文章目录
- 概述
- 原理介绍
- 核心逻辑
- ModNet 的结构
- 环境配置
- WebUI
- 小结
论文地址
论文GitHub
本文涉及的源码可从Modnet 人像抠图该文章下方附件获取
概述
人像抠图技术在多个领域有着广泛的应用场景,包括但不限于:
- 展馆互动拍照:展馆中使用的抠像拍照系统能够吸引用户,扩大展馆的知名度。用户可以通过抠像拍照软件体验丰富的拍照效果,从而愿意走进展馆。
- 商场引流:商场中的人流量较大,使用抠像拍照系统可以吸引更多顾客前来打卡拍照,聚集人气,引发潮流现象。
- 展会展示:展会中使用抠像拍照系统,不仅能给参观者留下回忆,还能展示上次展会使用抠像拍照软件所拍的照片,增加用户对参展商的好感。
- 图像编辑:在图像编辑软件中,人像抠图是常用操作之一。通过抠图可以将人物从原背景中分离出来,放到新背景中,实现人物换背景的效果。这在电影后期特效、游戏角色置换等领域有很广泛的应用。
- 商业广告:广告制作公司通常需要从各种原始图像中抠出人物,用于广告海报、网站设计、产品宣传等。使用AI人像分割技术,可以减少制作时间,提高制作效率,更加快速准确地实现广告设计。
- 数码相册:AI人像分割人像抠图技术可以帮助数码相册用户抠出自己照片中的人物,使得相册的美观程度得到大幅提升。
- 视频制作:在视频制作中,使用AI人像分割技术可以轻松地将视频中的人物与背景分离,提高视频制作的效率和品质。
- 电商行业:AI抠图技术可以快速地抠出商品图片,帮助商家实现更好的商品展示效果,提高销售量。同时,也可以帮助商家更快速地制作广告、海报等宣传素材。
随着技术的不断进步和应用场景的不断扩展,人像抠图技术将在更多领域发挥重要作用。
原理介绍
人像抠图(Portrait matting)旨在预测一个精确的 alpha 抠图,可以用于提取给定图像或视频中的人物。
MODNet 是一个轻量级的实时无 trimap 人像抠图模型, 与以往的方法相比,MODNet在单个阶段应用显式约束解决抠图子目标,并增加了两种新技术提高效率和鲁棒性。
MODNet 具有更快的运行速度,更准确的结果以及更好的泛化能力。简单来说,MODNet 是一个非常强的人像抠图模型。下面两幅图展示了它的抠图效果。

核心逻辑
ModNet 的结构
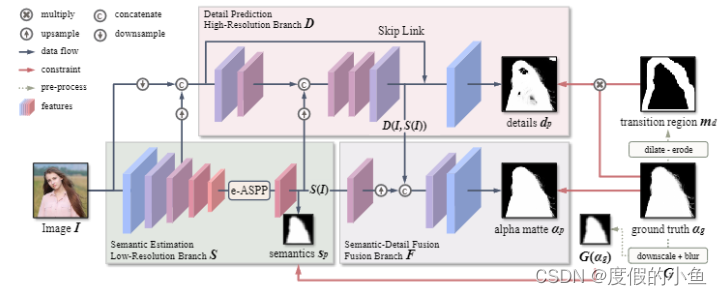
ModNet 基于三个基础模块构建:
- 语义预测(semantic estimation),
- 细节预测(detail prediction),
- 语义-细节混合(semantic-detail fusion)。
分别对应图中的左下(S)、上(D)、右下(F)三个模块。
语义预测主要作用于预测人像的整体轮廓,但是仅仅是一个粗略的前景 mask,用于低分辨率监督信号。细节预测用于区分前景与背景的过度区域,判断该区域内的点属于前景还是背景,可以预测边缘细节,用于高分辨率监测信号。两个相结合便可以实现整体的人像分离。
语义预测模块(S)中使用 channel-wise attention 的 SE-Block。监督信号为使用下采样及高斯模糊后的GT,损失函数采用L2-Loss。

MODNet 中使用 SOC 作为自监督学习策略。在不输入 trimap 的前提下,三个模块之间存在不一致性,所以需要保持三者的一致从而得到一个较好的结果。其具体策略为:
- F 模块与 D 模块在 unknown 区域的取值一致
- F 模块与 S 模块在确定前景与背景区域的取值一致
环境配置
运行 pip install -r requirements.txt 安装所需依赖,并确保你的环境中安装有 PyTorch。在文件夹中运行 python webui.py 即可启动网站,在浏览器中访问 http://0.0.0.0:8080/ 即可进入网页。
官方并没有给出训练代码以及训练数据集,因此本文主要介绍推理的步骤。
项目的结构如下图
首先导入库并加载模型,工作目录为代码所在文件夹。
import gradio as gr
import os, sys
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.transforms as transforms
from src.models.modnet import MODNet
import numpy as np
from PIL import Imagemodnet = MODNet(backbone_pretrained=False)
modnet = nn.DataParallel(modnet)
ckpt_path = "./pretrained/modnet_photographic_portrait_matting.ckpt"if torch.cuda.is_available():modnet = modnet.cuda()weights = torch.load(ckpt_path)
else:weights = torch.load(ckpt_path, map_location=torch.device('cpu'))
modnet.load_state_dict(weights)
modnet.eval()ref_size = 512
之后加载图片并处理数据,此处加载名称为1的图片。

image = '1.jpg'
im = Image.open(image)
im = np.asarray(im)if len(im.shape) == 2:im = im[:, :, None]
if im.shape[2] == 1:im = np.repeat(im, 3, axis=2)
elif im.shape[2] == 4:im = im[:, :, 0:3]im_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
)im = Image.fromarray(im)
im = im_transform(im)
im = im[None, :, :, :]
im_b, im_c, im_h, im_w = im.shape
if max(im_h, im_w) < ref_size or min(im_h, im_w) > ref_size:if im_w >= im_h:im_rh = ref_sizeim_rw = int(im_w / im_h * ref_size)elif im_w < im_h:im_rw = ref_sizeim_rh = int(im_h / im_w * ref_size)else:im_rh = im_him_rw = im_w
im_rw = im_rw - im_rw % 32
im_rh = im_rh - im_rh % 32
im = F.interpolate(im, size=(im_rh, im_rw), mode='area')
得到可以处理的数据im后,投入模型进行推理。将得到的结果保存为名为 temp.png 的图片。
_, _, matte = modnet(im.cuda() if torch.cuda.is_available() else im, True)
matte = F.interpolate(matte, size=(im_h, im_w), mode='area')
matte = matte[0][0].data.cpu().numpy()
matte_temp = './temp.png'
运行之后得到结果,可以看见模型很好的得到了人像

WebUI
在原项目的基础上,构建了一个 WebUI 方便大家进行操作,界面如下所示
拖拽你想抠图的人像到左侧的上传框中,点击提交,等待片刻即可在右侧得到对应的结果。此处使用 flickr 的图片进行演示。
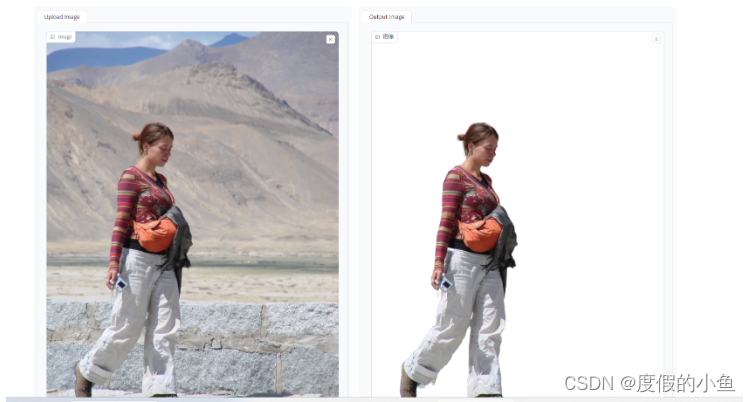
模型推导的 mask 会暂时保存在 temp 文件夹中,例如上面的图像得到的就是下图:

小结
在深度学习中,人像抠图通常使用全卷积网络(FCN)或类似U-Net的编解码器架构来实现。这些网络模型通过训练学习如何区分图像中的人像和背景,并生成一个掩码(mask),该掩码标识了人像的像素位置。
实现高质量的人像抠图:
- 选择适当的模型架构:你可以考虑使用U-Net、DeepLab、Mask R-CNN等流行的语义分割模型作为基础。这些模型已经在多个数据集上证明了其有效性。
- 收集并标注数据集:为了训练你的模型,你需要一个包含人像和背景标注的图像数据集。你可以使用开源数据集,如PASCAL VOC、COCO或自定义数据集。确保数据集足够大且多样化,以涵盖不同场景下的人像。
- 数据增强:为了提高模型的泛化能力,你可以应用各种数据增强技术,如旋转、缩放、裁剪、翻转和颜色变换等。
- 损失函数:选择适当的损失函数对于训练高质量的抠图模型至关重要。常用的损失函数包括交叉熵损失、Dice损失、Focal损失等。你可以根据你的任务需求和数据集特点选择合适的损失函数或组合使用。
- 优化器和学习率调度:选择合适的优化器(如Adam、SGD等)和学习率调度策略(如固定学习率、阶梯学习率衰减等)对于模型的训练过程至关重要。确保你的模型能够稳定地收敛并达到最佳性能。
- 后处理:在生成最终的人像抠图结果之前,你可以应用一些后处理技术来改进结果。例如,你可以使用形态学操作(如膨胀、腐蚀)来平滑掩码的边界,或者使用条件随机场(CRF)等模型来进一步优化掩码的质量。
- 评估与调整:在训练过程中和训练结束后,使用适当的评估指标(如像素准确率、IoU等)来评估你的模型性能。根据评估结果调整模型的超参数或架构以提高性能。
人像抠图是一个具有挑战性的任务,特别是在处理复杂背景和遮挡情况时。因此,你可能需要多次迭代和调整你的模型以达到最佳性能。