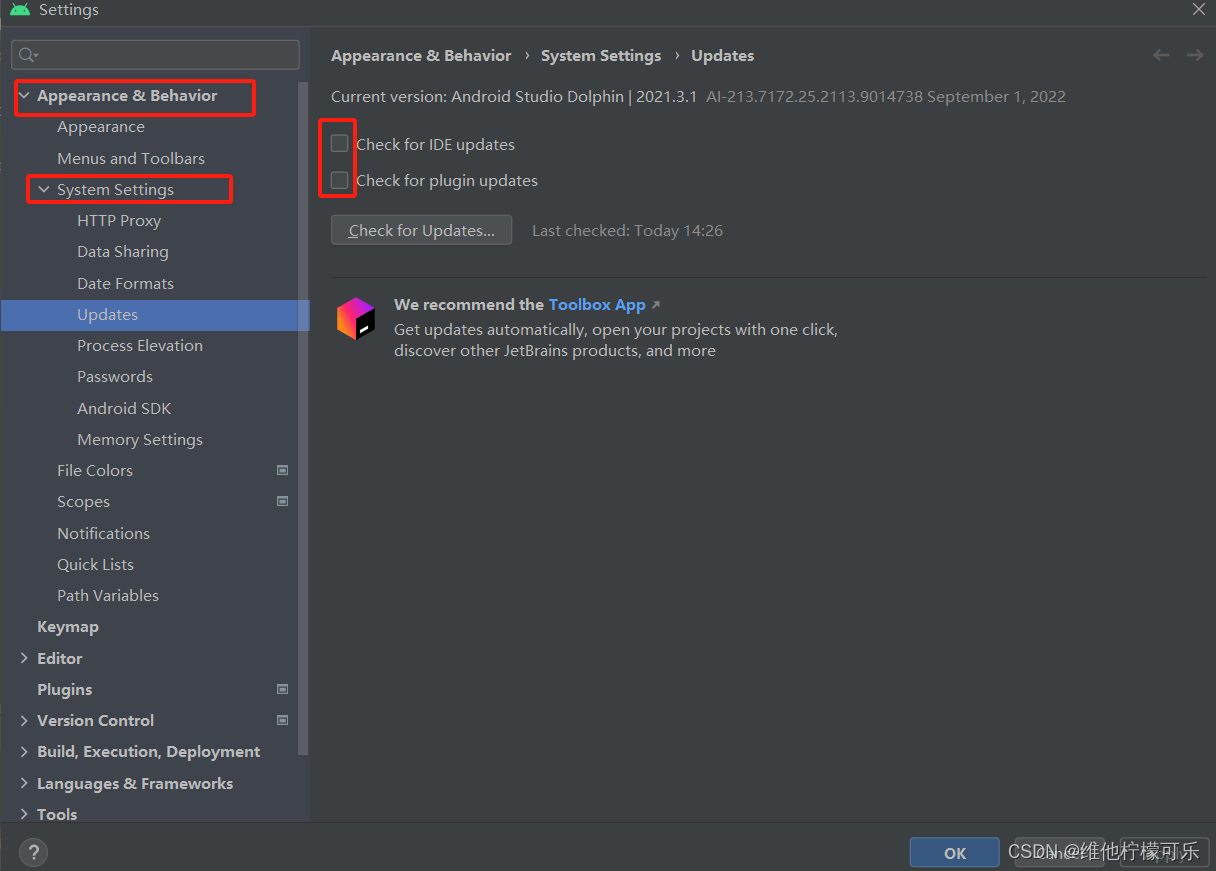
近一个月左右的时间学习爬虫,在用所积累的知识爬取了《中国大学排名》这个网站,爬取的内容虽然只是可见的文本,但对于初学者来说是一个很好的练习。在爬取的过程中,通过请求数据、解析内容、提取文本、存储数据等几个重要的内容入手,不过在存储数据后的数据排版方面并不是很完善(优化),希望阅读本文章的学者大大给些存储后的数据排版方面的指点:中文对齐的问题
文章目录
- 前言🌟
- 一、🍉从网络上获取大学排名网页内容— getHTMLText()
- 二、🍉提取网页内容中信息到合适的数据结构— fillUnivList()
- 三、🍉将数据保存至电脑文件夹中— Store_as_file()
- 四、🍉主函数
- 总结🌟
前言🌟
本次案例主要涉及bs4库中的BeautifulSoup内容、requests的使用和存储数据等知识。

提示:以下是本篇文章正文内容,下面案例可供参考
一、🍉从网络上获取大学排名网页内容— getHTMLText()
- 爬取的网址:https://www.shanghairanking.cn/rankings/bcur/202411
- 判断是否可以爬取
在该网站的根目录下查看robots.txt文件是否可以爬取内容,这里显示没有搜索到该内容
3.利用request库爬取
def getHTMLText(url):try:r = requests.get(url, timeout=30)r.raise_for_status() # 判断请求是否成功:如果不是200,产生异常requests.HTTPErrorr.encoding = r.apparent_encoding # http header中猜测的响应内容编码方式 设置为 内容中分析出的响应内容编码方式(备选编码方式)return r.textexcept:return "请求失败"
二、🍉提取网页内容中信息到合适的数据结构— fillUnivList()
- 分析网页
我们要爬取的是”排名“,”学校名称“,”省市“,”类型“,”总分“,”办学层次“等信息,如图: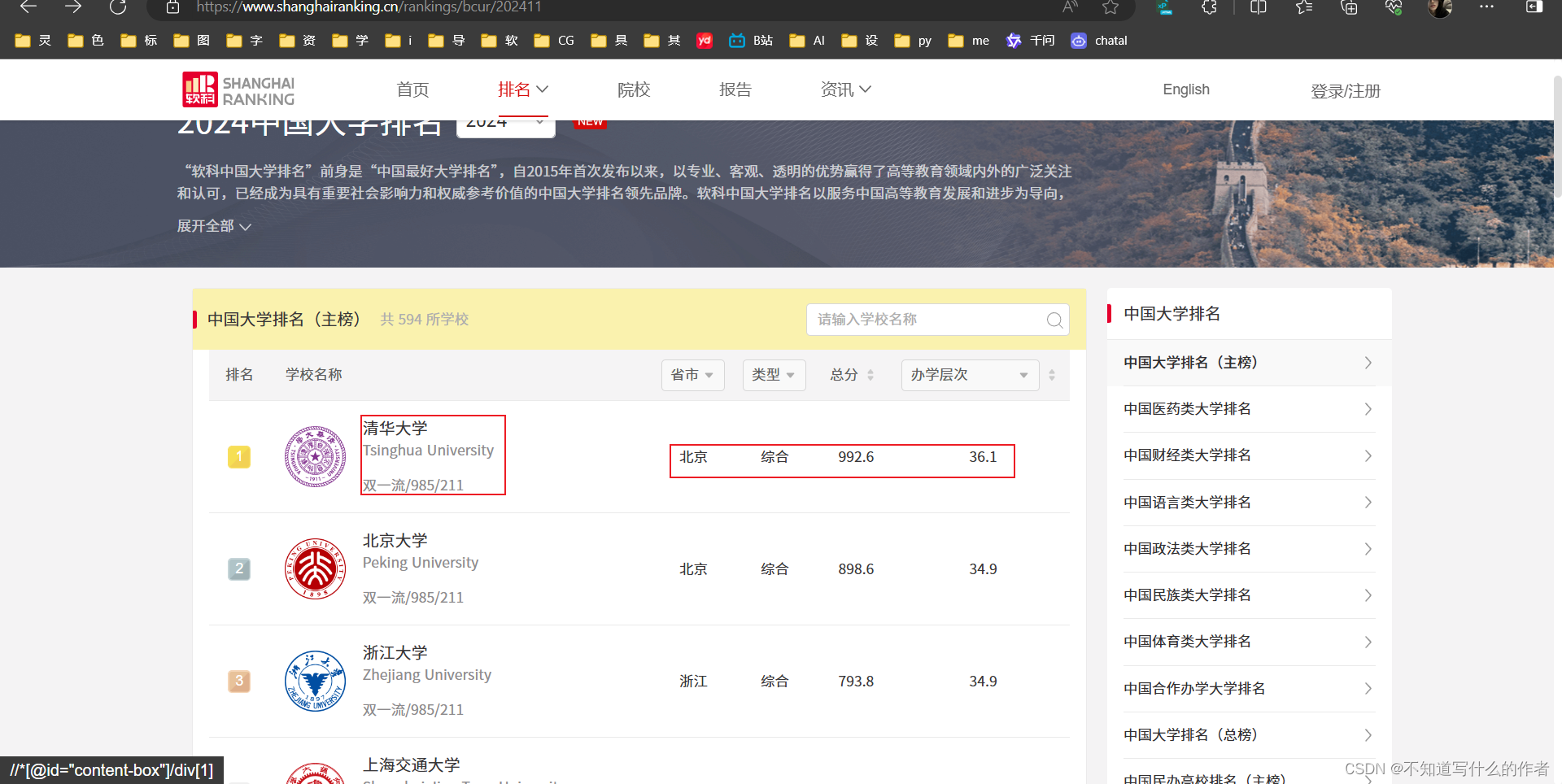
- 先是分析整体信息,需要爬取的文本信息都存放在
.html网页中的<tbody></tbody>中的<tr>标签下.
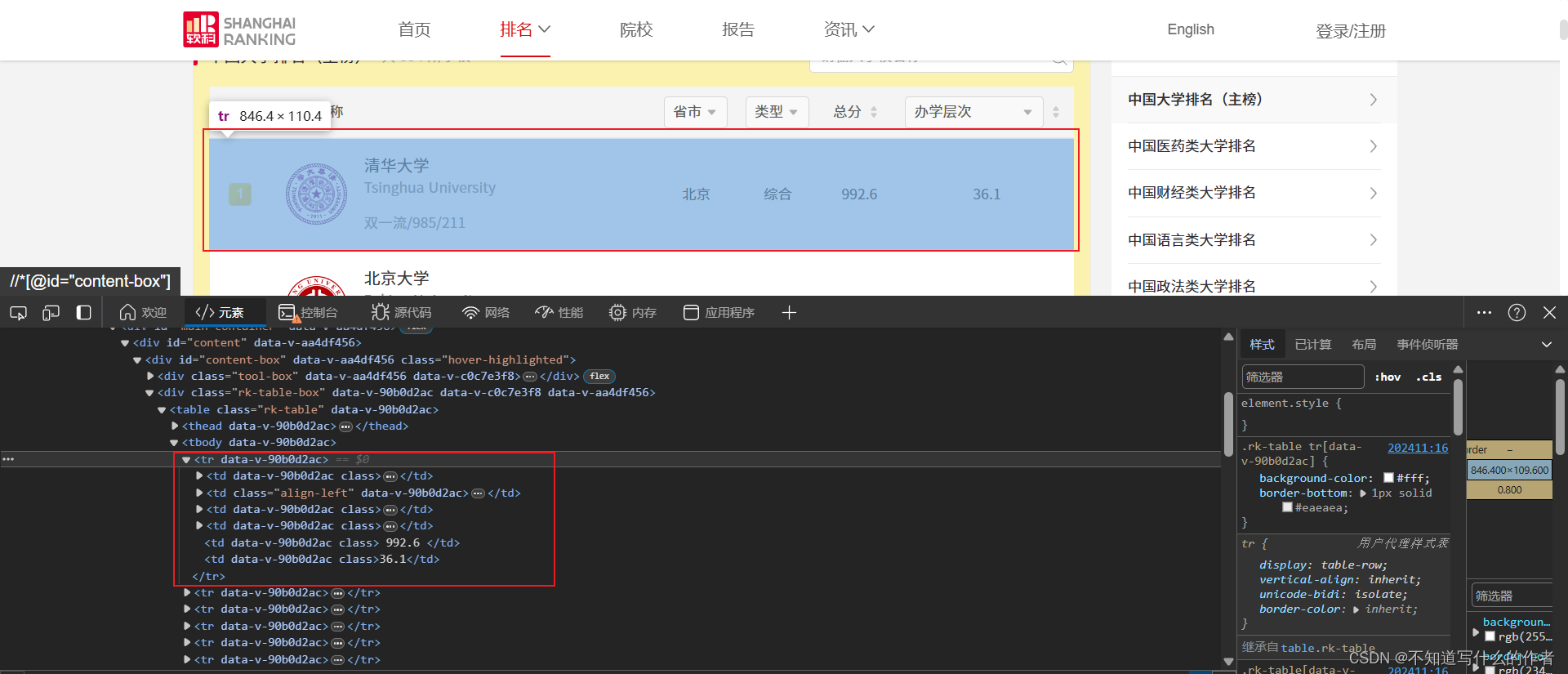
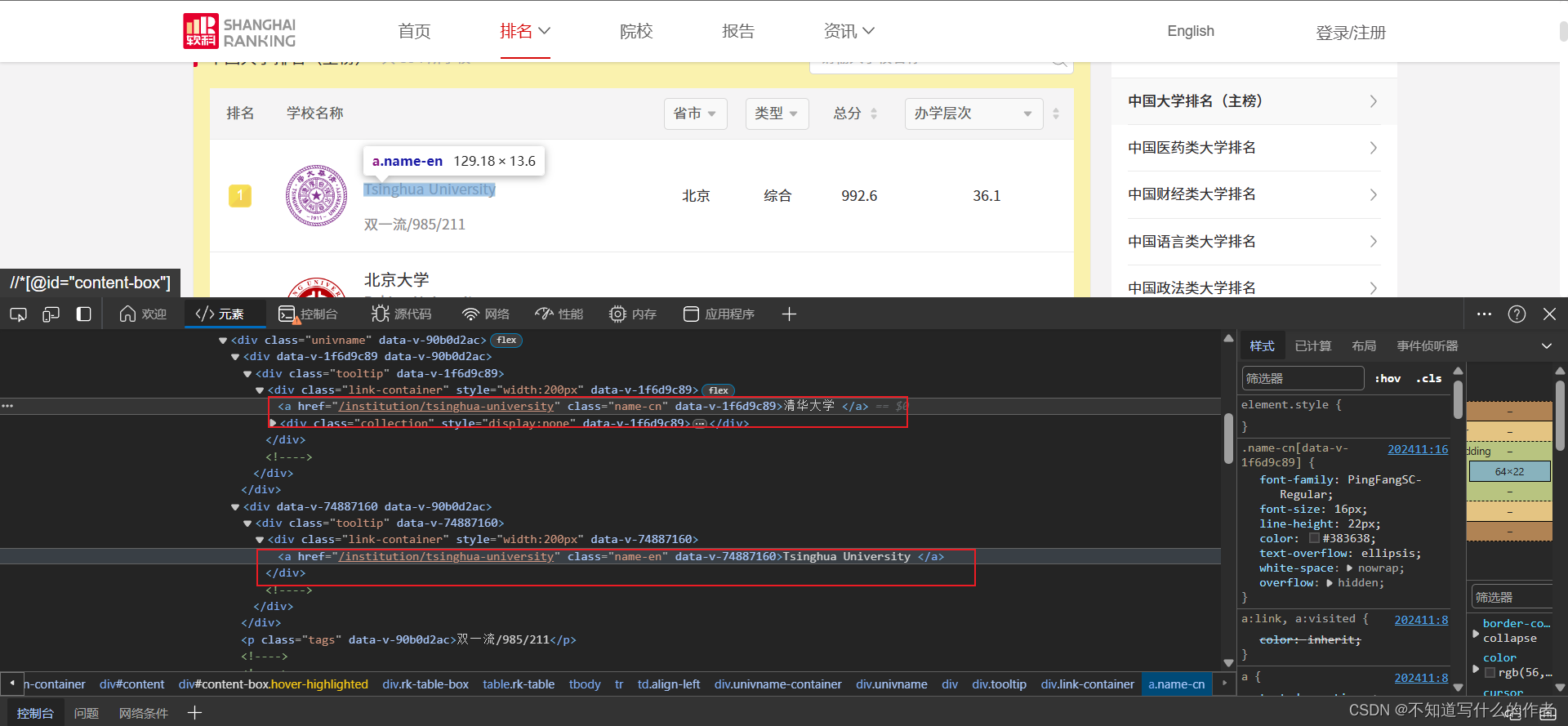
- ”学校名称”在
<div class="univname" data-v-90b0d2ac>标签下<a>标签中。
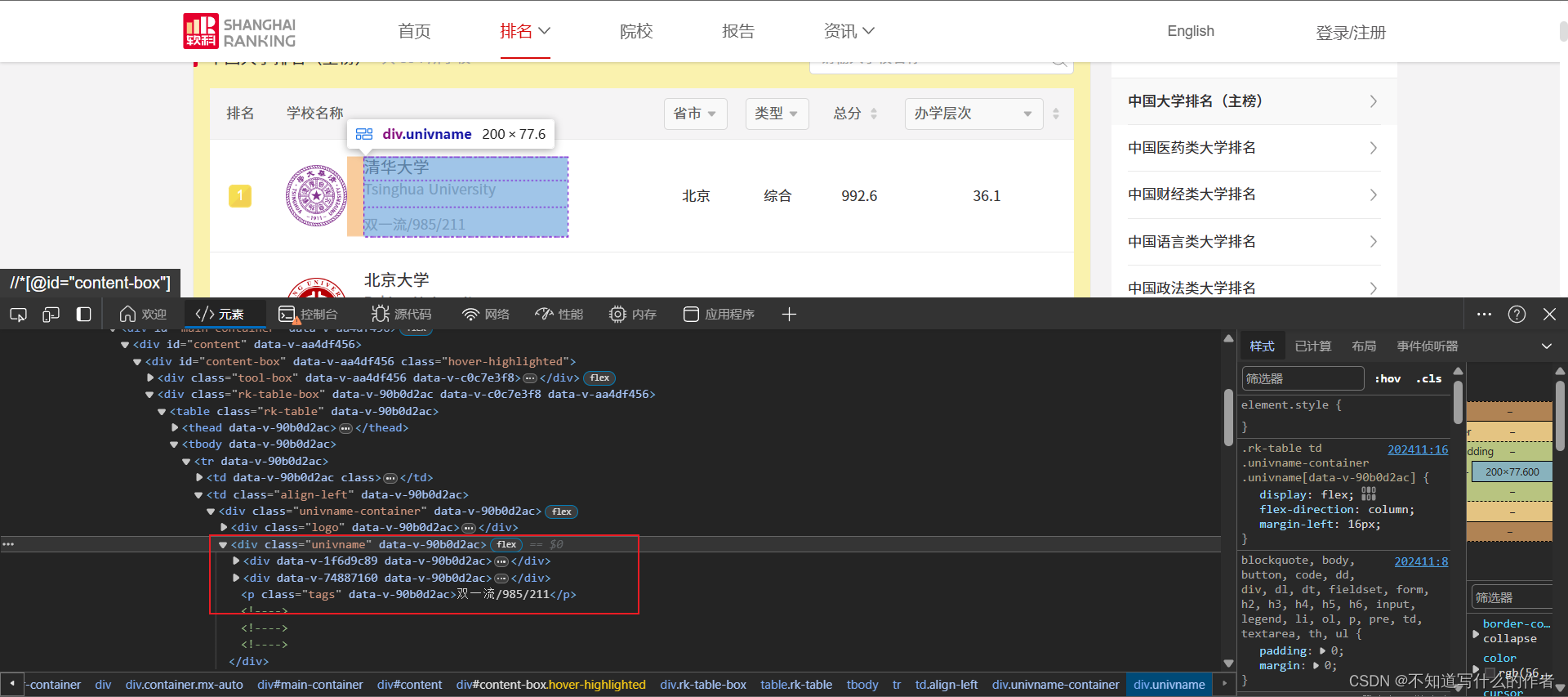
特征:<a>的父亲<div>标签的属性都是class="link-container"和style="width:200px
- 而”省市“,”类型“,”总分“,”办学层次“等,都是直接在
<tr>标签的子代中,所以可以直接获取相关数据存放至列表中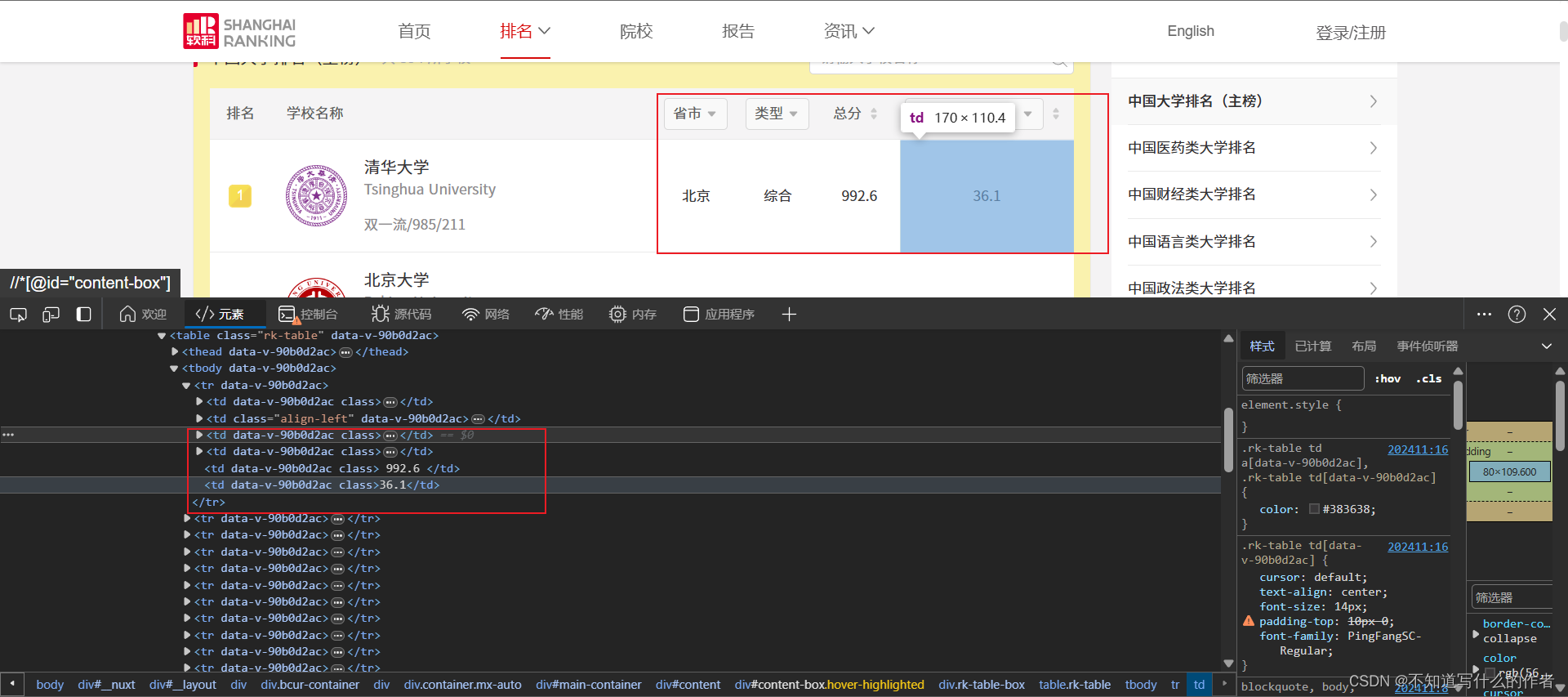
- 解析数据
获取主要爬取的数据,存放至列表中并返回
def fillUnivList(ulist, html):soup = BeautifulSoup(html, 'html.parser') # 设置BeautifulSoup解析器为'html.parser'soup.prettify() # 整理解析的网页# 创建列表tds_name = []name_types = []tds_location = []tds_type = []tds_total = []tds_level = []try:# 遍历tbody的下行遍历for tr in soup.tbody.children:# 检测tr标签的类型的类型,如果tr标签的类型不是bs4库定义的tag类型,将过滤掉if isinstance(tr, bs4.element.Tag): # 检查变量tr是否为BeautifulSoup库中Tag类的实例的一个条件判断语句# tds=str(list(tr('td')[2])[0]).strip()# 学校名称td_name = tr('td')[1]td_div_names = td_name.find_all('div', attrs={"style": "width:200px", "class": "link-container"})for div_tag in td_div_names:# 另一种写法# name_part = div_tag.find('a').get_text(strip=True).split('\n', 1)[0]a = str(div_tag.find_all('a')[0].string).strip().split('\n')[0]tds_name.append(a)# 学校类型td_name_type = tr('td')[1] \.find_all('div', attrs={"class": "univname"})[0] \.find_all('p', attrs={"class": "tags"})[0].get_text(strip=True)# 位置td_location = tr('td')[2].get_text(strip=True)# 类型td_type = tr('td')[3].get_text(strip=True)# 总分td_total = tr('td')[4].get_text(strip=True)# 办学层次td_level = tr('td')[5].get_text(strip=True)# 将各个数据添加至列表name_types.append(td_name_type)tds_location.append(td_location)tds_type.append(td_type)tds_total.append(td_total)tds_level.append(td_level)# break# 中文名字列表name_cns = tds_name[::2]# 英文名字列表name_ens = tds_name[1::2]i=1# 遍历列表大学信息,存放至空列表university中,使用zip打包,zip打包后的数据是元组for name_cn, name_en, name_type, location, type, total, level in \zip(name_cns, name_ens, name_types, tds_location, tds_type, tds_total, tds_level):university_data = {'序号':i,'学校名称': name_cn + " " + name_en + " " + name_type,'省市': location,'类型': type,'总分': total,'办学层次': level}i+=1ulist.append(university_data)return ulistexcept:return "爬取失败"
三、🍉将数据保存至电脑文件夹中— Store_as_file()
这里直接给出代码块,因为完全没有真的优化处理好爬取后的数据(还是很杂乱)
def Store_as_file(path,datas):# 打开文件准备写入with open(path, 'w', encoding='utf-8') as file:# 写入表头,方便阅读file.write("{:^10}\t{:<110}\t{:<10}\t{:<10}\t{:<10}\t{:>10}\n".format("序号","学校名称","省市","类型","总分","办学层次"))t="\t"*10# file.write(f"序号\t学校名称\t\t省市\t\t类型\t\t总分\t\t办学层次\n")# 遍历列表,将每个字典的内容写入文件for university in datas:# 使用制表符分隔各个字段,保证对齐line = "{序号:^10}\t{学校名称:<110}\t{省市:<10}\t{类型:<10}\t{总分:<10}\t{办学层次:>10}\n".format(**university)file.write(line)print(f"数据已成功保存至'{path}'")
四、🍉主函数
代码块:主函数的书写
def main():university = []num = int(input("请输入大学排名的年份:"))url=f"https://www.shanghairanking.cn/rankings/bcur/{num}11"html=getHTMLText(url)datas=fillUnivList(university,html)path=input("请输入存放内容的位置:")Store_as_file(path,datas)
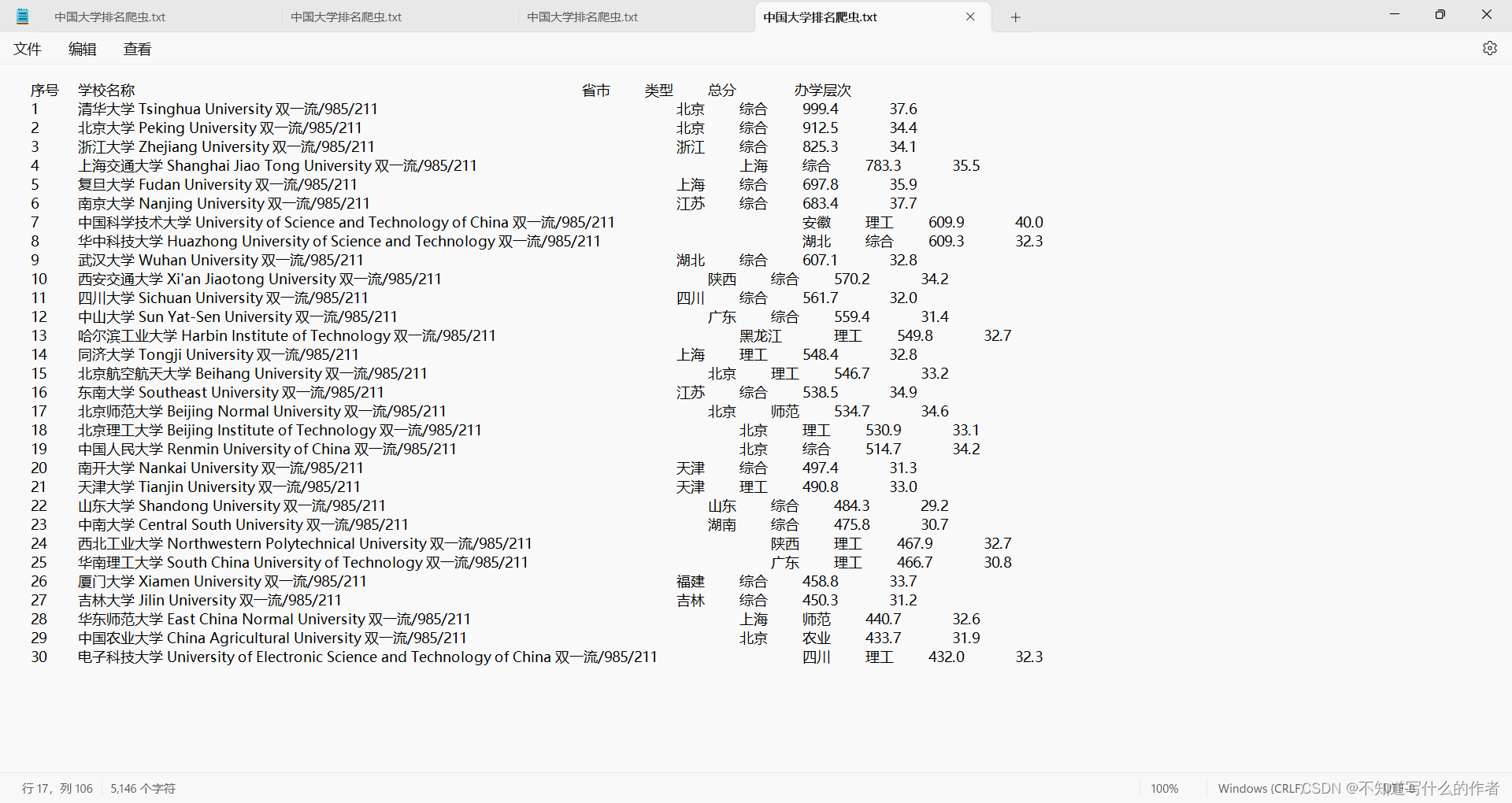
最终效果:当然,我是确实不知道怎么更改,还望读者帮忙提供点意见
总结🌟
总代码块:导入requests库和bs4库和bs4库中的BeautifulSoup
import requests
from bs4 import BeautifulSoup
import bs4def getHTMLText(url):try:r = requests.get(url, timeout=30)r.raise_for_status() # 判断请求是否成功:如果不是200,产生异常requests.HTTPErrorr.encoding = r.apparent_encoding # http header中猜测的响应内容编码方式 设置为 内容中分析出的响应内容编码方式(备选编码方式)return r.textexcept:return "请求失败"def fillUnivList(ulist, html):soup = BeautifulSoup(html, 'html.parser') # 设置BeautifulSoup解析器为'html.parser'soup.prettify() # 整理解析的网页# 创建列表tds_name = []name_types = []tds_location = []tds_type = []tds_total = []tds_level = []try:# 遍历tbody的下行遍历for tr in soup.tbody.children:# 检测tr标签的类型的类型,如果tr标签的类型不是bs4库定义的tag类型,将过滤掉if isinstance(tr, bs4.element.Tag): # 检查变量tr是否为BeautifulSoup库中Tag类的实例的一个条件判断语句# tds=str(list(tr('td')[2])[0]).strip()# 学校名称td_name = tr('td')[1]td_div_names = td_name.find_all('div', attrs={"style": "width:200px", "class": "link-container"})for div_tag in td_div_names:# 另一种写法# name_part = div_tag.find('a').get_text(strip=True).split('\n', 1)[0]a = str(div_tag.find_all('a')[0].string).strip().split('\n')[0]tds_name.append(a)# 学校类型td_name_type = tr('td')[1] \.find_all('div', attrs={"class": "univname"})[0] \.find_all('p', attrs={"class": "tags"})[0].get_text(strip=True)# 位置td_location = tr('td')[2].get_text(strip=True)# 类型td_type = tr('td')[3].get_text(strip=True)# 总分td_total = tr('td')[4].get_text(strip=True)# 办学层次td_level = tr('td')[5].get_text(strip=True)# 将各个数据添加至列表name_types.append(td_name_type)tds_location.append(td_location)tds_type.append(td_type)tds_total.append(td_total)tds_level.append(td_level)# break# 中文名字列表name_cns = tds_name[::2]# 英文名字列表name_ens = tds_name[1::2]i=1# 遍历列表大学信息,存放至空列表university中,使用zip打包,zip打包后的数据是元组for name_cn, name_en, name_type, location, type, total, level in \zip(name_cns, name_ens, name_types, tds_location, tds_type, tds_total, tds_level):university_data = {'序号':i,'学校名称': name_cn + " " + name_en + " " + name_type,'省市': location,'类型': type,'总分': total,'办学层次': level}i+=1ulist.append(university_data)return ulistexcept:return "爬取失败"def Store_as_file(path,datas):# 打开文件准备写入with open(path, 'w', encoding='utf-8') as file:# 写入表头,方便阅读file.write("{:^10}\t{:<110}\t{:<10}\t{:<10}\t{:<10}\t{:>10}\n".format("序号","学校名称","省市","类型","总分","办学层次"))t="\t"*10# file.write(f"序号\t学校名称\t\t省市\t\t类型\t\t总分\t\t办学层次\n")# 遍历列表,将每个字典的内容写入文件for university in datas:# 使用制表符分隔各个字段,保证对齐line = "{序号:^10}\t{学校名称:<110}\t{省市:<10}\t{类型:<10}\t{总分:<10}\t{办学层次:>10}\n".format(**university)file.write(line)print(f"数据已成功保存至'{path}'")def main():university = []num = int(input("请输入大学排名的年份:"))url=f"https://www.shanghairanking.cn/rankings/bcur/{num}11"html=getHTMLText(url)datas=fillUnivList(university,html)path=input("请输入存放内容的位置:")Store_as_file(path,datas)if __name__ == '__main__':main()
最后还是想哆嗦一下,希望读者大大,和爬虫感兴趣的多找我讨论讨论,给出点建议和学习上的交流👑👑 👏👏




![[论文笔记]REACT: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS](https://img-blog.csdnimg.cn/img_convert/5e66ad610c54d390b7a33a51052d7d1c.png)