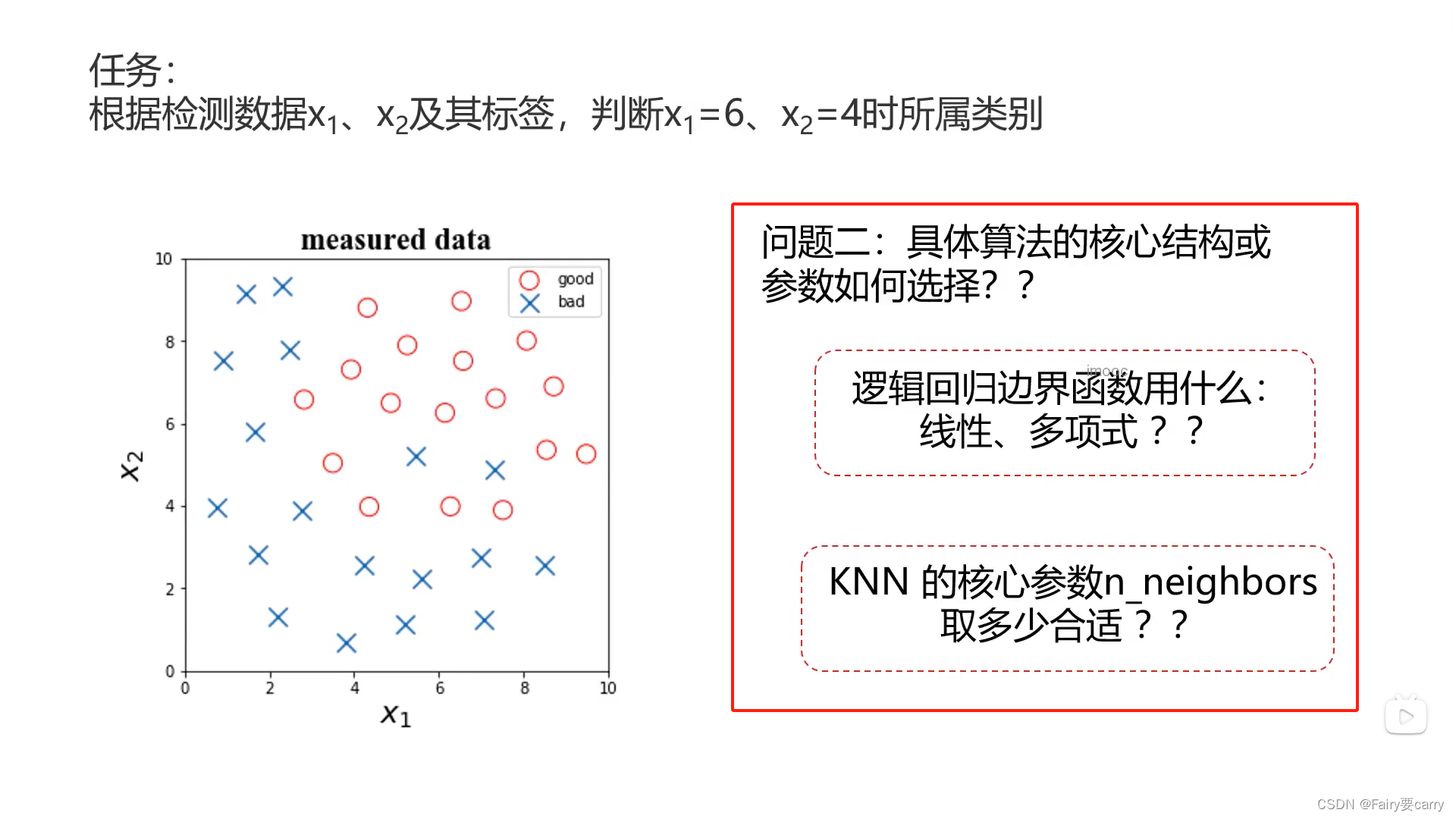
2.具体算法的核心结构以及参数如何选择?
比如逻辑回归的函数g(x)如何选择,线性还是多项式等等
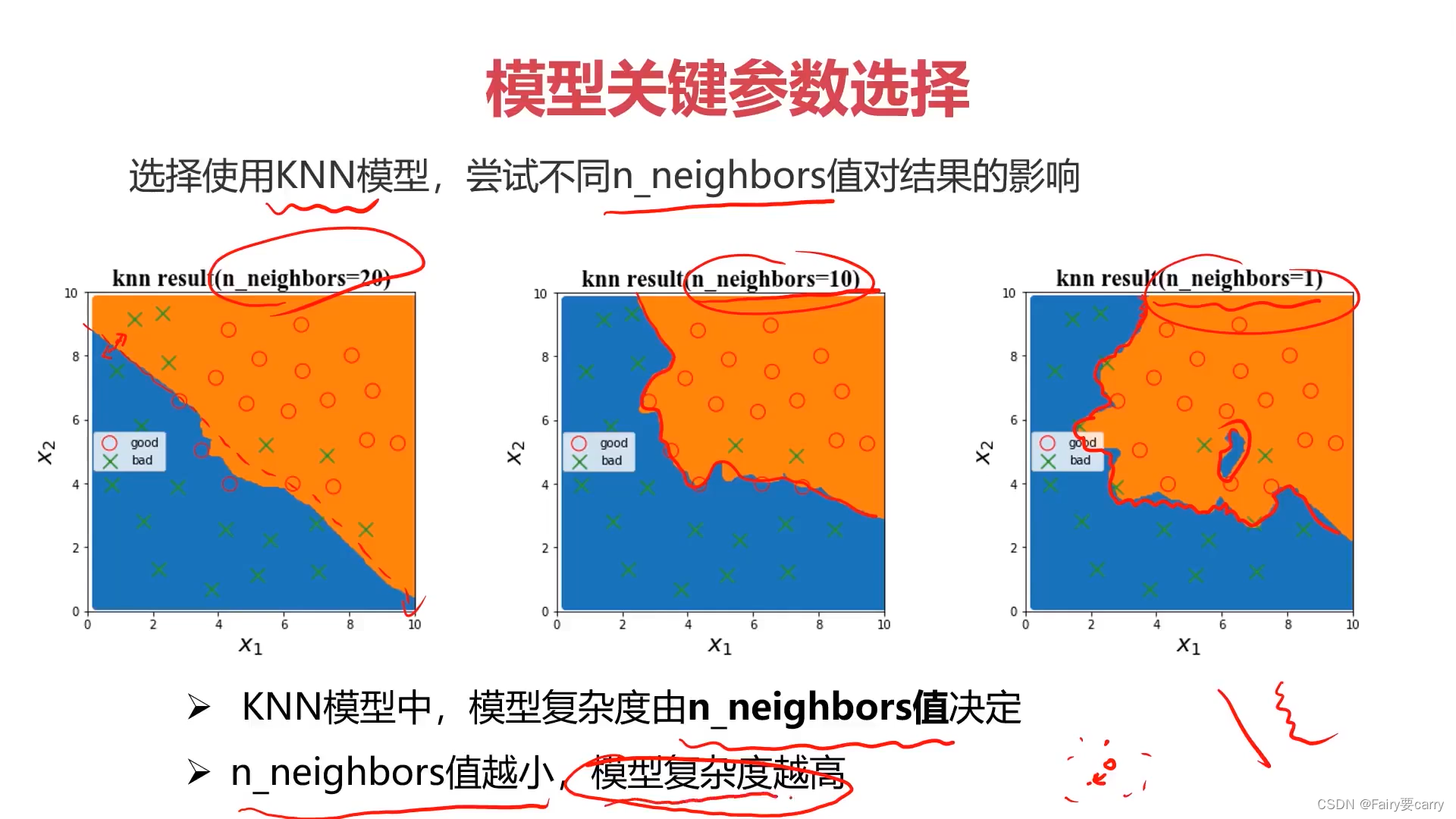
Knn的邻居参数
3.如何提高模型表现?
数据质量决定模型表现的上限
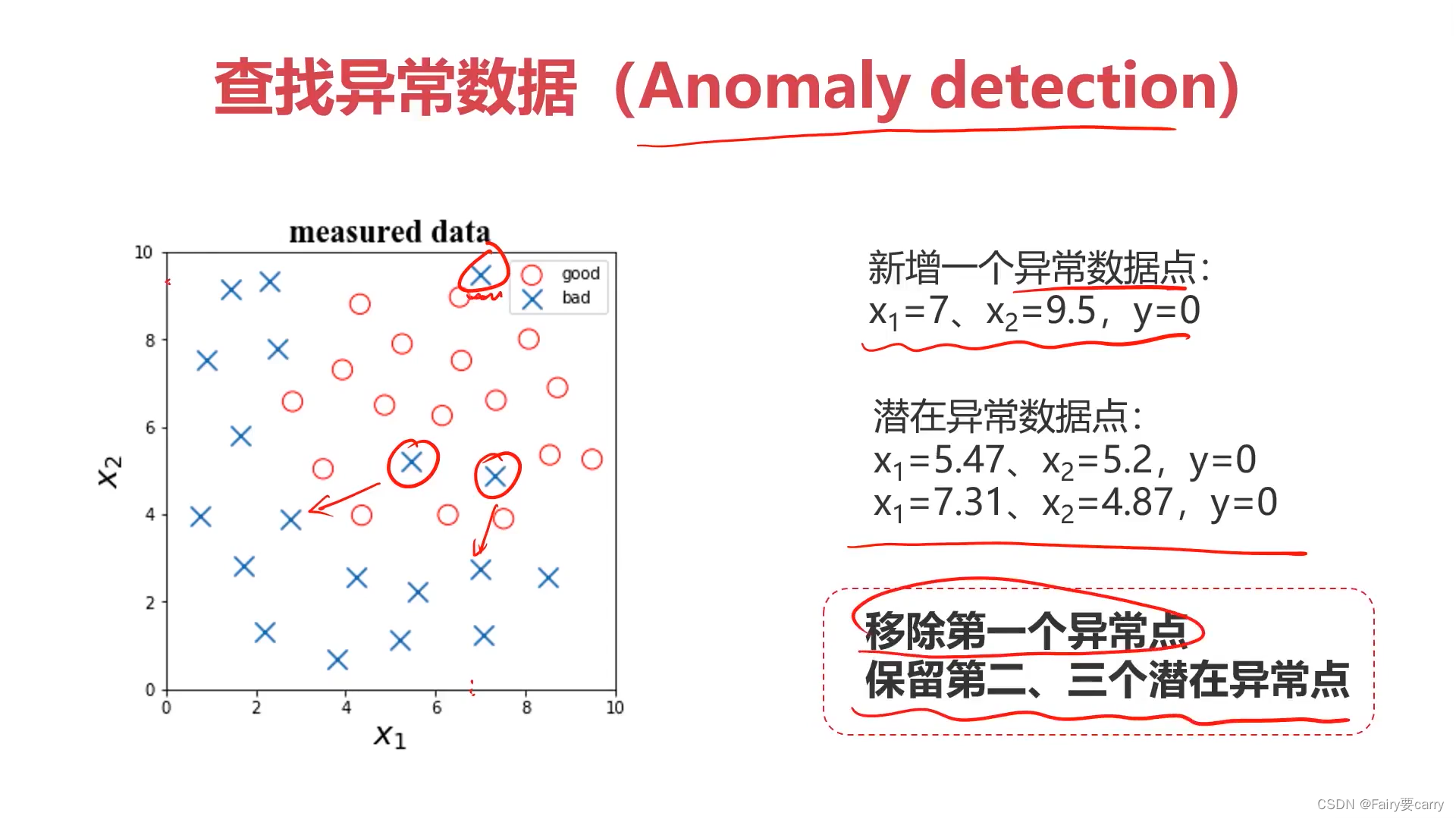
判断是否有异常数据:我们可以用异常检测法检测有没有异常数据,然后将其排除或者保留(保留的主要目的是考虑了数据的适用性)。
数据的意义:是否为无关数据。
对于数据的标签结果:统一管理
尝试更多的模型


4.举个例子:利用高斯分布概率统计异常检测
1.数据分布统计——>2.高斯分布概率统计分析异常——>3.优化:PCA分析维度是否可以减少——>4.尝试不同的模型进行优化
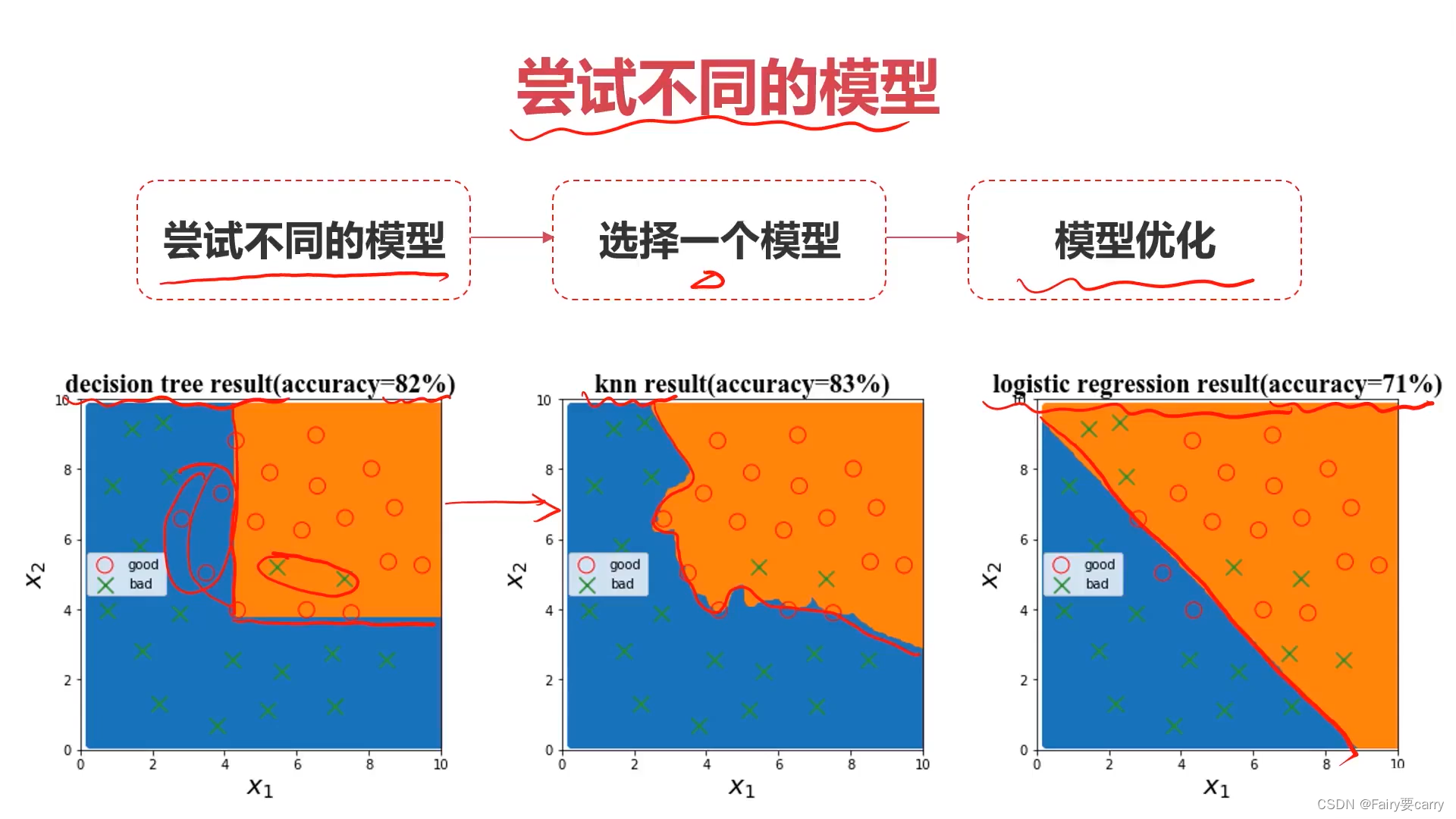
5.确定一个模型后,如何让模型的表现更好

模型的参数的选择:
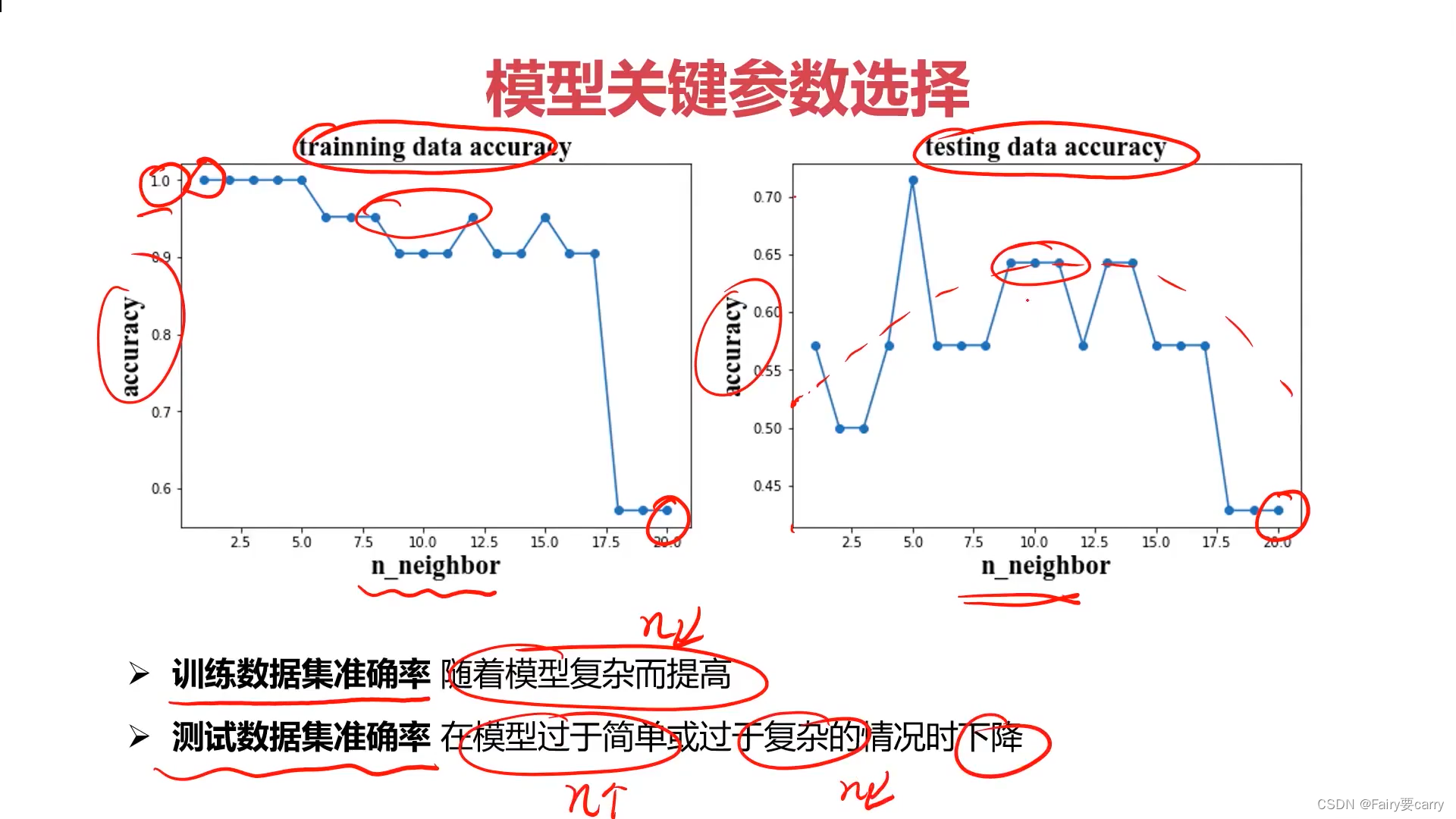
比如出现欠拟合的情况,模型不能很好的预测样本,我们可以降低KNN的参数n_neighbors值,越降低,模型复杂度越高。
模型复杂度越高说明训练集的准确率越高,但不代表测试集的准确率会很高,需要进行调整。