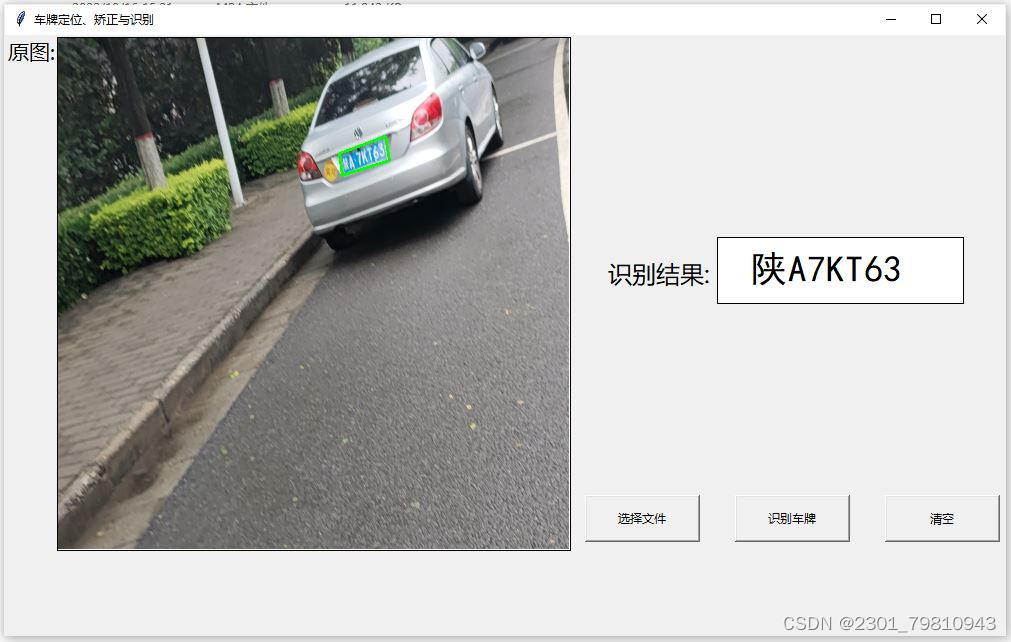
文章目录
- 关于 NebulaGraph
- 客户端支持
- 安装 NebulaGraph
- 关于 nGQL
- nGQL 可以做什么
- 2500 条 nGQL 示例
- 原生 nGQL 和 openCypher 的关系
- Backup&Restore
- 功能
- 导入导出
- 导入工具
- 导出工具
- NebulaGraph Importer
- NebulaGraph Exchange
- NebulaGraph Spark Connector
- NebulaGraph Flink Connectors
- NebulaGraph Studio
- NebulaGraph Dashboard
- 产品功能
- NebulaGraph Operator
- 工作原理
- 功能介绍
- NebulaGraph Algorithm 图计算
- NebulaGraph Bench
关于 NebulaGraph
-
官网:https://www.nebula-graph.com.cn
-
官方文档:https://docs.nebula-graph.com.cn/3.8.0/
手册PDF : https://docs.nebula-graph.com.cn/3.8.0/pdf/NebulaGraph-CN.pdf
客户端支持
NebulaGraph 提供多种类型客户端,便于用户连接、管理 NebulaGraph 图数据库。
- NebulaGraph Console:原生 CLI 客户端
- NebulaGraph CPP:C++ 客户端
- NebulaGraph Java:Java 客户端
- NebulaGraph Python:Python 客户端
- NebulaGraph Go:Go 客户端
安装 NebulaGraph
有以下安装方式:
- 基于 Docker
- 从云开始(免费试用)
- 本地部署步骤 1:安装 NebulaGraph
releases : https://github.com/vesoft-inc/nebula-console/releases
关于 nGQL
nGQL是 NebulaGraph 使用的的声明式图查询语言,支持灵活高效的图模式,而且 nGQL 是为开发和运维人员设计的类 SQL 查询语言,易于学习。
nGQL 是一个进行中的项目,会持续发布新特性和优化,因此可能会出现语法和实际操作不一致的问题,如果遇到此类问题,请提交 issue 通知 NebulaGraph 团队。 NebulaGraph 3.0 及更新版本正在支持 openCypher 9。
nGQL 可以做什么
- 支持图遍历
- 支持模式匹配
- 支持聚合
- 支持修改图
- 支持访问控制
- 支持聚合查询
- 支持索引
- 支持大部分 openCypher 9 图查询语法(不支持修改和控制语法)
2500 条 nGQL 示例
https://github.com/vesoft-inc/nebula/tree/master/tests/tck/features
features 目录内包含很多.features格式的文件,每个文件都记录了使用 nGQL 的场景和示例。例如:
原生 nGQL 和 openCypher 的关系
原生 nGQL 是由 NebulaGraph 自行创造和实现的图查询语言。openCypher 是由 openCypher Implementers Group 组织所开源和维护的图查询语言,最新版本为 openCypher 9。
由于 nGQL 语言部分兼容了 openCypher,这个部分在本文中称为 openCypher 兼容语句。
Backup&Restore
Backup&Restore(简称 BR)是一款命令行界面(CLI)工具,可以帮助备份 NebulaGraph 的图空间数据,或者通过备份文件恢复数据。
功能
- 一键操作备份和恢复数据。
- 支持基于以下备份文件恢复数据:
- 本地磁盘(SSD 或 HDD),建议仅在测试环境使用。
- 兼容亚马逊对象存储(Amazon S3)云存储服务接口,例如:阿里云对象存储(Alibaba Cloud OSS)、MinIO、Ceph RGW 等。
- 支持备份并恢复整个 NebulaGraph 集群。
- (实验性功能)支持备份指定图空间数据。
导入导出
导入工具
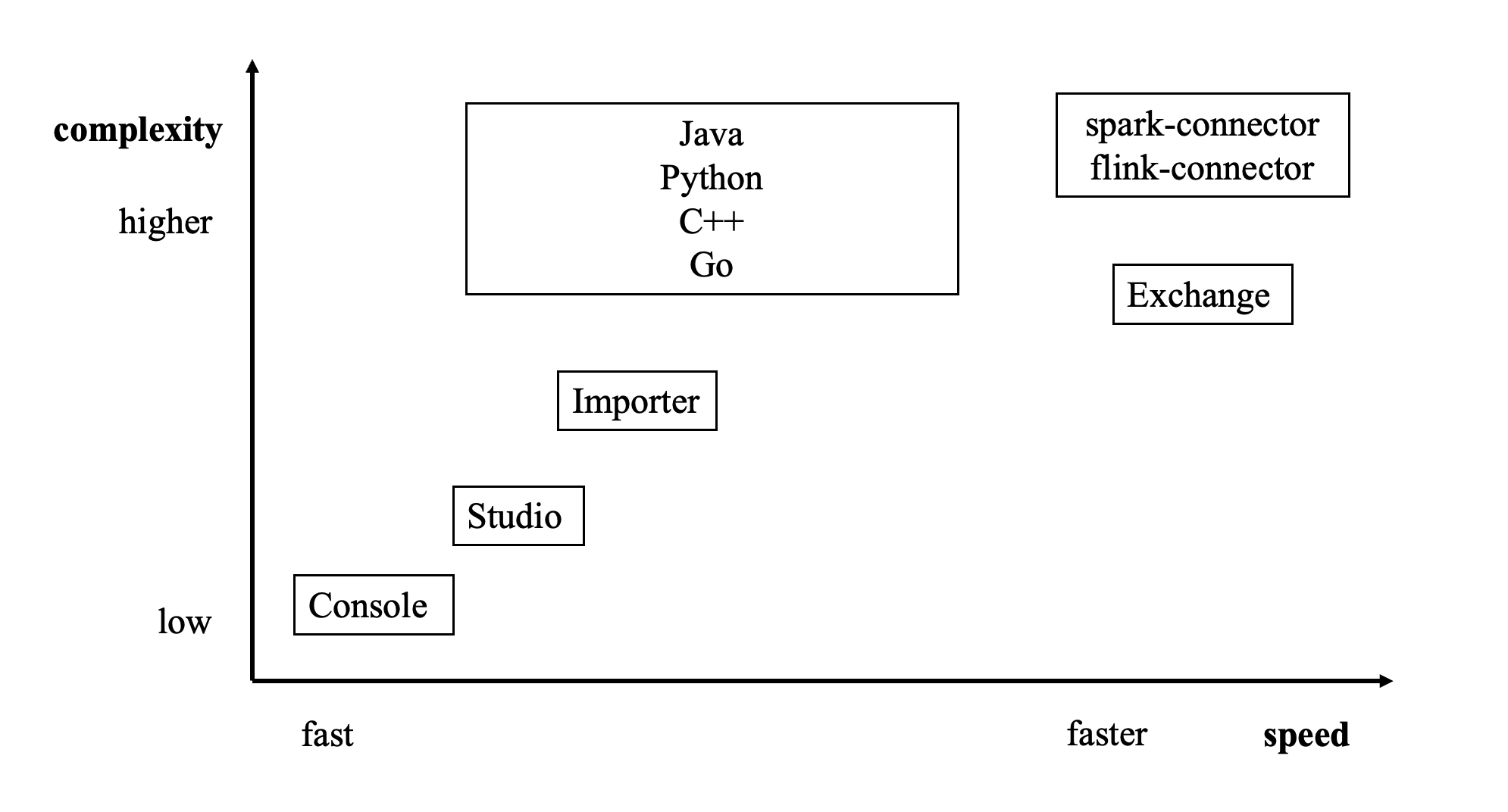
有多种方式可以将数据写入NebulaGraph 3.8.0:
- 使用命令行 -f 的方式导入:可以导入少量准备好的 nGQL 文件,适合少量手工测试数据准备。
- 使用 Studio 导入:可以用过浏览器导入本机多个 CSV 文件,格式有限制。
- 使用 Importer 导入:导入单机多个 CSV 文件,大小没有限制,格式灵活。适合十亿条数据以内的场景。
- 使用 Exchange 导入:从 Neo4j、Hive、MySQL 等多种源分布式导入,需要有 Spark 集群。适合十亿条数据以上的场景。
- 使用 Spark-connector/Flink-connector 读写 API:这种方式需要编写少量代码来使用 Spark/Flink 连接器提供的 API。
- 使用 C++/GO/Java/Python SDK:编写程序的方式导入,需要有一定编程和调优能力。
下图给出了几种方式的定位:
导出工具
- 使用 Spark-connector/Flink-connector 读写 API:这种方式需要编写少量代码来使用 Spark/Flink 连接器提供的 API。
- 使用 Exchange 导出功能将数据导出至 CSV 文件或另一个图空间(支持不同 NebulaGraph 集群)中。
NebulaGraph Importer
NebulaGraph Importer(简称 Importer)是一款 NebulaGraph 的 CSV 文件单机导入工具,可以读取并批量导入多种数据源的 CSV 文件数据,还支持批量更新和删除操作。
功能
- 支持多种数据源,包括本地、S3、OSS、HDFS、FTP、SFTP、GCS。
- 支持导入 CSV 格式文件的数据。单个文件内可以包含多种 Tag、多种 Edge type 或者二者混合的数据。
- 支持过滤数据源数据。
- 支持批量操作,包括导入、更新、删除。
- 支持同时连接多个 Graph 服务进行导入并且动态负载均衡。
- 支持失败后重连、重试。
- 支持多维度显示统计信息,包括导入时间、导入百分比等。统计信息支持打印在 Console 或日志中。
- 支持 SSL 加密。
NebulaGraph Exchange
NebulaGraph Exchange(简称 Exchange)是一款 Apache Spark™ 应用,用于在分布式环境中将集群中的数据批量迁移到 NebulaGraph 中,能支持多种不同格式的批式数据和流式数据的迁移。
Exchange 由 Reader、Processor 和 Writer 三部分组成。Reader 读取不同来源的数据返回 DataFrame 后,Processor 遍历 DataFrame 的每一行,根据配置文件中fields的映射关系,按列名获取对应的值。在遍历指定批处理的行数后,Writer 会将获取的数据一次性写入到 NebulaGraph 中。下图描述了 Exchange 完成数据转换和迁移的过程。
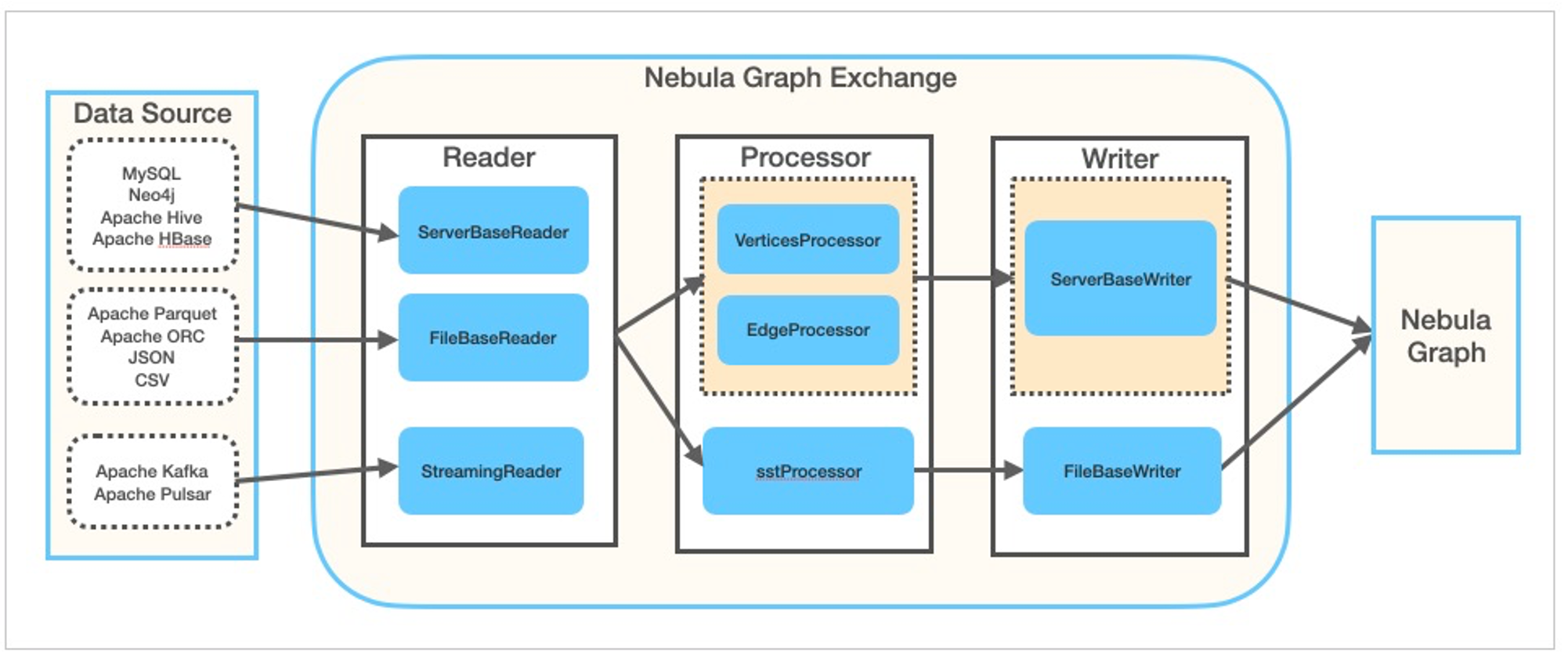
Exchange 有社区版和企业版两个系列,二者功能不同。社区版在 GitHub 开源开发,企业版属于 NebulaGraph 企业套餐。
NebulaGraph Spark Connector
详情:https://github.com/vesoft-inc/nebula-spark-connector/blob/release-3.8/README_CN.md
NebulaGraph Spark Connector 是一个 Spark 连接器,提供通过 Spark 标准形式读写 NebulaGraph 数据的能力。NebulaGraph Spark Connector 由 Reader 和 Writer 两部分组成。
- Reader
提供一个 Spark SQL 接口,用户可以使用该接口编程读取 NebulaGraph 图数据,单次读取一个点或 Edge type 的数据,并将读取的结果组装成 Spark 的 DataFrame。 - Writer
提供一个 Spark SQL 接口,用户可以使用该接口编程将 DataFrame 格式的数据逐条或批量写入 NebulaGraph 。
NebulaGraph Flink Connectors
NebulaGraph Flink Connector 是一款帮助 Flink 用户快速访问NebulaGraph的连接器,支持从NebulaGraph图数据库中读取数据,或者将其他外部数据源读取的数据写入NebulaGraph图数据库。
NebulaGraph Studio
NebulaGraph Studio(简称 Studio)是一款可以通过 Web 访问的开源图数据库可视化工具,搭配 NebulaGraph 内核使用,提供构图、数据导入、编写 nGQL 查询等一站式服务。
用户可以在 NebulaGraph GitHub 仓库中查看最新源码,详情参见 nebula-studio https://github.com/vesoft-inc/nebula-studio。
Studio 可以方便管理 NebulaGraph 数据,具备以下功能:
- 使用 Schema 管理功能,用户可以使用图形界面完成图空间、Tag(标签)、Edge Type(边类型)、索引的创建,查看图空间的统计数据,快速上手 NebulaGraph 。
- 使用导入功能,通过简单的配置,用户即能批量导入点和边数据,并能实时查看数据导入日志。
- 使用控制台功能,用户可以使用 nGQL 语句创建 Schema,并对数据执行增删改查操作。
NebulaGraph Dashboard
NebulaGraph Dashboard(简称 Dashboard)是一款用于监控 NebulaGraph 集群中机器和服务状态的可视化工具。
产品功能
- 监控集群中所有机器的状态,包括 CPU、内存、负载、磁盘和流量。
- 监控集群中所有服务的信息,包括服务 IP 地址、版本和监控指标(例如查询数量、查询延迟、心跳延迟等)。
- 监控集群本身的信息,包括集群的服务信息、分区信息、配置和长时任务。
- 支持全局调整监控数据的页面更新频率。
NebulaGraph Operator
NebulaGraph Operator 是用于在 Kubernetes 系统上自动化部署和运维 NebulaGraph 集群的工具。
依托于 Kubernetes 扩展机制,NebulaGraph 将其运维领域的知识全面注入至 Kubernetes 系统中,让 NebulaGraph 成为真正的云原生图数据库。
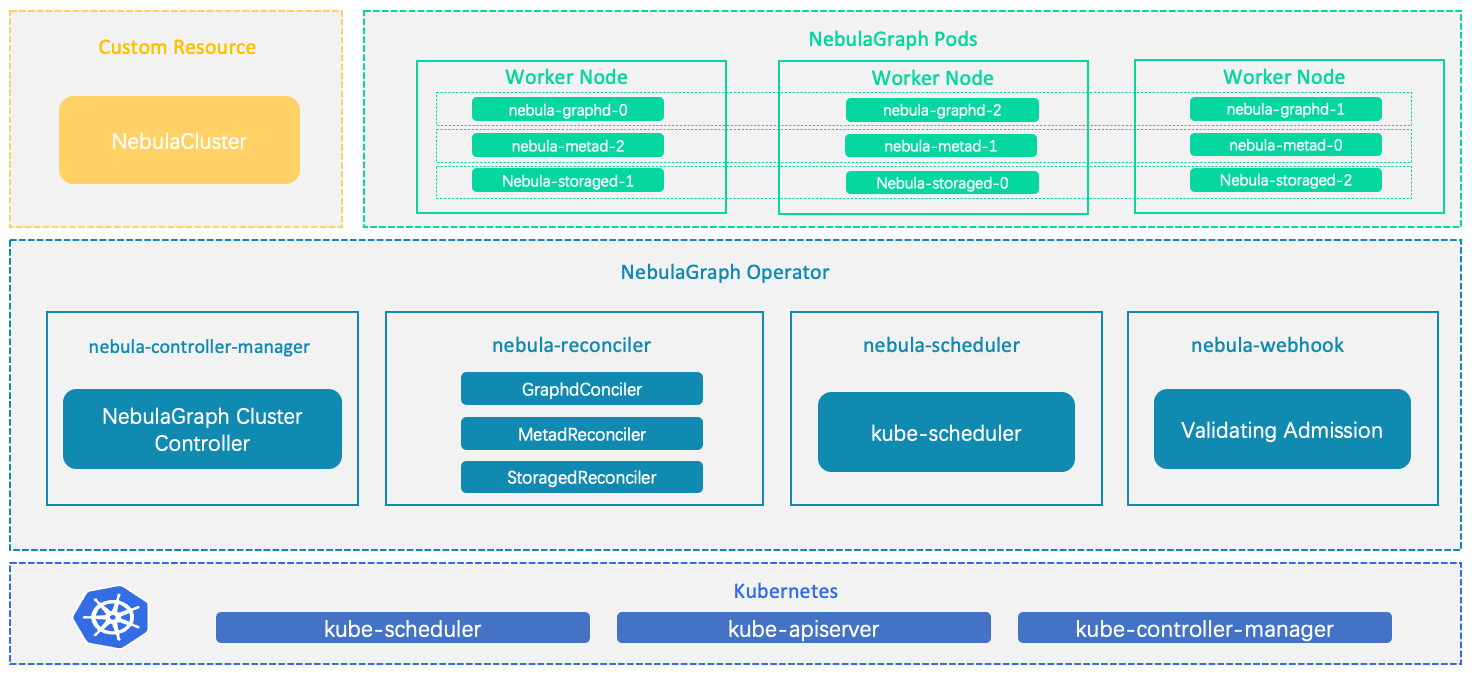
工作原理
对于 Kubernetes 系统内不存在的资源类型,用户可以通过添加自定义 API 对象的方式注册,常见的方法是使用 CustomResourceDefinition(CRD)。
NebulaGraph Operator 将 NebulaGraph 集群的部署管理抽象为 CRD。通过结合多个内置的 API 对象,包括 StatefulSet、Service 和 ConfigMap,NebulaGraph 集群的日常管理和维护被编码为一个控制循环。在 Kubernetes 系统内,每一种内置资源对象,都运行着一个特定的控制循环,将它的实际状态通过事先规定好的编排动作,逐步调整为最终的期望状态。当一个 CR 实例被提交时,NebulaGraph Operator 会根据控制流程驱动数据库集群进入最终状态。
功能介绍
NebulaGraph Operator 已具备的功能如下:
- 集群创建和卸载:NebulaGraph Operator 简化了用户部署和卸载集群的过程。用户只需提供对应的 CR 文件,NebulaGraph Operator 即可快速创建或者删除一个对应的 NebulaGraph 集群。更多信息参见创建 NebulaGraph 集群。
- 集群升级:支持升级 3.5.0 版的 NebulaGraph 集群至 3.6.0 版。
- 故障自愈:NebulaGraph Operator 调用 NebulaGraph 集群提供的接口,动态地感知服务状态。一旦发现异常,NebulaGraph Operator 自动进行容错处理。更多信息参考故障自愈。
- 均衡调度:基于调度器扩展接口,NebulaGraph Operator 提供的调度器可以将应用 Pods 均匀地分布在 NebulaGraph 集群中。
NebulaGraph Algorithm 图计算
NebulaGraph Algorithm (简称 Algorithm)是一款基于 GraphX 的 Spark 应用程序,通过提交 Spark 任务的形式使用完整的算法工具对 NebulaGraph 数据库中的数据执行图计算,也可以通过编程形式调用 lib 库下的算法针对 DataFrame 执行图计算。
NebulaGraph Bench
NebulaGraph Bench 是一款利用 LDBC 数据集对 NebulaGraph 进行性能测试的工具。
2024-05-21(二)