Cifar100数据集是一个经典的图像分类数据集,常用于计算机视觉领域的研究和算法测试。以下是关于Cifar100数据集的详细介绍:
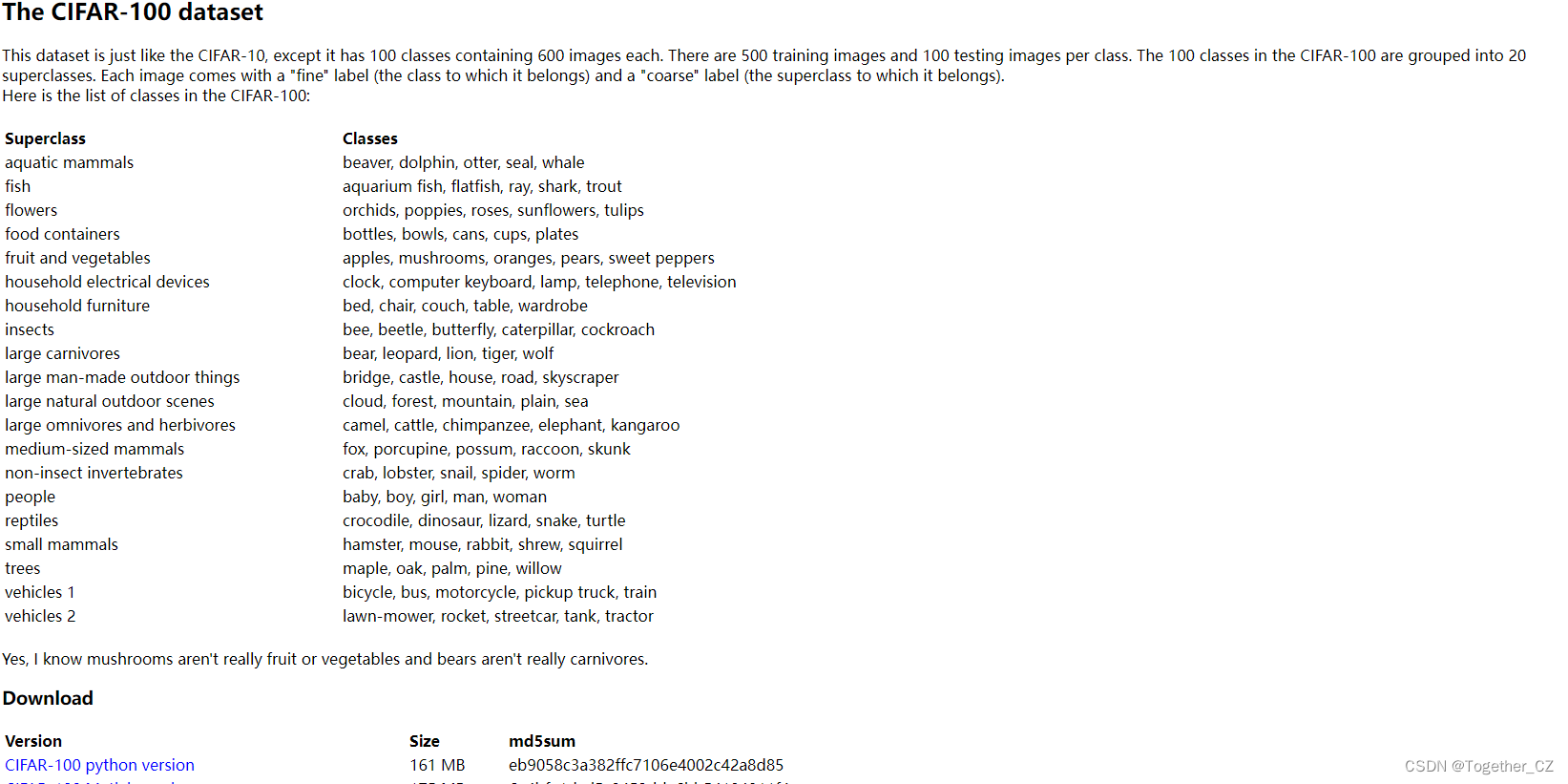
- 数据集构成:Cifar100数据集包含60000张训练图像和10000张测试图像。其中,训练图像分为100个类别,每个类别有600张图像;测试图像也分为100个类别,每个类别有100张图像。这些图像都是32x32像素的彩色图像,包含RGB三个通道。
- 类别划分:Cifar100数据集的100个类别被划分为20个大类别,每个大类别包含5个小类别。这些类别涵盖了动物、植物、交通工具、日常生活用品、自然景观、人物、体育、食物、艺术等多个领域。例如,动物类别包括鸟类、鱼类、爬行动物、哺乳动物等;植物类别包括树木、花卉、农作物等;交通工具类别包括汽车、火车、飞机、船等。
- 层次结构:Cifar100数据集的层次结构使得数据集更加丰富,包含了各种各样的对象和场景。这种层次结构有助于研究人员更好地理解数据集,并设计出更有效的算法来处理图像分类任务。
- 应用场景:Cifar100数据集常用于评估和比较各种图像分类算法的性能。研究人员可以使用该数据集来训练图像分类器,并测试其在不同类别上的识别准确率。此外,Cifar100数据集还可以用于开展图像生成和图像翻译等任务,如训练生成对抗网络(GAN)来生成逼真的图像。
- 数据集下载与预处理:Cifar100数据集可以通过官方渠道进行下载。下载后,需要对数据集进行预处理,包括加载图像、划分训练集和测试集、数据增强等操作。在Python中,可以使用pickle模块来加载Cifar100数据集,并使用numpy等库来处理图像数据。
Cifar100数据集是一个非常重要的图像分类数据集,具有广泛的应用场景和丰富的类别划分。通过使用Cifar100数据集,研究人员可以开发出更准确、更强大的图像分类算法,从而推动计算机视觉技术的发展。本文的主要目的就是想要基于Cifar100数据集来应用实践分析轻量级网络模型的性能。
首先看下实例效果:
由于CIFAR-100的完整类别列表较长,这里只给出部分类别实例,如下所示:
label_dict = { 'aquatic mammals': '水生哺乳动物', # 超类示例 'beaver': '河狸', # 水生哺乳动物超类下的类别 'dolphin': '海豚', # 水生哺乳动物超类下的类别 'fish': '鱼', # 超类示例(直接作为类别) 'shark': '鲨鱼', # 鱼类超类(或作为独立类别)下的类别 'flowers': '花', # 超类示例 'tulip': '郁金香', # 花卉超类下的类别 'sunflower': '向日葵', # 花卉超类下的类别 'food containers': '食物容器', # 超类示例 'bowl': '碗', # 食物容器超类下的类别 'cup': '杯子', # 食物容器超类下的类别 'household electrical devices': '家用电气设备', # 超类示例 'keyboard': '键盘', # 家用电气设备超类下的类别 'mouse': '鼠标', # 注意:这里的“mouse”指的是计算机鼠标,而非动物 'insect': '昆虫', # 超类(或作为独立类别)示例 'bee': '蜜蜂', # 昆虫超类下的类别 'butterfly': '蝴蝶', # 昆虫超类下的类别 # ...(其他类别)
}数据集官方网站在这里,如下所示:

这里给出来CIFAR-10-dataset和CIFAR-100-dataset两个数据集的下载地址。
CIFAR-10-dataset,如下所示:
CIFAR-100-dataset,如下所示:
官方提供的数据集不是图像形式的,这里可以直接加载使用,实例实现如下所示:
CIFAR_PATH = "自己的路径"
mean = [0.5070751592371323, 0.48654887331495095, 0.4409178433670343]
std = [0.2673342858792401, 0.2564384629170883, 0.27615047132568404]
num_workers= 2def cifar100_dataset(args):transform_train = transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.RandomRotation(15), # 数据增强transforms.ToTensor(),transforms.Normalize(mean, std)])transform_test = transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean, std)])cifar100_training = torchvision.datasets.CIFAR100(root=CIFAR_PATH, train=True, download=True, transform=transform_train)trainloader = torch.utils.data.DataLoader(cifar100_training, batch_size=args.bs, shuffle=True, num_workers=num_workers)cifar100_testing = torchvision.datasets.CIFAR100(root=CIFAR_PATH, train=False, download=True, transform=transform_test)testloader = torch.utils.data.DataLoader(cifar100_testing, batch_size=100, shuffle=False, num_workers=num_workers)return trainloader,testloader也可以选择将官方的数据集转化为图像的形式,之后再按照图像分类模型的标准做法来进行模型的开发训练。代码实现如下所示:
import os
import pickle
import numpy as np
from tqdm import trange
from os.path import join
from PIL import Imagedef createDir(path):if not os.path.exists(path):os.makedirs(path)def unpickle(file):with open(file, "rb") as fo:dict = pickle.load(fo, encoding="latin1")return dict# settings
src_dir = "./cifar-100-python"
dst_dir = "./cifar100"if __name__ == "__main__":meta = unpickle(join(src_dir, "meta"))createDir(dst_dir)for data_set in ["train", "test"]:print("Unpickling {} dataset......".format(data_set))data_dict = unpickle(join(src_dir, data_set))createDir(join(dst_dir, data_set))for fine_label_name in meta["fine_label_names"]:createDir(join(dst_dir, data_set, fine_label_name))for i in trange(data_dict["data"].shape[0]):img = np.reshape(data_dict["data"][i], (3, 32, 32))i0 = Image.fromarray(img[0])i1 = Image.fromarray(img[1])i2 = Image.fromarray(img[2])img = Image.merge("RGB", (i0, i1, i2))img.save(join(dst_dir,data_set,meta["fine_label_names"][data_dict["fine_labels"][i]],data_dict["filenames"][i],))
处理完成之后我们就得到了可用的图像数据集了,实例数据如下所示:

可以看到:官方的数据集都是标准的32x32的尺寸,整体来说分辨率还是比较小的:

以下是一些常用的轻量级卷积神经网络模型:
MobileNet:MobileNet是一种基于深度可分离卷积的轻量级模型,通过Depthwise Separable Convolution减少参数量和计算量,适用于移动设备上的图像分类和目标检测。
ShuffleNet:ShuffleNet通过使用通道洗牌操作来减少参数量和计算量。它采用逐点卷积和组卷积,将通道分为组并进行特征图的混洗,以增加特征的多样性。
EfficientNet:EfficientNet是一系列模型,通过使用复合缩放方法在深度、宽度和分辨率上进行均衡扩展。它在减少参数和计算量的同时,保持高准确性。
MobileNetV3:MobileNetV3是MobileNet的改进版本,引入了候选网络和网络搜索方法,通过优化模型结构和激活函数,进一步提升了轻量级模型的性能。
ProxylessNAS:ProxylessNAS是使用神经网络搜索算法来自动搜索轻量级模型结构的方法。它通过替代器生成网络中的每个操作,以有效地搜索高效的模型结构。
SqueezeNet:SqueezeNet是一种极小化的卷积神经网络模型,使用Fire模块将降维卷积和扩展卷积组合在一起,以减少参数量和计算量。
这些轻量级模型在参数量和计算量上相对较少,适用于资源受限的设备或场景。然而,每个模型都有不同的性能和特点,根据应用需求和资源限制,选择合适的模型进行使用。同时,还可以根据具体任务的要求进行模型的调整和优化。
GhostNet是一种轻量级的卷积神经网络模型,旨在在计算资源有限的设备上实现高效的图像分类和目标检测。其主要原理是通过使用Ghost Module来减少参数量和计算量,并提高模型在资源受限条件下的性能。
Ghost Module是GhostNet的关键组成部分,其主要思想是通过将一个普通的卷积层分解为两个部分:主要卷积(或称为Ghost指示器)和辅助卷积。具体构建原理如下:
主要卷积(Ghost指示器):该部分包含少量的输出通道数(称为精简通道),可以看作是对原始卷积的一种降维表示。它对输入进行低维特征提取,并通过学习有效的过滤器来减少参数量和计算量。
辅助卷积:该部分包含更多的输出通道数(称为扩展通道),用于捕捉更丰富的特征表达。这种设计有助于模型在较少的参数量下保持较高的表示能力,提高对复杂图像的判别能力。
GhostNet模型的优点如下:
轻量高效:GhostNet通过使用Ghost Module,减少了模型的参数量和计算量,使得它在计算资源受限的设备上运行速度更快,能够满足更多应用的需求。
参数效率:Ghost Module通过以较少的参数产生较多的特征图,提高了参数的利用效率。这使得模型更具可扩展性,并能够更好地适应低功耗的设备和移动端应用需求。
准确性保持:尽管GhostNet是为了追求高效而设计的,但经过实证研究表明,在一些图像分类和目标检测任务中,它的准确性能够与一些常用的大型模型相媲美,或接近。
GhostNet模型的缺点如下:
空间复杂性:尽管GhostNet在参数和计算量上显著减少,但由于采用了辅助卷积来提取更丰富的特征,其空间复杂性相对较高。这可能使得在计算资源极度有限的设备上推理速度较慢。
特定任务的局限性:GhostNet主要用于图像分类和目标检测任务。对于其他类型的任务,如语义分割或实例分割等,GhostNet可能需要额外的定制和改进来适应任务的需求。
总之,GhostNet作为一种轻量级的模型设计,通过Ghost Module降低了模型的参数量和计算量,提高了在计算资源有限的设备上的性能。尽管存在一些局限性,但它在保持一定准确性的同时,能够在资源受限情况下提供高效的图像分类和目标检测能力。
在以往的项目中使用Mobilenet模型居多,较少使用GhostNet,所以这里以实地项目开发的方式也是想进一步熟悉GhostNet模型,这里模型搭建实现代码如下所示:
# encoding:utf-8
from __future__ import division"""
__Author__:沂水寒城
功能: GhostNet
"""import torch
import torch.nn as nn
import math
import numpy as np
from torch.hub import load_state_dict_from_url
from utils.utils import load_weights_from_state_dictdef _make_divisible(v, divisor, min_value=None):"""参考https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py"""if min_value is None:min_value = divisornew_v = max(min_value, int(v + divisor / 2) // divisor * divisor)if new_v < 0.9 * v:new_v += divisorreturn new_vclass SELayer(nn.Module):"""SE Layer"""def __init__(self, channel, reduction=4):super(SELayer, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.fc = nn.Sequential(nn.Linear(channel, channel // reduction),nn.ReLU(inplace=True),nn.Linear(channel // reduction, channel),)def forward(self, x):b, c, _, _ = x.size()y = self.avg_pool(x).view(b, c)y = self.fc(y).view(b, c, 1, 1)y = torch.clamp(y, 0, 1)return x * ydef depthwise_conv(inp, oup, kernel_size=3, stride=1, relu=False):"""DW"""return nn.Sequential(nn.Conv2d(inp, oup, kernel_size, stride, kernel_size // 2, groups=inp, bias=False),nn.BatchNorm2d(oup),nn.ReLU(inplace=True) if relu else nn.Sequential(),)class GhostModule(nn.Module):"""Ghost"""def __init__(self, inp, oup, kernel_size=1, ratio=2, dw_size=3, stride=1, relu=True):super(GhostModule, self).__init__()self.oup = oupinit_channels = math.ceil(oup / ratio)new_channels = init_channels * (ratio - 1)self.primary_conv = nn.Sequential(nn.Conv2d(inp, init_channels, kernel_size, stride, kernel_size // 2, bias=False),nn.BatchNorm2d(init_channels),nn.ReLU(inplace=True) if relu else nn.Sequential(),)self.cheap_operation = nn.Sequential(nn.Conv2d(init_channels,new_channels,dw_size,1,dw_size // 2,groups=init_channels,bias=False,),nn.BatchNorm2d(new_channels),nn.ReLU(inplace=True) if relu else nn.Sequential(),)def forward(self, x):x1 = self.primary_conv(x)x2 = self.cheap_operation(x1)out = torch.cat([x1, x2], dim=1)return out[:, : self.oup, :, :]class GhostBottleneck(nn.Module):"""GhostBottleneck"""def __init__(self, inp, hidden_dim, oup, kernel_size, stride, use_se):super(GhostBottleneck, self).__init__()assert stride in [1, 2]self.conv = nn.Sequential(GhostModule(inp, hidden_dim, kernel_size=1, relu=True),depthwise_conv(hidden_dim, hidden_dim, kernel_size, stride, relu=False)if stride == 2else nn.Sequential(),SELayer(hidden_dim) if use_se else nn.Sequential(),GhostModule(hidden_dim, oup, kernel_size=1, relu=False),)if stride == 1 and inp == oup:self.shortcut = nn.Sequential()else:self.shortcut = nn.Sequential(depthwise_conv(inp, inp, 3, stride, relu=True),nn.Conv2d(inp, oup, 1, 1, 0, bias=False),nn.BatchNorm2d(oup),)def forward(self, x):return self.conv(x) + self.shortcut(x)class GhostNet(nn.Module):"""GhostNet"""def __init__(self, cfgs, num_classes=1000, width_mult=1.0):super(GhostNet, self).__init__()self.cfgs = cfgsoutput_channel = _make_divisible(16 * width_mult, 4)layers = [nn.Sequential(nn.Conv2d(3, output_channel, 3, 2, 1, bias=False),nn.BatchNorm2d(output_channel),nn.ReLU(inplace=True),)]input_channel = output_channelblock = GhostBottleneckfor k, exp_size, c, use_se, s in self.cfgs:output_channel = _make_divisible(c * width_mult, 4)hidden_channel = _make_divisible(exp_size * width_mult, 4)layers.append(block(input_channel, hidden_channel, output_channel, k, s, use_se))input_channel = output_channelself.features = nn.Sequential(*layers)output_channel = _make_divisible(exp_size * width_mult, 4)self.squeeze = nn.Sequential(nn.Conv2d(input_channel, output_channel, 1, 1, 0, bias=False),nn.BatchNorm2d(output_channel),nn.ReLU(inplace=True),nn.AdaptiveAvgPool2d((1, 1)),)input_channel = output_channeloutput_channel = 1280self.classifier = nn.Sequential(nn.Linear(input_channel, output_channel, bias=False),nn.BatchNorm1d(output_channel),nn.ReLU(inplace=True),nn.Dropout(0.2),nn.Linear(output_channel, num_classes),)self._initialize_weights()def forward(self, x, need_fea=False):if need_fea:features, features_fc = self.forward_features(x, need_fea)x = self.classifier(features_fc)return features, features_fc, xelse:x = self.forward_features(x)x = self.classifier(x)return xdef forward_features(self, x, need_fea=False):if need_fea:input_size = x.size(2)scale = [4, 8, 16, 32]features = [None, None, None, None]for idx, layer in enumerate(self.features):x = layer(x)if input_size // x.size(2) in scale:features[scale.index(input_size // x.size(2))] = xx = self.squeeze(x)return features, x.view(x.size(0), -1)else:x = self.features(x)x = self.squeeze(x)return x.view(x.size(0), -1)def _initialize_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")elif isinstance(m, nn.BatchNorm2d):m.weight.data.fill_(1)m.bias.data.zero_()def cam_layer(self):return self.features[-1]可以直接去华为开源仓库里面或者是开源社区其他的项目里面选择自己喜欢的代码实现即可,不需要自己去重头实现,理解应用即可。这里就不再赘述了,很多项目整体已经是比较完善的了。
这里对模型预测结果也进行了簇群可视化,如下所示:
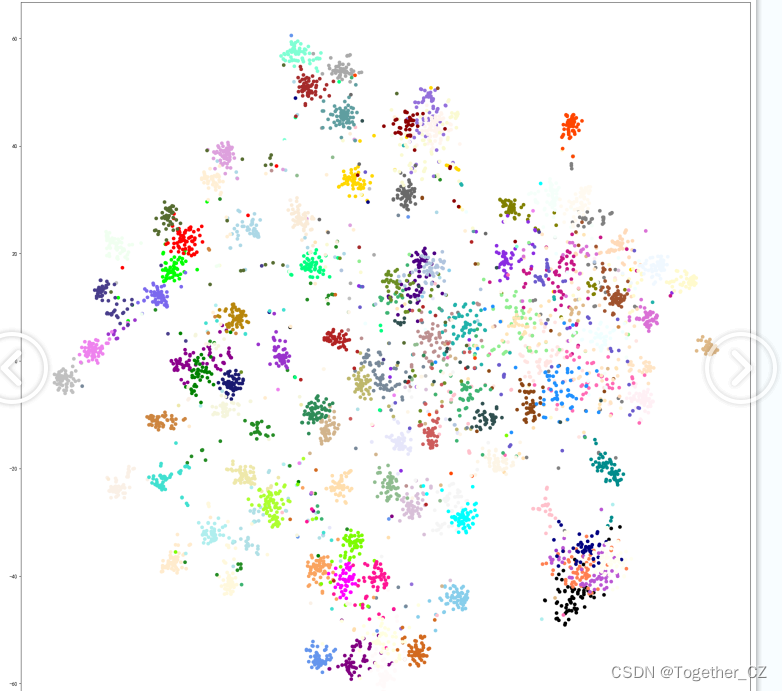
这里类别比较多,显得比较混乱一些,接下来绘制模型的混淆矩阵,如下所示:
训练过程中,loss走势曲线和acc变化曲线如下所示:
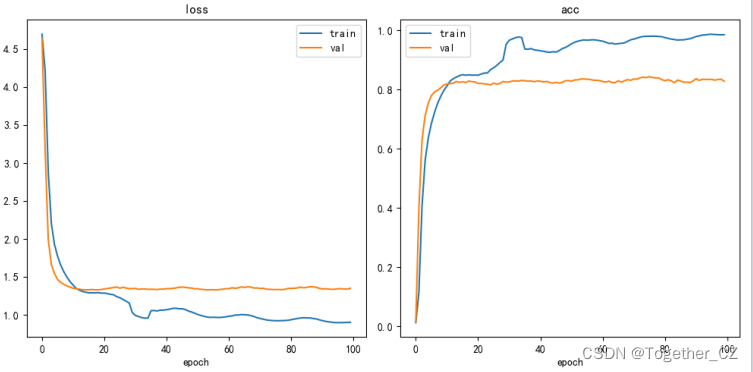
这组实验结果是在224x224的标准尺寸下得到的结果。
前面我们讲到过官方原始的数据集其实是32x32的小尺寸数据集,这里我们做了第二组的实验,就是直接使用官方的尺寸来进行模型的开发训练,得到结果详情如下所示:
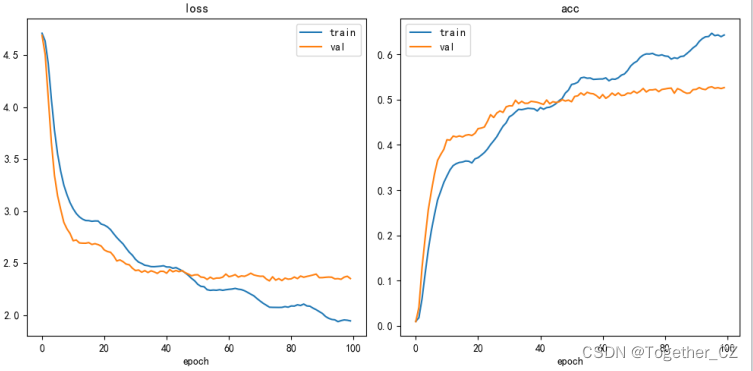
可以看到:32x32的尺寸图像精度与224x224的尺寸图像差了40%左右的精度,不难分析出图像的原始分辨率对于最终的分类识别效果的影响是巨大的。
混淆矩阵如下:
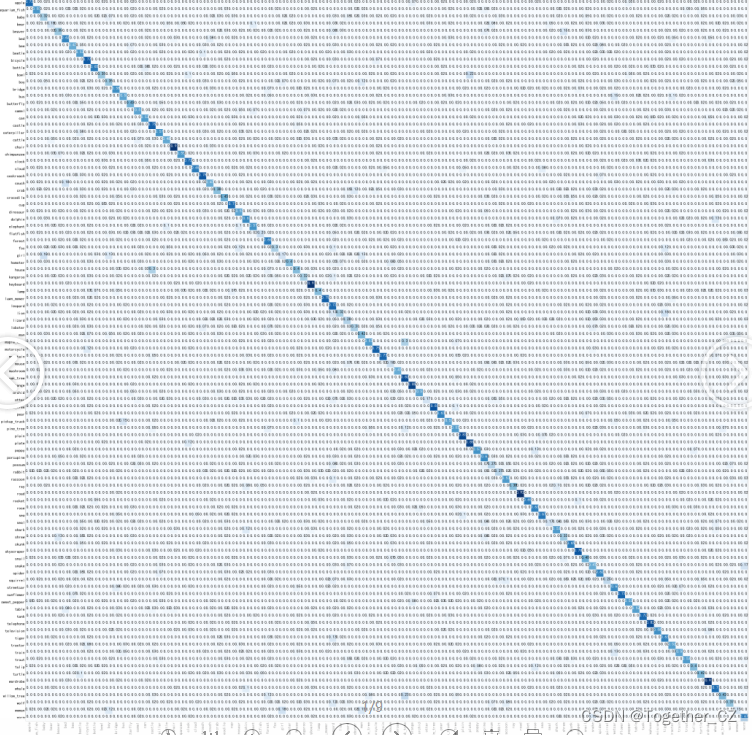
详细指标的对比结果如下:
224x224尺度图像结果
+------------+-----------+-----------+----------+
| train_loss | test_loss | train_acc | test_acc |
+------------+-----------+-----------+----------+
| 0.92347 | 1.33351 | 0.97965 | 0.84315 |
+------------+-----------+-----------+----------+32x32尺度图像结果
+------------+-----------+-----------+----------+
| train_loss | test_loss | train_acc | test_acc |
+------------+-----------+-----------+----------+
| 1.93752 | 2.35085 | 0.64693 | 0.52852 |
+------------+-----------+-----------+----------+感兴趣的话也都可以对应实践尝试下!