在往期博客《执行器 - Query 执行详解》中,我们介绍到到一条 Query 的 SQL 语句需要经过:词法分析 —— 生成 AST 语法树 —— 生成物理计划。本期博客我们接续上篇讲解一条 Query 语句物理计划的具体结构,以及如何构建物理计划。
物理计划是根据逻辑计划(逻辑计划讲解参考往期博客)生成的树形结构,执行引擎需要按照物理计划进行实际查询,根据逻辑计划的不同逻辑算子生成物理算子,通过记录处理链路,即数据流来记录算子的执行顺序,根据顺序进行执行。
01 物理计划结构
物理计划组成
▪ Processors
该成员记录了整个物理计划的算子。
▪ Streams
数据流,记录了所有算子之间的连接关系,Streams 和 Processors 基本上就可以较为完整地描述整个物理计划的拓扑结构。
▪ ResultRouters
物理计划按层次进行构建(由逻辑计划树自底向上进行构建),该成员记录了当前层次构建完成后的所有算子,它们是由同一种逻辑算子转换而成的多个物理算子。
▪ ResultTypes
当前层次构建完成后的所有算子的输出列类型数组。
▪ ResultColumns
当前层次构建完成后的所有算子的输出列数量。
▪ GatewayNodeID
物理计划执行的网关节点,数据最终的汇总节点。
▪ MergeOrdering
当前层次构建完成后,下一层需要按哪几列进行归并输入。
算子组成
▪ Node
算子执行所在节点。
▪ Spec
算子的规格信息。
算子规格组成
▪ Input
该算子的逻辑输入数目。
▪ Core
算子的内部执行逻辑。
▪ Post
记录数据经过该算子后的一些投影、选择、Limit 和 Offset 等处理。
▪ Output
算子的逻辑输出。
数据流组成
▪ SourceProcessor
标明连接的源算子。
▪ DestProcessor
标明连接的目标算子。
▪ DestInput
标明连接目标算子的哪个逻辑输入。
02 物理计划构建
以三节点集群执行一条查询语句为样例解析物理计划构建和执行流程,结构如下:
SQL
create table a(a1 int, a2 int, a3 bool);
insert into a values(1,1,false),(2,2,false),(3,3,false);
create table b(b1 int, b2 int, b3 bool);
insert into b values(1,2,false),(3,4,true),(5,6,true);
select * from a join b on a.a1=b.b1;
向右滑动查看
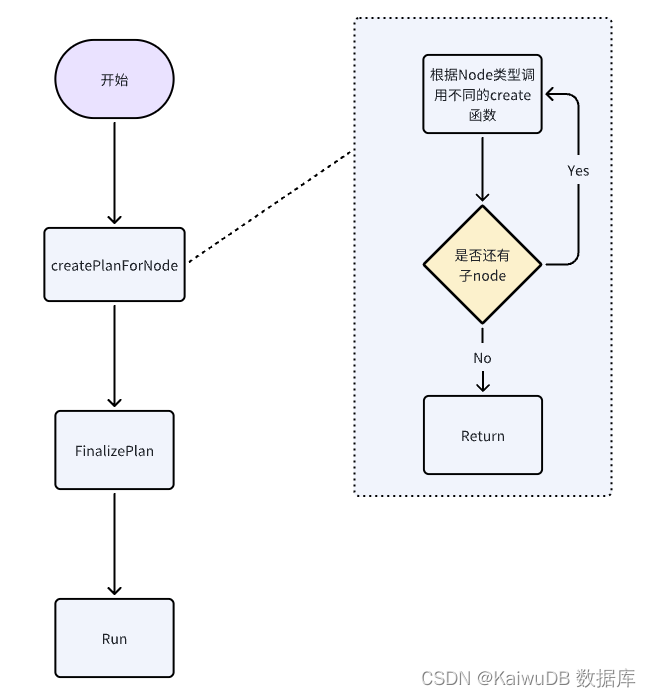
整体流程示意图
算子组成
▪ Node
算子执行所在节点。
根据逻辑算子生成物理算子
该物理计划构建首先会进入 Join 算子的物理算子生成函数 (createPlanNodeforJoin),进行左右两个 scanNode 的物理计划构建,scanNode 是处理表键/值对的扫描,并重组为行的算子。
在构建 scanNode 时,会构建表读取算子TableReader (createTableReaders),它会确认表数据的分布信息,根据数据分布所在节点创建出对应数量的 TableReader 算子,最终左右的物理计划将各生成的 3个 TableReader 算子加入到 PhysicalPlan 当中,如图所示。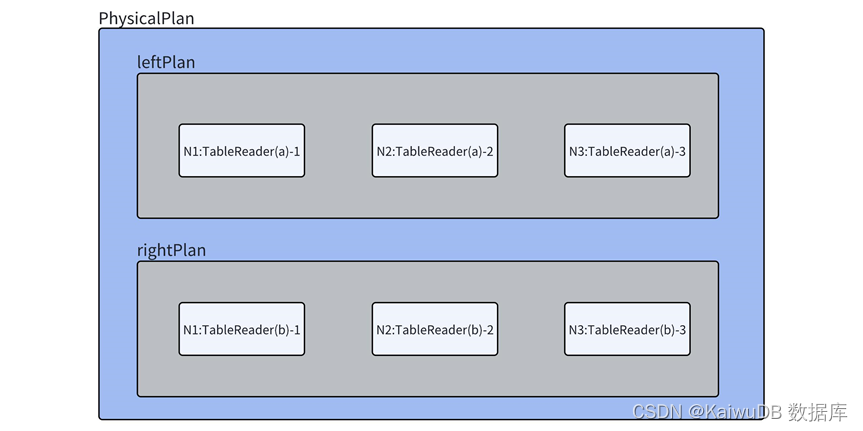
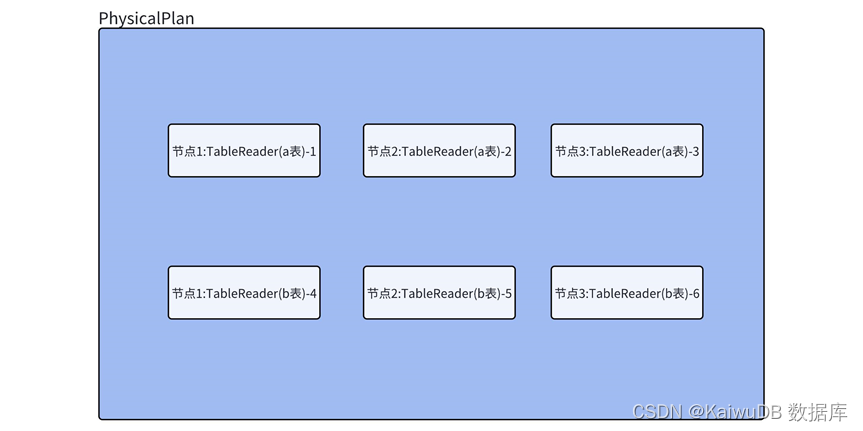
算子组成合并左右子计划
MergePlans 将左右计划进行合并,整体变成一个物理计划,该物理计划中有 6 个 TableReader 算子。
根据节点数构建 Join 算子
findJoinProcessorNodes 函数决定在几个节点做 Join 操作,这里的 Tablereader 算子是 3 节点,所以 Join 算子也会构建 3 个分别对应 3 个节点,之后在每个指定节点上添加 HashJoiner,并将左边和右边的输出进行连接,生成 3 个 HashJoiner 算子,并将它左右算子的 Output 类型改为 OutputRouterSpec_BY_HASH(执行时需要跨节点 Hash 重分布,下一小节会介绍另一种 Hash 分布方式)类型。
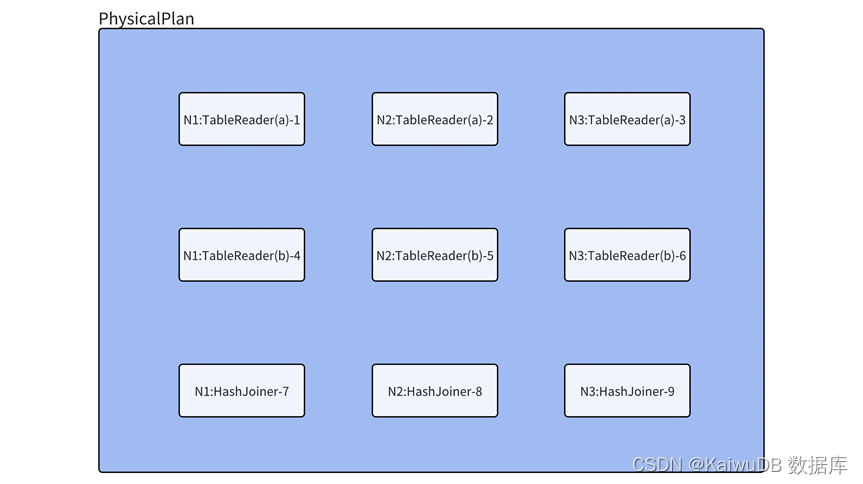
构建数据流
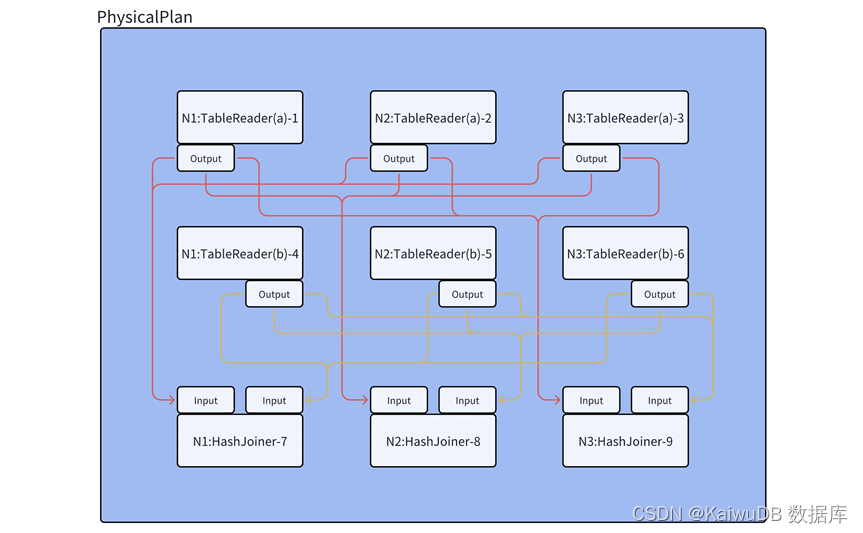
每个 HashJoiner 算子都需要有左右两个 Input,在每个节点上执行时都需要获取到两个表的 TableReader 算子的输出,所以需要调用 MergeResultStreams 方法按照节点数量将 a 表和 b 表的各 3 个 TableReader 连接到各个 HashJoiner 的 Input 左右两端。
如图所示,跨节点 Hash 数据重分布方式 (OutputRouterSpec_BY_HASH) 是要将三个节点上每个 HashJoiner 算子的 Input 每个表的数据做到基本平均分配,例:a表在节点 1 有 3000 条数据,节点 2 有 5000 条数据,节点 3 有 1000条 数据,节点 2需要将数据传输一部分到节点 1 和节点 3,最终三个节点的 HashJoiner 算子的 a 表 Input 都有 3000 条数据。
有向箭头表示数据流 (Stream),Stream 起于一个算子的 Output,终于另一个算子的Input,图中的 Output 类型均为上一小节所说的 OutputRouterSpec_BY_HASH。
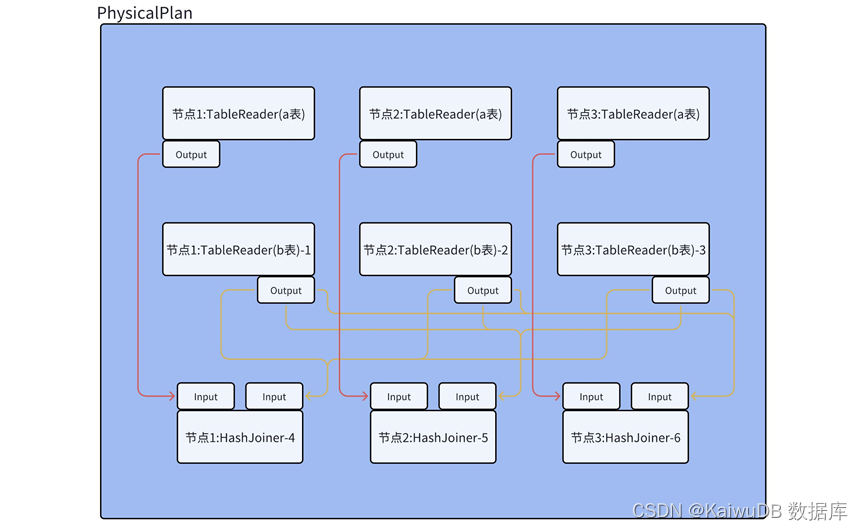
另外,除本样例中提到跨节点 Hash 重分布 (OutputRouterSpec_BY_HASH) 分布方式,还有一种镜像 Hash 分布方式 (OutputRouterSpec_MIRROR),此方式会将表数据完全广播到每一个节点上,不需要根据节点数进行数据重分布,此 Hash 分布方式的计划如图所示,具体采用哪种分布方式,需要根据表数据量,节点数等进行数据传播和接受的代价计算,两种方式哪个代价更小就使用哪种分布方式。
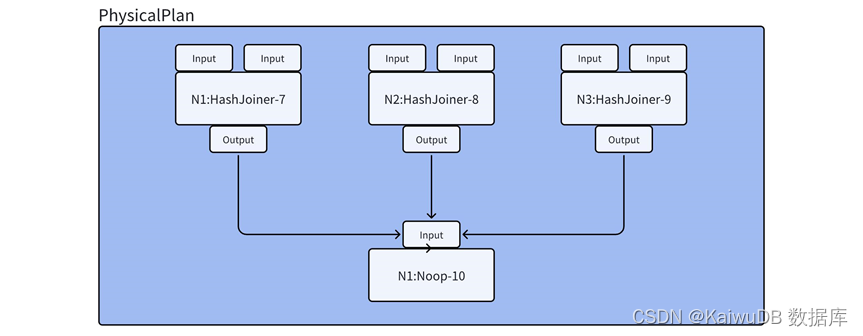
物理计划增加汇总算子
createPlanForNode 函数完成后,物理计划的基本结构就生成完毕,但还需要一个最终汇总结果返回的算子,FinalizePlan 函数便会在已有的物理计划基础上增加一个 Noop 算子,用于汇总最终的执行结果,还需要设置每个算子的 Input 和 Output 所关联的 StreamID,以及 Stream 的类型(Stream 如果连接相同节点的算子为 streamEndpointSpec_LOCAL,否则为 streamEndpointSpec_REMOTE)为之后物理计划的执行做准备,此阶段物理计划如图所示。
 至此,物理计划构建全部完成,而后将进行物理计划的分布式执行,此模块将在后续博客进行介绍。
至此,物理计划构建全部完成,而后将进行物理计划的分布式执行,此模块将在后续博客进行介绍。