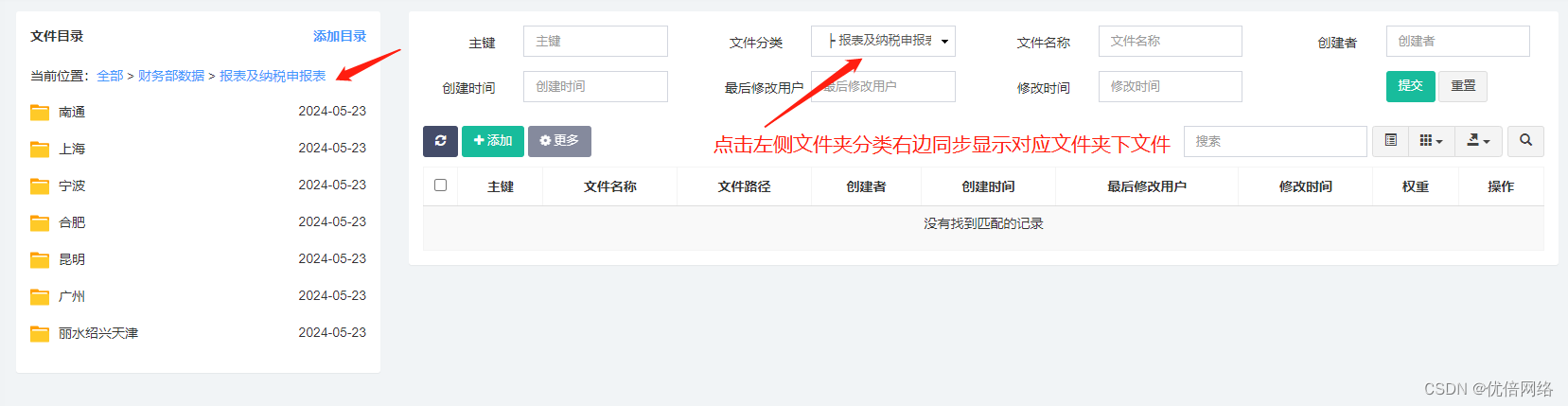
#include"stdio.h"#include<iostream>#include<cuda.h>#include<cuda_runtime.h>//Defining number of elements in Array#defineN50000//Defining Kernel function for vector addition
__global__ voidgpuAdd(int* d_a,int* d_b,int* d_c){//Getting Thread index of current kernelint tid = threadIdx.x + blockIdx.x * blockDim.x;while(tid < N){d_c[tid]= d_a[tid]+ d_b[tid];tid += blockDim.x * gridDim.x;}}intmain(void){//Defining host arraysint h_a[N], h_b[N], h_c[N];//Defining device pointersint* d_a,* d_b,* d_c;//----------创建事件记录起止时间---------------------cudaEvent_t e_start, e_stop;cudaEventCreate(&e_start);cudaEventCreate(&e_stop);//第一次记录时间戳cudaEventRecord(e_start,0);// allocate the memorycudaMalloc((void**)&d_a, N *sizeof(int));cudaMalloc((void**)&d_b, N *sizeof(int));cudaMalloc((void**)&d_c, N *sizeof(int));//Initializing Arraysfor(int i =0; i < N; i++){h_a[i]=2* i * i;h_b[i]= i;}// Copy input arrays from host to device memorycudaMemcpy(d_a, h_a, N *sizeof(int), cudaMemcpyHostToDevice);cudaMemcpy(d_b, h_b, N *sizeof(int), cudaMemcpyHostToDevice);//Calling kernels passing device pointers as parametersgpuAdd <<<512,512>>>(d_a, d_b, d_c);//Copy result back to host memory from device memorycudaMemcpy(h_c, d_c, N *sizeof(int), cudaMemcpyDeviceToHost);cudaDeviceSynchronize();//再次记录时间戳cudaEventRecord(e_stop,0);//等待所有GPU工作都完成cudaEventSynchronize(e_stop);float elapsedTime;//计算时间插值cudaEventElapsedTime(&elapsedTime, e_start, e_stop);printf("Time to add %d numbers: %3.1f ms\n", N, elapsedTime);int Correct =1;printf("Vector addition on GPU \n");//Printing result on consolefor(int i =0; i < N; i++){if((h_a[i]+ h_b[i]!= h_c[i])){Correct =0;}}if(Correct ==1){printf("GPU has computed Sum Correctly\n");}else{printf("There is an Error in GPU Computation\n");}//Free up memorycudaFree(d_a);cudaFree(d_b);cudaFree(d_c);return0;}
安装可参考:
centos7下安装elasticsearch7.8.1并配置远程连接_在一台服务器centos7上安装和配置elasticsearch。-CSDN博客
1、先停掉es进程 2、设置输入密码后访问配置 cd /home/soft/elasticsearch-7.12.1/config vim elasticsearch.yml 3、启动es服务 cd /home/…
FL Studio v21.2.3.4004中文破解版是一款完整的软件音乐制作环境或数字音频工作站 (DAW)。代表了超过 18 年的创新发展,它在一个软件包中提供了您创作、编曲、录制、编辑、混音和掌握专业品质音乐所需的一切。FL Studio v21.2.3.4004中文破解版现在是世界上最受欢迎…
一,菜单合并效果图 源文件参考:fastadmin 子级菜单展开合并、分类父级归纳 - FastAdmin问答社区
php服务端:
public function _initialize()
{parent::_initialize();$this->model new \app\admin\model\auth\Filetype;$this->admin…
kali linux配置agent
在博主配置kali 的时候遇到了一些小问题,主要就是连接一直报错超时。 方法一:优点:免费,但是agent很不稳定
搜索免费ip,在Google搜索free proxy list
检查可用ip
连接成功 cd /etcls |grep redsnano reds…
本博客内容涉及到:切片
切片
1. 切片的概念
首先先对数组进行一下回顾:
数组定义完,长度是固定的,例如:
var num [5]int [5]int{1,2,3,4,5}定义的num数组长度是5,表示只能存储5个整形数字,…









![[nextjs]推荐几个很好看的模板网站](https://img-blog.csdnimg.cn/direct/d3bafb4e6dae41888998f5c56df31e7d.png)