阿尔法狗(AlphaGo)的意思是“围棋王”,俗称“阿尔法狗”,它是世界上第一个打败人类围棋冠军的AI。2015年10月,阿尔法狗以5 : 0战胜了欧洲围棋冠军樊麾二段,在2016年3月,阿尔法狗以4 : 1战胜了世界冠军李世石九段。2017年,新版不依赖人类经验完全从零开始自学的零狗(AlphaGo Zero)以100 : 0战胜阿尔法狗。
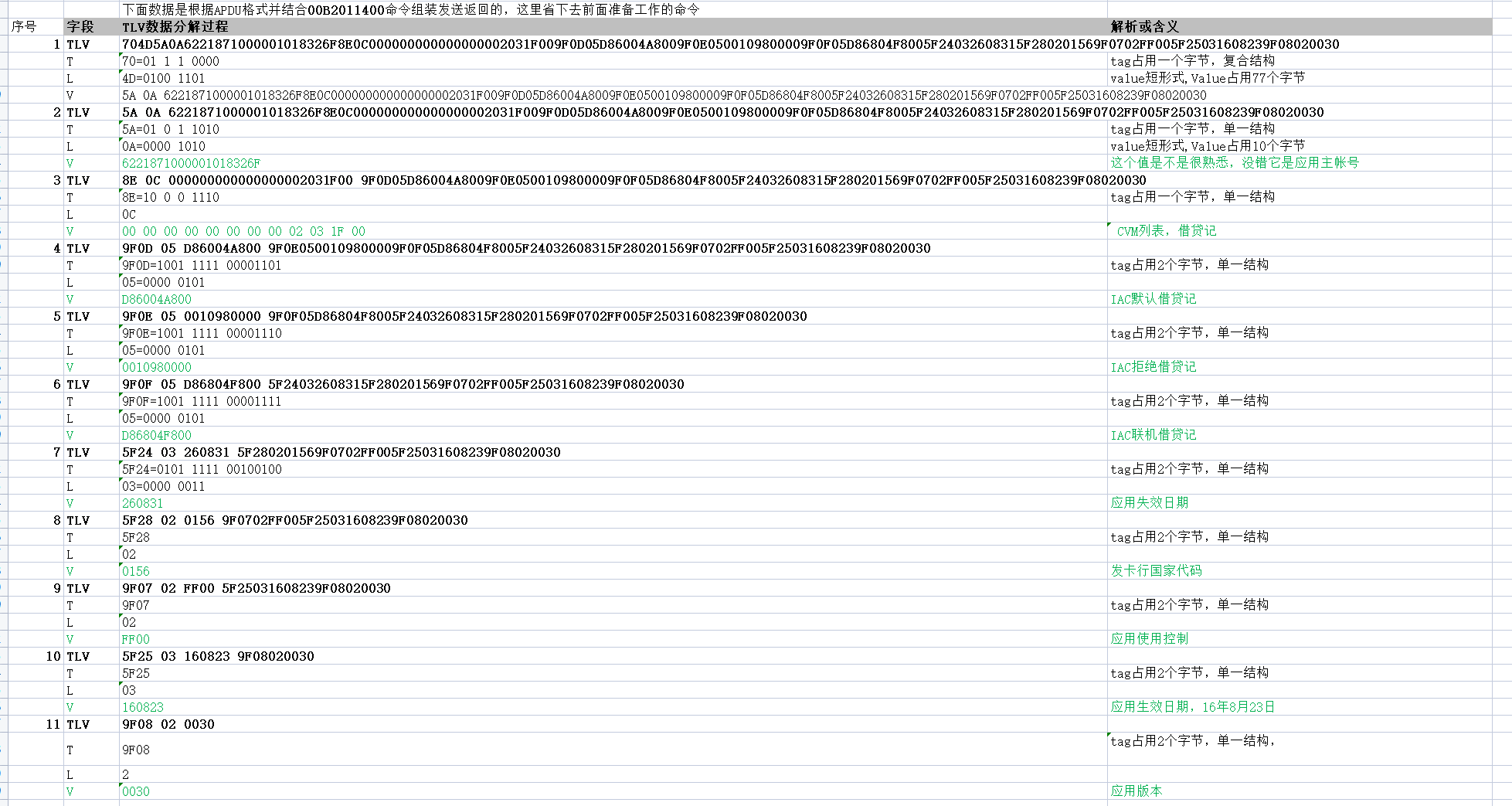
阿尔法狗使用策略网络和价值网络辅助蒙特卡洛树搜索,以降低搜索的深度和宽度。机巧围棋落子策略完全基于零狗算法,本文将用强化学习的语言描述围棋游戏的状态和动作,并介绍阿尔法狗和机巧围棋中构造的策略网络和价值网络。
1. 动作和状态
围棋的棋盘是19 X 19的网格,黑白双方轮流在两条线的交叉点处放置棋子。一共有19 X 19 = 361个可以放置棋子的位置,同时可以选择PASS(放弃一次当前落子的权利),因此动作空间是 A = { 0 , 1 , 2 , ⋯ , 361 } \mathcal{A}=\{0,1,2,\cdots,361\} A={0,1,2,⋯,361},其中第 i i i种动作表示在第 i i i个位置(从0开始)放置棋子,第361种动作表示PASS。
机巧围棋是基于9路围棋的人工智能程序,即棋盘是9 X 9的网格。相应地动作空间 A = { 0 , 1 , 2 , ⋯ , 81 } \mathcal{A}=\{0,1,2,\cdots,81\} A={0,1,2,⋯,81}。

阿尔法狗2016版本使用19 X 19 X 48的张量(tensor)表示一个状态,零狗使用19 X 19 X 17的张量表示一个状态。如图一所示,零狗中使用的状态张量的意义如下:
- 状态张量的每个切片(slice)是19 X 19的矩阵,对应19 X 19的棋盘。一个19 X 19的矩阵可以表示棋盘上所有黑色棋子的位置,如果一个位置上有黑色棋子,则矩阵对应位置的元素为1,否则为0。同样的道理,可以用一个19 X 19的矩阵表示棋盘上所有白色棋子的位置。
- 在零狗的状态张量中,一共存在17个矩阵。其中8个矩阵记录最近8步棋盘上黑子的位置,8个矩阵记录最近8步白子的位置。还有一个矩阵表示下一步落子方,如果接下来由黑方落子,则该矩阵元素全部等于1,如果接下来由白方落子,则该矩阵的元素全部都等于0。
为了减少计算量,机巧围棋对状态张量做了一定的简化。在机巧围棋中,使用9 X 9 X 10的张量表示一个状态,其中4个9 X 9的矩阵记录最近4步棋盘上黑子的位置,4个矩阵记录白子的位置。一个矩阵表示下一步落子方,如果接下来由黑方落子,则该矩阵元素全部等于0,由白方落子则等于1。还有最后一个矩阵表示上一步落子位置,即上一步落子位置元素为1,其余位置元素为0,若上一步为PASS,则该矩阵元素全部为0。
阿尔法狗2016版本的状态张量意义比较复杂,本文不详细展开,具体可参加下图:

2. 策略网络
策略网络 π ( a ∣ s ; θ ) \pi(a|s;\theta) π(a∣s;θ)的结构如图三所示。零狗策略网络的输入是19 X 19 X 17的状态 s s s,输出是362维的向量 f f f,它的每个元素对应动作空间中的一个动作。策略网络的输出层激活函数为Softmax,因此向量 f f f所有元素均是正数,而且相加等于1。

3. 价值网络
在阿尔法中还有一个价值网络 v π ( s ; ω ) v_\pi(s;\omega) vπ(s;ω),它是对状态价值函数 V π ( s ) V_\pi(s) Vπ(s)的近似,价值网络的结构如图四所示。价值网络的输入是19 X 19 X 17的状态 s s s,输出是一个 [ − 1 , + 1 ] [-1, +1] [−1,+1]的实数,它的大小评价当前状态 s s s的好坏。

策略网络和价值网络的输入相同,都是状态 s s s。而且它们都用卷积层将 s s s映射到特征向量,因此零狗中让策略网络和价值网络共用卷积层。
零狗中策略网络和价值网络共用卷积层,但是在阿尔法狗2016版本中没有共用。因为零狗中策略网络和价值网络是一起训练的,而阿尔法狗2016版本中是先训练策略网络,然后用策略网络来训练价值网络,二者不是同时训练的,因此不能共用卷积层。后续会详细介绍阿尔法狗中神经网络训练方法。
4. 机巧围棋网络结构
零狗训练用了5000块TPU,在机巧围棋中为了减少计算量,大幅简化了策略网络和价值网络。在机巧围棋中,使用了3个卷积层从状态 s s s中提取特征,分别是:
- 3 X 3步长1的32通道卷积;
- 3 X 3步长1的64通道卷积;
- 3 X 3步长1的128通道卷积。
在策略网络部分,首先使用1 X 1的8通道卷积对信息进行夸通道整合,再接一个全连接层将特征向量维度压缩成256,最后再接入输出层;在价值网络部分,首先使用1 X 1的4通道卷积对信息进行夸通道整合,再接入两个全连接层,最后接入输出层。具体代码如下:
# -*- coding: utf-8 -*-
# @Time : 2021/3/29 21:01
# @Author : He Ruizhi
# @File : policy_value_net.py
# @Software: PyCharmimport paddleclass PolicyValueNet(paddle.nn.Layer):def __init__(self, input_channels: int = 10,board_size: int = 9):""":param input_channels: 输入的通道数,默认为10。双方最近4步,再加一个表示当前落子方的平面,再加上一个最近一手位置的平面:param board_size: 棋盘大小"""super(PolicyValueNet, self).__init__()# AlphaGo Zero网络架构:一个身子,两个头# 特征提取网络部分self.conv_layer = paddle.nn.Sequential(paddle.nn.Conv2D(in_channels=input_channels, out_channels=32, kernel_size=3, padding=1),paddle.nn.ReLU(),paddle.nn.Conv2D(in_channels=32, out_channels=64, kernel_size=3, padding=1),paddle.nn.ReLU(),paddle.nn.Conv2D(in_channels=64, out_channels=128, kernel_size=3, padding=1),paddle.nn.ReLU())# 策略网络部分self.policy_layer = paddle.nn.Sequential(paddle.nn.Conv2D(in_channels=128, out_channels=8, kernel_size=1),paddle.nn.ReLU(),paddle.nn.Flatten(),paddle.nn.Linear(in_features=9*9*8, out_features=256),paddle.nn.ReLU(),paddle.nn.Linear(in_features=256, out_features=board_size*board_size+1),paddle.nn.Softmax())# 价值网络部分self.value_layer = paddle.nn.Sequential(paddle.nn.Conv2D(in_channels=128, out_channels=4, kernel_size=1),paddle.nn.ReLU(),paddle.nn.Flatten(),paddle.nn.Linear(in_features=9*9*4, out_features=128),paddle.nn.ReLU(),paddle.nn.Linear(in_features=128, out_features=64),paddle.nn.ReLU(),paddle.nn.Linear(in_features=64, out_features=1),paddle.nn.Tanh())def forward(self, x):x = self.conv_layer(x)policy = self.policy_layer(x)value = self.value_layer(x)return policy, value
5. 结束语
本文介绍了阿尔法狗中的两个深度神经网络——策略网络和价值网络,并讲解了机巧围棋中的网络实现。在阿尔法狗或者机巧围棋中,神经网络结构并不是一层不变的,可以依据个人经验或喜好随意调整。总的来说,浅的网络能够减少计算量,加快训练和落子过程,深的网络可能更有希望训练出更高水平狗。
最后,期待您能够给本文点个赞,同时去GitHub上给机巧围棋项目点个Star呀~
机巧围棋项目链接:https://github.com/QPT-Family/QPT-CleverGo