GitHub - THU-MIG/yolov10: YOLOv10: Real-Time End-to-End Object Detection
YOLOv10 - Ultralytics YOLO Docs
https://arxiv.org/pdf/2405.14458 论文地址
最近yolo又出了个yolov10了,不得不感慨CV是真卷,毕竟yolov9也才没多久。记录一下阅读笔记。
目录
方法
1.双标签分配 dual label assignments:
2.模型设计
2.1 Lightweight classification head
2.2 Spatial-channel decoupled downsampling
2.3 Rank-guided block design.
2.4 Large-kernel convolution
2.5 Partial self-attention (PSA)
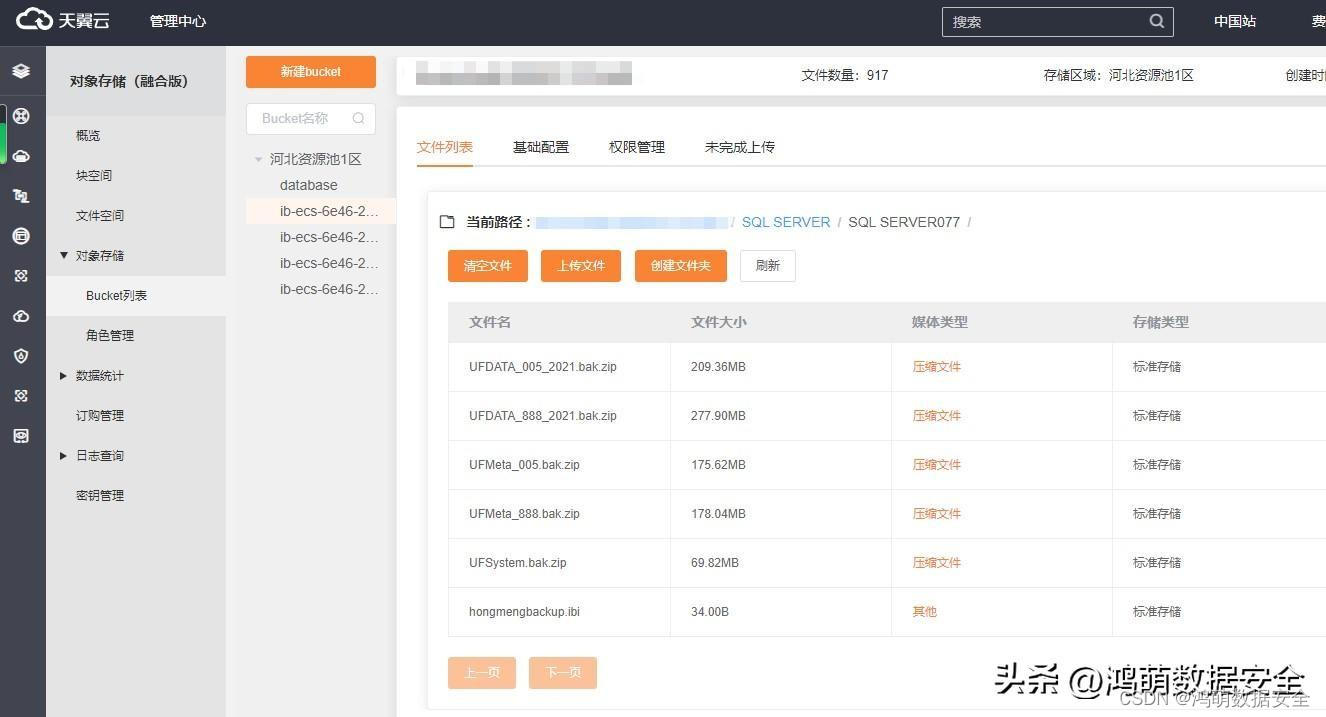
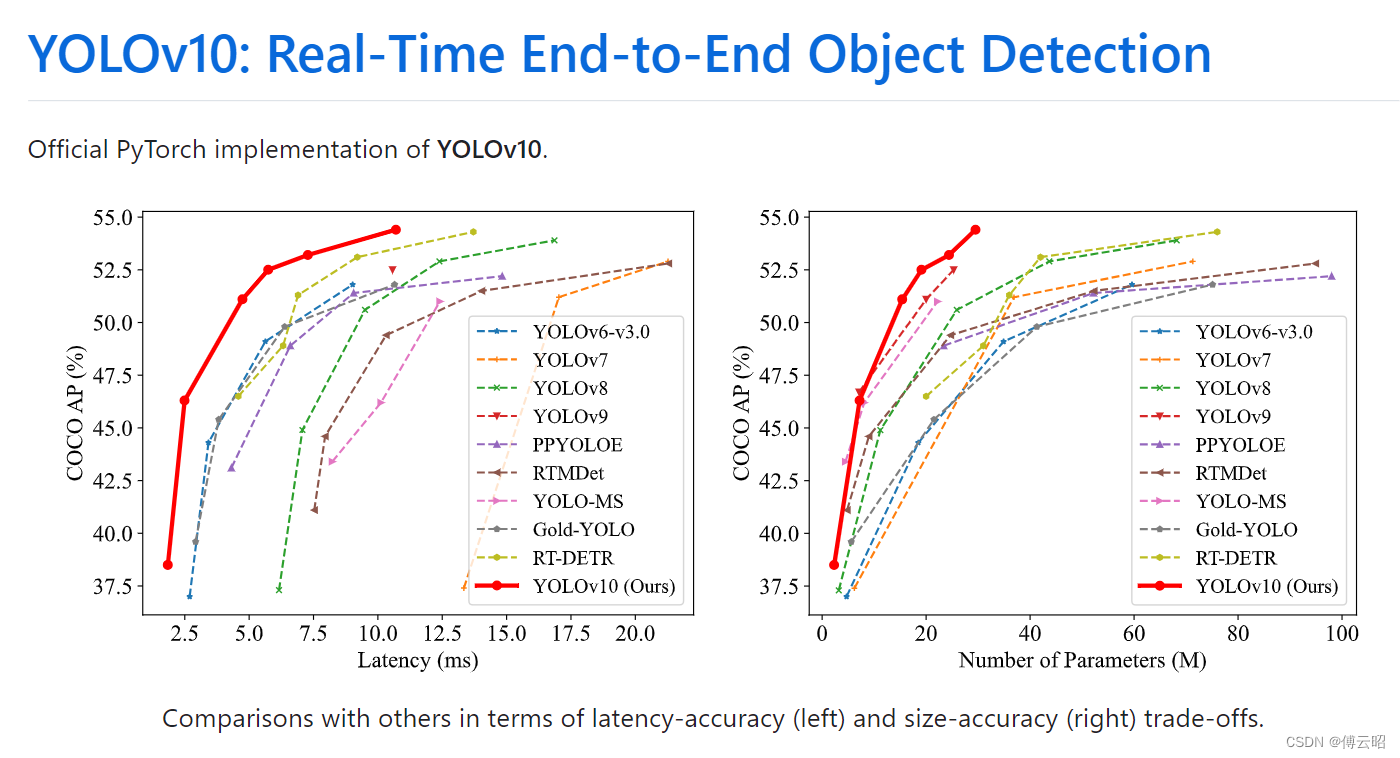
结果:
方法
主要特点总结:
- 7*7 conv,DW,PW,
- partial slef-attention,
- one2many && one2one head(nms free),
- Rank-guided block
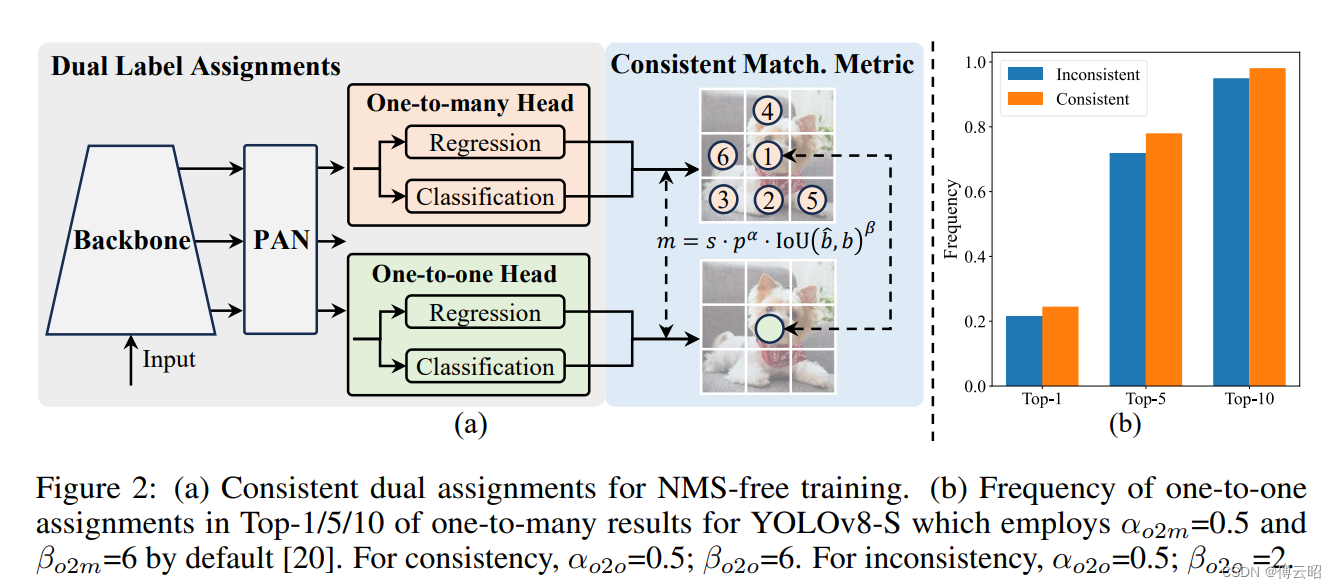
这就是网络的结构了,前面的backbone和PAN都和yolos差不多。核心的特点是:
1.双标签分配 dual label assignments:
one-to-many head:一个gt对应了多个正样本候选预测bbox。
one-to-one head:一个gt对应了一个正样本候选预测bbox,避免NMS.
one-to-many head 和one-to-one head,大概逻辑是,以前的yolo大多都是anchor-based,需要后处理NMS,这必然需要计算资源和时间,这里他在训练的时候把one-to-many head 和one-to-one head同时一起训练,而再推理的时候只使用one-to-one head做推理,那么可以避免NMS。但是呢one-to-one head的训练效果一般都不如one-to-many head,所以作者采用了one-to-many head 去监督one-to-one head,让它向one-to-many学习,效果也会不错。

2.模型设计
2.1 Lightweight classification head
作者认为分类是很简单的任务,难度小,不需要像回归头那样那么大的参数量,所以简化了一下。
2.2 Spatial-channel decoupled downsampling
作者认为:传统的YOLO模型使用3x3标准卷积,并以步长2来实现空间下采样和通道转换(从C到2C)。这种方法计算量较大。作者采用先使用PW卷积来调整通道维度,然后再使用DW卷积来执行空间下采样。从而减少参数量和提高速度。
2.3 Rank-guided block design.
-
YOLO模型通常会在所有阶段使用相同的基本构建块,如YOLOv8中的瓶颈块。
-
作者使用"内在秩"分析了每个阶段的冗余度。结果显示,更深的阶段和更大的模型更容易存在更多的冗余。
-
这表明对所有阶段都应用相同的块设计可能是次优的,无法达到最佳的容量效率权衡。
-
为解决这个问题,作者提出了一种基于秩的块设计方案,使用更紧凑的架构设计来降低冗余的阶段的复杂度。
-
具体来说,作者提出了一种紧凑的翻转块(CIB)结构,它利用廉价的深度卷积进行空间混合,使用高效的逐点卷积进行通道混合。
-
接着,作者提出了一种基于秩的块分配策略,在保持竞争力容量的同时实现更高的效率。
-
这个策略会根据各阶段的内在秩排序,逐步将领先阶段的基本块替换为CIB,只要性能不降低就会一直替换下去。
-
通过这种自适应的紧凑块设计,可以在不影响性能的情况下实现更高的效率。

2.4 Large-kernel convolution
作者认为:
-
使用大卷积核深度卷积是一种有效的方法,可以增大模型的感受野,提高性能。
-
但是如果在所有阶段都使用大卷积核,可能会对用于检测小目标的浅层特征造成污染,同时也会引入较大的I/O开销和延迟。
-
因此,作者提出在紧凑的翻转块(CIB)中,仅在深层阶段使用大卷积核深度卷积。
-
具体来说,就是将CIB中第二个3x3深度卷积的核大小增加到7x7。
-
同时,作者还使用结构重参数化技术,添加了一个额外的3x3深度卷积分支,以缓解优化问题,但不增加推理开销。
-
随着模型尺寸的增大,其感受野自然会扩大,使用大卷积核的收益也会减小。
-
因此,作者只在小模型规模中采用大卷积核,随着模型变大,逐步放弃使用大卷积核。
2.5 Partial self-attention (PSA)
-
Self-attention因其出色的全局建模能力,在各种视觉任务中广泛应用。但是它也存在高计算复杂度和高内存开销的问题。
-
针对注意力头的冗余性,作者提出了一种高效的PSA模块设计。
-
具体来说,PSA先将特征沿通道方向均等划分为两部分,只将其中一部分输入到由MHSA和FFN组成的NPSA块中。
-
两部分特征经过NPSA块后再进行拼接和1x1卷积融合。
-
同时,作者还采取了一些措施来进一步提高PSA的效率,如调整MHSA中query、key和value的维度比例,以及用BatchNorm替代LayerNorm。
-
此外,PSA模块仅置于最低分辨率的Stage 4之后,避免self-attention的二次复杂度带来的过多开销。
-
这种方式可以在保持低计算成本的情况下,将self-attention的全局表示学习能力引入到YOLO模型中,从而提高模型性能。
结果:

个人感觉,可能存在overfit的情况!!!