背景
近邻算法(Nearest Neighbor Algorithm)是一种基本但非常有效的分类和回归方法。最早由Fix和Hodges在1951年提出,经过几十年的发展和改进,已成为数据挖掘、模式识别和机器学习领域的重要工具。近邻算法基于相似性原则,通过查找最接近的样本进行预测。其核心思想是相似的样本具有相似的特征,因而在预测时可以参考相似样本的类别或数值。常见的近邻算法包括k近邻算法(k-Nearest Neighbors, k-NN)、KD树(KD-Tree)和球树(Ball Tree)。

一、近邻算法的基本概念
近邻算法通过比较样本之间的距离来进行分类或回归。其核心思想是相似的样本具有相似的特征,因而在预测时可以参考相似样本的类别或数值。
1.1 距离度量
常用的距离度量包括:
-
欧氏距离(Euclidean Distance):最常用的距离度量,适用于连续型数据。公式为:
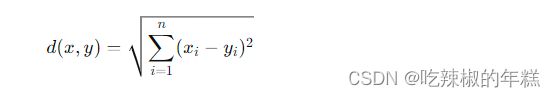
-
曼哈顿距离(Manhattan Distance):适用于高维空间和稀疏数据。公式为:

-
闵可夫斯基距离(Minkowski Distance):欧氏距离和曼哈顿距离的推广,适用于多种情况。公式为:
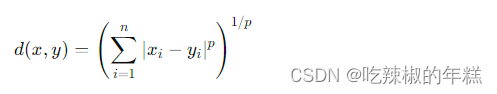
-
余弦相似度(Cosine Similarity):用于度量两个向量之间的夹角,相似度越大,距离越小。公式为:

1.2 算法类型
- 分类:将新样本分类到与其最相似的样本所属的类别。
- 回归:预测新样本的数值为与其最相似的样本数值的加权平均。
二、k近邻算法(k-NN)
2.1 基本原理
k近邻算法通过查找与目标样本最近的k个样本进行预测。对于分类任务,k个邻居中的多数类作为预测结果;对于回归任务,k个邻居的平均值作为预测结果。k近邻算法无需训练过程,直接利用所有训练数据进行预测,因此也被称为懒惰学习算法(Lazy Learning)。
2.2 具体实现
以下是k近邻算法的分类实现:
import numpy as np
from collections import Counter
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_scoreclass KNN:def __init__(self, k=3):self.k = kdef fit(self, X, y):self.X_train = Xself.y_train = ydef predict(self, X):predictions = [self._predict(x) for x in X]return np.array(predictions)def _predict(self, x):distances = [np.sqrt(np.sum((x - x_train)**2)) for x_train in self.X_train]k_indices = np.argsort(distances)[:self.k]k_nearest_labels = [self.y_train[i] for i in k_indices]most_common = Counter(k_nearest_labels).most_common(1)return most_common[0][0]# 加载示例数据集
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练和预测
knn = KNN(k=3)
knn.fit(X_train, y_train)
predictions = knn.predict(X_test)# 计算准确率
print("Accuracy:", accuracy_score(y_test, predictions))
2.3 优劣势
优势:
- 简单易懂:k近邻算法的基本思想简单直观,易于理解和实现。
- 无训练过程:无需训练过程,直接利用所有训练数据进行预测。
劣势:
- 计算复杂度高:对每个测试样本都需要计算与所有训练样本的距离,因此预测过程的计算复杂度较高,适合小规模数据集。
- 对噪声数据敏感:k近邻算法对噪声数据较为敏感,可能影响预测结果。
- 数据标准化要求:不同特征的量纲不同时,需对数据进行标准化处理,否则距离计算可能会受到影响。
三、KD树(KD-Tree)
3.1 基本原理
KD树是一种对k近邻算法进行优化的数据结构,通过将数据划分到k维空间中的子区域,实现高效的最近邻搜索。KD树通过递归地将数据空间划分为k维超矩形,适用于低维数据的最近邻搜索。
3.2 具体实现
以下是KD树的实现和最近邻搜索:
from scipy.spatial import KDTree# 示例数据
X = np.random.rand(10, 2)# 构建KD树
kd_tree = KDTree(X)# 查询最近邻
point = np.random.rand(1, 2)
distance, index = kd_tree.query(point)print("Nearest neighbor:", X[index])
print("Distance:", distance)
3.3 优劣势
优势:
- 提高了k近邻搜索的效率:KD树通过分割数据空间,实现了快速的最近邻搜索,特别适合低维数据。
- 支持动态插入和删除操作:KD树允许动态插入和删除数据点,适用于数据集动态变化的场景。
劣势:
- 构建和维护树结构的复杂度较高:构建KD树需要较高的计算复杂度,插入和删除操作也较为复杂。
- 维度灾难:随着维度增加,KD树的性能提升有限,高维数据的最近邻搜索效果不佳。
四、球树(Ball Tree)
4.1 基本原理
球树是一种替代KD树的结构,通过使用超球体代替超矩形来划分空间,适用于高维数据和度量空间。球树通过递归地将数据空间划分为球形区域,实现高效的最近邻搜索。
4.2 具体实现
以下是球树的实现和最近邻搜索:
from sklearn.neighbors import BallTree# 示例数据
X = np.random.rand(10, 2)# 构建球树
ball_tree = BallTree(X)# 查询最近邻
point = np.random.rand(1, 2)
dist, ind = ball_tree.query(point)print("Nearest neighbor:", X[ind])
print("Distance:", dist)
4.3 优劣势
优势:
- 适用于高维数据:球树在高维空间中表现良好,比KD树更适合高维数据。
- 支持多种距离度量:球树支持多种距离度量,如欧氏距离、曼哈顿距离等。
劣势:
- 构建和维护树结构的复杂度较高:构建和维护球树需要较高的计算复杂度,插入和删除操作也较为复杂。
- 构建时间较长:随着数据规模增加,构建球树的时间较长。
五、应用实例
5.1 手写数字识别
使用k-NN算法进行手写数字识别:
from sklearn.datasets import load_digits
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.neighbors import KNeighborsClassifier# 加载数据
digits = load_digits()
X, y = digits.data, digits.target# 预处理数据
scaler = StandardScaler()
X = scaler.fit_transform(X)# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练k-NN分类器
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, y_train)# 预测并计算准确率
predictions = knn.predict(X_test)
print("Accuracy:", accuracy_score(y_test, predictions))
5.2 图像检索
使用KD树进行图像特征的最近邻搜索:
from sklearn.decomposition import PCA
from sklearn.datasets import fetch_olivetti_faces
from scipy.spatial import KDTree# 加载数据
faces = fetch_olivetti_faces()
X, y = faces.data, faces.target# 降维
pca = PCA(n_components=50)
X_pca = pca.fit_transform(X)# 构建KD树
kd_tree = KDTree(X_pca)# 查询最近邻
query_image = X_pca[0].reshape(1, -1)
dist, ind = kd_tree.query(query_image, k=5)# 输出最近邻结果
print("Nearest neighbors:", ind)
print("Distances:", dist)
5.3 文章推荐
使用球树进行文章推荐:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.neighbors import BallTree# 示例文章
documents = ["The quick brown fox jumps over the lazy dog.","Never jump over the lazy dog quickly.","Bright vixens jump; dozy fowl quack.","Jinxed wizards pluck ivy from the big quilt.","The five boxing wizards jump quickly."
]# 计算TF-IDF特征
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(documents).toarray()# 构建球树
ball_tree = BallTree(X, metric='cosine')# 查询最近邻
query = vectorizer.transform(["Jumping over dogs is fun."]).toarray()
dist, ind = ball_tree.query(query, k=3)# 输出最近邻结果
print("Nearest neighbors:", ind)
print("Distances:", dist)
六、总结
近邻算法是一类基础且强大的分类和回归方法,广泛应用于图像识别、推荐系统等领域。本文详细介绍了k近邻算法(k-NN)、KD树(KD-Tree)、球树(Ball Tree)的基本原理、具体实现、优劣势及应用实例。通过这些算法的学习和应用,可以有效提高分类和回归任务的性能和精度。
拓展阅读与参考文献
- 《统计学习方法》 - 李航
- 《机器学习》 - 周志华
- 《模式分类》 - Duda, Hart, Stork
- Efficient Algorithms for Nearest Neighbor Search in High Dimensions - Arya, Mount, Netanyahu, Silverman, Wu (1998)
- Nearest Neighbors in High-Dimensional Data: The Efficiency-Accuracy Tradeoff - Indyk, Motwani (1998)