| 时间 | 版本 | 修改人 | 描述 |
|---|---|---|---|
| 2024年5月28日15:03:49 | V0.1 | 宋全恒 | 新建文档 |
简介
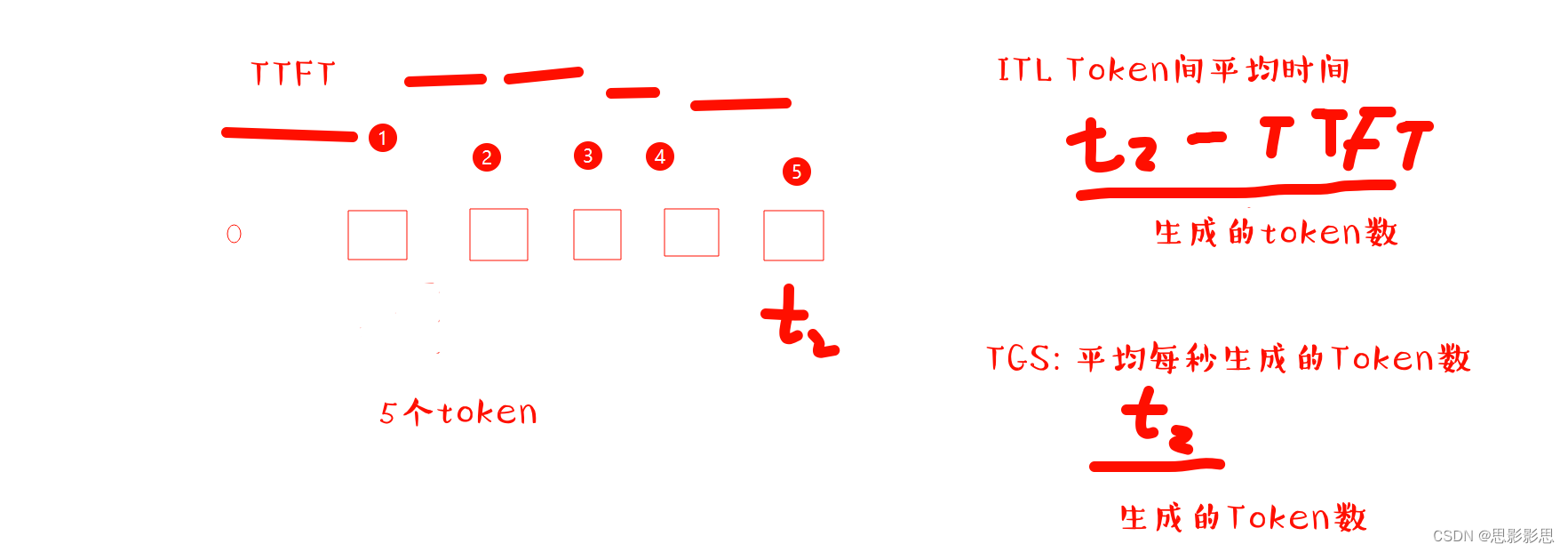
本文主要用于求解大模型推理过程中的几个指标:
主要是TTFT,ITL, TGS
代码片段
import osdata_dir = "/workspace/models/"
model_name = "Llama-2-7b-hf"
data_dir = data_dir + model_nameimport transformers
from transformers import AutoTokenizer, AutoModel
from transformers import LlamaForCausalLM, LlamaTokenizerimport time
import torch
# from ixformer.inference.models.chatglm2_6b import ChatGLMForConditionalGeneration
# from torch.cuda import profilerimport argparse
import pickle
# from thop import profile
import json
from datetime import datetimedef main(args):tokenizer = AutoTokenizer.from_pretrained(data_dir, trust_remote_code=True, device_map="auto")model = transformers.AutoModelForCausalLM.from_pretrained(data_dir, trust_remote_code=True, device_map='auto')INPUT_LEN = [32,64,128,256,512,1024,2048]# INPUT_LEN = [1024, 2048]current_time = datetime.now().strftime("%Y%m%d%H%M%S")res_file = "result_" + model_name + "_fp16_" + current_time + ".txt"print("res_file {res_file}")with open(res_file, "w") as f_result:with open("input_request_list","rb") as f:input_request_list = pickle.load(f)for input_request in input_request_list:print(input_request)test_len = input_request[1]if test_len not in INPUT_LEN:continueprint("testing len:{}...".format(test_len))query, prompt_len, output_len = input_requestinputs = tokenizer(query, return_tensors='pt').to('cuda')geneate_ids = model.generate(inputs.input_ids, max_new_tokens=1, max_length=None, do_sample=False)# response, _ = model.chat(tokenizer, query, max_new_tokens=1, do_sample=False, history=[])#torch.cuda.synchronize()print("start TTFT test...")TTFT_list = []for _ in range(2):start_time = time.time()geneate_ids = model.generate(inputs.input_ids, max_new_tokens=1, max_length=None, do_sample=False)# response, _ = model.chat(tokenizer, query, do_sample=False, max_new_tokens=1,max_length=None, history=[])#torch.cuda.synchronize()end_time = time.time()TTFT = (end_time - start_time) * 1000print(TTFT)TTFT_list.append(TTFT)TTFT = sum(TTFT_list)/len(TTFT_list)print("time to first token:{:2f} ms".format(TTFT))print("start ITL test...")ITL_list = []out_tokens_num = 0for _ in range(2):start_time = time.time()geneate_ids = model.generate(inputs.input_ids, max_new_tokens=50, max_length=None, do_sample=False)outputs = geneate_ids.tolist()[0][len(inputs["input_ids"][0]):]# response, _ = model.chat(tokenizer, query, max_new_tokens=50, do_sample=False, history=[])#torch.cuda.synchronize()end_time = time.time()# out_tokens_num = len(tokenizer(response).input_ids)out_tokens_num = len(outputs)print("out_tokens_num:{}".format(out_tokens_num))ITL = ((end_time - start_time) * 1000 - TTFT) / out_tokens_numprint(ITL)ITL_list.append(ITL)ITL = sum(ITL_list) / len(ITL_list)print("inter-token latency:{:2f} ms".format(ITL))f_result.write("In len:{}\n".format(test_len))f_result.write("Out len:{}\n".format(out_tokens_num))f_result.write("TTFT:{:.2f}\n".format(TTFT))f_result.write("ITL:{:.2f}\n".format(ITL))f_result.write("\n")f_result.flush()if __name__ == "__main__":main()调试过程
vscode配置调试代码
具体可以参见, 05-16 周四 vscode 搭建远程调试环境
launch.json配置
{// 使用 IntelliSense 了解相关属性。 // 悬停以查看现有属性的描述。// 欲了解更多信息,请访问: https://go.microsoft.com/fwlink/?linkid=830387"version": "0.2.0","configurations": [{"name": "LLaMa2 推理","type": "debugpy","request": "launch","program": "/workspace/infer/test_dql_fp16.py","console": "integratedTerminal","cwd": "/workspace/infer/","args": []}]
}
执行日志
(python38_torch201_cuda) root@node-01:/workspace/infer/# cd /workspace/infer/ ; /usr/bin/env /root/miniconda/envs/python38_torch201_cuda/bin/python /root/.vscode-server/extensions/ms-python.debugpy-2024.0.0-linux-x64/bundled/libs/debugpy/adapter/../../debugpy/launcher 52003 -- /workspace/infer/test_dql_fp16.py
XCCL /workspace/tools/xccl_rdma-ubuntu_x86_64/so/libbkcl.so loaded
[15:02:54][node-01][6791][WARN][BKCL][globals.cpp:127] set BKCL BLOCK SIZE to 0
SYMBOL_REWRITE torch success
SYMBOL_REWRITE torchvision success
[2024-05-28 15:02:56,781] [INFO] [real_accelerator.py:158:get_accelerator] Setting ds_accelerator to cuda (auto detect)
MODULE_REPLACE apex success
MODULE_REPLACE fused_lamb success
WARNING: hook error! No module named 'megatron'
SYMBOL_REWRITE deepspeed success
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:16<00:00, 8.30s/it]
res_file {res_file}
['I have an interview about product speccing with the company Weekend Health. Give me an example of a question they might ask with regards about a new feature', 32, 39]
testing len:32...
/root/miniconda/envs/python38_torch201_cuda/lib/python3.8/site-packages/transformers/generation/configuration_utils.py:362: UserWarning: `do_sample` is set to `False`. However, `temperature` is set to `0.6` -- this flag is only used in sample-based generation modes. You should set `do_sample=True` or unset `temperature`.warnings.warn(
/root/miniconda/envs/python38_torch201_cuda/lib/python3.8/site-packages/transformers/generation/configuration_utils.py:367: UserWarning: `do_sample` is set to `False`. However, `top_p` is set to `0.9` -- this flag is only used in sample-based generation modes. You should set `do_sample=True` or unset `top_p`.warnings.warn(
Both `max_new_tokens` (=1) and `max_length`(=None) seem to have been set. `max_new_tokens` will take precedence. Please refer to the documentation for more information. (https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)
2024-05-28 15:04:24.257995: I tensorflow/core/util/util.cc:169] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`.
start TTFT test...
/root/miniconda/envs/python38_torch201_cuda/lib/python3.8/site-packages/transformers/generation/configuration_utils.py:362: UserWarning: `do_sample` is set to `False`. However, `temperature` is set to `0.6` -- this flag is only used in sample-based generation modes. You should set `do_sample=True` or unset `temperature`.warnings.warn(
/root/miniconda/envs/python38_torch201_cuda/lib/python3.8/site-packages/transformers/generation/configuration_utils.py:367: UserWarning: `do_sample` is set to `False`. However, `top_p` is set to `0.9` -- this flag is only used in sample-based generation modes. You should set `do_sample=True` or unset `top_p`.warnings.warn(
Both `max_new_tokens` (=1) and `max_length`(=None) seem to have been set. `max_new_tokens` will take precedence. Please refer to the documentation for more information. (https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)
80.51776885986328
Both `max_new_tokens` (=1) and `max_length`(=None) seem to have been set. `max_new_tokens` will take precedence. Please refer to the documentation for more information. (https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)
75.45685768127441
time to first token:77.987313 ms
start ITL test...
Both `max_new_tokens` (=50) and `max_length`(=None) seem to have been set. `max_new_tokens` will take precedence. Please refer to the documentation for more information. (https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)
out_tokens_num:50
65.30064821243286
Both `max_new_tokens` (=50) and `max_length`(=None) seem to have been set. `max_new_tokens` will take precedence. Please refer to the documentation for more information. (https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)
out_tokens_num:50
65.08305311203003
inter-token latency:65.191851 ms
['In Java, I want to replace string like "This is a new {object} at {place}" with a Map, {object: "student", "point 3, 4"}, and get a result "This is a new student at point 3, 4". How can I do?', 64, 494]
testing len:64...
Both `max_new_tokens` (=1) and `max_length`(=None) seem to have been set. `max_new_tokens` will take precedence. Please refer to the documentation for more information. (https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)
start TTFT test...
Both `max_new_tokens` (=1) and `max_length`(=None) seem to have been set. `max_new_tokens` will take precedence. Please refer to the documentation for more information. (https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)
82.96585083007812
Both `max_new_tokens` (=1) and `max_length`(=None) seem to have been set. `max_new_tokens` will take precedence. Please refer to the documentation for more information. (https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)
83.1289291381836
time to first token:83.047390 ms
start ITL test...
Both `max_new_tokens` (=50) and `max_length`(=None) seem to have been set. `max_new_tokens` will take precedence. Please refer to the documentation for more information. (https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)
out_tokens_num:50
67.13986396789551
Both `max_new_tokens` (=50) and `max_length`(=None) seem to have been set. `max_new_tokens` will take precedence. Please refer to the documentation for more information. (https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)
out_tokens_num:50
64.81363773345947
inter-token latency:65.976751 ms
["MK runs out of the palace and opens the gates, allowing Macaque and the freedom fighters to come in and begin taking out Wukong's guards. The dark-haired soldiers who Wukong had forced into his army cheer at the sight of their true king and begin turning on the golden-haired soldiers. MK just barely manages to shout a warning to Macaque that Wukong is on his way before Wukong appears, leaping down from a cloud and knocking Macaque out of the sky and slamming him hard into the ground. Let's write that whole scene with details and dialogue.", 128, 701]
testing len:128...
Both `max_new_tokens` (=1) and `max_length`(=None) seem to have been set. `max_new_tokens` will take precedence. Please refer to the documentation for more information. (https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)
start TTFT test...
Both `max_new_tokens` (=1) and `max_length`(=None) seem to have been set. `max_new_tokens` will take precedence. Please refer to the documentation for more information. (https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)
102.16498374938965
Both `max_new_tokens` (=1) and `max_length`(=None) seem to have been set. `max_new_tokens` will take precedence. Please refer to the documentation for more information. (https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)
102.17642784118652
time to first token:102.170706 ms
start ITL test...
Both `max_new_tokens` (=50) and `max_length`(=None) seem to have been set. `max_new_tokens` will take precedence. Please refer to the documentation for more information. (https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)
out_tokens_num:50
64.69708442687988
Both `max_new_tokens` (=50) and `max_length`(=None) seem to have been set. `max_new_tokens` will take precedence. Please refer to the documentation for more information. (https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)
out_tokens_num:50
67.01707363128662
inter-token latency:65.857079 ms
['this is one specification for the customer, can you explain it \n\nusing System;\nusing System.Linq;\nusing Ardalis.GuardClauses;\nusing Ardalis.Specification;\nusing uInvoice.Core.Entities;\n\nnamespace uInvoice.Core.Specifications\n{\n public class CustomerByIdWithIncludesSpec : Specification, ISingleResultSpecification\n {\n public CustomerByIdWithIncludesSpec(Guid customerId)\n {\n Guard.Against.NullOrEmpty(customerId, nameof(customerId));\n\n Query.Where(customer => customer.CustomerId == customerId && customer.IsActive == true)\n .OrderBy(customer => customer.CustomerCode)\n .Include(f => f.CustomerAddresses)\n .Include(f => f.CustomerEmailAddresses)\n .Include(f => f.CustomerPhoneNumbers)\n .Include(f => f.CustomerPriceLists)\n .Include(f => f.Invoices)\n .AsNoTracking();\n }\n }\n}', 256, 376]
testing len:256...
Both `max_new_tokens` (=1) and `max_length`(=None) seem to have been set. `max_new_tokens` will take precedence. Please refer to the documentation for more information. (https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)
start TTFT test...
Both `max_new_tokens` (=1) and `max_length`(=None) seem to have been set. `max_new_tokens` will take precedence. Please refer to the documentation for more information. (https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)
130.12409210205078
Both `max_new_tokens` (=1) and `max_length`(=None) seem to have been set. `max_new_tokens` will take precedence. Please refer to the documentation for more information. (https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)
129.8387050628662
time to first token:129.981399 ms
start ITL test...
Both `max_new_tokens` (=50) and `max_length`(=None) seem to have been set. `max_new_tokens` will take precedence. Please refer to the documentation for more information. (https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)
out_tokens_num:50
66.0555100440979
Both `max_new_tokens` (=50) and `max_length`(=None) seem to have been set. `max_new_tokens` will take precedence. Please refer to the documentation for more information. (https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)
out_tokens_num:50
64.68253374099731
inter-token latency:65.369022 ms
['Nezha nods in agreement and turns his chariot towards the city. As they fly over the rooftops, he asks MK about Pigsy and how he came to be with Wukong.\n\nMK tells Nezha about how he had been kidnapped by Wukong and taken to the Mountain of Flowers and Fruit, where he was put in the alcove cage. He explains how Macaque had helped him escape and how they had been hiding out at Pigsy\'s noodle shop ever since.\n\nNezha listens intently, his expression grave. "I\'m sorry you had to go through that," he says. "But I\'m glad you\'re safe now."\n\nAs they approach the noodle shop, Nezha gently sets the chariot down in the street. MK hops out and runs inside. Pigsy is there, cooking noodles as usual. When he sees MK, he drops his ladle and runs over to give him a big hug.\n\n"Thank goodness you\'re safe!" Pigsy says, tears in his eyes. "I was so worried about you."\n\nMK tells Pigsy about everything that happened, about how Macaque had saved him and how Nezha had helped them. Pigsy listens in amazement, his eyes widening with each new detail.\n\nNezha steps inside the shop and nods at Pigsy. "I\'m glad to see you\'re both doing well," he says.\n\nPigsy looks at Nezha with a mixture of fear and awe. "Thank you for everything you\'ve done," he says. "I don\'t know how to repay you."\n\nNezha smiles. "You don\'t need to repay me. I did what I did because it was the right thing to do."\n\nPigsy nods, still looking a bit overwhelmed. "I understand. Thank you again."\n\nMK looks up at Nezha, his eyes shining. "Thank you for bringing me home," he says.\n\nNezha ruffles MK\'s hair affectionately. "Of course. Take care of yourself, okay?"\n\nWith that, Nezha steps back into his chariot and takes off into the sky. Pigsy and MK watch him go, their hearts filled with gratitude and wonder at the amazing events that had just transpired.', 512, 38]
testing len:512...
Both `max_new_tokens` (=1) and `max_length`(=None) seem to have been set. `max_new_tokens` will take precedence. Please refer to the documentation for more information. (https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)
start TTFT test...
Both `max_new_tokens` (=1) and `max_length`(=None) seem to have been set. `max_new_tokens` will take precedence. Please refer to the documentation for more information. (https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)
285.5086326599121
Both `max_new_tokens` (=1) and `max_length`(=None) seem to have been set. `max_new_tokens` will take precedence. Please refer to the documentation for more information. (https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)
279.91533279418945
time to first token:282.711983 ms
start ITL test...
Both `max_new_tokens` (=50) and `max_length`(=None) seem to have been set. `max_new_tokens` will take precedence. Please refer to the documentation for more information. (https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)
out_tokens_num:50
67.791428565979
Both `max_new_tokens` (=50) and `max_length`(=None) seem to have been set. `max_new_tokens` will take precedence. Please refer to the documentation for more information. (https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)
out_tokens_num:50
65.05216598510742
inter-token latency:66.421797 ms
['Yes, I can definitely help you with that!\n\nThe Python script would need to perform the following functions:\n\n1. Initialize the GPIO pins and relay modules to control the solenoids\n2. Monitor the pressure switch for input to start the sequence\n3. Start the timed sequences for each solenoid, adjusting the duration based on user input from the touchscreen\n4. Log data for each sequence, including the start and end times, solenoid used, and location data from the GPS module\n5. Upload the data to the cloud through WiFi or Bluetooth\n\nHere\'s an example script to get you started:\n```python\nimport time\nimport RPi.GPIO as GPIO\nimport pygame\nimport gpsd\n\n# Initialize the GPIO pins and relay modules\nGPIO.setmode(GPIO.BCM)\nrelay_pins = [1, 2, 3, 4, 5, 6, 7, 8, 9]\nfor pin in relay_pins:\n GPIO.setup(pin, GPIO.OUT)\n\n# Initialize the GPS module\ngpsd.connect()\n\n# Initialize the Pygame GUI\npygame.init()\nscreen = pygame.display.set_mode((800, 480))\nfont = pygame.font.SysFont("Arial", 24)\n\n# Function to start a timed sequence for a solenoid\ndef run_sequence(solenoid, duration):\n GPIO.output(relay_pins[solenoid], GPIO.HIGH)\n time.sleep(duration)\n GPIO.output(relay_pins[solenoid], GPIO.LOW)\n\n# Main loop\nwhile True:\n # Get input from the pressure switch to start the sequence\n if GPIO.input(pressure_switch_pin):\n # Display the GUI on the touchscreen\n screen.fill((255, 255, 255))\n label = font.render("Select sequence duration for each solenoid:", True, (0, 0, 0))\n screen.blit(label, (50, 50))\n solenoid_durations = [0] * 9\n for i in range(9):\n label = font.render("Solenoid " + str(i + 1) + " duration (seconds):", True, (0, 0, 0))\n screen.blit(label, (50, 100 + i * 50))\n pygame.draw.rect(screen, (0, 0, 255), (350, 100 + i * 50, 100, 30))\n pygame.draw.rect(screen, (255, 0, 0), (460, 100 + i * 50, 100, 30))\n pygame.display.update()\n\n # Wait for user input on the touchscreen\n running = True\n while running:\n for event in pygame.event.get():\n if event.type == pygame.QUIT:\n running = False\n elif event.type == pygame.MOUSEBUTTONDOWN:\n pos = pygame.mouse.get_pos()\n for i in range(9):\n if pos[0] >= 350 and pos[0] <= 450 and pos[1] >= 100 + i * 50 and pos[1] <= 130 + i * 50:\n solenoid_durations[i] += 1\n pygame.draw.rect(screen, (0, 255, 0), (350, 100 + i * 50, solenoid_durations[i] * 10, 30))\n pygame.display.update()\n elif pos[0] >= 460 and pos[0] <= 560 and pos[1] >= 100 + i * 50 and pos[1] <= 130 + i * 50:\n solenoid_durations[i] -= 1\n if solenoid_durations[i] <\n```', 1024, 18]
testing len:1024...
Both `max_new_tokens` (=1) and `max_length`(=None) seem to have been set. `max_new_tokens` will take precedence. Please refer to the documentation for more information. (https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)
start TTFT test...
Both `max_new_tokens` (=1) and `max_length`(=None) seem to have been set. `max_new_tokens` will take precedence. Please refer to the documentation for more information. (https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)
526.5488624572754
Both `max_new_tokens` (=1) and `max_length`(=None) seem to have been set. `max_new_tokens` will take precedence. Please refer to the documentation for more information. (https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)
537.6203060150146
time to first token:532.084584 ms
start ITL test...
Both `max_new_tokens` (=50) and `max_length`(=None) seem to have been set. `max_new_tokens` will take precedence. Please refer to the documentation for more information. (https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)
out_tokens_num:50
65.85144281387329
Both `max_new_tokens` (=50) and `max_length`(=None) seem to have been set. `max_new_tokens` will take precedence. Please refer to the documentation for more information. (https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)
out_tokens_num:50
67.71608114242554
inter-token latency:66.783762 ms
['Annie the Ant: En klønete og glemsk maur som ved et uhell snubler over et mykorrhizanettverk mens hun leter etter mat.\nWoody the Tree: Et klokt og tålmodig tre som lærer de andre karakterene om fordelene med mykorrhizale forhold og hvordan de hjelper trær å vokse.\nBuzzy the Bee: En hyperaktiv og energisk bie som lærer om mykorrhisering mens hun pollinerer blomster i et mykorrhizalt økosystem.\nSammy the Soil: En klønete og vennlig haug med jord som fungerer som en guide for de andre karakterene, og viser dem mykorrhiseringens underverk og hvordan det bidrar til sunn jord.\nBella the Bacteria: En frekk og selvsikker bakterie som vet alt om den viktige rollen til bakterier i mykorrhiza-forhold og hjelper de andre karakterene å forstå dette også.\nPippin the Plant: En nysgjerrig og eventyrlysten plante som oppdager fordelene med mykorrhisering mens du utforsker skogbunnen.\nSammy the Soil, Pippin the Plant og vennene deres var fast bestemt på å finne en måte å hjelpe den forurensede Sammy i hagen deres. Med hjelp av Dr. Baltazar lærte de mer om mycoremediation og hvordan sopp som østers sopp kan bidra til å rydde opp forurenset jord.\nSammen bestemte de seg for å prøve et eksperiment med østers soppmycelium for å rydde opp petroleum i Sammys jord. Pippin plantet noen østers sopp gyte i forurenset jord, og de ventet å se hva som ville skje.\nEtter noen uker kunne de se myceliet spre seg gjennom jorda og bryte ned oljen. Snart begynte små østers sopp å vokse, og jorda begynte å se sunnere ut.\ntil hverandre. En god lesning for elevene deres, og en fin avslutning pÃ¥ kurssløpet deres.\nSammy the Soil ble overrasket over kraften til mycorrhizal sopp og hvordan de kunne bidra til å rydde opp forurenset jord. Han følte seg stolt over å være en del av et så utrolig undergrunnssamfunn.\nDa de fortsatte å lære mer om mycorrhizal sopp, oppdaget gruppen at disse små organismer også var viktige for plantevekst. Woody the Tree forklarte at mycorrhizal sopp danner et gjensidig fordelaktig forhold til plantens røtter, og hjelper dem med å absorbere næringsstoffer fra jorda.\nBuzzy the Bee var spent på å høre at mykorrhizal sopp også var viktig for blomstene hun besøkte, og at de bidro til å gjøre nektar og pollen mer næringsrik for henne og hennes andre bier.\nAnnie the Ant var fascinert av det komplekse nettverket av mycorrhizal sopp som koblet forskjellige planter og trær i skogen. Hun innså at disse soppene var som skogens internett, slik at forskjellige organismer kunne kommunisere og dele ressurser.\nSammen fortsatte vennegjengen å utforske den utrolige verden av mykorrhizasopp, og de ble overrasket over hvor mye de måtte lære. De oppdaget at disse små organismene ikke bare var viktige for jordhelsen, men for helsen til hele økosystemer.\nVed oljehullet er Pueblo tørrlandbruksteknikker utstilt i en offentlig park i sentrum. Hagen, designet og Pippin the Planed av den urfolksledede organisasjonen milljøagewntenne hvordan mat og medisiner kan dyrkes i et miljø Men de har et problem: Sammy-ene er giftige.\nPetroleum fra en nærliggende parkeringsplass siver inn i Sammy når det regner sko østerssopp vil rydde opp i rotet.\nDet har fungert før.\nMykolog Fungo the Fung forklarer at i en prosess som kalles mycoremediation, har sopp evnen til å fjerne kjemikalier fra Sammy the - og tungmetaller fra vann - gjennom myceliet.\n“De er på en måte naturens største nedbrytere, demonterende, langt bedre enn og kraftigere enn bakteriene Bella, dyrene og Pippin the Plans,” sa McCoy. “De bryter ned alle slags ting.”\nSopp har bidratt til å fjerne petroleum fra Sammy the Sammy overalt fra Orleans, California, hvor de ryddet opp i et lite motorolje- og dieseldrivstoffsøl på et samfunnssenter, til den ecmediation for å rydde opp i tungmetallene. De vet ennå ikke om anbefalingene deres vil føre til strengere oppryddingskrav. I mellomtiden gjør sammy de kan for å rydde opp i petroleum ved Food Oasis.begravde pippin murstein inokulert med østerssoppmycel. De planlegger å teste Sammy the Sammy våren for å se hvordan utbedringen fungerte.\n“Jeg tror det vanlige synet er at disse stedene har gått tapt for oss fordi de er forurenset,” sa sammy a. "Men for meg er det som om du ikke bare ville forlatt din syke sammy jorden sin for å lide alene.\n"Det er slik vi føler om disse stedene. De er syke. De trenger helbredelse. De trenger vår kjærlighet og oppmerksomhet m varianter vil vokse på mycelet til de oljespisende soppene til det meste av eller all oljen er borte.» Saken er at disse mycelene, nettverket av filamenter som soppen vokser på, de kan ikke se forskjellen mellom petroleum og næringsstoffer som glukose, så de er enn noen gang.»\nDe kan bryte ned stort sett alt bortsett fra noen ganske hardcore kjemiske substrater som plast og noen tungmetaller, inkludert gull og sølv," sa McCoy. Akkurat nå er Sammies dekket av gullfarget østerssopp fordi gull også er giftig. Til slutt vil soppen bli brun når de bryter ned petroleumenuadorianske Amazonas, hvor de brukes til å rense opp det største landbaserte oljeutslippet i historien.\nBeata Tsosie-Peña fra Santa Clara Pueblo er programkoordinator hos Tewa Women United. Hun sa at hennes eldste opplevde sykdom, sykdom og spontanabort som et resultat av forurensning i området.\nDet er ikke bare Sammy the s i hagen som er forurenset. Ved det nærliggende Los Alamos National Laboratory siver seksverdig krom, et tungmetall og kjent kreftfremkallende stoff inn i vannforsyningen.\nEn koalisjon inkludert pippin tar til orde for, gjennom offentlig vitnesbyrd i en prosess for bruker mycore', 2048, 597]
testing len:2048...
Both `max_new_tokens` (=1) and `max_length`(=None) seem to have been set. `max_new_tokens` will take precedence. Please refer to the documentation for more information. (https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)
start TTFT test...
Both `max_new_tokens` (=1) and `max_length`(=None) seem to have been set. `max_new_tokens` will take precedence. Please refer to the documentation for more information. (https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)
1192.781686782837
Both `max_new_tokens` (=1) and `max_length`(=None) seem to have been set. `max_new_tokens` will take precedence. Please refer to the documentation for more information. (https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)
1187.046766281128
time to first token:1189.914227 ms
start ITL test...
Both `max_new_tokens` (=50) and `max_length`(=None) seem to have been set. `max_new_tokens` will take precedence. Please refer to the documentation for more information. (https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)
out_tokens_num:50
67.58917331695557
Both `max_new_tokens` (=50) and `max_length`(=None) seem to have been set. `max_new_tokens` will take precedence. Please refer to the documentation for more information. (https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)
out_tokens_num:50
69.20413970947266
inter-token latency:68.396657 ms
代码执行
input_request_list
input_request_list = pickle.load(f)
print(f"len(input_request_list): {len(input_request_list)}")
for input_request in input_request_list:
断点可以发现,input_request_list内容如下
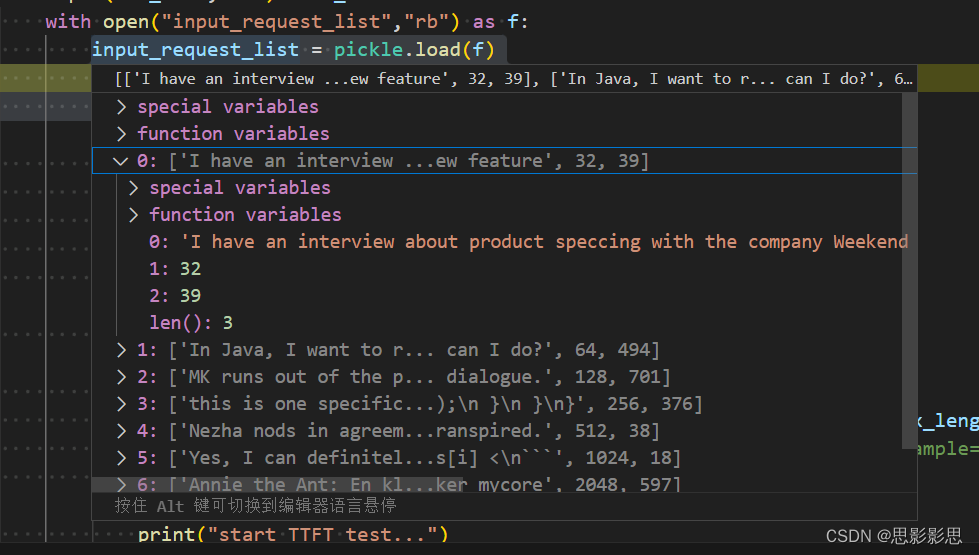
程序打印了input_request内容如下:
['I have an interview about product speccing with the company Weekend Health. Give me an example of a question they might ask with regards about a new feature', 32, 39]
搜索关键时要理解这三个过程,
query, prompt_len, output_len = input_requestinputs = tokenizer(query, return_tensors='pt').to('cuda')
geneate_ids = model.generate(inputs.input_ids, max_new_tokens=1, max_length=None, do_sample=False)
上述代码,关键是理解input_request,其是一个元祖,有三个元素组成,
- query 即提示词。
- 提示词长度,注意,不是字符串的长度,而是使用tokenizer处理后的tokenizer的长度。
- output_len 指定的事输出长度,在大模型推理过程中,由于随机性作用,输出长度无法指定,在代码执行中,该变量是没有读取的。
上述的代码,用已经初始化的tokenizer分词器,处理query,得到query对应的inputs,其中inputs包含了query对应的tokens信息。这些tokens信息,即inputs.input_ids。
而model.generate中传递进了query对应的token序列,得到了geneate_ids,即为生成的响应对应的序列。由于第一个model.generate相当于warmup,所以,这次推理不产生实际作用。
而query和32的关系,为使用llama2对应的分词器,处理query得到的token序列长度就是32,这是产品测试需求决定的。
理解分词序列
🎈query和对应的token序列为什么长度不一?
在大模型语境中,查询(query)的长度和其对应的token的长度可能不同的原因是因为在进行自然语言处理任务时,文本数据通常需要进行处理和转换成模型可以理解和处理的形式,这个过程通常会包括分词(tokenization)。
分词是将原始文本拆分成一系列独立的单元(token)或词语,每个单元代表着一个有意义且可被模型处理的独立单元。在不同任务中,这些单元可以是字符、子词(subword)、或者完整的词语。
由于分词过程对于不同文本有不同规则和策略,并且可能涉及到特定领域、术语等方面考虑,所以导致了查询(query)经过分词后生成了一系列token。这些token数量通常会比原始查询字符串长度更长。
另外,在大模型语境中还可能存在其他文本预处理步骤如去除停用词(stopword),进行大小写转换等操作,这也会影响到最终生成token序列的长度与原始查询字符串长度之间的差异。
总之,在自然语言处理任务中,为了使得模型更好地理解和学习文本信息,我们通常需要对输入数据进行预处理,并将其转化为可以被模型接受和操作的形式。因此,在大模型语境下查询(query)与其对应token序列长度差异较大是很正常情况。
🎈分词器处理query得到tokens序列,这些token序列是有序的吗?
是的,分词器处理查询(query)通常会产生一个有序的tokens序列。这意味着分词器将原始查询字符串拆分成一系列独立的单元(token),并按照它们在原始字符串中出现的顺序进行排列。
按顺序排列tokens是为了确保模型能够正确地理解和解释文本信息,并保留了输入文本中的语法和语义结构。这样,模型就可以更好地理解查询(query)所表达的含义,并基于此执行后续任务(如检索、分类等)。
因此,在大多数情况下,经过分词处理后生成的token序列是有序的,并且会尊重原始查询字符串中单词或子词出现的先后顺序。
统计TTFT
print("start TTFT test...")
TTFT_list = []
for _ in range(2):start_time = time.time()geneate_ids = model.generate(inputs.input_ids, max_new_tokens=1, max_length=None, do_sample=False)# response, _ = model.chat(tokenizer, query, do_sample=False, max_new_tokens=1,max_length=None, history=[])#torch.cuda.synchronize()end_time = time.time()TTFT = (end_time - start_time) * 1000print(TTFT)TTFT_list.append(TTFT)
TTFT = sum(TTFT_list)/len(TTFT_list)
print("time to first token:{:2f} ms".format(TTFT))
上述代码,主要是通过time库统计生成第一个token所耗费的实践,并且把每次统计得到的实践放在了TTFT_list中,在循环外,统计得到一个平均值。这里面较为重要的事max_new_tokens限制参数值为1,就是为了测量首Token生成时间。
统计ITL和TGS
print("start ITL test...")
ITL_list = []
TGS_list = []
out_tokens_num = 0
for _ in range(10):start_time = time.time()geneate_ids = model.generate(inputs.input_ids, max_new_tokens=50, max_length=None, do_sample=False)outputs = geneate_ids.tolist()[0][len(inputs["input_ids"][0]):]# response, _ = model.chat(tokenizer, query, max_new_tokens=50, do_sample=False, history=[])#torch.cuda.synchronize()end_time = time.time()# out_tokens_num = len(tokenizer(response).input_ids)out_tokens_num = len(outputs)print("out_tokens_num:{}".format(out_tokens_num))ITL = ((end_time - start_time) * 1000 - TTFT) / out_tokens_numTGS = ((end_time - start_time) * 1000 ) / out_tokens_numprint(f"ITL: {ITL}")print(f"TGS: {TGS}")ITL_list.append(ITL)TGS_list.append(TGS)
ITL = sum(ITL_list) / len(ITL_list)
TGS = sum(TGS_list) / len(TGS_list)上述代码的核心为:
geneate_ids = model.generate(inputs.input_ids, max_new_tokens=50, max_length=None, do_sample=False)outputs = geneate_ids.tolist()[0][len(inputs["input_ids"][0]):]
首先是使用model生成query对应的响应的tokens序列,在生成过程中限制max_new_tokens为50,即生成的token序列最长为50,具体生成的序列长度不确定。
这段代码的目的是使用给定的模型生成新的token序列,并将结果存储在outputs变量中。首先,使用模型的generate方法生成新的token序列。其中,inputs.input_ids是输入模型进行推理的token序列,max_new_tokens表示要生成最多多少个新的token(默认为50),max_length表示生成结果最大长度(默认为None),do_sample表示是否进行采样(默认为False)。然后,通过tolist()方法将生成的tensor转换成Python列表形式。geneate_ids.tolist()返回一个二维列表,第一维对应batch中每个样本,第二维对应每个样本生成的token序列。
接下来,在这个二维列表中获取第一个样本,并使用切片操作 [len(inputs["input_ids"][]):] 去掉之前输入部分重复出现在输出中。最后将处理后得到结果存储在outputs变量中。这里假设batch size为1,并且只取了一个示例进行处理。
实际生成的token序列长度被保存在了out_tokens_num变量中,接下来就是计算token中间序列。
geneate_ids.tolist()[0][len(inputs["input_ids"][0]):]
[0]表示batch只有1,取出第一个,而[len(inputs["input_ids"][0]):]是因为输出的tokens序列包含了输入的序列,因此截掉输入的token序列长度。因此统计出了生成的token序列数目。
执行总结
之前一直觉得大模型很神秘,其实大模型推理的驱动的主要逻辑还是使用的程序流程主要还是for循环,分支语句以及串行,笔者呢有多年的开发经验,理解起来还是比较简单的,但是大模型的结构,transformer的工作原理,这些确实是看了很多次都没有看懂的,压力很大。
能够每天有所进步或许是最开心的事情吧,日日知非,日日有进步,我希望余生都可以这样