1. 累加器
累加器:分布式共享只写变量
考虑如下计算RDD中数据的和:
val rdd = sc.makeRDD(List(1, 2, 3, 4))var sum = 0
rdd.foreach(num => {sum += num}
)println("sum = " + sum)预期结果10,但其实不是
![]()
foreach里面的函数是在Executor节点分布式执行的,所以多个分布式节点来同时修改sum,但是这个sum是Driver传给Executor的,各个Executor执行完并不会将sum返回给Driver,所以Driver端执行打印sum,sum依然为0。如果需要将最终的计算结果返回给Driver,就要使用到累加器变量。
累加器用来把Executor端变量信息聚合到Driver端。在Driver程序中定义的累加器变量,在Executor端会得到这个变量的一个新的副本,执行任务更新完这个副本之后,传回Driver端进行聚合。
使用累加器:
val rdd = sc.makeRDD(List(1, 2, 3, 4))val sum = sc.longAccumulator("sum")rdd.foreach(num => {sum.add(num)
})println("sum = " + sum.value)如果转换算子中使用了累加器,最终没有调用行动算子,那么实际也不会执行计算,例如下面代码sum依然为0
val rdd = sc.makeRDD(List(1, 2, 3, 4))val sum = sc.longAccumulator("sum")rdd.map(num => {sum.add(num)num
})println("sum = " + sum.value)注意,使用累加器最终执行行动算子不止一次,可能最终结果不符合预期
val rdd = sc.makeRDD(List(1, 2, 3, 4))val sum = sc.longAccumulator("sum")val mapRDD = rdd.map(num => {sum.add(num)num
})mapRDD.collect()
mapRDD.collect()
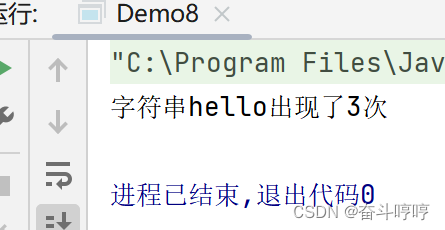
println("sum = " + sum.value)![]()
所以一般累加器需要放在行动算子里进行操作。
使用累加器实现WordCount,以避免Shuffle操作。首先定义一个自定义累加器,以实现map的累加(因为Spark中只有List集合的累加)
// AccumulatorV2泛型:IN:输入类型; OUT:输出类型
class MyAccumulator extends AccumulatorV2[String, mutable.Map[String, Long]] {private var wcMap = mutable.Map[String, Long]// 判断是否是初始状态override def isZero : Boolean = {wcMap.isEmpty}override def copy() : AccumulatorV2[String, mutable.Map[String, Long]] = {new MyAccumulator()}override def reset() : Unit = {wcMap.clear()}// 累加函数,每新来一个输入,如何累加override def add(word : String) : Unit = {val newCnt = wcMap.getOrElse(word, 0L) + 1wcMap.update(word, newCnt);}// 合并函数,由Driver执行,这里本质是两个map的合并override def merge(other : AccumulatorV2[String, mutable.Map[String, Long]]) : Unit = {val map1 = wcMapval map2 = othermap2.foreach{case(word, count) => {val newCnt = map1.getOrElse(word, 0L) + countmap1.update(word, newCnt)}}
}override def value : mutable.Map[String, Long] = {wcMap}
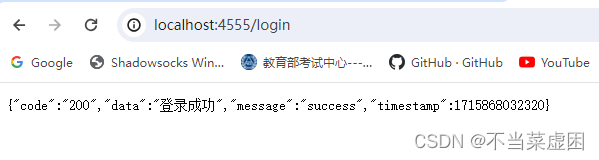
}val rdd = sc.makeRDD(List("hello", "spark", "hello"))val myAcc = sc.newMyAccumulator()
sc.register(myAcc, "wordCountAcc")rdd.foreach(word => {myAcc.add(word)
})println(myAcc.value)![]()
2. 广播变量
累加器:分布式共享只读变量
如果想实现两个rdd的相同key的value连接起来,一般会想到join算子,但是join是笛卡尔乘积,且存在shuffle,严重影响性能。可采用如下代码实现类似功能:
val rdd = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3)))val map = mutable.Map(("a", 4), ("b", 5), ("c", 6))rdd1.map {case(w, c) => {val l : Int = map.getOrElse(w, 0)(w, (c, l))}
}.collect.foreach(println)
上述代码存在一个问题,map算子内的函数是在Executor内执行的(具体来说是Executor里的task执行的),里面用到了map这份数据,如果map很大,那么每个Executor的每个task都会包含这份大数据,非常占用内存,影响性能。于是引入了广播变量的概念,将这种数据存放在每一个Executor的内存中,该Executor中的各个task共享这个只读变量:
val rdd = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3)))val map = mutable.Map(("a", 4), ("b", 5), ("c", 6))val bc : Broadcast[mutable.Map[String, Int]] = sc.broadcast(map)rdd1.map {case(w, c) => {val l : Int = bc.value.getOrElse(w, 0)(w, (c, l))}
}.collect.foreach(println)
3. 案例需求
1)已经从原始日志文件中读出了商品的点击数量rdd、下单数量rdd、支付数量rdd,都是(商品id, cnt)的形式,需要将这三种rdd组合成(商品id, (点击数量, 下单数量, 支付数量))的rdd,并且依次按照点击数量、下单数量、 支付数量排序取前十。
很自然地想到组合rdd的算子join,但是join只能组合相同的key,如果一个商品只有点击没有下单,那么使用join是不会出现在最终结果的,同理leftOuterJoin和rightOuterJoin也是类似的,不能实现相应的功能。因此只有cogroup算子满足要求,cogroup = connect + group。(join和cogroup算子的功能示例参见:RDD算子介绍(三))
val cogroupRDD : RDD[(String, (Iterable[Int], Iterable[Int], Iterable[Int]))]= clickRDD.cogroup(orderRDD, payRDD)val resultRDD = cogroupRDD.mapValues{case(clickIter, orderIter, payIter) => {var clickCnt = 0val iter1 = clickIter.iteratorif (iter1.hasNext) {clickCnt = iter1.next()}var orderCnt = 0val iter2 = orderIter.iteratorif (iter2.hasNext) {orderCnt = iter2.next()}var payCnt = 0val iter3 = payIter.iteratorif (iter3.hasNext) {payCnt = iter1.next()}(clickCnt, orderCnt, payCnt)}
}resultRDD.sortBy(_._2, false).take(10).foreach(println)上述实现方式使用了cogroup算子,该算子可能存在shuffle,且该算子不常用,可以采用另外一种方式实现。首先将商品的点击数量rdd、下单数量rdd、支付数量rdd转换为(商品id, (clickCnt, orderCnt, payCnt))的形式,然后进行union,最后进行聚合。
val rdd1 = clickRDD.map {case (id, cnt) => {(id, (cnt, 0, 0)}
}val rdd2 = orderRDD.map {case (id, cnt) => {(id, (0, cnt, 0)}
}val rdd3 = payRDD.map {case (id, cnt) => {(id, (0, 0, cnt)}
}val rdd : RDD[(String, (Int, Int, Int))] = rdd1.union(rdd2).union(rdd3)val resultRDD = rdd.reduceByKey((t1, t2) => {(t1._1 + t2._1, t1._2 + t2._2, t3._3 + t3._3)
})resultRDD.sortBy(_._2, false).take(10).foreach(println)上述代码使用了reduceByKey,还是会有shuffle操作,要完全避免shuffle操作,可以使用foreach算子,如果要使用foreach算子,就必须使用累加器了。这个累加器的作用就是遍历原始数据,按照商品id进行分组,对商品的用户行为类型(点击、下单、支付)对进行数量统计。可以将商品的用户行为(点击、下单、支付)数量封装成一个样例类HotCatagory,然后这个累加器的输入就是商品id+行为类型(点击、下单、支付),输出就是这个样例类的集合。具体实现过程参考https://www.bilibili.com/video/BV11A411L7CK?p=116&spm_id_from=pageDriver&vd_source=23ddeeb1fb342c5293413f7b87367160
2)统计页面的跳转率。所谓某个页面A到某个页面B的跳转率,就是页面A到页面B的次数/页面A的点击次数。首先统计各个页面的点击次数,数据结构为map,作为分母。对于分子,需要按照sessionId进行分组,然后按照时间排序,这样才能得到各个用户浏览页面的顺序,然后转换数据结构,统计各个页面到其他页面的跳转次数。
actionDataRDD.cache()// 分母
val pageIdToCountMap : Map[Long, Long] = actionDataRDD.map(action => {(action.page_id, 1L)
}).reduceByKey(_+_).collect.toMapval sessionRDD : RDD[(String, Iterable[UserVisitAction])] = actionDataRDD.groupBy(_.session_id)val mvRDD : RDD[(String, List[((Long, Long), Int)])] = sessionRDD.mapValues(iter => {val sortList : List[UserVisitAction] = iter.toList.sortBy(_.action_time)val flowIds : List[Long] = sortList.map(_.page_id)val pageFlowIds : List[(Long, Long)] = flowIds.zip(flowIds.tail)pageFlowIds.map(t=> (t, 1))}
)// 分子
val dataRDD = mvRDD.map(_._2).flatMap(list=>list).reduceByKey(_+_)dataRDD.foreach {case((page1, page2), sum) => {val cnt : Long = pageIdToCountMap.getOrElse(page1, 0L)println(s"页面${page1}跳转页面${page2}的转换率为" + (sum.toDouble / cnt))}
}