🚀🚀🚀 YOLOv10: 实时端到端的目标检测。YOLOv10比最先进的YOLOv9延迟时间更低,测试结果可以与YOLOv9媲美,可能会成为YOLO系列模型部署的“新选择”。

官方论文地址:https://arxiv.org/pdf/2405.14458
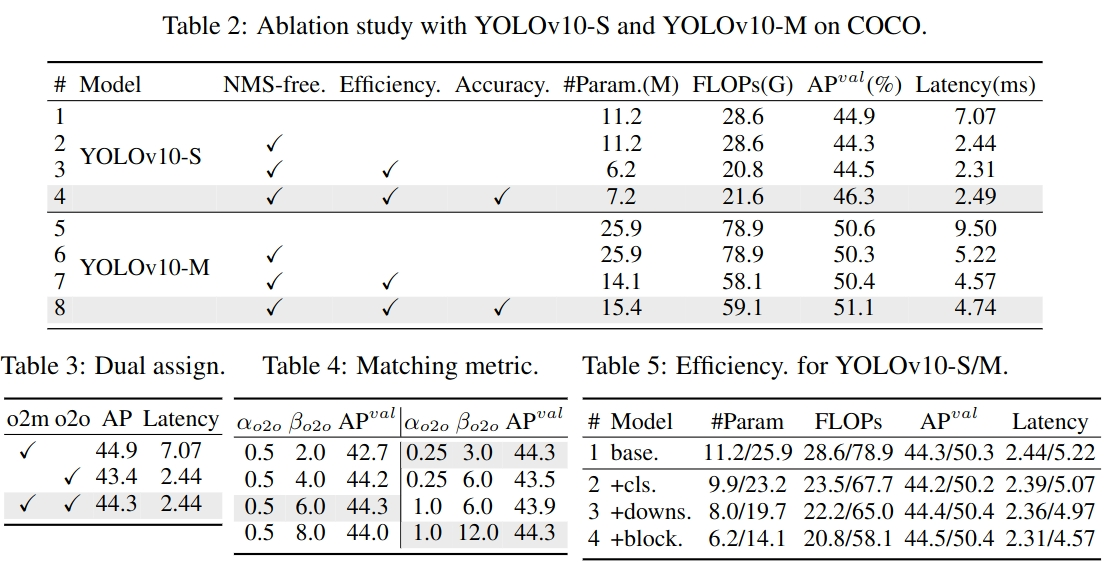
官方代码地址:https://github.com/THU-MIG/yolov10
首先,我们先看看YOLOv10的性能。

摘要
在过去的几年里,由于在计算成本和检测性能之间取得了有效的平衡,YOLOs已经成为实时目标检测领域的主导范式。研究人员已经对yolo的架构设计、优化目标、数据增强策略等进行了探索,并取得了显著进展。然而,对非最大抑制(NMS)的后处理依赖阻碍了yolo的端到端部署,并对推理延迟产生不利影响。此外,YOLOs中各部件的设计缺乏全面彻底的检查,导致计算冗余明显,限制了模型的能力。导致了次优的效率,以及有相当大的性能改进潜力。在这项工作中,我们的目标是从后处理和模型架构两个方面进一步推进YOLOs的性能效率边界。为此,我们首先提出了一种一致的双任务方法,用于无nms训练的YOLOs,它同时带来了具有竞争力的性能和较低的推理延迟。此外,我们还介绍了整体效率-精度驱动的模型设计策略。我们从效率和精度两个角度对YOLOs的各个组成部分进行了全面优化,大大降低了计算开销,增强了性能。我们的努力成果是用于实时端到端目标检测的新一代YOLO系列,称为YOLOv10。大量的实验表明,YOLOv10在各种模型尺度上都达到了最先进的性能和效率。例如,我们的YOLOv10-S在COCO上类似的AP下比RT-DETR-R18快1.8倍,同时参数数量和FLOPs减少2.8倍。与YOLOv9-C相比,在相同性能下,YOLOv10-B的延迟减少了46%,参数减少了25%。
1 介绍
实时目标检测一直是计算机视觉领域的研究热点,其目的是在低延迟下准确预测图像中目标的类别和位置。它被广泛应用于各种实际应用,包括自动驾驶、机器人导航、目标跟踪等。近年来,研究人员致力于设计基于cnn的目标检测器来实现实时检测。其中,yolo因其在性能和效率之间的平衡而越来越受欢迎。yolo的检测流程由模型前处理和NMS后处理两部分组成。然而,这两种方法都有不足之处,导致精度-延迟边界不够理想。
具体来说,yolo在训练过程中通常采用一对多的标签分配策略,即一个真值对象对应多个正样本。尽管这种方法产生了优越的性能,但需要NMS在推理过程中选择最佳的正预测。这降低了推理速度,使性能对NMS的超参数敏感,从而阻碍了YOLOs实现端到端最优部署。解决这个问题的一个方法是采用最近引入的端到端DETR架构。例如,RT-DETR提出了一种高效的混合编码器和最小不确定性查询选择,将detr推进到实时应用领域。然而,部署detr的固有复杂性阻碍了其在准确性和速度之间实现最佳平衡的能力。另一条路线是探索基于cnn的检测器的端到端检测,该检测器通常利用一对一分配策略来抑制冗余预测。然而,它们通常会引入额外的推理开销或实现次优性能。
此外,模型架构设计仍然是YOLOs面临的一个基本挑战,它对精度和速度有重要影响。为了实现更高效的模型架构,研究人员探索了不同的设计策略。为增强主干特征提取能力,提出了多种主计算单元,包括DarkNet、CSPNet、EfficientRep和ELAN等。对于Neck,研究了PAN、BiC、GD、RepGFPN等方法来增强多尺度特征融合。此外,还研究了模型缩放策略和重新参数化等技术。虽然这些努力取得了显著的进展,但从效率和精度的角度对YOLOs中各种组件的全面检查仍然缺乏。因此,yolo内部仍然存在相当大的计算冗余,导致参数利用率低,效率次优。此外,由此产生的受约束的模型能力也导致了较差的性能,为精度的提高留下了充足的空间。
在这项工作中,我们的目标是解决这些问题,并进一步推进YOLOs的精度-速度边界。我们的目标是在整个检测管道中进行后处理和模型架构。为此,首先,通过提出一种具有双标签分配和一致匹配度量的无nms yolo的一致双分配策略来解决后处理中的冗余预测问题。它使模型在训练过程中得到丰富和谐的监督,而在推理过程中不需要NMS,从而获得高效率的竞争性能。其次,通过对YOLOs中各部件的全面检测,提出了整体效率-精度驱动的模型体系结构设计策略;为了提高效率,我们提出了轻量化分类头(lightweight classification head)、空间通道解耦下采样(spatial-channel decoupled downsampling)和秩引导块设计(rank-guided block design),以减少显式计算冗余,实现更高效的架构。为了提高准确性,我们探索了大核卷积,并提出了有效的部分自关注模块来增强模型能力,利用低成本下的性能改进潜力。
基于这些方法,我们成功地实现了一系列具有不同模型尺度的实时端到端检测器,即YOLOv10- N / S / M / B / L / X。在目标检测的标准基准(即COCO)上进行的大量实验[33]表明,我们的YOLOv10在各种模型尺度的计算精度权衡方面可以显著优于以前最先进的模型。与YOLOv9-C相比,在相同的性能下,YOLOv10-B的延迟降低了46%。此外,YOLOv10具有高效的参数利用率。我们的YOLOv10-L / X比YOLOv8-L / X分别高出0.3 AP和0.5 AP,参数数量分别减少1.8倍和2.3倍。我们希望我们的工作能够激发该领域的进一步研究和进步。
个人总结:YOLOV10主要改进后处理部分和模型架构两个方面,提出了最新的YOLOv10。
- 1 提出一种具有双标签分配和一致匹配度量的无nms yolo的一致双分配策略来解决后处理中的冗余预测问题,消除了对NMS的依赖;
一对多标签分配指的是每个真实框的对应预测的边界框有多个,与GT的IOU超过0.5的候选边界框将被分配为正样本。基于每个正样本都会计算损失,进而调整权重参数,提高模型精度。正因为多个正样本,所以提供了丰富的监督信号。
一对一分配策略中,每个真实边界框只分配一个预测边界框作为正样本。无需NMS后处理,推理性能更优。
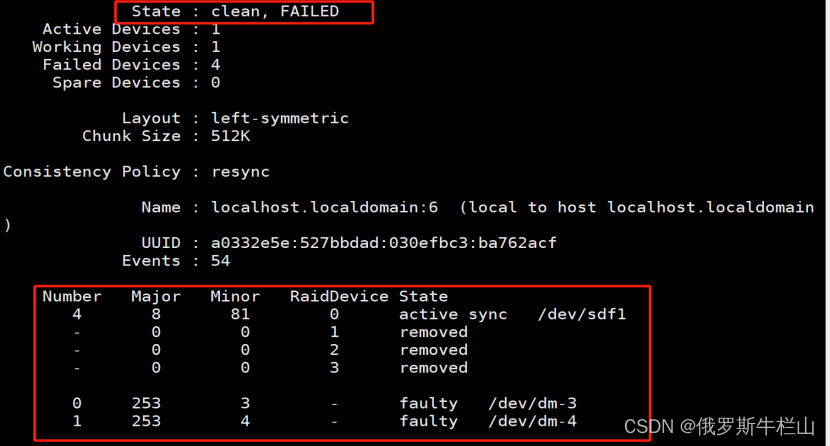
NMS后处理:由于一对多分配策略会产生多个重叠的正样本,也就是说多个边界框可能检测到同一个目标,因此需要使用非极大值抑制NMS来选择最优的预测边界框。NMS会抑制重叠度高的非最佳边界框,只保留得分最高的边界框,以减少检测结果的冗余。
- 2 提出了整体效率-精度驱动的模型体系结构设计策略。为了提高效率,分别提出了轻量化分类头(lightweight classification head)、空间通道解耦下采样(spatial-channel decoupled downsampling)和秩引导块设计(rank-guided block design),以减少显式计算冗余,实现更高效的架构。
通过实验证明,yolov10优于最先进的模型。
2 相关工作
实时目标探测器
实时目标检测的目的是在低延迟的情况下对目标进行分类和定位,这对现实世界的应用至关重要。在过去的几年里,大量的努力已经指向开发高效的探测器。其中,YOLO系列最为主流。YOLOv1、YOLOv2和YOLOv3识别了典型的检测架构,由Backbone、Neck和Head三部分组成。YOLOv4和YOLOv5引入了CSPNet设计来取代DarkNet,并结合了数据增强策略、增强的PAN和更多样化的模型尺度等。YOLOv6分别为Neck和Backbone提供了BiC和SimCSPSPPF,并采用锚定辅助训练和自蒸馏策略。YOLOv7引入了E-ELAN的富梯度流路径,并探索了几种可训练的免费增益方法。YOLOv8提出了C2f构建块,用于有效的特征提取和融合。Gold-YOLO提供了先进的GD机制来增强多尺度特征融合能力。YOLOv9提出了GELAN来改进体系结构和PGI来增强训练过程。
个人总结:这一段就是YOLO的发展史。
端到端目标检测器
端到端目标检测已经从传统的管道转变为提供流线型架构的范式。DETR引入变压器架构,采用匈牙利损失实现一对一匹配预测,从而消除了手工制作组件和后处理。从那时起,各种各样的DETR变体被提出,以提高其性能和效率。deformable - detr利用多尺度可变形注意力模块加快收敛速度。DINO将对比去噪、混合查询选择和forward two scheme集成到detr中。RT-DETR进一步设计了高效的混合编码器,并提出了最小不确定性查询选择,以提高精度和延迟。另一条实现端到端目标检测的线路是基于CNN检测器。可学习的神经网络和关系网络提供了另一种网络来消除检测器的重复预测。OneNet和DeFCN提出了一对一匹配策略,以实现完全卷积网络的端到端目标检测。FCOSpss引入了一个正样本选择器来选择最优样本进行预测。
3 方法
3.1 无NMS训练的一致的双重分配
在训练过程中,yolo通常利用TAL(标签分配策略)为每个实例分配多个阳性样本。采用一对多分配,可以产生丰富的监控信号,便于优化,实现更优的性能。但是,它需要yolo依赖NMS的后处理,导致部署的推理效率不够理想。虽然以前的工作探索一对一匹配来抑制冗余预测,但它们通常会引入额外的推理开销或产生次优性能。在这项工作中,我们提出了一种具有双标签分配和一致匹配度量的无nms的yolo训练策略,实现了高效率和竞争性的性能。

双标签分配
与一对多分配不同,一对一匹配只对每个基本事实分配一个预测,避免了NMS的后处理。然而,这种算法的监督能力较弱,导致算法的精度和收敛速度不理想。幸运的是,这种缺陷可以通过一对多赋值来弥补。为了实现这一目标,我们为yolo引入了双标签分配,以结合两种策略的优点。具体来说,如图2.(a)所示,我们为yolo加入了另一个一对一的头部。它保留了与原始一对多分支相同的结构和优化目标,但利用一对一匹配来获得标签分配。在训练过程中,两个头部与模型共同优化,让Backbone和Neck享受一对多分配提供的丰富监督。在推理过程中,我们抛弃了一对多头,利用一对一头进行预测。这使yolo能够进行端到端部署,而不会产生任何额外的推理成本。此外,在一对一匹配中,我们采用了top 1的选择,达到了与匈牙利匹配相同的性能效果,并且减少了额外的训练时间。
个人总结:在训练阶段,利用一对多头,为每个真实边界框分配多个正样本,提供丰富的监督信号,帮助模型更好地学习特征。与此同时,利用一对一头,为每个真实边界框分配一个正样本,确保训练过程中模型能够学会选择最佳的预测边界框;在推理阶段,抛弃了一对多头,只利用一对一头进行预测,从而提高性能。

一致的匹配度量
在分配过程中,一对一和一对多方法都利用一个度量来定量地评估预测和实例之间的一致性水平。为了实现两个分支的预测感知匹配,我们采用统一的匹配度量,如下:
![]()
其中,p是分类得分,b^和b分别是预测边界框和真实边界框,s表示空间先验,α和β是超参数。通过一致的匹配度量,可以确保一对一头和一对多头在优化方向上的一致性,进一步提升模型的性能。
3.2 整体效率-精度驱动的模型体系结构设计
除了后处理之外,yolo的模型架构也对效率和精度的权衡提出了很大的挑战。虽然之前的探索有各种设计策略,对YOLOs各部件的全面检查仍显不足。因此,模型体系结构表现出不可忽略的计算冗余和约束能力,这阻碍了其实现高效率和高性能的潜力。在这里,我们的目标是从效率和准确性的角度全面执行YOLOs的模型设计。
效率驱动的模型设计。YOLO的组件包括干stem、下采样层、具有基本构建块的stages和头部。stem的计算成本很少,因此我们对其他三个部分进行了效率驱动的模型设计。
- ① 轻量化分级头
在yolo中,分类和回归头通常共享相同的架构。然而,它们在计算开销方面表现出明显的差异。例如,在YOLOv8-S中,分类头(5.95G/1.51M)的FLOPs和参数数分别是回归头(2.34G/0.64M)的2.5倍和2.4倍。然而,在分析分类误差和回归误差的影响后,我们发现回归头对YOLOs的性能具有更重要的意义。因此,我们可以减少分类头的开销,而不必担心对性能造成很大的影响。因此,我们简单地对分类头采用轻量级架构,它由两个深度可分离的卷积组成,核大小为3×3,然后是一个1×1卷积。
- ② 空间通道解耦下采样
yolo通常利用步长为2的规则3×3标准卷积,实现空间下采样(从H × W到H/2 × W/2)和通道转换(从C到2C)同时进行。这引入了不可忽略的计算成本O(9/2HWC2)和参数量O(18C2)。相反,我们建议将空间缩减和信道增加操作解耦,从而实现更有效的下采样。具体来说,我们首先利用点向卷积来调节通道维度,然后利用深度卷积来执行空间下采样。这将计算成本降低到O(2HWC2+9/2HWC)和参数数量减少到O(2C2+18C)。同时,它最大限度地提高了下采样期间的信息保留,从而在降低延迟的情况下获得具有竞争力的性能。
- ③ 基于秩的块设计
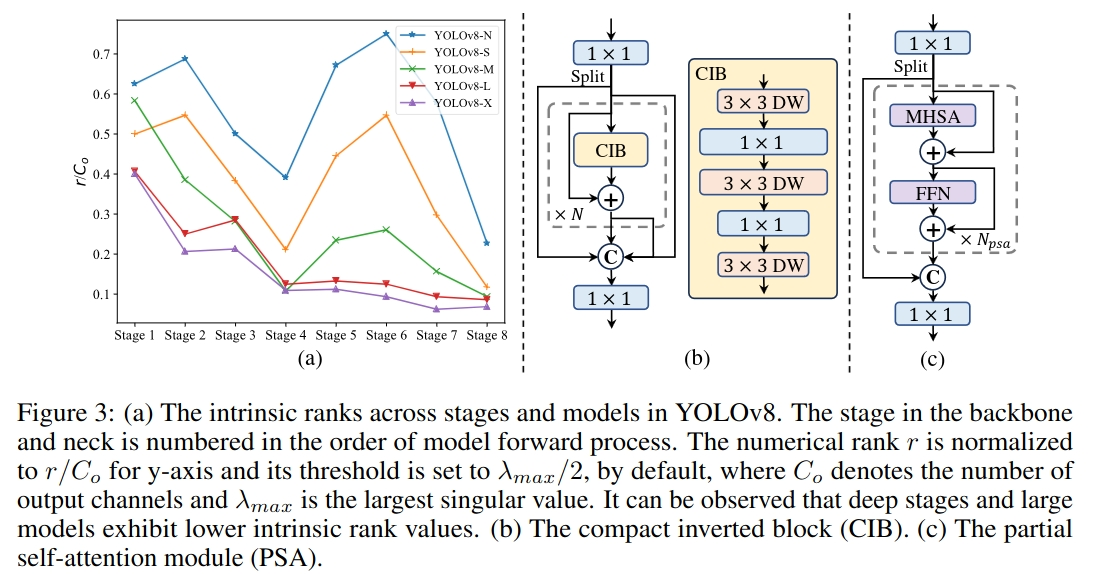
yolo通常在所有阶段使用相同的基本构建块,例如,YOLOv8中的瓶颈块。为了彻底检查这种同质设计的yolo,我们利用内在秩来分析每个阶段的冗余度。具体来说,我们计算每个阶段最后一个基本块的最后一个卷积的数值秩,计算大于阈值的奇异值的个数。结果如图3 (a)所示。YOLOv8,表明深层阶段和大型模型倾向于表现出更多的冗余。这一观察结果表明,简单地在所有阶段采用相同的区块设计并不能达到最佳的产能效率平衡。为了解决这个问题,我们提出了一个基于秩的块设计方案,旨在减少使用紧凑的架构设计显示冗余的阶段的复杂性。我们首先提出了一种紧凑的倒置块(CIB)结构,该结构采用廉价的深度卷积进行空间混合,采用高性价比的点卷积进行通道混合,如图3 (b)所示。它可以作为高效的基本构建块,例如嵌入ELAN结构(图3.(b))。在此基础上,我们提出了一种基于秩的区块分配策略,以在保持竞争能力的同时达到最佳效率。具体来说,给定一个模型,我们根据其内在的升序排序其所有阶段。我们进一步检查用CIB替换先导阶段基本块的性能变化,如果与给定模型相比没有性能下降,我们继续更换下一阶段,否则停止该过程。因此,我们可以在跨阶段和模型规模实现自适应紧凑块设计,实现更高的效率,而不影响性能。由于篇幅限制,我们在附录中提供了算法的细节。

3.3 精度驱动的模型设计
我们进一步探索了精度驱动设计的大核卷积和自关注,旨在以最小的成本提高性能。
- ① 大核卷积
采用大核深度卷积是扩大接受野和增强模型能力的有效方法。然而,简单地在所有阶段利用它们可能会导致用于检测小物体的浅层特征受到污染,同时还会在高分辨率阶段引入显著的I/O开销和延迟。因此,我们建议在深度阶段利用CIB中的大核深度卷积。具体来说,我们将CIB中第二个3×3深度卷积的内核大小增加到7×7,如下所示。此外,我们采用结构重参数化技术引入另一个3×3深度卷积分支,以缓解优化问题,而不会产生推理开销。此外,随着模型大小的增加,其感受野自然会扩大,使用大核卷积的好处会减少。因此,我们只对小模型采用大核卷积。
- ② 部分自注意力(PSA)
自注意由于其卓越的全局建模能力而被广泛应用于各种视觉任务中。然而,它表现出很高的计算复杂度和内存占用。为了解决这个问题,鉴于普遍存在的注意头冗余,我们提出了一种高效的部分自我注意(PSA)模块设计,如图3 (c)所示。具体来说,我们在1×1卷积后将跨通道的特征均匀地划分为两部分。我们只将其中一部分输入到由多头自注意模块(MHSA)和前馈网络(FFN)组成的NPSA模块中。然后通过1×1卷积将两个部分连接并融合。此外,我们遵循将查询和键的维度分配为MHSA中值的一半,并将LayerNorm替换为BatchNorm以进行快速推理(优化说明)。此外,PSA仅放置在分辨率最低的阶段4之后,避免了自关注的二次计算复杂性带来的过多开销(放置位置说明)。这样可以将全局表示学习能力融入到yolo中,计算成本较低,很好地增强了模型的能力,从而提高了性能。在官方代码block.py文件中包含PSA,如下图所示:

4 实验
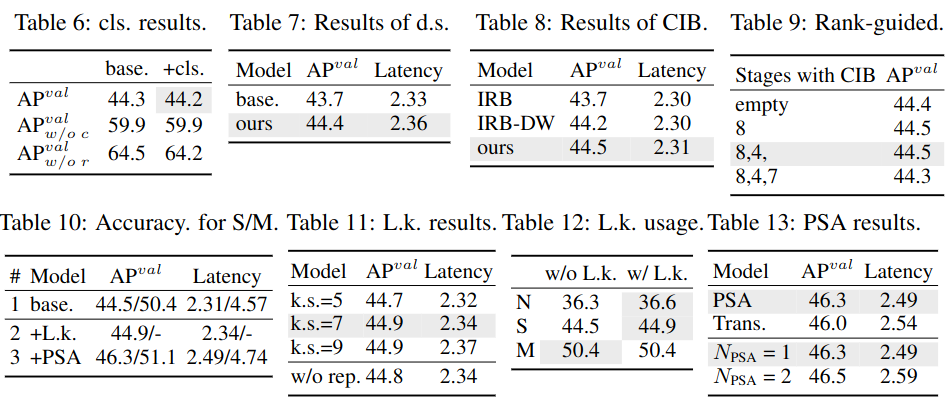
实验分析结果如下:

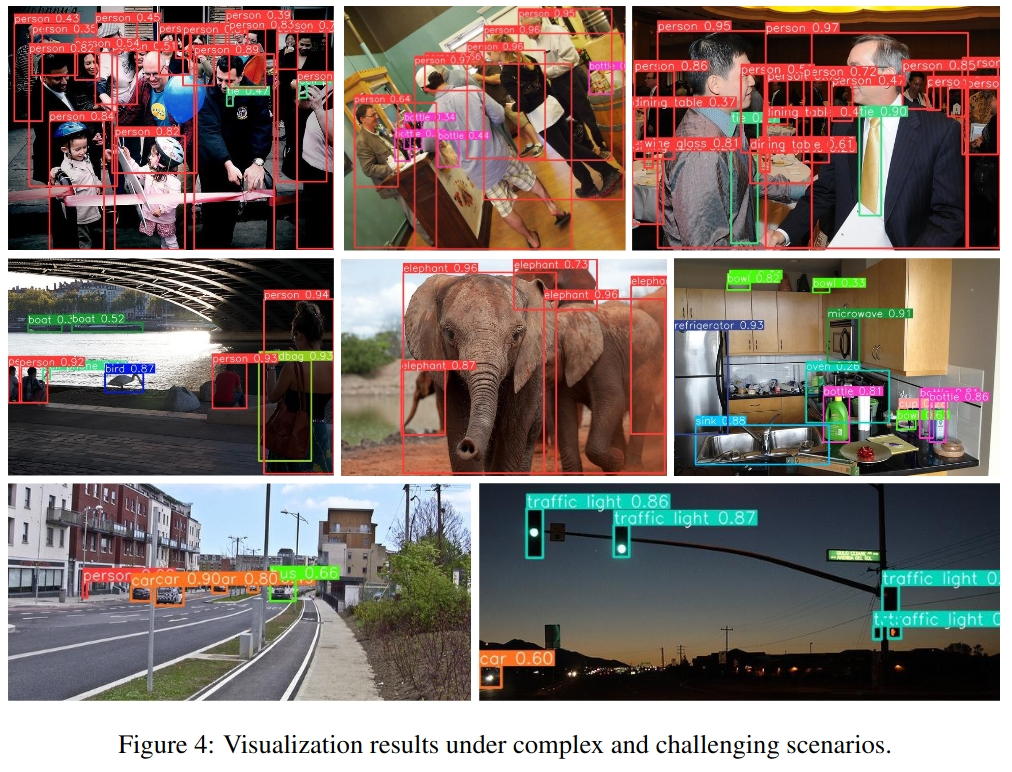
可视化结果如下:
5 结论
在本文中,我们针对整个yolo检测管道的后处理和模型架构进行了研究。对于后处理,我们提出了一致的双分配方法进行无nms训练,实现了高效的端到端检测。对于模型架构,我们引入了整体效率-精度驱动的模型设计策略,改善了性能-效率的权衡。这些带来了我们的YOLOv10,一种新的实时端到端目标探测器。大量实验表明,与其他先进探测器相比,YOLOv10的性能和延迟达到了最先进的水平,充分证明了它的优越性。
至此,本文分享的内容就结束啦!遇见便是缘,感恩遇见!!!💛 💙 💜 ❤️ 💚 💛 💙 💜 ❤️ 💚
![[vue3后台管理二]首页和登录测试](https://img-blog.csdnimg.cn/direct/dba3a7b2120b4b36be69931ff1a413a2.png)