本科毕业设计(论文)
题目:基于 Hadoop和Spark的课程推荐系统的设计与实现
烟台南山学院教务处
二〇二四年六月
院 系:科技与数据学院数据科学与软件工程系
专 业:数据科学与大数据技术
班 级:数据科学2001
姓 名:张子莉
学 号:202020709112
指导教师:宋晓娜


本人郑重声明:所呈交的学位论文,是本人在导师的指导下进行
研究工作所取得的成果。除文中已经注明引用的内容外,本论文不含
任何其他个人或集体已经发表或撰写过的研究成果。对本文的研究做
出重要贡献的个人和集体,均已在论文中作了明确的说明并表示了谢
意。本声明的法律结果由本人承担。
论文作者签名:
年 月 日
烟台南山学院关于毕业设计(论文)使用授权的说明
本人完全了解烟台南山学院有关保留、使用学士学位论文的规定,
即:学校有权保留、送交论文的复印件,允许论文被查阅,学校可以
公布论文的全部或部分内容,可以采用影印或其他复制手段保存论文。
指导教师签名:
年 月 日
论文作者签名:
年 月 日













如今,计算机和网络技术迅猛发展,数字化教育逐渐兴起,网上教育平台也大量涌现。比如说中国大学Mooc网,Icc教育平台,网易云课堂,沪上网校等等。这些教育平台为学生提供了广阔的学习空间。但这些平台由于数据量巨大,想要获取所需数据需要耗费大量的时间,而且对这些数据并没有比较完备的分析,如果设计一个可以将有用数据进行数据分析并可视化,就可以明确用户的需求,为在线教育平台提供了参考价值。
本系统基于Hadoop和Spark等大数据技术设计,数据来源是通过Python爬虫获取网络数据,数据清洗与处理采用了Hadoop中的数据清洗工具Mapreduce,数据分析阶段采用了Spark,数据可视化阶段采用Flask和Echarts。采用Vue.js搭建前端框架,采用Spring Boot搭建后端框架,采用MySQL建立数据库。采用VS Code、IDEA 作为主要开发工具。对网络海量的课程数据信息以图表的形式进行一个直观的展示,此外,该系统还具备了对课程的购买和查询功能等,充分体现了大数据技术在教育领域的应用价值。
关键词:数据可视化 网络爬虫 Hadoop Spark
Design and Implementation of the Course Recommendation System based on Hadoop and Spark
Nowadays, with the rapid development of computer and network technology, the rise of digital education, and a large number of online education platforms. For example, China University Mooc network, Icc education platform, netease Cloud classroom, Shanghai online school and so on. These educational platforms provide students with a broad learning space for them. However, due to the huge amount of data, these platforms need a lot of time to obtain the required data, and there is no relatively complete analysis of these data. If one is designed to analyze and visualize the useful data and clarify the needs of users, it provides reference value for the online education platform.
This system is designed based on big data technologies such as Hadoop and Spark. The data source is network data acquisition through Python crawler, the data cleaning tool Mapreduce in Hadoop is used for data cleaning and processing, Spark is used in the data analysis stage, and Flask and Echarts are used in the data visualization stage. The Vue.js framework is used on the front end and the Spring Boot framework on the back end, MySQL was used to establish the database. The VS Code and IDEA were used as the main development tools. The online massive amount of course data information is intuitively displayed in the form of charts. In addition, the system also has the function of purchase and query of courses, which fully reflects the application value of big data technology in the field of education.
Key words: Data visualization, Web Crawler, Hadoop ,Spark
目录
第1章 绪论
1.1 研究背景及意义
1.2 国内外研究现状
1.2.1 国内研究现状
1.2.2 国外研究现状
1.3 论文组织结构
1.4 本章小结
第2章 主要开发工具及关键技术介绍
2.1 主要开发工具介绍
2.1.1 WebStorm
2.1.2 IntelliJ IDEA
2.1.3 Virtual Studio Code
2.2 关键技术介绍
2.2.1 数据分析
2.2.2 网络爬虫技术
2.2.3 Hadoop生态系统
2.2.4 Spark计算引擎
2.2.5 MySQL 数据库
2.2.6 协同过滤算法
2.2.7 Maven 整合
2.2.8 前后端分离技术
2.3 本章小结
第3章 系统分析
3.1 系统可行性分析
3.1.1 技术可行性分析
3.1.2 经济可行性分析
3.1.3 操作可行性分析
3.2 功能需求分析
3.2.1 数据可视化大屏
3.2.2 用户用例分析
3.2.2 管理员用例分析
3.3 性能需求分析
3.3.1 响应时间
3.3.2 可伸缩性
3.3.3 可靠性
3.4 本章小结
第4章 系统设计
4.1 系统架构设计
4.1.1 数据采集模块
4.1.2 数据处理模块
4.1.3 推荐算法模块
4.1.4 用户交互模块
4.2 功能模块设计
4.3 数据仓库设计
4.3.1 数据仓库分层设计
4.3.2 数据仓库维度设计
4.4 数据库设计
4.4.1 E-R图设计
4.4.2 逻辑结构设计
4.4.3 物理结构设计
4.5 本章小结
第5章 系统实现
5.1 用户功能的实现
5.1.1 用户注册模块的实现
5.1.2 用户登录模块的实现
5.1.3 智能推荐模块模块
5.1.4 课程查询模块
5.1.5 课程评论模块
5.1.6 订单管理模块
5.1.7 支付充值模块(购物车模块)
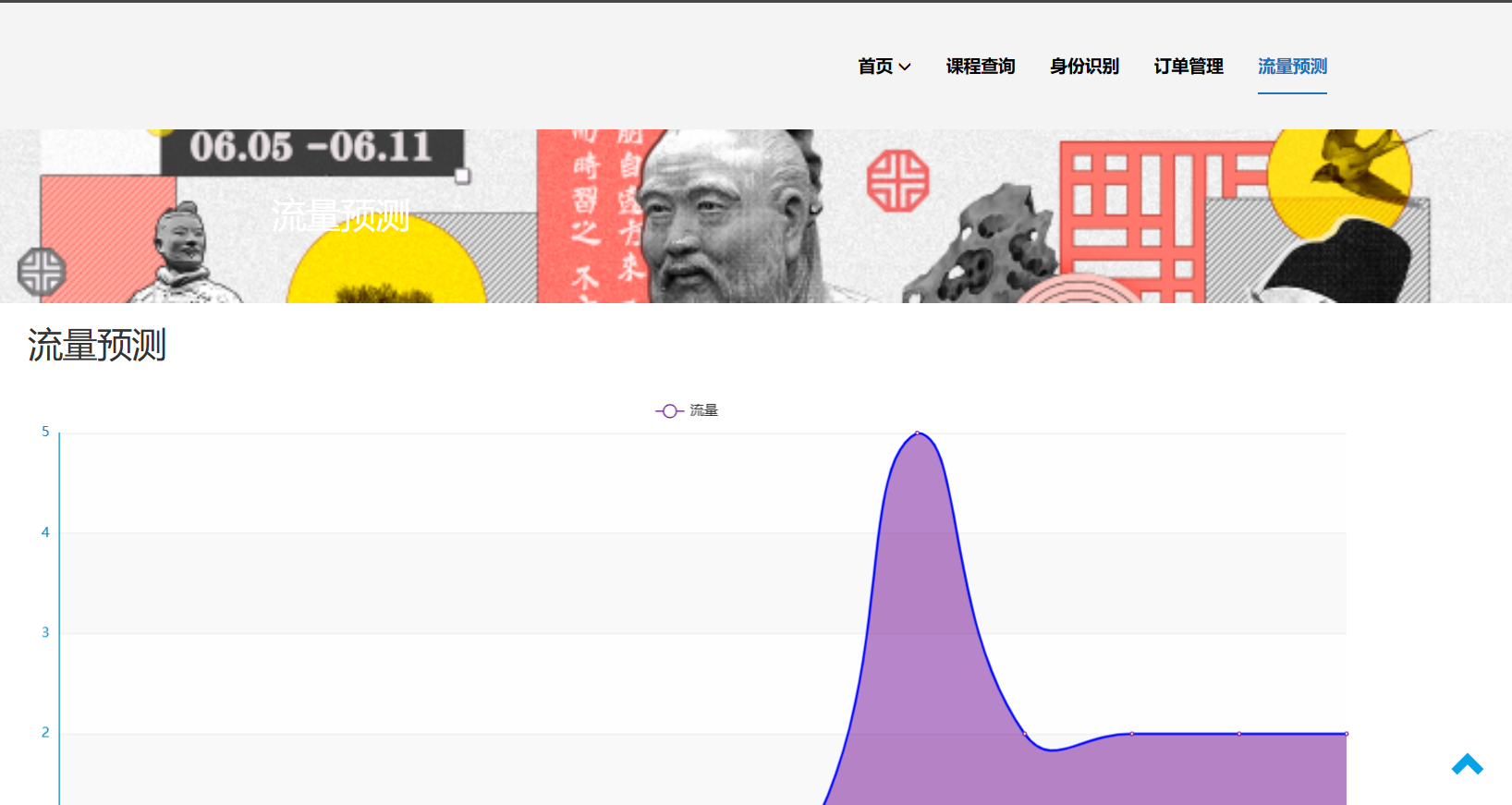
5.1.8 预测功能
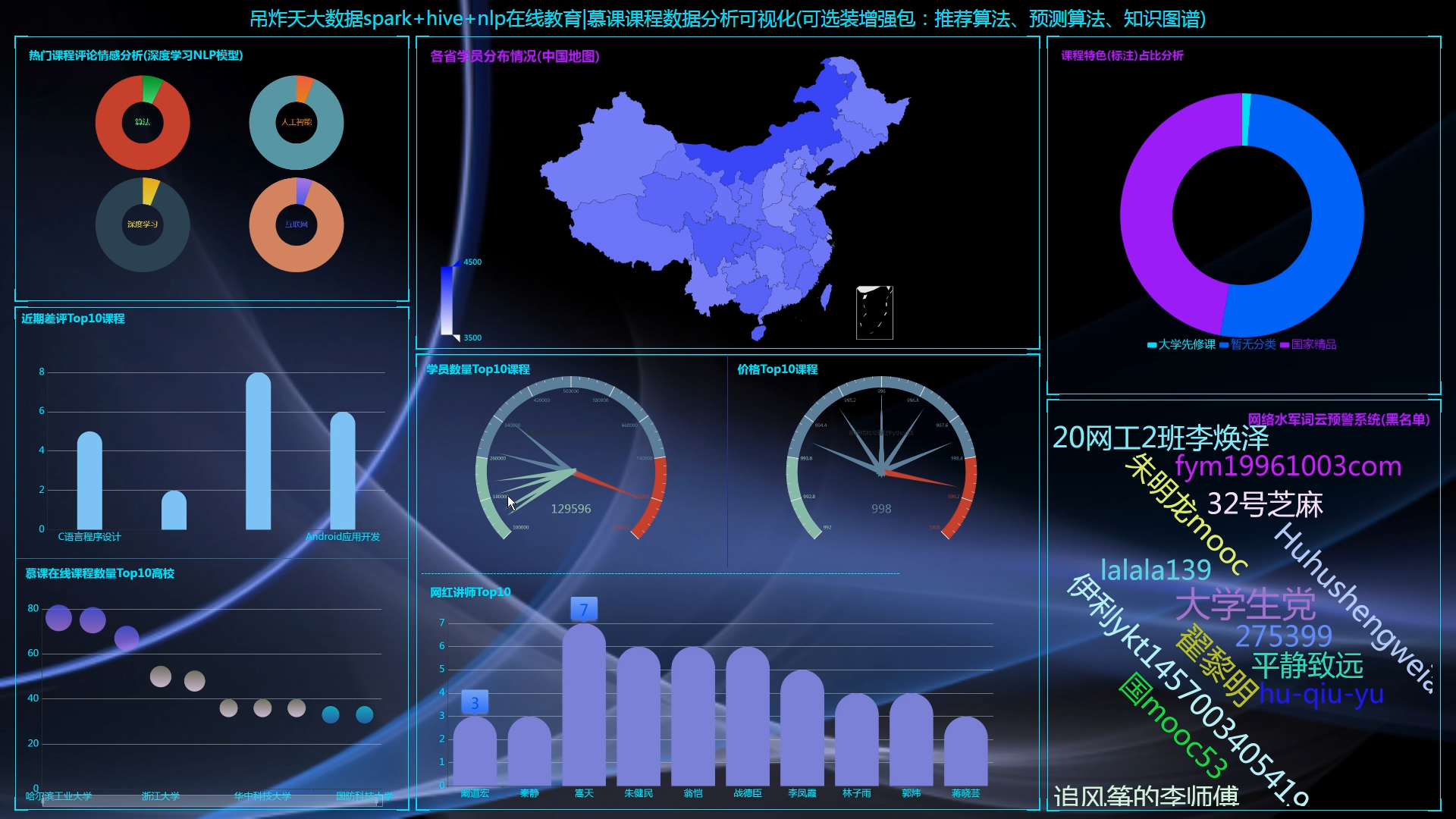
5.2 数据采集以及可视化大屏的实现
5.2.1 数据采集模块
5.2.2 数据可视化大屏
5.2.3 决策建议
5.3 系统管理员功能的实现
5.3.1 用户管理模块
5.3.2 个人中心模块
5.3.3 系统权限模块
5.3.4 系统日志模块
5.3.5 评论管理
5.3.6 章节管理
5.4 本章小结
第6章 系统测试
6.1 系统功能测试
6.2 系统可用性测试
6.3 维护测试
6.4 性能测试
6.5 测试结果分析
结论
致谢
参考文献
1.1 研究背景及意义
21世纪以来,信息技术不断发展,在线教育平台逐步兴起,为学生提供了宝贵的课程资源,打破了传统线下授课在时空上的局限性。然而这些在线教育平台含有了大量的学习数据,包括学习行为、学习习惯、知识点掌握情况等[1]。这些海量的学习数据蕴含着宝贵的教育信息,然而传统的在线教育平台由于数据处理和分析能力的不足和数据安全性的问题,在数据的采集、存储、处理和分析方面具有一定的挑战性[2]。因为对于在线教育平台而言,海量的用户行为数据、课程数据、学习数据等需要被高效地处理和分析,而传统的在线教育平台在处理数据时,往往面临着数据量大、处理速度慢、分析结果不准确等问题。
而在信息爆炸的时代,就在线教育而言,面临着海量的数据信息,人们往往会有这样的困惑,就是如何快速的从海量数据中获取真正符合个人需要的信息。另外,学生对于课程的选择和学习方向的确定也需要一定的参考,需要一个可以分析海量数据的课程推荐系统来满足个性化需求[3]。基于Hadoop和Spark的课程推荐系统,能够有效地解决这些问题,为在线教育的发展提供强大的技术支持。
该课程推荐系统的设计与实现以及可视化大屏的展示,可以有效地帮助老师和学生分析学习数据,了解学生的学习状态和学习习惯,及时调整教学策略,提高教学效果[4]。此外,对于卖家来说,该课程推荐系统的设计与实现以及可视化大屏也可以帮助他们更好地了解用户行为和需求,优化平台服务,提升用户体验。因此,该系统的设计与实现对在线教育的发展与完善和教学质量的提高有很大的促进作用。
1.2 国内外研究现状
1.2.1 国内研究现状
目前在国内,一些研究者已经尝试利用Hadoop和Spark等大数据技术来构建课程推荐系统。通过利用Hadoop和Spark在计算能力和分布式处理方面上的优势,对网络上的海量的课程数据进行预处理和分析,从而提高系统的推荐准确性和效率。除此之外,一些研究者还尝试结合爬虫技术从互联网上收集与课程相关的数据,并利用大数据技术对这些数据进行清洗、筛选和处理,为推荐系统提供更准确和全面的数据支持[5]。有研究者在基于Hadoop和Spark平台完成管理工具的伸缩和扩展上,使用了Apache Atlas元素管理工具,实现了元素管理。通过搭建集群的方式实现主机与主机之间的交互。
另外,国内一些研究者还开始关注将大数据可视化的研究和应用于课程推荐系统中。数据可视化在让用户更直观地理解和使用推荐系统方面起到了至关重要的作用。一些研究者已经使用图表和动画效果等可视化方式,将推荐系统的结果直观地呈现给用户,并通过交互式的界面让用户更好地参与到推荐过程中。
综上所述,国内的研究者已经开始关注利用Hadoop和Spark等大数据技术搭建课程推荐系统,并结合爬虫技术和数据可视化来提高推荐系统的准确性和用户体验。这些研究在推动大数据技术在课程推荐领域的应用方面具有重要意义,为今后的研究和应用提供了有益的借鉴和参考。
1.2.2 国外研究现状
在数据可视化领域,国外处于领先地位,已经提出了许多成熟的慕课数据可视化解决方案,包括基于Echarts、D3.js等技术的可视化平台。这些平台能够对在线教育平台数据进行多维度、多角度的展示和分析,为教育管理者和教师提供了强大的决策支持。在课程推荐系统方面,国外的研究较为深入,涉及到的技术更加先进和成熟。例如,基于大数据的推荐算法、基于用户行为分析的推荐系统等已经取得了一些成功的案例。在实际应用中,这些系统往往能够更好地满足用户的需求,并且具有更强的稳定性和可扩展性。
就大数据技术而言,美国、欧洲、日本等发达国家取得了显著成就,并引发了经济社会的深刻变革。美国在大数据技术的研究与应用方面居于全球领先地位。美国政府已经认识到大数据技术的重要性,并在政策层面积极推动数据开放共享、数据安全与隐私保护等方面的工作,在企业层面如谷歌、微软、亚马逊等也取得了重要突破。尽并将这些技术广泛应用于医疗、金融、教育、交通等领域,极大地推动了相关行业的发展。尽管大数据技术在全球范围内取得了显著成果,并为经济社会发展带来了深刻变革,但各国在发展这些技术的过程中,仍然面临数据安全与隐私保护、人才培养、技术标准制定等挑战。未来,各国需要进一步加强合作,共同推动大数据技术的创新与发展,以期为全球经济增长和人类福祉作出更大的贡献。未来,各国需要进一步加强合作,共同推动大数据技术的创新与发展,以期为全球经济增长和人类福祉作出更大的贡献。
1.3 论文组织结构
第 1 章是绪论。本章主要讲了大数据技术和在线教育平台的发展状况,运用大数据技术,为解决在线教育平台由于数据量多而杂而导致的分宝贵数据效率低的问题,从而使大数据技术在教育领域得到更高的应用价值。
第2章主要介绍了系统中所涉及的开发工具和相关技术。如运用Python爬虫对课程数据进行采集,使用Hadoop进行数据存储与清洗,应用Spark的机器学习库MLlib来实现推荐功能,并利用Echarts.js设计可视化大屏。采用Vue.js搭建前端界面,采用Spring Boot搭建后端框架,使用VS Code、IDEA等作为主要开发工具。
第3章是系统分析本章对系统的需求进行以下三个方面的分析:即系统可行性分析、功能需求分析、性能需求分析,并对这三个方面的需求进行具体分析。
第4章是系统设计。本章的主要内容是设计系统的方法,包括以下三个方面。第一,系统整体结构。第二,设计各模块的实现逻辑;第三,设计说明系统的数据库。
第5章是系统实现。本章是通过运用先前规划的系统设计,结合开发工具和相关技术,构建 各功能模块,展示出相应的实现界面效果。
第6章是系统测试。本章是对系统整体性能的调试,确保各功能模块正常运行,并对系统进行全面测试,以验证系统的运行效果。
1.4 本章小结
本章主要分析了该系统设计的背景和意义,说明了在国内外,大数据技术和推荐系统的研究现状,大致叙述了本论文的组织结构。
2.1 主要开发工具介绍
2.1.1 WebStorm
WebStorm是JetBrains旗下与IntelliJIDEA同源的JavaScript集成开发环境(简称IDE)。继承了IntelliJidea的部分强大的JS特性。WebStorm支持多种前端框架,如React、Angular、Vue等,以其丰富的代码编辑、调试、重构和版本控制功能,使之成为开发者最为偏爱的前端开发工具之一。
2.1.2 IntelliJ IDEA
IntelliJ IDEA,全称Intelligent Java Integrated Development Environment,即智能化的Java集成开发坏境。IntelliJ IDEA开发于JetBrains公司,在软件开发中,这款Java IDE在智能代码助手、代码自动提示、重构、JavaEE支持、版本控制工具等方面功能丰富,被广泛认可为当前流行且功能强大的Java IDE之一,为开发人员提供了高效便捷的编码、调试和部署环境。
2.1.3 Virtual Studio Code
Visual Studio Code,简称为 VS Code,是一款由微软开发的轻量级、跨平台集成开发环境其功能涵盖了多种编程语言,包括JavaScript、TypeScript、Python、C++等,并提供了各种插件和工具,以简化开发过程。VS Code拥有强大的编辑功能,智能的代码提示以及直观的调试体验,这些特性有助于提高开发者的工作效率和代码质量。
2.2 关键技术介绍
2.2.1 数据分析
2.2.2 网络爬虫技术
网络爬虫是自动信息抓取过程,需要依赖于事先设定的规则。通过分析网页自动获取网页信息,与手动查找网页数据相比,自动抓取无疑更为便利。本文使用 Python 的 Requests 库和 Beautifulsoup 库去解析网站,获取数据[7]。当网络爬虫开始抓取网页时,可能会引发网站的反爬机制,导致操作失败。因此,在开发爬虫程序时,需要考虑如何应对反爬机制,这将增加额外的工作量。并且,合法合规是网络爬虫必须要遵守的准则,不能随意侵犯网站信息。
2.2.3 Hadoop生态系统
Hadoop生态系统是一个由Apache Hadoop项目发展而来的大数据处理平台,它包含了许多有关大数据处理的组件和工具,用于构建和管理大规模数据处理应用程序。Hadoop生态系统包括了Hadoop分布式文件系统(HDFS)、Hadoop YARN、Hadoop MapReduce和一系列其他核心组件[8],如HBase、Hive、Oozie、Flume、Zookeeper、Sqoop、Mahout等。这些组件和工具相互配合,为用户提供全面的大数据解决方案,助力企业有效地处理和分析海量数据,以获得更多商业洞察和价值。Hadoop生态系统的大体框架如图2.1所 示。
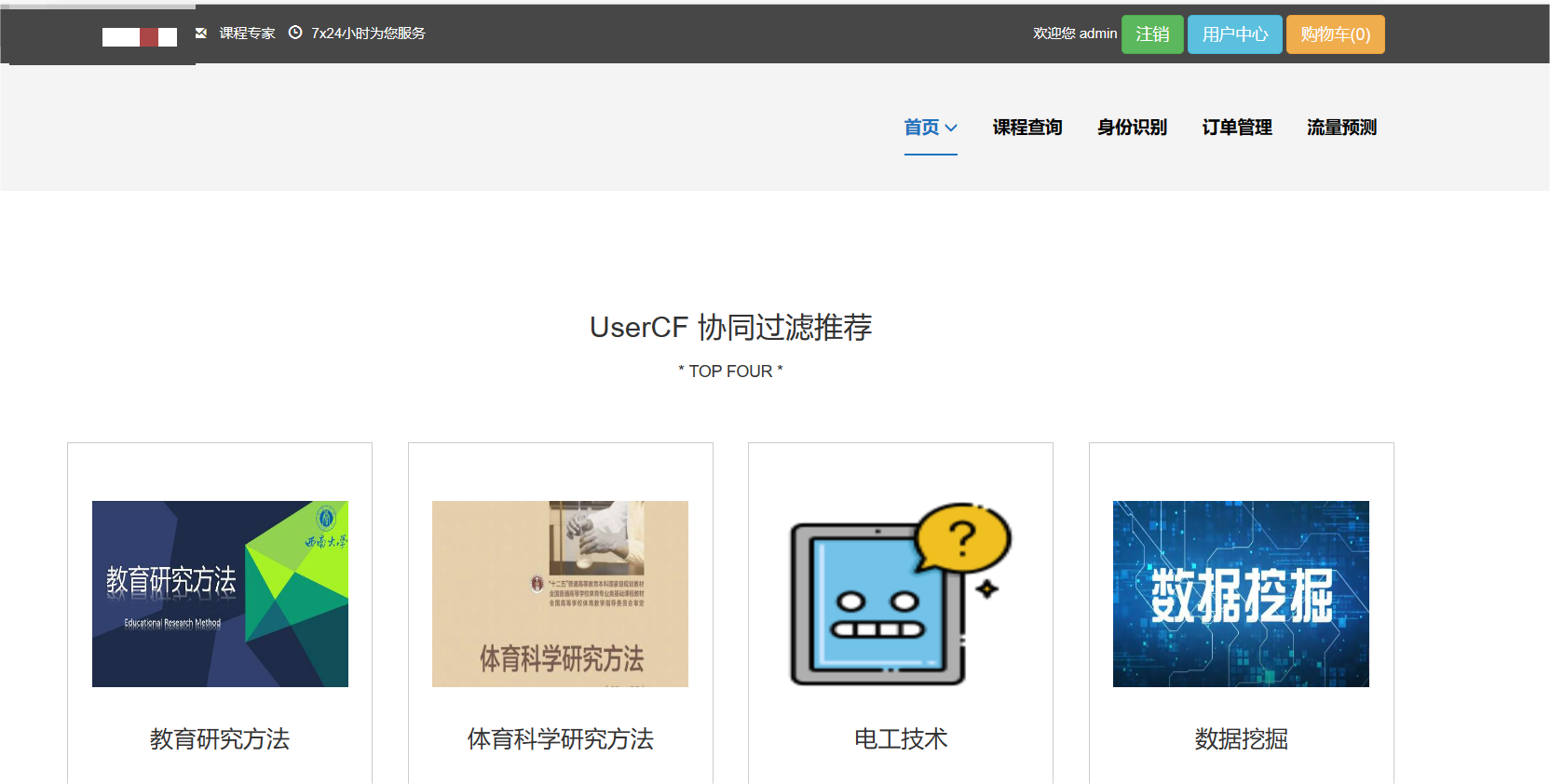
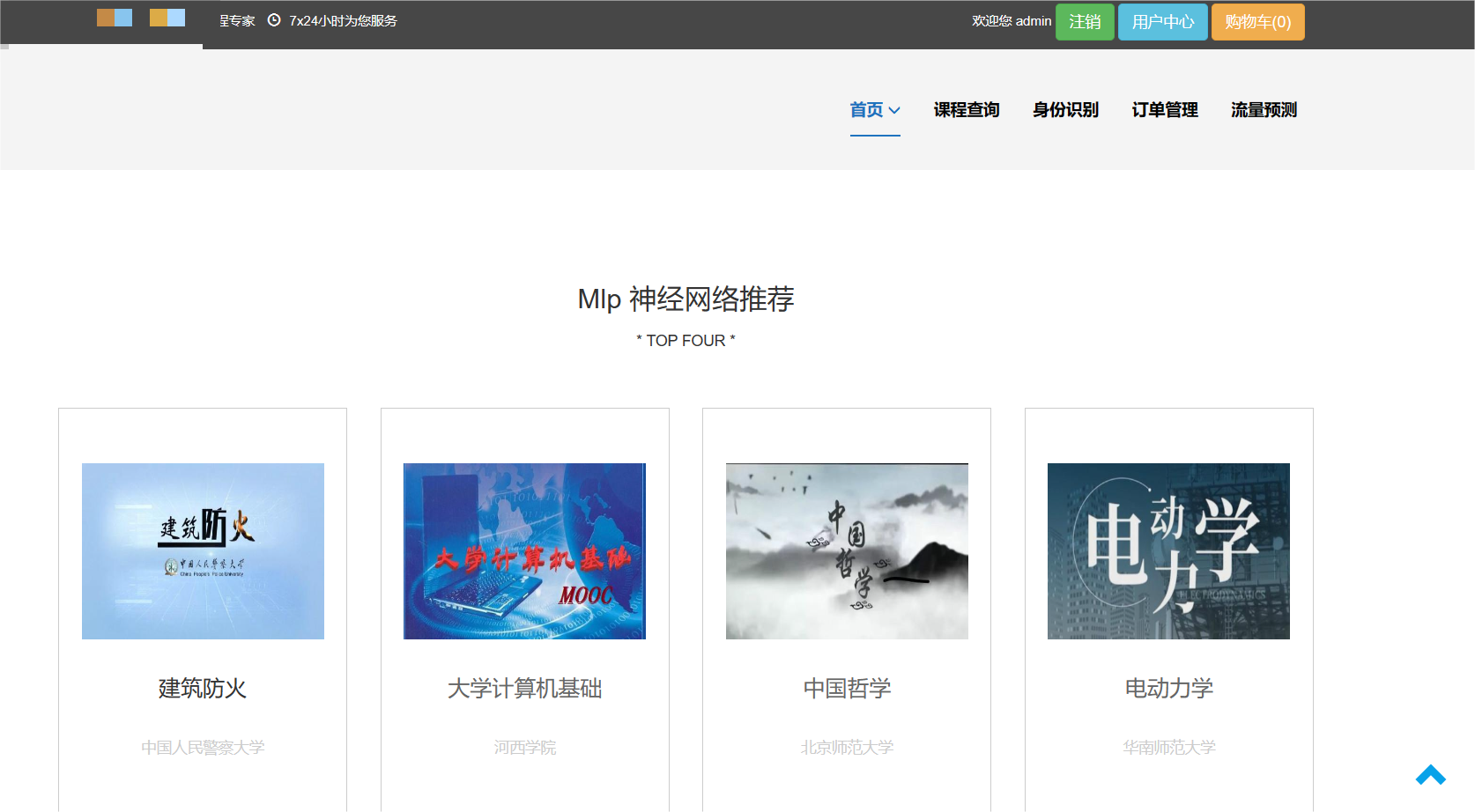
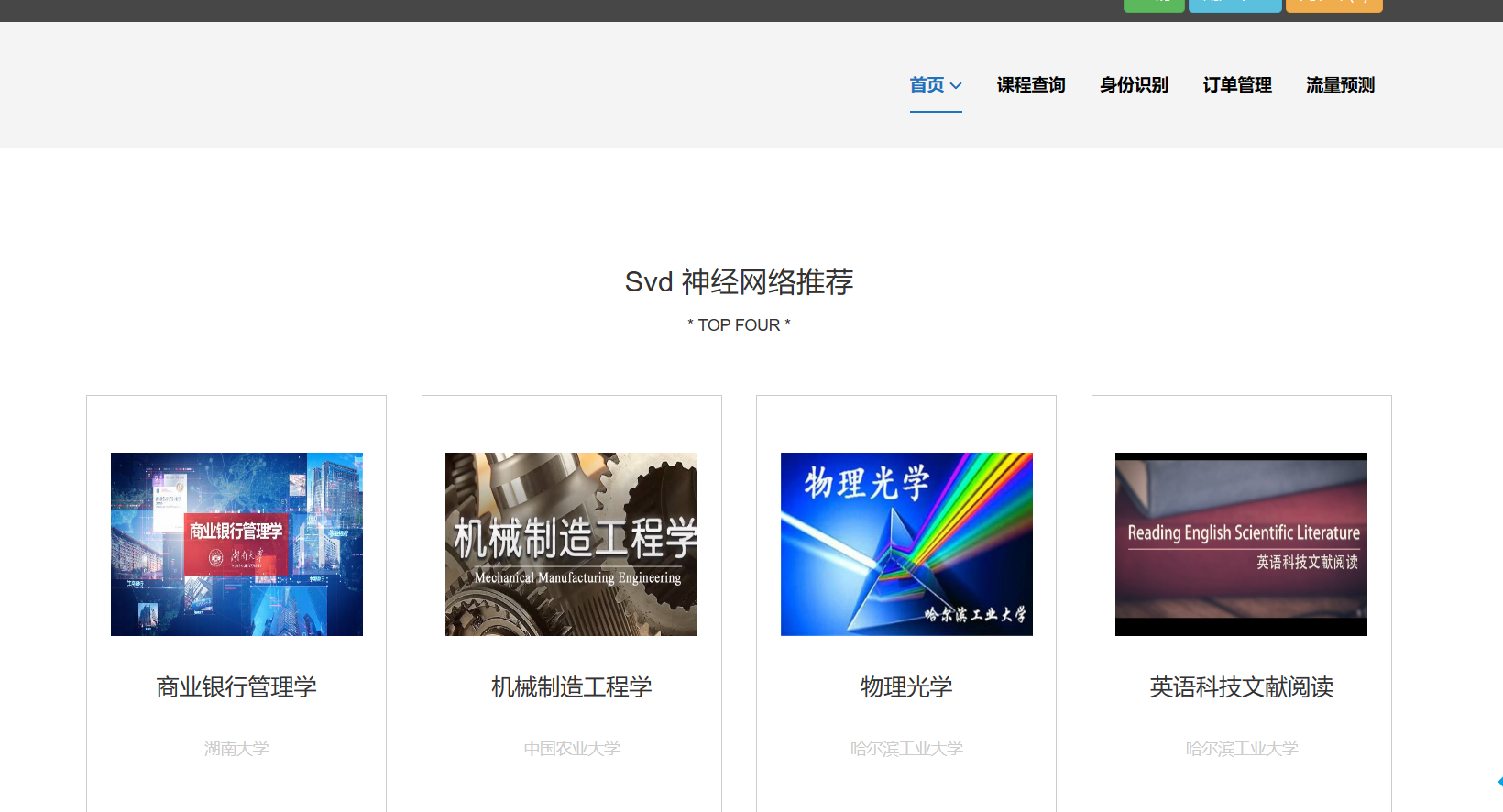
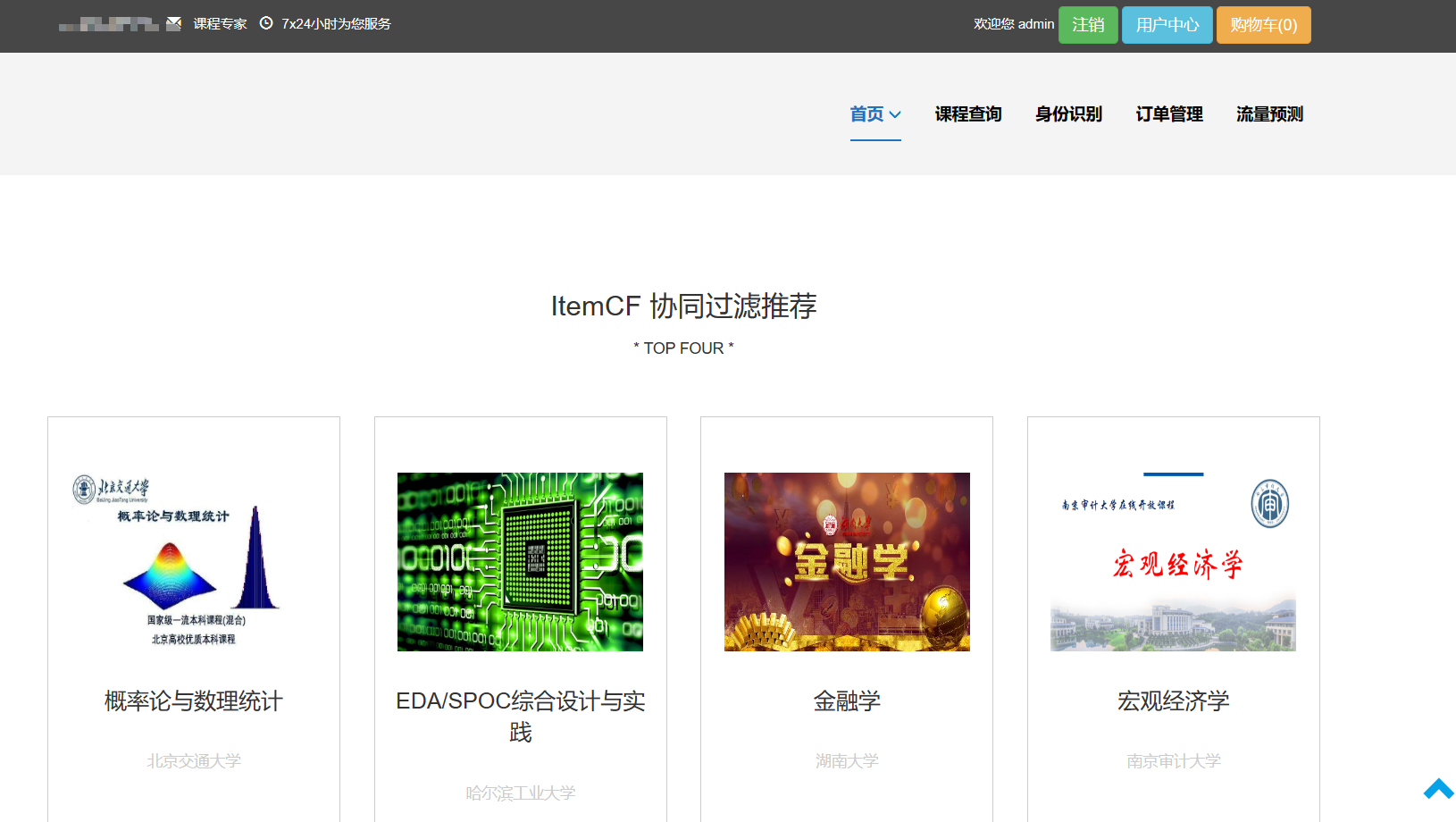
核心算法代码分享如下:
package com.bigdata.storm.kafka.util;import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;/*** @program: storm-kafka-api-demo* @description: redis工具类* @author: 小毕* @company: 清华大学深圳研究生院* @create: 2019-08-22 17:23*/
public class JedisUtil {/*redis连接池*/private static JedisPool pool;/***@Description: 返回redis连接池*@Param: *@return: *@Author: 小毕*@date: 2019/8/22 0022*/public static JedisPool getPool(){if(pool==null){//创建jedis连接池配置JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();//最大连接数jedisPoolConfig.setMaxTotal(20);//最大空闲连接jedisPoolConfig.setMaxIdle(5);pool=new JedisPool(jedisPoolConfig,"node03.hadoop.com",6379,3000);}return pool;}public static Jedis getConnection(){return getPool().getResource();}/* public static void main(String[] args) {//System.out.println(getPool());//System.out.println(getConnection().set("hello","world"));}*/}