| chat | 瓶颈结构 | 沙漏结构 |
|---|---|---|
| 初衷 | 瓶颈结构最初被引入用于深度卷积神经网络中,旨在通过减少中间特征图的通道数来降低计算复杂度,并在保持网络容量的同时减少参数量。 这种设计能够在保持网络性能的前提下,提高计算效率和降低内存消耗。 | 沙漏结构最初提出是为了处理具有多尺度信息的输入和输出,特别是在姿态估计、人体关键点检测等任务中。 该结构通过在网络内部增加上采样和下采样操作,允许网络在不同层次捕捉和融合多尺度的特征,从而提高网络对细节和整体信息的感知能力。 |
| 作用 | 瓶颈结构广泛应用于各种计算机视觉任务,如图像分类、物体检测和语义分割等。 它通常作为ResNet等深度网络结构中的关键组件,通过降低通道数来有效控制网络的复杂度,提高训练和推理效率。 | 沙漏结构主要应用于需要处理多尺度信息的任务,例如姿态估计、人体姿态关键点检测、医学影像分析等。 通过沙漏结构,网络可以有效地整合从粗糙到细节的多层次信息,提升对复杂模式和细微特征的识别和推理能力。 |
瓶颈结构
-
来源:瓶颈结构是在GoogLeNet/Inception-v1中提出的,而后的ResNet、MobileNet等很多网络也采用并发展了这个结构。
-
初衷:瓶颈结构的初衷是为了降低大卷积层的计算量。
-
即在计算比较大的卷积层之前,先用一个1x1卷积来压缩大卷积层输入特征图的通道数目,以减小计算量;
-
在大卷积层完成计算之后,根据实际需要,有时候会再次使用一个卷积来将大卷积层输出特征图的通道数目复原。
-
-
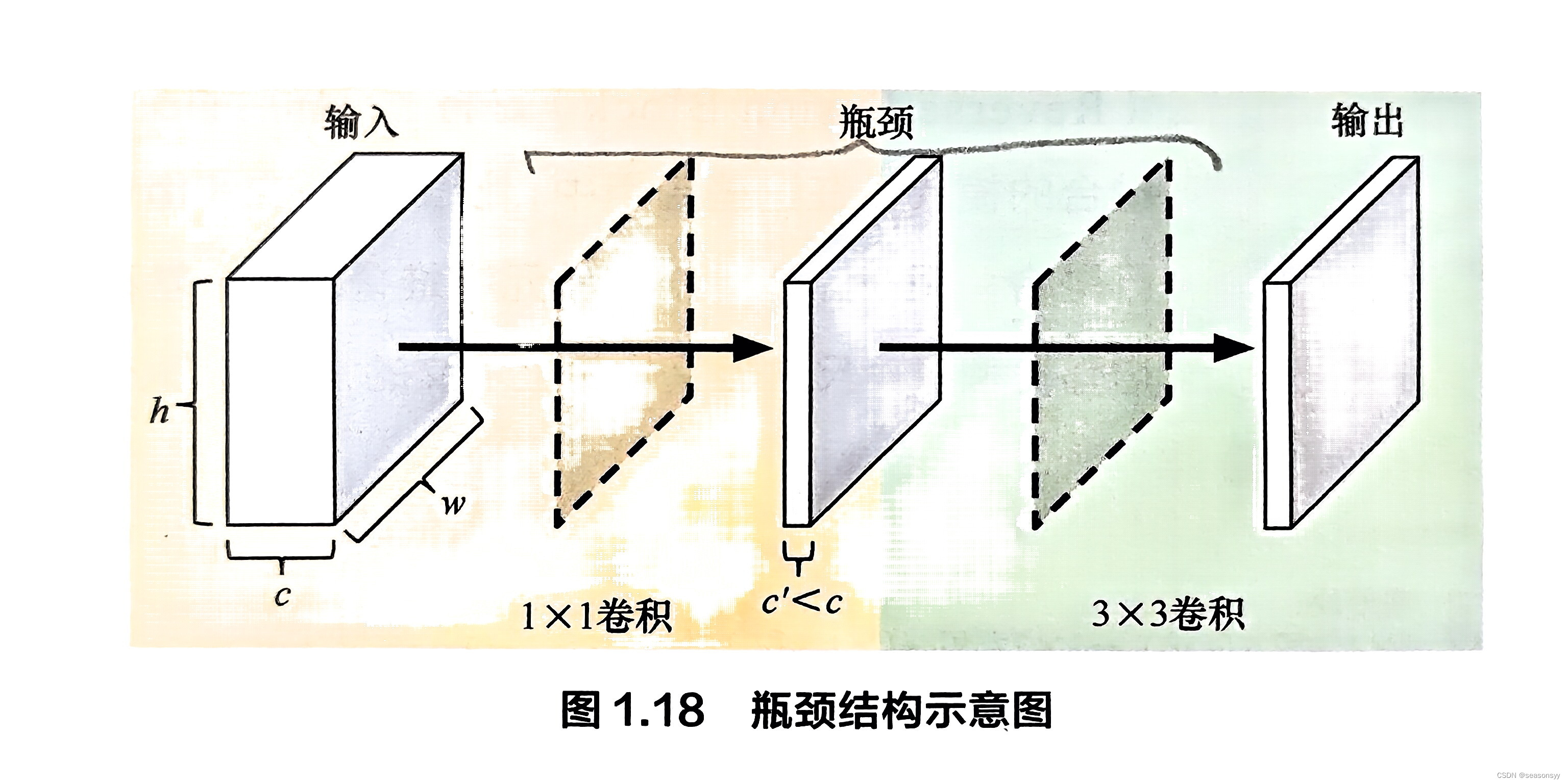
组成:由此,瓶颈结构一般是一个小通道数的1x1卷积层,接一个较大卷积层,后面可能还会再跟一个大通道数的1x1卷积层(可选),如图1.18所示。
-
作用:瓶颈结构是卷积神经网络中比较基础的模块,它可以用更小的计算代价达到与之前相似甚至更好的效果(因为瓶颈结构会增加网络层数,所以特征提取能力可能也会有相应提升)。
-
应用领域:瓶颈结构基本上可以用于所有的卷积神经网络中,场景包括物体检测和分割、生成式对抗网络等大方向,以及诸如人脸匹配、再识别、关键点检测等细分领域。
相关阅读:
1×1卷积
Same卷积
1×1卷积和Same卷积有什么区别
沙漏结构
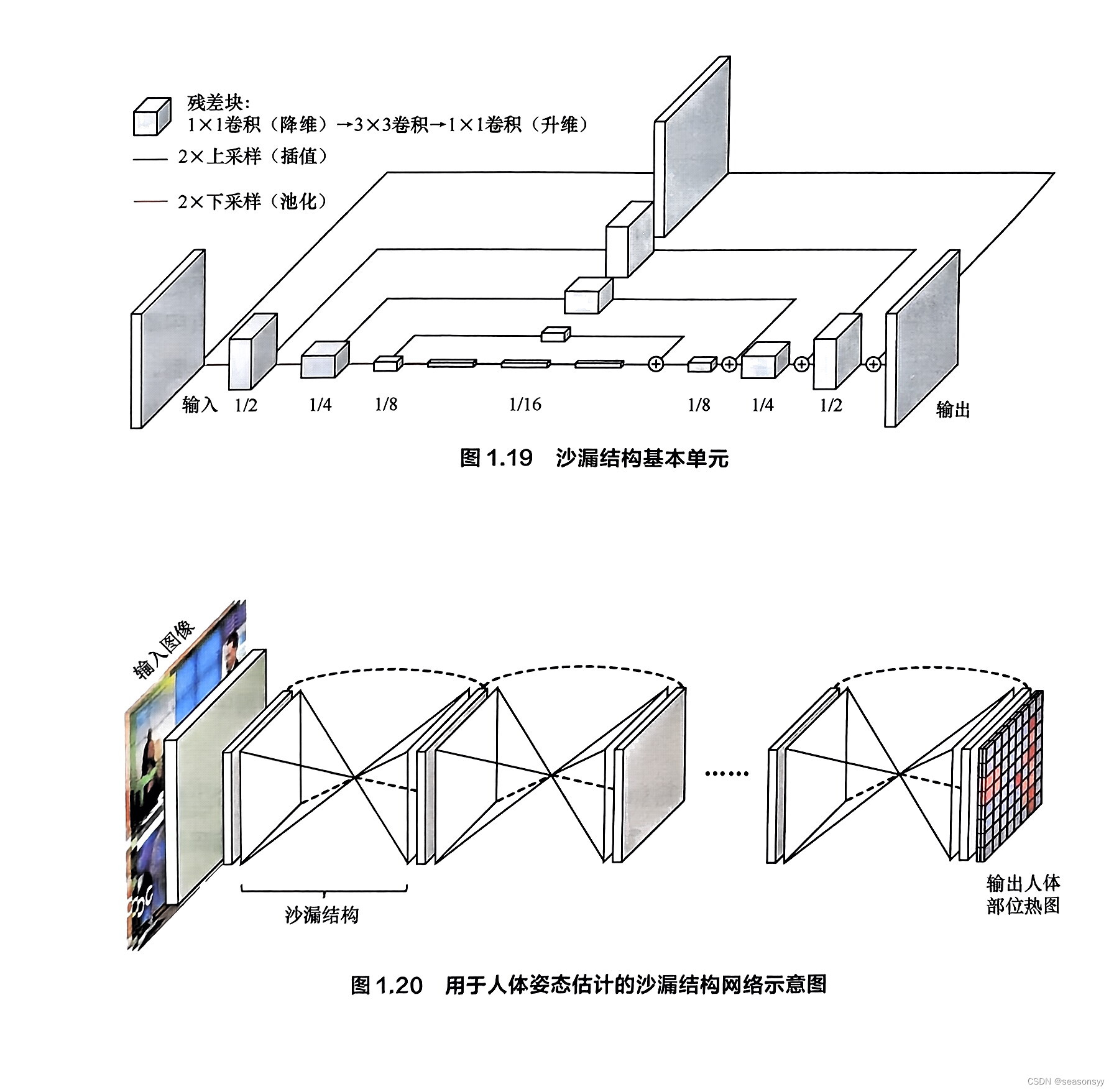
沙漏结构也是卷积神经网络中比较基础的模块,它类似于瓶颈结构,但尺度要更大,涉及的层也更多。
沙漏结构一般包括以下两个分支。
(1)自底向上(bottom-up)分支:利用卷积、池化等操作将特征图的尺寸逐层压缩(通道数可能增加),类似于自编码器中的编码器(encoder)。
(2)自顶向下(top-down)分支:利用反卷积或插值等上采样操作将特征图的尺寸逐层扩大(通道数可能降低),类似于自编码器中的解码器(decoder)。
参考文献[24]用一个具有沙漏结构的网络来解决人体姿态估计任务,其基本单元如图1.19所示;整个网络则由多个沙漏结构堆叠而成,如图1.20所示。
此外,在物体检测任务中,沙漏结构也有着大量应用,如TDM(Top-Down Modulation)[25]、FPN(Feature Pyramid Network)[26]、RON(Reverse connection with Objectness prior Networks)[27]、DSSD(Deconvolutional Single-Shot Detector)[28]、DefineDet[29]等模型,它们的网络结构如图1.21所示。
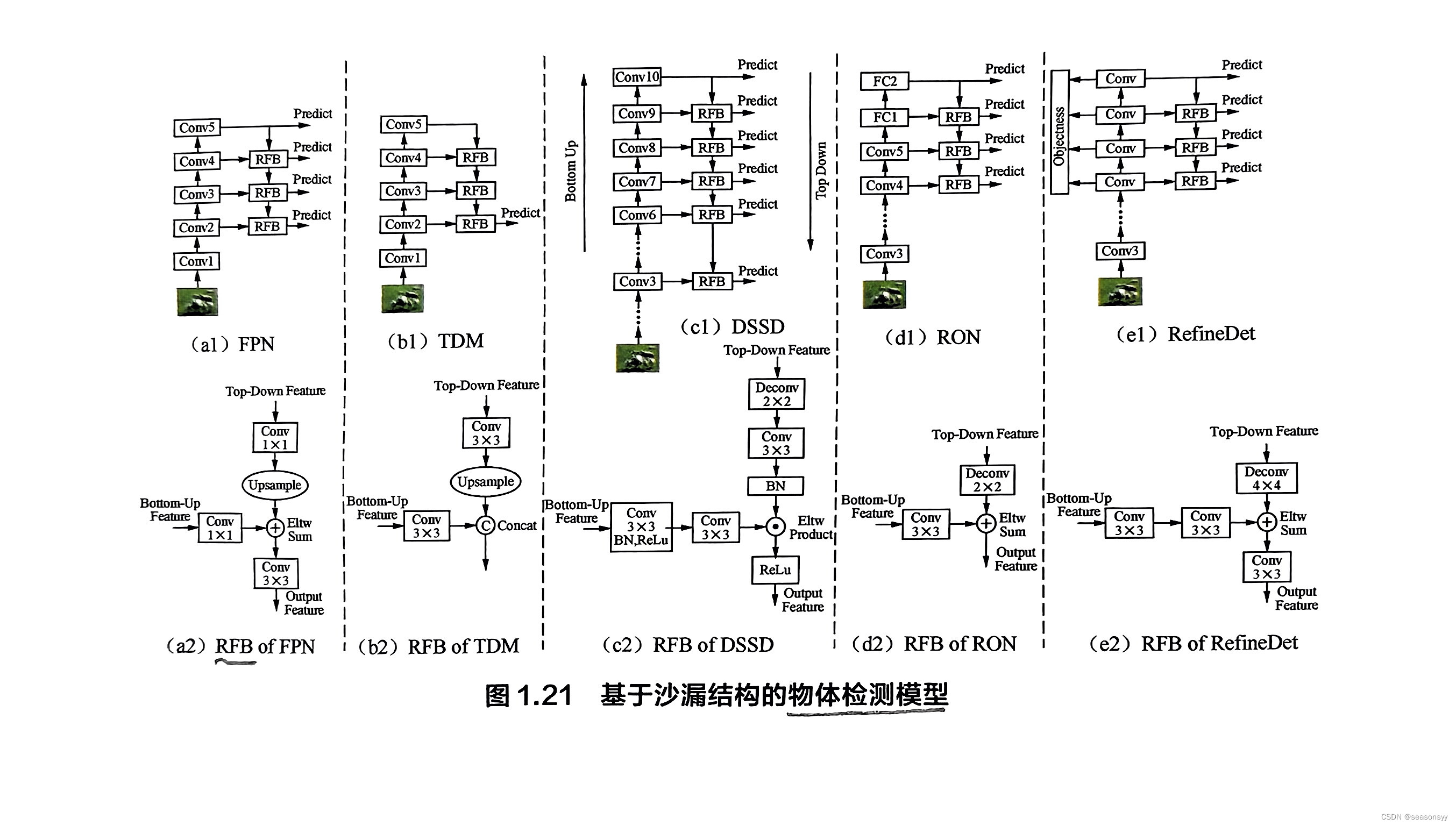
图中的RFB(Reverse Fusion Block)是将上采样后的深层特征和浅层特征进行融合的模块。
- 作用:
- 在这些应用中,沙漏结构的作用一般是将多尺度信息进行融合;
- 同时,沙漏结构单元中堆叠的多个卷积层可以提升感受野,增强模型对小尺寸但又依赖上下文的物体(如人体关节点)的感知能力。
[24] NEWELL A, YANG K,DENG J. Stacked hourglass networks for human pose estimation[C]//European Conference on Computer Vision. Springer, 2016: 483-499.
[25] SHRIVASTAVA A, SUKTHANKAR R, MALIK J, et al. Beyond skip connections: Top-down modulation for object detection[J].arXiv preprint arXiv: 1612.06851,2016.
[26] LIN T-Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2017: 2117-2125.
[27] KONG T,SUN F, YAO A,et al. RON: Reverse connection with objectness prior networks for object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017:5936-5944.
[28] FU C-Y, LIU W, RANGA A,et al. DSSD: Deconvolutional single shot detector[J]. arXiv preprint arXiv:1701.06659,2017.
[29] ZHANG S,WEN L,BIAN X,et a1. Single-shot refinement neural network for object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2018: 4203-4212.
参考文献:
《百面深度学习》 诸葛越 江云胜主编
出版社:人民邮电出版社(北京)
ISBN:978-7-115-53097-4
2020年7月第1版(2020年7月北京第二次印刷)
推荐阅读:
//好用小工具↓
分享一个免费的chat工具
分享一个好用的读论文的网站
// 深度学习经典网络↓
LeNet网络(1989年提出,1998年改进)
AlexNet网络(2012年提出)
VGGNet网络(2014年提出)
LeNet、AlexNet、VGGNet总结
GoogLeNet网络(2014年提出)
ResNet网络(2015年提出)