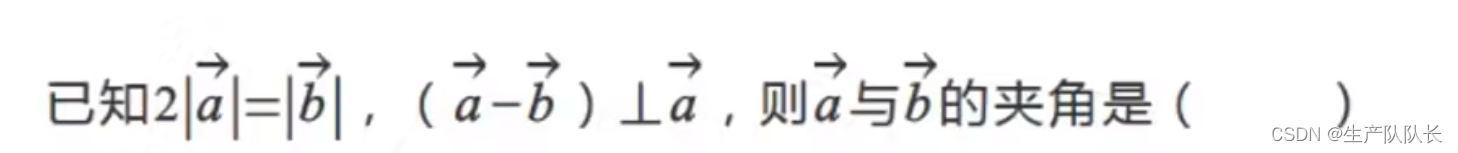目录
- 前言
- 一、 开源大模型的优势
- 1. 社区支持与合作
- 1.1 全球协作网络
- 1.2 快速迭代与创新
- 1.3 共享最佳实践
- 2. 透明性与可信赖性
- 2.1 审计与验证
- 2.2 减少偏见与错误
- 2.3 安全性提升
- 3. 低成本与易访问性
- 3.1 降低研发成本
- 3.2 易于定制化
- 3.3 教育资源丰富
- 4. 促进标准化
- 5. 推动技术进步
- 二、 闭源大模型的优势
- 1. 商业保护与竞争优势
- 1.1 知识产权控制
- 1.2 商业秘密保护
- 1.3 品牌建设
- 2. 质量控制与稳定性
- 2.1 严格的质量控制
- 2.2 定制化服务
- 2.3 持续的支持和维护
- 3. 客户信任与合规性
- 3.1 建立客户信任
- 3.2 遵守法规合规性
- 3.3 风险控制
- 4.商业模式的灵活性
- 4.1 创新的商业模式
- 4.2 价格策略
- 4.3 交叉销售和捆绑
- 三、数据隐私保护与用户数据安全
- 1. 数据隐私保护
- 1.1 遵循隐私法规
- 1.2 控制数据访问
- 1.3 审计跟踪
- 2. 用户数据安全
- 2.1 加强安全防护
- 2.2 定期安全审核
- 2.3 定制安全解决方案
- 四、商业应用领域的考量
- 1.商业模式适应性
- 1.1 灵活的商业策略
- 1.2 竞争壁垒
- 1.3 客户关系管理
- 2. 合规性要求
- 2.1 满足特定行业标准
- 2.2 保护敏感信息
- 五、 实际应用中的选择
- 1. 根据组织目标选择
- 1.1 创新与研究
- 1.2 商业产品与服务
- 2. 考虑资源和能力
- 2.1 技术能力和专业知识
- 2.2 资金投入
- 六、未来发展趋势
前言
在人工智能领域,大型机器学习模型的开发面临着一个关键的选择:走向开源还是选择闭源。这两种模式各有优劣,而选择一个合适的路径对于模型的成功至关重要。本文将从数据隐私保护、用户数据安全、商业应用领域的考量等方面进行探讨,并分析在实际应用中如何选择以及未来发展趋势。
一、 开源大模型的优势

在人工智能技术飞速发展的今天,开源大模型已经成为推动创新和协作的重要力量。开源大模型的主要优势:
1. 社区支持与合作
1.1 全球协作网络
开源大模型借助于全球开发者社区的力量,形成了一个跨地域、跨学科的协作网络。这种协作方式不仅加速了问题的解决,还促进了不同文化和思想背景的人才之间的交流与碰撞。
1.2 快速迭代与创新
开源社区的多样性和开放性为大模型的快速迭代提供了土壤。社区成员可以在短时间内对模型进行修改、优化和增强,从而迅速响应市场和技术的变化。
1.3 共享最佳实践
开源大模型允许开发者分享最佳实践和成功案例,这有助于整个社区提升技术水平。通过共享代码、教程和文档,开发者可以减少重复工作,提高开发效率。
2. 透明性与可信赖性
2.1 审计与验证
开源大模型的源代码公开,使得任何人都可以进行审计和验证。这种开放性提高了模型的透明度,有助于建立用户对技术的信任。
2.2 减少偏见与错误
开放的代码库允许研究人员和开发者检查模型的潜在偏见和错误。社区的集体智慧可以帮助识别和纠正这些问题,从而提高模型的准确性和公平性。
2.3 安全性提升
开源社区的众多眼睛可以更快地发现安全漏洞。通过公开的漏洞报告和修复过程,开源大模型能够更迅速地响应安全威胁。
3. 低成本与易访问性
3.1 降低研发成本
开源大模型通常可以免费使用或以极低的成本获得,这对于资金有限的学术研究者和初创公司来说是一个巨大的优势。
3.2 易于定制化
开源模型的灵活性意味着它们可以根据特定需求进行定制。企业和个人可以根据自己的应用场景对模型进行调整,而不必从头开始构建。
3.3 教育资源丰富
开源大模型通常伴随着丰富的教育资源,如教程、案例研究和在线课程。这些资源有助于新手快速学习和掌握复杂的机器学习技术。
4. 促进标准化
开源大模型推动了AI领域的标准化。当多个团队和组织使用相同的开源模型作为基础时,他们更容易实现结果的可比性和可复现性。
5. 推动技术进步
开源大模型的存在加速了人工智能技术的普及和进步。通过开放的研究,学术界和工业界能够共同推动技术的边界,解决更加复杂的问题。
开源大模型的优势在于其能够集合全球智慧,快速迭代和创新,提供透明可信的技术解决方案,降低成本并易于获取,同时推动行业标准化的制定和技术的持续进步。这些优势使得开源大模型成为推动人工智能发展的重要力量。
二、 闭源大模型的优势

在人工智能领域,闭源大模型以其独有的特性和优势,在某些场景下成为企业和个人的首选。闭源大模型的主要优势:
1. 商业保护与竞争优势
1.1 知识产权控制
闭源大模型的核心优势在于对知识产权的严格控制。公司可以保护其算法和技术不被竞争对手复制或利用,从而在市场上保持独特的竞争优势。
1.2 商业秘密保护
对于包含敏感商业秘密的模型,闭源可以防止机密信息泄露。这对于保护企业的商业战略和客户数据至关重要。
1.3 品牌建设
闭源模型可以帮助企业建立强大的品牌形象。通过提供独家的服务和产品,企业可以在客户心中树立专业和可靠的形象。
2. 质量控制与稳定性
2.1 严格的质量控制
闭源模型的开发通常伴随着严格的质量控制流程。这使得企业能够确保模型的稳定性和可靠性,满足高标准的业务需求。
2.2 定制化服务
闭源模型允许企业根据特定客户需求提供定制化服务。这种灵活性使得企业能够更好地满足不同客户的个性化需求。
2.3 持续的支持和维护
闭源模型的用户通常可以获得厂商提供的持续支持和维护服务。这有助于确保模型长期内的稳定运行和性能优化。
3. 客户信任与合规性
3.1 建立客户信任
闭源模型的不透明性有时反而可以增加某些客户的信任,因为他们相信企业不会滥用他们的数据。
3.2 遵守法规合规性
闭源模型更容易符合特定的法规要求,尤其是在处理敏感数据时。企业可以通过自定义模型来确保符合数据保护法规。
3.3 风险控制
闭源模型可以帮助企业更好地控制技术和运营风险。通过内部开发和维护,企业可以减少对外部开源依赖带来的不确定性。
4.商业模式的灵活性
4.1 创新的商业模式
闭源模型允许企业探索创新的商业模式,如基于使用的计费模式或提供订阅服务,从而创造新的收入流。
4.2 价格策略
闭源模型使得企业可以根据市场需求和竞争状况灵活定价。闭源产品的独家性往往使它们能够以更高的价格销售。
4.3 交叉销售和捆绑
企业可以利用闭源模型作为交叉销售或捆绑其他产品和服务的平台,从而增加客户粘性和市场渗透力。
闭源大模型的优势在于其能够保护商业秘密和知识产权,提供高质量的稳定模型,建立客户信任,并探索灵活的商业模式。这些优势使得闭源大模型在特定的商业场景和需求下成为理想的选择。然而,闭源模型也需要面对开放源代码模型所不具备的挑战,如开发的高成本和对社区支持的缺乏。因此,选择合适的开源或闭源模型需要根据具体的业务需求和战略目标来决定。
三、数据隐私保护与用户数据安全

在讨论大模型时,数据隐私保护和用户数据安全是不可或缺的考虑因素。以下深入分析这两个方面:
1. 数据隐私保护
1.1 遵循隐私法规
随着GDPR、CCPA等数据保护法规的实施,对用户数据的处理越来越受到法律的严格限制。闭源大模型可以定制化地设计数据处理流程,以确保遵守地区性隐私法规。
1.2 控制数据访问
闭源模型能够更严格地控制对数据的访问权限,只有授权的人员才能访问敏感数据,降低了数据泄露的风险。
1.3 审计跟踪
闭源系统通常具备完整的审计跟踪功能,企业可以追踪数据流向,确保数据处理的透明性和可追溯性。
2. 用户数据安全
2.1 加强安全防护
闭源大模型可以实施特定的安全措施,如端到端加密和多重身份验证,这为模型提供额外的安全层。
2.2 定期安全审核
通过定期进行安全审核和漏洞扫描,闭源模型的开发者能够及时发现并修复潜在的安全威胁。
2.3 定制安全解决方案
面对复杂的安全挑战,闭源模型允许企业根据其特定需求定制解决方案,以应对不断变化的安全环境。
四、商业应用领域的考量

在商业应用中,选择大模型需要权衡多方面的因素,特别是涉及商业模式和合规性的需求。
1.商业模式适应性
1.1 灵活的商业策略
闭源大模型可以适应多种商业模式,包括基于结果的定价、订阅服务或混合模式,为企业提供了丰富的策略选择。
1.2 竞争壁垒
闭源模型可以作为构建竞争壁垒的工具,防止竞争对手复制或窃取有价值的算法和技术。
1.3 客户关系管理
闭源模型可以更好地整合到客户关系管理(CRM)系统中,帮助企业提升客户服务质量和用户体验。
2. 合规性要求
2.1 满足特定行业标准
特定行业如金融、医疗等领域对数据处理有严格的合规要求。闭源模型可以根据这些要求进行定制开发,以满足行业标准。
2.2 保护敏感信息
处理敏感信息如个人健康记录或财务数据时,闭源模型可以提供必要的安全级别,保护这些信息不被未经授权的访问。
五、 实际应用中的选择

在实际的应用中,选择合适的大模型需要考虑组织的具体需求、资源和战略目标。
1. 根据组织目标选择
1.1 创新与研究
对于致力于创新和研究的机构,开源大模型由于其开放性和可访问性可能是更佳的选择。
1.2 商业产品与服务
对于旨在开发商业产品或提供服务的企业,闭源大模型可能更合适,特别是在需要保护知识产权和遵守特定合规要求的情况下。
2. 考虑资源和能力
2.1 技术能力和专业知识
组织需要评估内部团队的技术能力和专业知识,以确定是否有能力开发和维护闭源大模型,或者能否有效地利用和贡献于开源项目。
2.2 资金投入
闭源大模型可能需要较大的前期投资,而开源大模型虽然免费,但可能需要额外的定制化工作,这些都需要根据组织的财务状况来考虑。
六、未来发展趋势

随着人工智能技术的不断进步,我们可能会看到更多的混合模型出现,结合了开源和闭源的优点。此外,随着法律法规的完善,数据隐私和安全问题将得到更好的解决。
总结而言,选择开源还是闭源并不是一个简单的黑白问题。对于学术界和初创公司来说,开源可能是一个更好的选择,因为它提供了更多的合作机会和更低的成本。而对于大型企业来说,闭源可能更为合适,因为它能够保护商业利益并提供更稳定的产品和服务。
最终,这个选择取决于组织的目标、资源和战略定位。无论是开源还是闭源,关键在于如何最大化模型的价值并服务于社会。

🎯🔖更多专栏系列文章:程序人生之路、AIGC-AI大模型探索之路
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!