问题排查的思路与方向
问题排查思路
- 分析问题:根据理论知识+经验分析问题,判断问题可能出现的位置或可能引起问题的原因,将目标缩小到一定范围;
- 排查问题:基于上一步的结果,从引发问题的“可疑性”角度出发,从高到低依次进行排查,进一步排除一些选项,将目标范围进一步缩小;
- 定位问题:通过相关的监控数据的辅助,以更“细粒度”的手段,将引发问题的原因定位到精准位置;
- 解决问题:判断到问题出现的具体位置以及引发的原因后,采取相关措施对问题加以解决;
- 尝试最优解(非必须):将原有的问题解决后,在能力范围内,且环境允许的情况下,应该适当考虑问题的最优解(可以从性能、拓展性、并发等角度出发);
问题排查方向
应用程序本身导致的问题
- 程序内部频繁触发GC,造成系统出现长时间停顿,导致客户端堆积大量请求。
- JVM参数配置不合理,导致线上运行失控,如堆内存、各内存区域太小等。
- Java程序代码存在缺陷,导致线上运行出现Bug,如死锁/内存泄漏、溢出等。
- 程序内部资源使用不合理,导致出现问题,如线程/DB连接/网络连接/堆外内存等。
上下游内部系统导致的问题
- 上游服务出现并发情况,导致当前程序请求量急剧增加,从而引发问题拖垮系统。
- 下游服务出现问题,导致当前程序堆积大量请求拖垮系统,如Redis宕机/DB阻塞等。
程序所部署的机器本身导致的问题
- 服务器机房网络出现问题,导致网络出现阻塞、当前程序假死等故障。
- 服务器中因其他程序原因、硬件问题、环境因素(如断电)等原因导致系统不可用。
- 服务器因遭到入侵导致Java程序受到影响,如木马病毒/矿机、劫持脚本等。
第三方的RPC远程调用导致的问题
- 作为被调用者提供给第三方调用,第三方流量突增,导致当前程序负载过重出现问题。
- 作为调用者调用第三方,但因第三方出现问题,引发雪崩问题而造成当前程序崩溃。
数据库问题可能发生方面
SQL执行报错
业务代码bug,编写的SQL语句报错;
- 一般会抛出异常信息如
Error updating database. Cause: java.sql.SQLException: Field 'category_name' doesn't have a default value可根据异常信息百度解决;
慢SQL
偶发的SQL执行缓慢的情况;
-
慢查询日志:
-
查看慢查询日志:
show variables like 'slow_query_log_file';
- 行慢查询SQL的用户:root,登录IP为:localhost[127.0.0.1]。
- 慢查询执行的具体耗时为:0.014960s,锁等待时间为0s。
- 本次SQL执行后的结果集为4行数据,累计扫描6行数据。
- 本次慢查询发生在db_zhuzi这个库中,发生时间为1667466932(2022-11-03 17:15:32)。
- 最后一行为具体的慢查询SQL语句。
-
排查SQL执行缓慢的原因:
- 根据慢查询日志中的信息,得到具体慢
SQL信息,并根据Look_time耗时判断是不是由于并发事物导致的长时间阻塞,如果不是则使用explain执行分析工具,判断索引情况; - 如果在慢查询日志中,存在大量由于并发事物导致的慢查询,则可以通过查看Mysql的锁状态来判断当前Mysql节点的承载并发压力是否过高;
- 根据慢查询日志中的信息,得到具体慢
-
机器故障
部署MySQL的及其故障,如磁盘、内存、CPU100%、MySQL自身故障等;
客户端连接异常
- 数据库的连接数超出了最大连接数,此时再出现新连接时会出现异常;
- 解决办法:排查数据库和客户端连接池的配置是否合理,适当调整参数;
- 客户端数据库连接池与
Mysql版本不匹配,或超时时间过小,可能导致连接中断;- 解决办法:排查数据库和客户端连接池的配置是否合理,适当调整参数;
Mysql、JAVA程序所部署的机器不在同一网段,导致两者之间可能存在网络通信故障;- 排查方向如下:
- 检测防火墙与安全组的端口是否开放,或与外网机器是否做了端口映射。
- 检查部署MySQL的服务器白名单,以及登录的用户IP限制,可能是IP不在白名单范围内。
- 如果整个系统各节点部署的网段不同,检查各网段之间交换机的连接超时时间是多少。
- 检查不同网段之间的网络带宽大小,以及具体的带宽使用情况,有时因带宽占满也会出现问题。
- 如果用了
MyCat、MySQL-Proxy这类代理中间件,记得检查中间件的白名单、超时时间配置。
- 排查方向如下:
- 机器资源不足,如CPU、硬盘占用过高,导致
MySQL没有资源分配给新连接;- 在一切正常的情况下,有时候出现连接不上
MySQL的情况时,可以去查看部署Mysql服务的机器的硬件使用情况,若出现异常则说明是机器问题;
- 在一切正常的情况下,有时候出现连接不上
死锁频发
MySQL会默认开启死锁检测算法,当运行期间出现死锁问题时,会主动介入并解除死锁,具体可参考Mysql锁机制中的死锁介绍,但其指标不治本,死锁现象是由于业务代码不合理造成的,极大可能反复出现;
-
定位死锁问题:可通过
SHOW ENGINE INNODB STATUS\G;查看InnoDB的运行状态日志,其中包含InnoDB运行期间所有的状态日志,其中死锁日志在LATEST DETECTED DEADLOCK这块区域;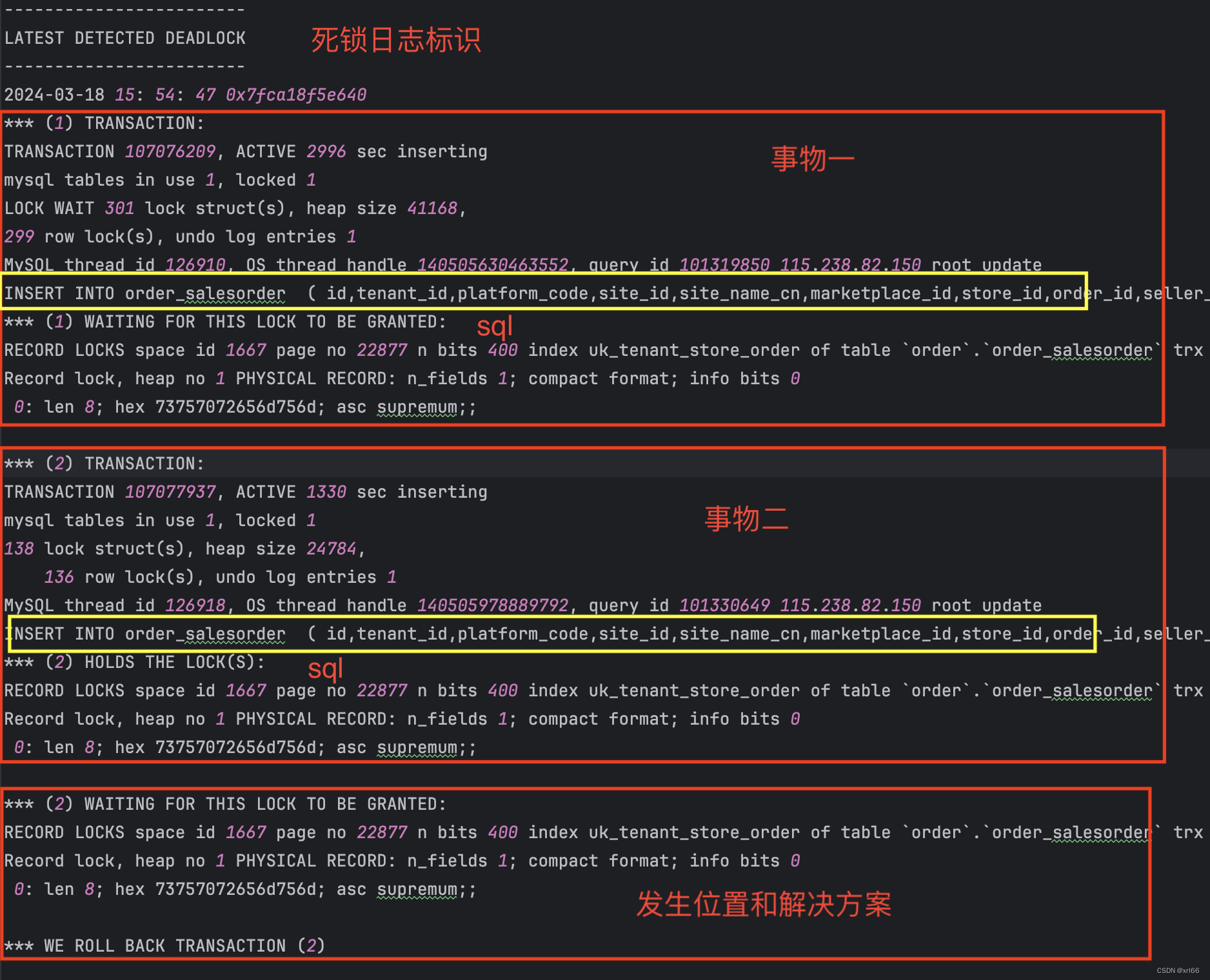
- 信息中包含了死锁发生的时间
*** (n) TRANSACTION:产生死锁的事物和具体sql*** (2) WAITING FOR THIS LOCK TO BE GRANTED: 指明了发生死锁冲突的地点位于order库中order_salesorder表的uk_tenant_store_order索引上,第二个事务正在等待获取插入意向锁,但是由于第一个事务持有了表级的共享锁,并且也在等待获取插入意向锁;*** WE ROLL BACK TRANSACTION (2):解决方案是回滚了第二个事物;
CPU100%
-
排查思路:
- 找到CPU过高的服务器;
- 定位具体进程,
top; - 定位进程中的具体线程,
top -Hp [PID]; - 找到线程正在执行的代码逻辑;
- 从代码层面着手优化;
-
具体步骤:
-
通过
top命令查看占用CPU最高的进程(这里假设mysql占用率最高):top - 16:02:11 up 623 days, 23:46, 1 user, load average: 0.24, 0.22, 0.19 Tasks: 139 total, 1 running, 138 sleeping, 0 stopped, 0 zombie %Cpu(s): 1.5 us, 0.1 sy, 0.0 ni, 98.2 id, 0.0 wa, 0.2 hi, 0.0 si, 0.0 st MiB Mem : 15469.9 total, 152.1 free, 6837.6 used, 8480.2 buff/cache MiB Swap: 0.0 total, 0.0 free, 0.0 used. 8314.0 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 3093986 admin 20 0 6576080 1.4g 18008 S 5.3 9.6 2:50.12 java 3057999 admin 20 0 6335928 1.2g 16864 S 0.7 8.1 4:42.53 java 13699 root 20 0 1722052 283200 5076 S 0.3 1.8 3126:16 /usr/local/clou 106781 admin 20 0 5079784 1.0g 2612 S 0.3 6.9 3184:01 java 765635 mysql 20 0 2653408 1.4g 10140 S 0.3 9.0 54062:02 mysqld 2836690 admin 20 0 273680 9612 2008 S 0.3 0.1 356:23.41 redis-server 3054745 admin 20 0 4696200 815644 16600 S 0.3 5.1 3:24.90 java 3499020 root 10 -10 89768 13020 9316 S 0.3 0.1 66:17.11 AliYunDun 3499031 root 10 -10 133384 24060 12164 S 0.3 0.2 126:29.57 AliYunDunMonito 1 root 20 0 111468 6140 3204 S 0.0 0.0 8:14.12 systemd 2 root 20 0 0 0 0 S 0.0 0.0 0:13.04 kthreadd 3 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_gp 4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_par_gp -
之后可以通过
top -Hp [PID]命令查询进程中CPU占用率最高的线程;top - 16:09:44 up 623 days, 23:54, 2 users, load average: 0.00, 0.05, 0.11 Threads: 53 total, 0 running, 53 sleeping, 0 stopped, 0 zombie %Cpu(s): 5.1 us, 0.3 sy, 0.0 ni, 94.2 id, 0.0 wa, 0.3 hi, 0.1 si, 0.0 st MiB Mem : 15469.9 total, 179.2 free, 6847.7 used, 8443.0 buff/cache MiB Swap: 0.0 total, 0.0 free, 0.0 used. 8303.9 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 3096811 mysql 20 0 2653408 1.4g 10140 S 0.7 9.0 0:00.02 mysqld 765637 mysql 20 0 2653408 1.4g 10140 S 0.3 9.0 2:54.55 mysqld 3087933 mysql 20 0 2653408 1.4g 10140 S 0.3 9.0 0:01.49 mysqld 3096213 mysql 20 0 2653408 1.4g 10140 S 0.3 9.0 0:00.03 mysqld 765635 mysql 20 0 2653408 1.4g 10140 S 0.0 9.0 0:04.38 mysqld 765636 mysql 20 0 2653408 1.4g 10140 S 0.0 9.0 0:00.00 mysqld 765638 mysql 20 0 2653408 1.4g 10140 S 0.0 9.0 3:08.71 mysqld -
查看OS线程ID与MySQL线程ID关系(MySQL5.7及以上),通过查询
performance_schema库中的threads表SELECT * FROM threads where THREAD_OS_ID = 3096811;
THREAD_ID:Mysql内部线程IdPROCESSLIST_USER:数据库连接的客户端用户PROCESSLIST_HOST:数据库连接的客户端地址PROCESSLIST_DB:访问的库PROCESSLIST_INFO:当前线程正在执行的sqlTHREAD_OS_ID:操作系统的线程ID
-
得到当前线程正在执行的sql,则可以从代码层面着手优化;
-
磁盘100%
- 可能导致磁盘
IO占用过高的原因:- 突然大批量变更库中数据,需要执行大量写入操作,如主从数据同步时就会出现这个问题。
- MySQL处理的整体并发过高,磁盘I/O频率跟不上,比如是机械硬盘材质,读写速率过慢。
- 内存中的BufferPool缓冲池过小,大量读写操作需要落入磁盘处理,导致磁盘利用率过高。
- 频繁创建和销毁临时表,导致内存无法存储临时表数据,因而转到磁盘存储,导致磁盘飙升。
- 执行某些SQL时从磁盘加载海量数据,如超2张表的联查,并每张表数据较大,最终导致IO打满。
- 日志刷盘频率过高,其实这条是i、ii的附带情况,毕竟日志的刷盘频率,跟整体并发直接挂钩。
- 解决办法:
- **提升硬件,**若磁盘不是固态硬盘的可将磁盘升级成固态硬盘;
- 引入中间件,如引入
Redis减小读压力,引入MQ进行流量削峰; - 调大
BufferPool缓冲池大小; SQl语句上优化,撰写SQL语句时尽量减少多张大表联查,不要频繁的使用和销毁临时表;
Performance_Schema库监控全局资源
MySQL5.6引入,主要记录:数据库整体的监控信息,比如事务监控信息、最近执行的SQL信息、最近连接的客户端信息、数据库各空间的使用信息等,基于这个库可以在线上构建出一个完善的MySQL监控系统:Statements/execution stages:MySQL统计的一些消耗资源较高的SQL语句。Table and Index I/O:MySQL统计的那些表和索引会导致I/O负载过高。Table Locks:MySQL统计的表中数据的锁资源竞争信息。Users/Hosts/Accounts:消耗资源最多的客户端、IP机器、用户。Network I/O:MySQL统计的一些网络相关的资源情况。






![[链表专题]力扣141, 142](https://img-blog.csdnimg.cn/img_convert/eb33678530842daa48a4c1c4b42d8976.png)